为什么Postgres能够取代MySQL成为最受欢迎的数据库?
发表时间: 2023-12-13 20:45
你好,我是 EarlGrey,喜欢翻译点东西,偶尔写写代码。
后台回复关键词“电子书”,送你一份我收藏的电子书合集。
本文来自 Star History 网站的 10 月精选,经 EarlGrey@进击的Grey 翻译后与大家分享。
原文链接为:https://star-history.com/blog/ai-for-postgres
在2023年Stack Overflow开发者调查中,Postgres被评为最受欢迎的数据库,取代了MySQL的桂冠。为什么?我们认为背后的一大因素是Postgres的扩展。得益于可扩展的架构以及Postgres仍然是一个社区所有的项目这一事实,Postgres生态系统最近一直在蓬勃发展。
Postgres 扩展为数据库添加了媲美内置特性的功能。多年来,已经出现了一些针对人工智能用例的扩展。其中有一些是今年出现的,但令人惊讶的是,还有一些是几年前首次出现的,现在仍然是其中的佼佼者。
在本文中,我们将分享五种 Postgres 扩展,它们将提升您的人工智能体验。
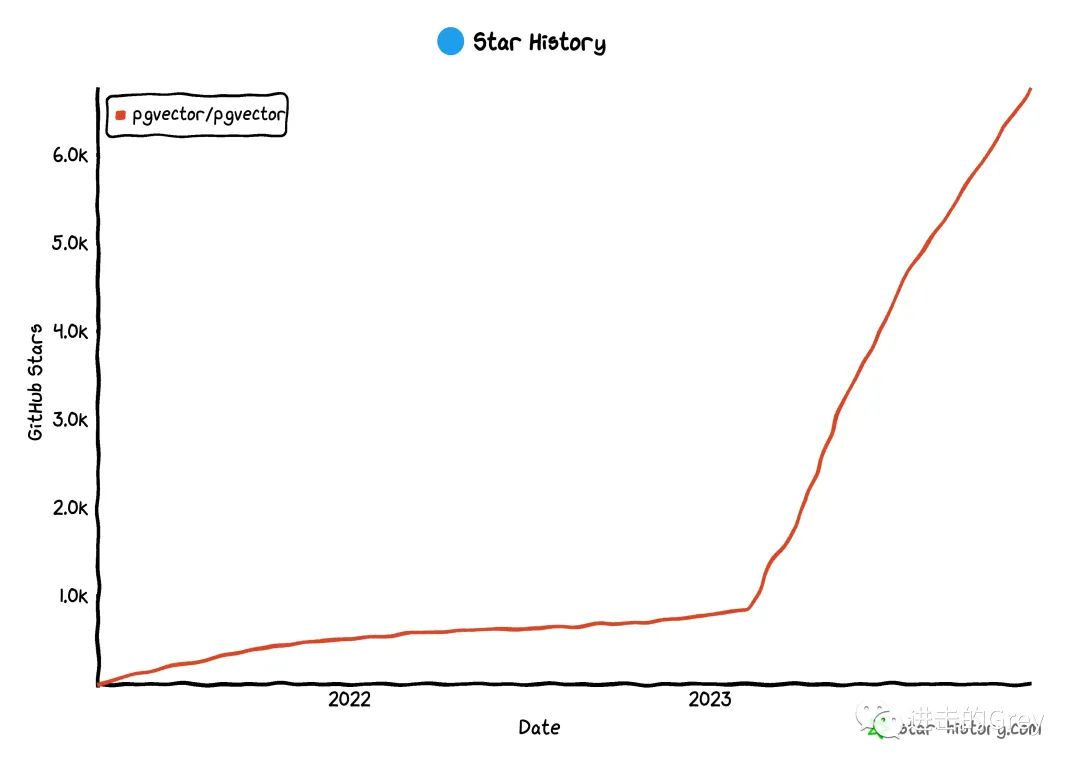
pgvector是专为 Postgres 设计的开源向量相似性搜索(支持 Postgres 11+)。它也可用于存储嵌入。它从 2021 年就开始出现了,远在人工智能成为我们日常生活的一部分之前。2023.2 年左右,当向量相似性搜索成为热门话题时,它的受欢迎程度急剧上升。
如果你正在寻找一个向量数据库,Postgres 就可以满足你的需求,你可以继续使用 Postgres,它的优势包括
