芯片后端报告解读指南:前端工程师必读!
发表时间: 2019-02-10 21:19
(注:本篇文章内容,EETOP之前已推送过一次,看过的请略过)
来源:知乎 知乎作者:重走此间路 已获作者授权,感谢!
首先,我要强调,我不是做后端的,但是工作中经常遇到和做市场和芯片同事讨论PPA。这时,后端会拿出这样一个表格:
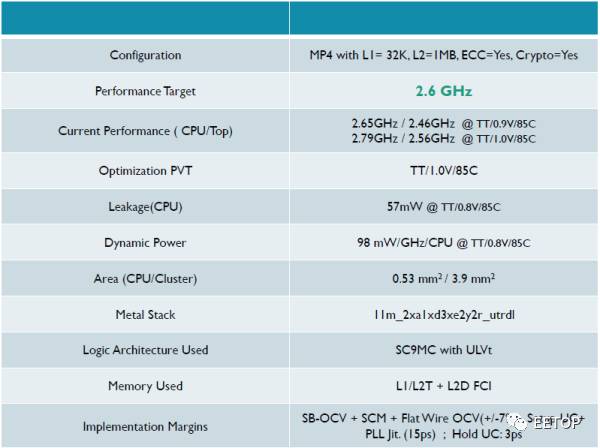
上图是一个A53的后端实现结果,节点是TSMC16FFLL+,我们就此来解读下。
首先,我们需要知道,作为一个有理想的手机芯片公司,可以选择的工厂并不多,台积电(TSMC),联电(UMC),三星,Global Foundries(GF),中芯(SMIC)也勉强算一个。还有,今年开始Intel工厂(ICF)也会开放给ARM处理器。事实上有人已经开始做了,只不过用的不是第三方的物理库。通常新工艺会选TSMC,然后要降成本的时候会去UMC。GF一直比较另类,保险起见不敢选,而三星不太理别人所以也没人理他。至于SMIC,嘿嘿,那需要有很高的理想才能选。
16nm的含义我就不具体说了,网上很多解释。而TSMC的16nm又分为很多小节点,FFLL+,FFC等。他们之间的最高频率,漏电,成本等会有一些区别,适合不同的芯片,比如手机芯片喜欢漏电低,成本低的,服务器喜欢频率高的,不一而足。
接下来看表格第一排,Configuration。这个最容易理解,使用了四核A53,一级数据缓存32KB,二级1MB,打开了ECC和加解密引擎。这几个选项会对面积产生较大影响,对频率和功耗也有较小影响。
接下来是Performance target,目标频率。后端工程师把频率称作Performance,在做后端实现时,必须在频率,功耗,面积(PPA)里选定一个主参数来作为主要优化目标。这个表格是专门为高性能A53做的,频率越高,面积和漏电就会越大,这是没法避免的。稍后我再贴个低功耗小面积的报告做对比。
下面是Current Performance,也就是现在实现了的频率。里面的TT/0.9V/85C是什么意思?我们知道,在一个晶圆(Wafer)上,不可能每点的电子漂移速度都是一样的,而电压,温度不同,它们的特性也会不同,我们把它们分类,就有了PVT(Process,Voltage, Temperature),分别对应于TT/0.9V/85C。而Process又有很多Conner,类似正态分布,TT只是其中之一,按照电子漂移速度还可以有SS,S,TT,F,FF等等。通常后端结果需要一个Signoff条件(我们这通常是SSG),按照这个条件出去流片,作为筛选门槛,之下的芯片就会不合格,跑不到所需的频率。所以条件设的越低,良率(Yield)就会越高。但是条件也不能设的太低,不然后端很难做,或者干脆方程无解,跑不出结果。X86上有个词叫体质,就是这个PVT。
这一栏有四个频率,上下两组容易区分,就是不同的电压。在频率确定时,动态功耗是电压的2次方,这个大家都知道。而左右两组数字的区别就是Corner了,分别为TT和SSG。
下一行是Optimization PVT。大家都知道后端EDA工具其实就是解方程,需要给他一个优化目标,它会自动找出最优局部解。而1.0V和0.9V中必须选一个值,作为最常用的频率,功耗和面积的甜点(Sweet Spot)。这里是选了1.0V,它的SSG和目标要求更接近,那些达不到的Corner可以作为降频贱卖。
