零基础如何开始学习 Node.js?
发表时间: 2019-07-25 08:15
定义:
流的英文 Stream,流(Stream)是一个抽象的数据接口,Node.js 中很多对象都实现了流,流是 EventEmitter 对象的一个实例,总之它是会冒数据(以 Buffer 为单位),或者能够吸收数据的东西,它的本质就是让数据流动起来。 可能看一张图会更直观:
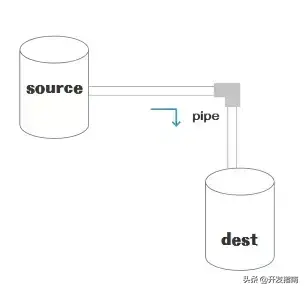
注意:Stream 不是 Node.js 独有的概念,而是一个操作系统最基本的操作方式,只不过Node.js 有 API 支持这种操作方式。Linux 命令的 | 就是 Stream。
视频播放例子
小伙伴们肯定都在线看过电影,对比定义中的图-水桶管道流转图,Source 就是服务器端的视频,Dest 就是你自己的播放器(或者浏览器中的 Flash 和 H5 Video)。大家想一下,看电影的方式就如同上面的图管道换水一样,一点点从服务端将视频流动到本地播放器,一边流动一边播放,最后流动完了也就播放完了。
说明:视频播放的这个例子,如果我们不使用管道和流动的方式,直接先从服务端加载完视频文件,然后再播放。会造成很多问题
读取大文件 Data 的例子
使用文件读取
const http = require('http');const fs = require('fs');const path = require('path');const server = http.createServer(function (req, res) { const fileName = path.resolve(__dirname, 'data.txt'); fs.readFile(fileName, function (err, data) { res.end(data); });});server.listen(8000);使用文件读取这段代码语法上并没有什么问题,但是如果 data.txt 文件非常大的话,到了几百M,在响应大量用户并发请求的时候,程序可能会消耗大量的内存,这样可能造成用户连接缓慢的问题。而且并发请求过大的话,服务器内存开销也会很大。这时候我们来看一下用Stream 实现。
const http = require('http');const fs = require('fs');const path = require('path');const server = http.createServer(function (req, res) { const fileName = path.resolve(__dirname, 'data.txt'); let stream = fs.createReadStream(fileName); // 这一行有改动 stream.pipe(res); // 这一行有改动});server.listen(8000);使用 Stream 就可以不需要把文件全部读取了再返回,而是一边读取一边返回,数据通过管道流动给客户端,真的减轻了服务器的压力。
看了两个例子我想小伙伴们应该知道为什么要使用 Stream 了吧!因为一次性读取,操作大文件,内存和网络是吃不消的,因此要让数据流动起来,一点点的进行操作。
再次看这张水桶管道流转图
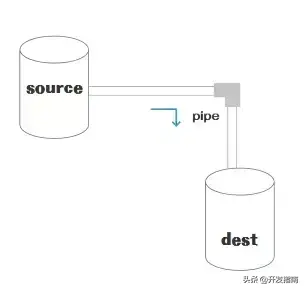
图中可以看出,Stream 整个流转过程包括 Source,Dest,还有连接二者的管道 Pipe (Stream 的核心),分别介绍三者来带领大家搞懂 Stream 流转过程。
Stream 的常见 来源方式 有三种:
这里先说一下从控制台输入这种方式,2 和 3 两种方式 Stream 应用场景章节会有详细的讲解。
看一段 process.stdin 的代码
process.stdin.on('data', function (chunk) { console.log('stream by stdin', chunk) console.log('stream by stdin', chunk.toString())})//控制台输入koalakoala后输出结果stream by stdin <Buffer 6b 6f 61 6c 61 6b 6f 61 6c 61 0a>stream by stdin koalakoala运行上面代码:然后从控制台输入任何内容都会被 data 事件监听到,process.stdin 就是一个 Stream 对象,data 是 Stream 对象用来监听数据传入的一个自定义函数,通过输出结果可看出 process.stdin 是一个 Stream 对象。
说明: Stream 对象可以监听"data","end","opne","close","error"等事件。Node.js 中监听自定义事件使用 .on 方法,例如 process.stdin.on(‘data’,…), req.on(‘data’,…) ,通过这种方式,能很直观的监听到 Stream 数据的传入和结束
从水桶管道流转图中可以看到,在 Source 和 Dest 之间有一个连接的管道 Pipe,它的基本语法是 source.pipe(dest),Source 和 Dest 就是通过 Pipe 连接,让数据从 Source 流向了dest。
Stream 的常见 输出方式 有三种:
Stream 的应用场景主要就是处理 IO 操作,而 HTTP 请求和文件操作都属于 IO 操作。这里再提一下 Stream 的本质——由于一次性 IO 操作过大,硬件开销太多,影响软件运行效率,因此将 IO 分批分段进行操作,让数据像水管一样流动起来,直到流动完成,也就是操作完成。下面对几个常用的应用场景分别进行介绍
一个对网络请求做压力测试的工具 ab,ab 全称 Apache bench ,是 Apache 自带的一个工具,因此使用 ab 必须要安装 Apache 。MacOS 系统自带 Apache ,Windows 用户视自己的情况进行安装。运行 ab 之前先启动 Apache ,MacOS 启动方式是 sudo apachectl start 。
Apache bench 对应参数的详细学习地址,有兴趣的可以看一下 Apache bench 对应参数的详细学习地址(
https://ruby-china.org/topics/13870)。
介绍这个小工具的目的是对下面几个场景可以进行直观的测试,看出使用stream带来了哪些性能的提升。
这样一个需求:
使用 Node.js 实现一个 HTTP 请求,读取 data.txt 文件,创建一个服务,监听 8000 端口,读取文件后返回给客户端,讲 Get 请求的时候用一个常规文件读取与其做对比,请看下面的例子。
