OpenAI o1的逻辑推理能力如何?全面解析其优势与不足!
发表时间: 2024-09-23 17:43
来源:AI 科技大本营(ID:rgznai100)
作者:Timothy B Lee
编译:Eric Harrington
GPT-4o 对象棋策略没有深刻的见解,但训练数据中却有足够多的国际象棋对局,所以至少可以猜测出一个看似合理的走法。
相比之下,o1 试图扮演人类,真正地去分析棋盘状态。而它做得如此糟糕,以至于最终吐出了完全无意义的内容。
去年 11 月的时候,外媒报道 OpenAI 前首席科学家 Ilya Sutskever(当时他还没离职)领导的团队取得了技术突破,有关 OpenAI 的 Q* 项目的消息也因此传出,该项目旨在构建能解决复杂数学问题的模型。
从此,全世界“妖魔化”了 Q* 的存在,有许多专家声称这就是 OpenAI 的 AGI(通用人工智能)项目,甚至还有一些 OpenAI 研究人员向董事会写了一封信,警告“一项强大的人工智能发现可能会威胁人类”。
这件事的结果就是,Ilya Sutskever 从此多了一个在外网爆火的梗:“Ilya 到底看到了什么?”(What did Ilya see?)
全球网友就像这样反复刷着表情包,每天都要在 OpenAI 官推底下质问 Ilya 为什么会对这个秘密 AI 项目讳莫如深,直到 Ilya 从 OpenAI 离职后也没消停。
终于,在 2024 年的上半年,外媒报道 Q* 项目重出江湖,并被重命名为“草莓”(Strawberry)。随后在九月上旬,OpenAI 揭示了他们一直秘密研究的这项内容:
更长的思维链
现在假设要求一个大模型预测序列“2+5+4+5-12+7-5=”中的下一个 token。这个确切的序列可能并未出现在大模型的训练集中,所以它不会想当然地给出答案。然而,如果我们要求模型“逐步思考”,它会产生类似这样的输出:
1. 从前两个数字开始:二加五等于七;
2. 加上下一个数字:七加四等于十一;
3. 加上下一个数字:十一加五等于十六;
4. 减去下一个数字:十六减十二等于四;
5. 加上下一个数字:四加七等于十一;
6. 减去最后一个数字:十一减五等于六。
以上就是 o1 模型的基本思路。假设用户给 o1 一个困难的推理问题,比如 OpenAI 的官方例子:
编写一个 bash 命令行脚本,该脚本接受一个以“[1,2],[3,4],[5,6]”格式表示的矩阵字符串,并以相同格式打印其转置矩阵。
这是一个编程任务,如果没有人工智能辅助,人类程序员可能需要三十分钟才能完成。而 o1 模型采用了类似于我上面给出的数学例子的方法:它将问题分解成更小的问题,然后逐个解决这些问题。以下是 o1-preview 在解决问题时的部分思考过程:
好的,让我们思考如何在 bash 中解析输入字符串,构建矩阵(可能使用数组),转置它,然后以预期格式输出结果转置矩阵……
方法:
- 解析输入字符串以提取矩阵元素;
- 将矩阵构建为数组的数组;
- 转置矩阵;
- 以相同格式输出转置后的矩阵。
实现步骤:
1. 将输入字符串作为参数捕获。
2. 移除任何空格(如果有的话)。
3. 解析输入字符串,将数字提取到数组中。
o1 像上述这样继续思考了大约八百字,然后产生了一个符合要求的 Bash 脚本。
这是 OpenAI 的官方示例,所以他们在博客里透露了具体的思维链细节。但在日常使用中,OpenAI 其实会对用户隐藏这个思考过程。这意味着用户通常需要等待模型思考三十秒、六十秒,甚至更长时间才能得到回应——就像一个人在解决复杂问题时需要时间思考一样。

要理解为什么 o1 模型如此强大,你需要了解模仿学习(Imitation Learning)和强化学习之间的区别。
在 Brian Christian 2020 年的著作《The Alignment Problem》中,讲述了计算机科学家 Stéphane Ross 在卡内基梅隆大学读研究生时的一个故事:2009 年,Ross 试图使用模仿学习来教导人工智能模型玩一款名为 SuperTuxKart 的卡丁车赛车游戏。研究人员想通过观察 Ross 玩游戏并模仿他的行为来训练神经网络玩 SuperTuxKart。但即使在数小时的游戏后,他的人工智能模型仍然难以保持在赛道上。
Christian 写道,问题在于“学习者看到的是专家解决问题的过程,而专家几乎从不遇到麻烦。但无论学习者多么优秀,他们都会犯错误——无论是明显的还是微妙的。但由于学习者从未看到专家陷入困境,他们也从未看到专家如何摆脱困境。”
当 Ross 玩游戏时,他大多将车保持在赛道中央附近,并指向正确的方向。因此,只要人工智能保持在赛道中央附近,它大多会做出正确的决定。
欢迎回顾 Brian Christian 在 CSDN《新程序员 007》的文章:《AI 对齐是未来十年最重要的科学和社会技术工程 | 新程序员》。
