测试PostgreSQL数据库的Upsert功能:不存在则新增,存在则更新
发表时间: 2017-12-13 15:03
INSERT INTO the_table (id, column_1, column_2)VALUES (1, 'A', 'X'), (2, 'B', 'Y'), (3, 'C', 'Z')ON CONFLICT (id) DO UPDATE SET column_1 = excluded.column_1, column_2 = excluded.column_2;
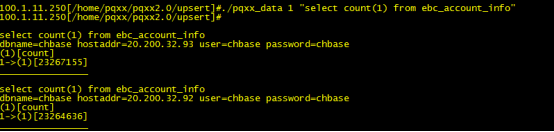
两个库表,每个库大概2326万数据
每个库数据量如下
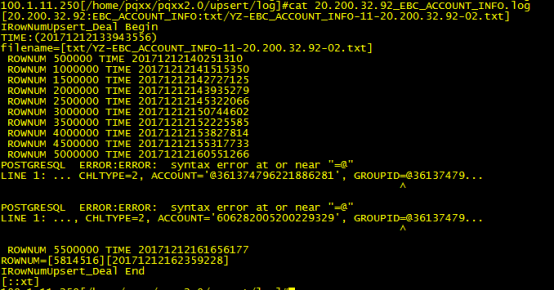
操作文件每500000对应时间
从上面可以看出,库表存量数据为2326万左右的数据,利用pg的upsert功能进行数据的存在则update,不存在则insert的实现
其中第一个50万花从13点39分开始到14点02分完成,总共有23分钟
计算一下,500000除以23分钟,也就是一分钟只处理21739条,也就是一秒钟才362条记录,由于第一个时间可能包含了打开文件读取的时间,有所增加
第二个50万,以及后面的每个50万记录,大概时间在12分钟到15分钟直接,就算平均的14分钟,这样每分钟35714条,每秒595条
这样的效率对于大数据量,比如2千万+数据量使用upinser并不一定可选
这是92文件的全部日志,由于有两条错误记录,然后是10000条一提交,所以有20000条记录进入了err日志文件需要重跑,但可以大概的看一下总体的5814516条记录往23264636条数据的PG数据库进行upsert操作,总共花掉了2小时44分钟
从上图可以看出来,最终数据由23264636变为了29059152,新增了5794516条记录,164分钟处理时间
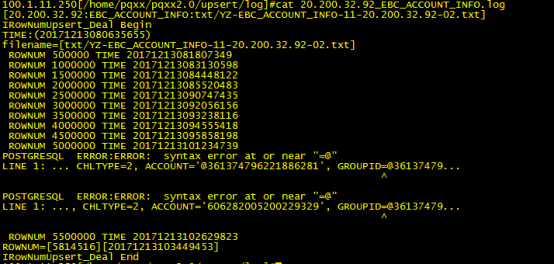
下面使用原文件再执行一次所花费时间如下
可以看出,这一次没50万条的记录所花费时间在11到14分钟,折中,每50万条记录12分钟,总时长2小时28分钟,比第一次少了16分钟之多,也就是这一次每分钟41666条记录,比第一次多了5952,每秒多了99条,这可是第一次的16个点啊,效率明显加强
第一次打底数据为23267155,第二次打底数据为第一次结束后的最终数据29059152
第一次全部数据都执行了insert,第二次全部数据都执行了update
第一次总时长164分钟,第二次总时长148分钟
第一次每秒595条insert,第二次每秒694条update
所以postgresql数据库的upsert功能原理是先去查找,当匹配到关键值时立马进行update操作,若发现没有则再做insert处理
而且upsert最终执行update的效率会高于最终执行insert的效率
当文件大部分为insert时,是否需要考虑直接使用insert功能不使用upsert的insert呢?
首先我们说说upsert的好处,那就是避免了去区分数据文件的数据是应该insert还是update,这其实也是省去了一定的处理时间,当然在很多事物不同步时也是可以选择这样的分布处理,只要前期工作做得够好就行,不然就向上面的报错一样,1条出现错误那那一批次全部失败,当然也可以优化提交的记录数,也可以一条一提交,这个需要自己根据自己的情况而定,目前美丽的程序员是不适合一条一提交,还好错误文件有提前报错,稍作修改就可以再次执行插入那剩下的19998条记录
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12





 鲁公网安备37020202000738号
鲁公网安备37020202000738号