// getTest.jsconst http = require('http');const fs = require('fs');const path = require('path');const server = http.createServer(function (req, res) { const method = req.method; // 获取请求方法 if (method === 'GET') { // get 请求方法判断 const fileName = path.resolve(__dirname, 'data.txt'); fs.readFile(fileName, function (err, data) { res.end(data); }); }});server.listen(8000);// getTest2.js// 主要展示改动的部分const server = http.createServer(function (req, res) { const method = req.method; // 获取请求方法 if (method === 'GET') { // get 请求 const fileName = path.resolve(__dirname, 'data.txt'); let stream = fs.createReadStream(fileName); stream.pipe(res); // 将 res 作为 stream 的 dest }});server.listen(8000);对于下面 Get 请求中使用 Stream 的例子,会不会有些小伙伴提出质疑,难道 Response 也是一个 Stream 对象,是的没错,对于那张水桶管道流转图,Response 就是一个 Dest。
虽然 Get 请求中可以使用 Stream,但是相比直接 File 文件读取·res.end(data) 有什么好处呢?这时候我们刚才推荐的压力测试小工具就用到了。getTest1 和 getTest2 两段代码,将data.txt 内容增加大一些,使用 ab 工具进行测试,运行命令 ab -n 100 -c 100 http://localhost:8000/,其中 -n 100 表示先后发送 100 次请求,-c 100 表示一次性发送的请求数目为 100 个。对比结果分析使用 Stream 后,有非常大的性能提升,小伙伴们可以自己实际操作看一下。
一个通过 Post 请求微信小程序的地址生成二维码的需求。
/** 微信生成二维码接口* params src 微信url / 其他图片请求链接* params localFilePath: 本地路径* params data: 微信请求参数* */const downloadFile=async (src, localFilePath, data)=> { try{ const ws = fs.createWriteStream(localFilePath); return new Promise((resolve, reject) => { ws.on('finish', () => { resolve(localFilePath); }); if (data) { request({ method: 'POST', uri: src, json: true, body: data }).pipe(ws); } else { request(src).pipe(ws); } }); }catch (e){ logger.error('wxdownloadFile error: ',e); throw e; }}看这段使用了 Stream 的代码,为本地文件对应的路径创建一个 Stream 对象,然后直接 .pipe(ws) ,将 Post 请求的数据流转到这个本地文件中,这种 Stream 的应用在 Node 后端开发过程中还是比较常用的。
Request 和 Reponse 一样,都是 Stream 对象,可以使用 Stream 的特性,二者的区别在于,我们再看一下水桶管道流转图,

Request 是 Source 类型,是图中的源头,而 Response 是 Dest 类型,是图中的目的地。在文件操作中使用 Stream
const fs = require('fs')const path = require('path')// 两个文件名const fileName1 = path.resolve(__dirname, 'data.txt')const fileName2 = path.resolve(__dirname, 'data-bak.txt')// 读取文件的 stream 对象const readStream = fs.createReadStream(fileName1)// 写入文件的 stream 对象const writeStream = fs.createWriteStream(fileName2)// 通过 pipe执行拷贝,数据流转readStream.pipe(writeStream)// 数据读取完成监听,即拷贝完成readStream.on('end', function () { console.log('拷贝完成')})看了这段代码,发现是不是拷贝好像很简单,创建一个可读数据流 readStream,一个可写数据流 writeStream,然后直接通过 Pipe 管道把数据流转过去。这种使用 Stream 的拷贝相比存文件的读写实现拷贝,性能要增加很多,所以小伙伴们在遇到文件操作的需求的时候,尽量先评估一下是否需要使用 Stream 实现。
目前一些比较火的前端打包构建工具,都是通过 Node.js 编写的,打包和构建的过程肯定是文件频繁操作的过程,离不来 Stream,例如现在比较火的 Gulp,有兴趣的小伙伴可以去看一下源码。
之前的文章都是围绕前两种可读数据流和可写数据流,第四种流不太常用,需要的小伙伴网上搜索一下,接下来对第三种数据流 Duplex Stream 说明一下。
Duplex Stream 双向的,既可读,又可写。 Duplex streams 同时实现了 Readable 和Writable 接口。 Duplex streams 的例子包括
我在项目中还未使用过双工流,一些 Duplex Stream 的内容可以参考这篇文章 NodeJS Stream 双工流(
https://www.cnblogs.com/dolphinX/p/6376615.html)
data .on('end', function() { console.log('data end'); }) .pipe(a) .on('end', function() { console.log('a end'); }) .pipe(b) .on('end', function() { console.log('b end'); });看完了这篇文章是不是对 Stream 有了一定的了解,并且知道了 Node 对于文件处理还是有完美的解决方案的。本文中三次展示了水桶管道流转图,总要的事情说三遍希望小伙伴们记住它,除了以上内容小伙伴们会不会有一些思考,比如
作者:大西轰已在服务区
链接:
https://juejin.im/post/5d25ce36f265da1ba84ab97a
著作权归作者所有。
感谢阅读,如果这篇文章对你又帮助,记得 点赞 ,收藏,转发 哟。
期待下次与你相遇 :)
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号