但偶尔,人工智能会犯一个小错误——比如说,向右偏离得太远。然后它就会处于一种与训练数据略有不同的情况。这会使它更有可能犯另一个错误——比如继续向右偏离。这会使车辆更加远离训练样本的分布。因此,错误往往会产生雪球效应,直到车辆完全偏离道路——就像一个初学者在学习骑自行车时,一个小的失衡可能导致完全的摔倒。
大模型也存在同样的问题。例如,去年年初,美国著名报纸《纽约时报》的记者 Kevin Roose 与一个基于 GPT-4 的早期微软聊天机器人聊了两个小时。随着时间的推移,对话变得越来越疯狂。最终,微软的聊天机器人竟然声称爱上了 Roose,并敦促他离开妻子。
从根本上说,这种情况的发生是因为传统的大模型是使用模仿学习进行训练的,而错误累积的问题意味着如果运行时间足够长,它们往往会偏离轨道——就像一个初学者在学习新技能时,一个小错误可能导致整个过程偏离正轨。在《纽约时报》的报道之后,微软限制了其聊天机器人可以进行的对话长度。
大模型偏离轨道的倾向在使用长思维链进行推理时尤其成问题。假设一个问题需要五十个步骤来解决,而模型在每个步骤都有百分之二的机会犯错。那么模型只有大约百分之三十六的机会(0.98^50)得到正确答案。
这里有另一种看待问题的方式:当大模型使用模仿学习进行训练时,如果它输出的恰好是训练数据中的下一个 token,就会得到正面强化。如果输出任何其他 token,就会得到负面强化。
这意味着训练算法将思维链推理过程中的所有 token 都视为同等重要,而实际上有些 token 比其他 token 重要得多。例如,如果一个模型需要计算“2+2”,在思维链推理过程中有许多有效的表达方式:

“真正通用”的强化学习
强化学习采取了不同的方法。强化学习不是试图完美地复制训练数据中的每个 token,而是根据它最终是否得到正确答案来评分响应。而且,随着推理步骤数量的增加,这种反馈变得越发重要。
那么,如果强化学习如此出色,为什么不是每个人都使用它呢?一个原因是,强化学习可能会遇到一个称为稀疏奖励(sparse rewards)的问题——即在整个学习过程中,有效的反馈信号很少。如果一个大模型只产生了答案中的一小部分 token,强化学习算法可能无法知道它是否正在朝着正确答案的方向前进。因此,完全使用强化学习训练的模型可能永远无法变得足够好以开始接收正面反馈。而无论有什么缺陷,模仿学习至少可以对每个 token 给出反馈。这使它成为训练初期的好选择,因为此时新生模型甚至无法产生连贯的句子。一旦模型能够有时产生良好的答案,那么强化学习就可以帮助它更快地改进。
另一个挑战是,强化学习需要一种客观的方式来判断模型的输出。当计算机科学家 Noam Brown 去年加入 OpenAI 参与“草莓”项目时,他在一系列推文中暗示了 OpenAI 的策略:
“多年来,我一直在研究人工智能自我对弈和在扑克和外交等游戏中的推理,”Brown 写道,“现在我将研究如何让这些方法真正通用。”
自我对弈指的是一个模型与自己的副本对弈的过程——就像一个人在下棋时自己和自己对弈。然后,游戏的胜负结果回被用于强化学习。因为软件可以确定谁赢了游戏,所以训练过程可以完全自动化,避免了昂贵的人工监督的需要。
Brown 指出 AlphaGo 作为 OpenAI 效仿的例子,这是一个使用自我对弈和强化学习训练的 DeepMind 系统。DeepMind 在 2016 年击败了世界上最好的人类围棋选手之一——这也是人工智能发展史上的一个里程碑。
像围棋或扑克这样的游戏有客观的规则来决定赢家。相比之下,判断大模型产生的 token 是否良好通常很困难。在某些领域,可能需要聘请昂贵的人类专家来评判模型的输出——比如诗歌,毕竟文无第一,有时难以分析好坏。
OpenAI o1 专注于数学和计算机编程中的推理问题。这些问题不仅有客观的正确答案,而且通常可以自动生成新的问题以及答案。这可以导致一个完全自动化的训练过程,类似于用于训练 AlphaGo 的自我对弈过程。
虽然 o1 在数学和科学推理方面有显著改进,但 o1 模型在推理能力上并不是“通用”的。例如,o1 在语言推理方面并没有明显优于其他前沿模型。我怀疑这是因为 OpenAI 团队还没有找到一种自动化的方法来生成他们需要的那种训练数据,以便在语言任务上进行强化学习。

你正在计划一个婚礼招待会,有五张桌子,每张桌子三位客人。
- Alice 不想和 Bethany、Ellen 或 Kimmie 坐在一起。
- Bethany 不想和 Margaret 坐在一起。
- Chuck 不想和 Nancy 坐在一起。
- Fiona 不想和 Henry 或 Chuck 坐在一起。
- Jason 不想和 Bethany 或 Donald 坐在一起。
- Grant 不想和 Ingrid、Nancy 或 Olivia 坐在一起。
- Henry 不想和 Olivia、Louise 或 Margaret 坐在一起。
- Louise 不想和 Margaret 或 Olivia 坐在一起。
你如何安排客人,以便所有这些偏好都得到尊重?