再下一行是漏电Leakage,就是静态功耗。CPU停在那啥都不跑也会有这个功耗,它包含了四个CPU中的逻辑和一级缓存的漏电。但是A53本身是不包含二级缓存的,其他的一些小逻辑,比如SCU(Snooping Control Unit)也在CPU核之外,这些被称作Non-CPU,包含在MP4中。我们待机的时候就是看的它,可以通过power gating关掉二三级缓存,但是通常来说,不会全关,或者没法关。
下面是Dynamic Power,动态功耗。基本上我见过的CPU在测量动态功耗的时候,都是跑的Dhrystone。Dhrystone是个非常古老的跑分程序,基本上就是在做字符串拷贝,非常容易被软件,编译器和硬件优化,作为性能指标基本上只有MCU在看了。但是它有个好处,就是程序很小,数据量也少,可以只运行在一级缓存(如果有的话),这样二级缓存和它之后的电路全都只有漏电。虽然访问二级三级缓存甚至DDR会比访问一级缓存耗费更多的能量,但是它们的延迟也大,此时CPU流水线很可能陷入停顿。这样的后果就是Dhrystone能最大程度的消耗CPU核心逻辑的功耗,比访问二级以上缓存的程序都要高。所以通常都拿Dhrystone来作为CPU最大功耗指标。实际上,是可以写出比Dhrystone更耗电的程序的,称作Max Power Vector,做SoC功耗估算的时候会用上。
动态功耗和电压强相关。公式里面本身就是2次方,然后频率变化也和电压相关,在跨电压的时候就是三次方的关系了。所以别看1.0V只比0.72V高了39%,最终动态功耗可能是3倍。而频率高的时候,动态功耗占了绝大部分,所以电压不可小觑。
此外,动态功耗和温度相关,SoC运行的时候不可能温度维持在0度,所以功耗通常会拿85度或者更高来计算,这个就不多说了。
下一行是Area,面积。面积是芯片公司的立足之本,和毛利率直接相关。所以在性能符合的情况下,越小越好,甚至可以牺牲功耗,不惜推高电压,所以有了OD(Over Drive)。有个数据,当前28nm上,每个平方毫米差不多是10美分的成本,一个超低端的手机芯片怎么也得30mm(200块钱那种手机用的,可能你都没见过,还是智能机),芯片面积成本就是3刀,这还不算封测,储存和运输。低端的也得是40mm(300块的手机)。我们常见的600-700块钱的手机,其中六分之一成本是手机芯片。当然,反过来,也有人不缺钱的,比如苹果,据说A10在16nm上做到了125mm,换算成这里的A53MP4,单看面积不考虑功耗,足足可以放120个A53,极其奢侈,这可是跑在2.8G的A53,如果是1.5G的,150个都可能做到。
那苹果这么大的面积到底是做什么了?首先,像GPU,Video,Display,基带,ISP这些模块,都是可以轻易的拿面积换性能的,因为可以并行处理。而且,功耗也可以拿面积换,一个最简单的方法就是降频,增加处理单元数。这样漏电虽然增加,但是电压下降,动态功耗可以减少很多。一个例外就是CPU的单核性能,为什么苹果可以做到Kirin960的1.8倍,散热还能接受?和物理库,后端,前端,软件都有关系。
首先,A10是6发射,同时代的A73只用了2发射。当然,由于受到了数据和指令相关性限制,性能不是三倍提升,而6发射的后果是面积和功耗非线性增加。作为一个比较,我看过ARM的6发射CPU模型,同工艺下,单核每赫兹性能是A73的1.8倍,动态功耗估算超过2倍,面积也接近2倍。当然,它的微结构和A73是有挺大区别的。这个单核芯片跑在16nm,2.5Ghz,单核功耗差不多是1W。而手机芯片的功耗可以维持在2.5W不降频,所以苹果的2.3Ghz的A10算下来还是可行的。