如果你使用的是普通的Postgres,只需编译并安装扩展即可;如果你使用的是Postgres服务或应用程序,其中有些已经包含了pgvector,例如Aiven、Neon、Supabase、Postgres.app等。
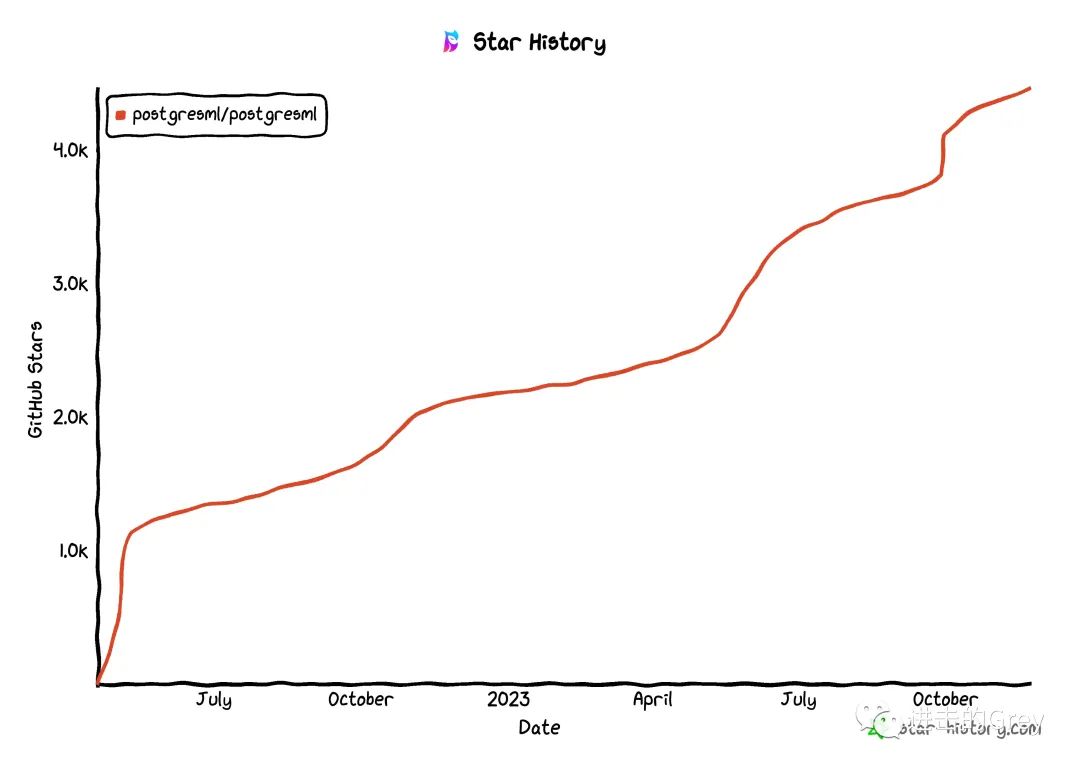
PostgresML是一个允许开发人员将机器学习(ML)模型集成到Postgres中的扩展,今年5月获得了470万美元种子轮融资。它可以使用 SQL 查询对文本和数据进行训练和推理,大大降低了应用程序开发的复杂性。
如果你的公司没有花哨的 ML 工作负载(因为不是所有人都是人工智能巨头),但又想建立自己的机器学习模型,从新鲜数据中学习,这将是一个很好的入门方法。
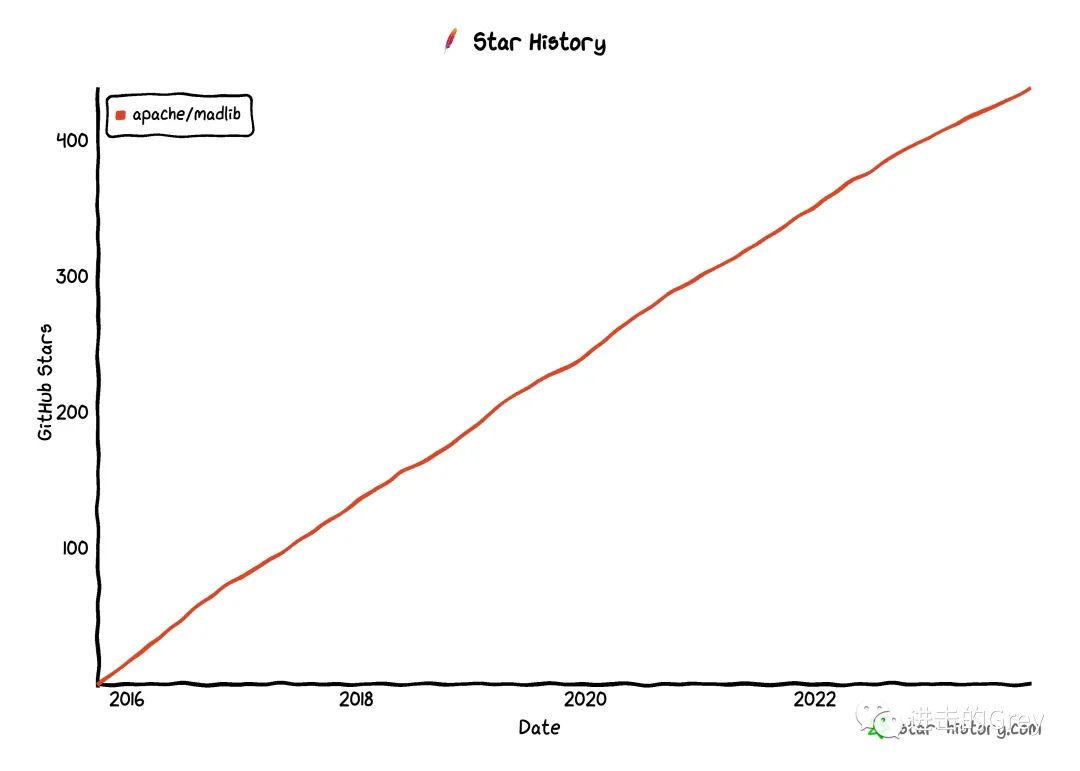
Apache MADlib是一个用 SQL 进行大数据机器学习的工具。早在 ChatGPT 为人工智能带来热度之前,它就已经出现,其 repo 于 2016 年发布在 GitHub 上,但最初的版本可以追溯到 2011 年。

人们认为 SQL 无法很好地对大型或非结构化数据集进行推理、预测或因果分析,这种看法已不再正确。MADlib 基本上是一个数据库内机器学习库,你可以在数据所在的数据库中执行高级机器学习。安装后,你可以使用 SQL 执行各种数据分析任务,包括轻松地进行回归和分类。
MADlib 中的 MAD 实际上是 Magnetic(磁性)、Agile(敏捷)和 Deep(深度)的缩写。
pg_embedding是 Neon 今年七月发布的产品。