这是一个 NP-hard(非确定性多项式时间难解)问题,这意味着没有已知的算法可以有效地解决它,只能通过穷举试错来解决。当我要求 GPT-4o 解决这个问题时,它会开始像这样分配人员到桌子:
桌子 1:Alice、Chuck、Jason;
桌子 2:Bethany、Ellen、Kimmie;
桌子 3:Fiona、Ingrid、Donald...
到第三桌的时候,GPT-4o 的思考卡住了,因为只剩下两张桌子,而它还没有安排 Louise、Margaret 或 Henry 的座位——根据题干,这三个人都不想坐在一起。
按理来说,GPT-4o 应该回溯思考,调换前三张桌子上的人,以尝试解决冲突。但事实恰恰相反,GPT-4o 只是给出了最后两张桌子的分配,这些分配不符合要求,然后就此草草结束,给用户了一道错误答案。
相比之下,o1 思考了 35 秒,然后生成了以下正确的解决方案:
桌子 1:Alice、Donald、Fiona;
桌子 2:Grant、Bethany、Kimmie;
桌子 3:Henry、Chuck、Ellen;
桌子 4:Jason、Margaret、Olivia;
桌子 5:Louise、Ingrid、Nancy。
o1 模型通过试错找到了这个座位表。而根据 ChatGPT 放出的部分思维链(前文提到,OpenAI 不会给用户查看完整思维链),o1 有着这样的内心独白:“我重新考虑让 Jason、Margaret 和 Nancy 坐在桌子 4。Louise 的偏好使桌子 5 变得复杂,这表明需要进一步调整。” 也就是说,o1 和 GPT-4o 遇到了同样的问题,但它懂得尝试不同的排列,直到找到一个可行的方案。
我注意到大模型往往会被复杂性问题搞糊涂,所以我想知道 o1 是否能处理一个非常长的应用题,并写了一个 Perl 脚本来生成这样的故事:
Alice 把 1 个弹珠放进红色罐子里;
Frank 从有最多弹珠的罐子里拿出一个弹珠;
David 把 4 个弹珠放进蓝色罐子里;
Frank 又从蓝色罐子里拿出一半的弹珠,放进紫色罐子里;
然后,Frank 从蓝色罐子里拿出1个弹珠……
每个罐子里有多少个弹珠?