它使用 Hierarchical Navigable Small Worlds (HNSW) 索引进行高维相似性搜索,这比 pgvector 增加对 HNSW 的支持还要早(很难理解为什么它刚出来时比 pgvector](https://neon.tech/blog/pg-embedding-extension-for-vector-search) 快 20 倍)。
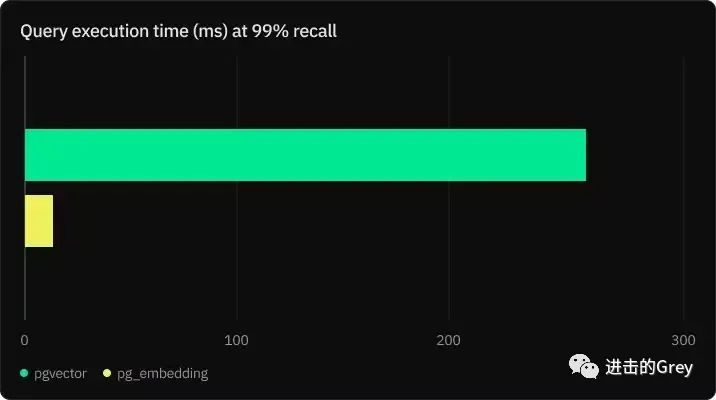
但几个月后的九月份,他们又添加了一条说明,提到他们不再致力于 pg_embedding 了。看来真的不存在买还是建的两难选择:如果有像样的服务,它就是不二之选。
pg_gpt是一个实验性的Postgres扩展,它在Postgres内部使用了OpenAI GPT API,因此你可以用自然语言向数据库提问。它实际上是由开源 ELT 平台 CloudQuery 开发的。
这个插件通过向 OpenAI GPT API 发送部分数据库模式(虽然没有数据)来工作,因此不建议在生产数据库中使用,但如果你想了解公共模式的一些信息,这将是一个有趣的工具。
今年我们看到了很多:科技界正在转向人工智能,并在寻找一种导航方式,以找到自己的立足点。好在Postgres开放支持扩展,我们有福了,可以通过这些扩展为我们的Postgres添加人工智能功能,而无需转向新的数据库。
***
- EOF -
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12

 鲁公网安备37020202000738号
鲁公网安备37020202000738号