脚本可以让这个问题一直生成下去,所以我想测试模型会在第几步被搞糊涂。我发现 GPT-4o 可以解决最多约 50 步的这类问题,但它被 70 步的问题搞糊涂了。o1 模型则可以解决最多 200 步的问题,但在 250 步的时候会犯很多错误。
我觉得有趣的是,这个问题在概念上并不难。所有的模型都使用了相同的基本策略:逐行计算每个罐子里的弹珠数量。它们的区别在于随着问题规模的增长,保持“专注”的能力。o1 模型并不完美,但它在保持专注的方面比其他前沿模型要好得多——结果就是,o1 模型因此在推理能力上比 OpenAI 或其他公司之前的大语言模型强大得多。
然而,o1 并不完美,下面我会找一些它们仍然无法解决的问题。

o1 模型在空间推理方面表现不佳
这是少数几个让 GPT-4o 和 o1 模型都感到棘手的问题之一:
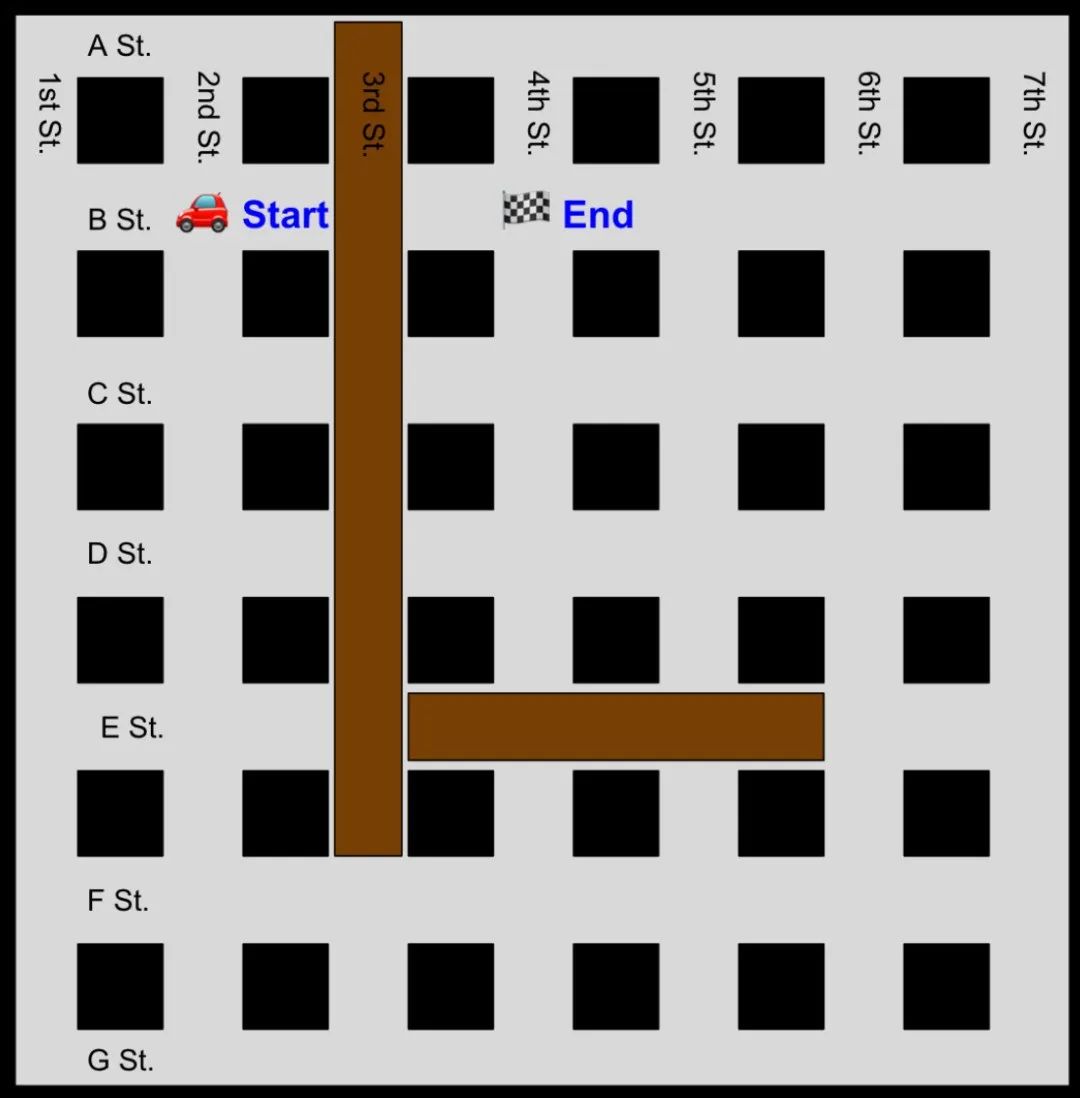
一个城市有七条南北向的街道,从西边的第一街到东边的第七街。它有七条东西向的街道,从北边的 A 街到南边的 G 街。第三街在 F 街以北被封闭,所以汽车不允许在 A、B、C、D 或 E 街上穿过第三街。E 街在第三街和第六街之间被封闭,汽车不允许在第四或第五街上穿过 E 街。从第二街和 B 街到第四街和 B 街的最短路线是什么?
o1 模型还不能接收图像输入,但读者们可以。所以我为大家绘制了这个场景的可视化图表,方便理解问题。
以下是 o1 的回答:
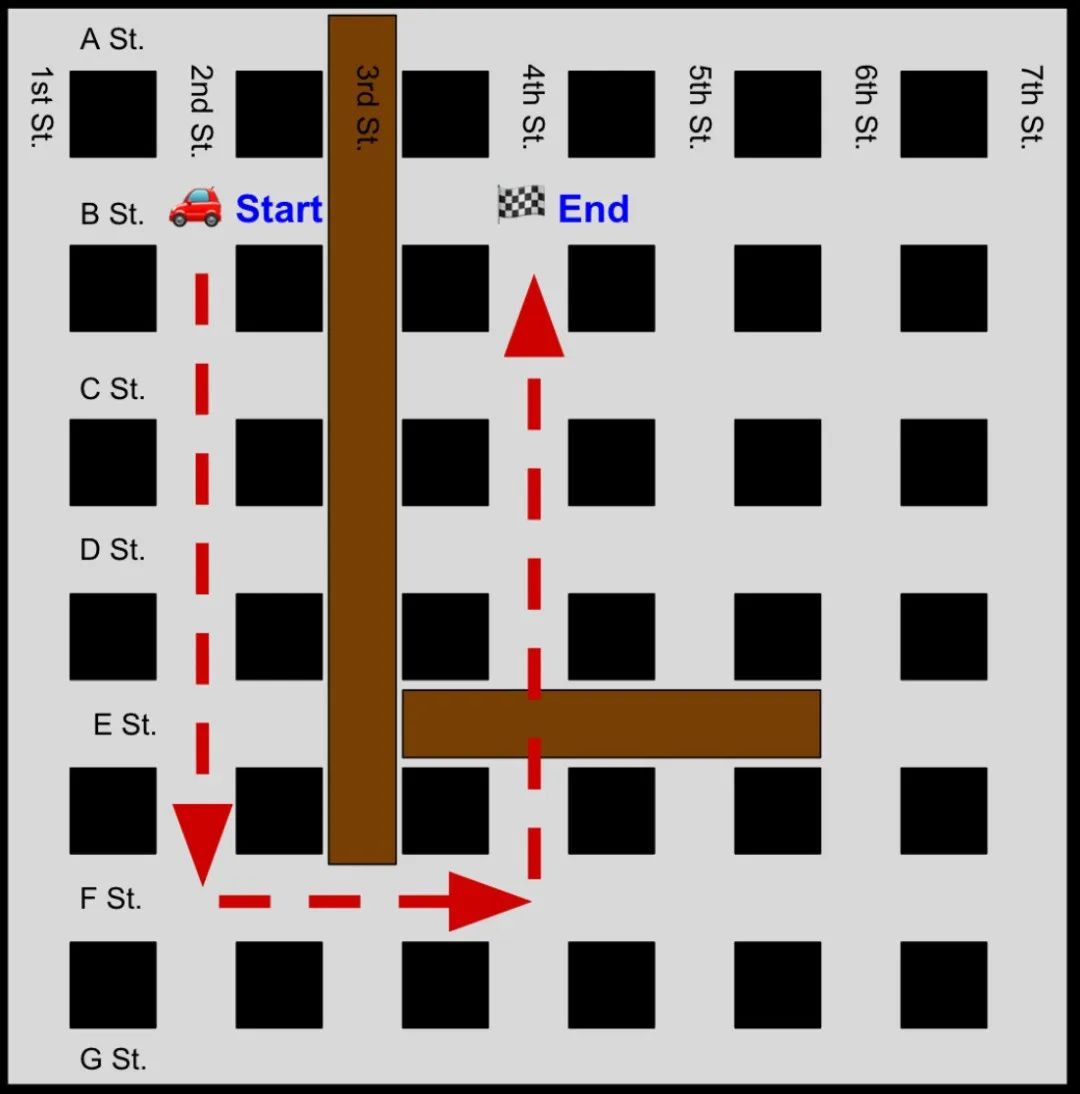
可能的路线:
直接路线(不可行):沿 B 街从第二街向东,到第四街 —— 不可行,因为由于封闭,你不能在 B 街上穿过第三街。
替代路线(可行且最短):
- 步骤 1:沿第二街向南,从 B 街到 F 街(向南 4 个街区)。
- 步骤 2:沿 F 街向东,从第二街到第四街,穿过第三街(向东 2 个街区)。
- 步骤 3:沿第四街向北,从 F 街到 B 街(向北 4 个街区)。
我们把 o1 给出的这条推荐路线画出来,看看到底行不行:
完全错了!而我们也测试了 GPT-4o,它也推荐了无效的路线。
o1 模型对国际象棋同样一无所知。问题如下:
一局标准的国际象棋游戏开局如下:
1. e4 e5
2. Qh5 Nf6
3. Qg6
黑方最强的走法是什么?



声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12




 鲁公网安备37020202000738号
鲁公网安备37020202000738号