为了控制功耗,在做RTL的时候就需要插入额外晶体管,做Clock Gating,而且这还是分级的,RTL级,模块级,系统级,信号时钟上也有(我看到的SoC时钟通常占了整个逻辑电路功耗的三分之一)。这样一套搞下来,面积起码大1/3.然后就是Power Gating,也是分级的。最简单的是每块缓存给一个开关,模块也有一个开关。复杂的根据不同指令,可以计算出哪些Cache bank短时间内不用,直接给它关了。Power Gating需要的延时会比Clock Gating大,有的时候如果操作很频繁,Power Gating反而得不偿失,这需要仔细的考量。而且,设计的越复杂,验证也就越难写,这里面需要做一个均衡。除了时钟域,电源域,还有电压域,可以根据不同频率调电压。当然了,域越多,布线越难,面积越大。
再往上,可以定义出不同的power state,让上层软件也参与经来,形成电源管理和调度。我在这个回答里面写的更详细一些:如何评价 ARM 的 big.LITTLE 大小核切换技术?
再回到苹果A10,它还使用了6MB的缓存。这个在手机里面也算大的惊世骇俗。通常高端的A73加2MB,A53加1MB,已经很高大上了,低端的加起来也不超过1MB。我拿SPECINT2K在A53做过一些实验,二级缓存从128KB增加到1MB只会增加15%不到的性能,到6MB那性能/面积收益更不是线性的,这是赤裸裸的面积换性能。而且苹果宣扬的不是SPECINT,而是GeekBench4.0,我怀疑是不是这个跑分对缓存大小更敏感,有空可以做做实验。顺带提一句,安兔兔5.0和缓存大小没半毛钱关系,这让广大高端手机芯片公司情何以堪。到了6.0似乎改了,我还没仔细研究过。至于使用了大面积缓存引起的漏电,倒是有办法解决,那就是部分关闭缓存,用多少开多少,是个精细活,需要软硬件同时配合。
影响面积的因素还没完,上面只是前端,后端还有一堆考量呢。
首先就是表格下一排,Metal Stack。芯片制造的时候是一层层蚀刻的,而蚀刻的时候需要一层层打码,免得关键部分见光,简称Mask。这里的11m就表示有11层。晶体管本身是在最底层的,而走线就得从上面走,层数越多越容易,做板子布线的同学肯定一看就明白了。照理说这就该多放几层,但是工厂跟你算钱也是按照层数来的,越多越贵。层数少了不光走线难,总体面积的利用率也低,像A53,11层做到80%的利用率就挺好了。所以芯片上不是把每个小模块面积求和就是总体面积,还得考虑布局布线(PR,Placing&Routing),考虑面积利用率。
再看表格下两排,Logic Architecture和Memory。这个也容易理解,就是逻辑和内存,数字电路的两大模块分类。这个内存是片上静态内存,不是外面的DDR。uLVT是什么意思呢,Ultra Low Voltage Threshold,指的是标准逻辑单元(Standard Cell)用了超低电压门限。电压低对于动态功耗当然是个好事,但是这个标准单元的漏电也很高,和频率是对数关系,也就是说,漏电每增加10倍,最高频率才增加log10%。后端可以给EDA工具设一个限制条件,比如只有不超过1%的需要冲频率的关键路径逻辑电路使用uLVT,其余都使用LVT,SVT或者HVT(电压依次升高,漏电减小),来减小总体漏电。
对于动态功耗,后端还可以定制晶体管的源极和漏极的长度,越窄的电流越大,漏电越高,相应的,最高频率就可以冲的更高。所以我们有时候还能看到uLVT C16,LVT C24之类的参数,这里的C就是指Channel Length。
接下去就是Memory,又作Memory Instance,也有人把它称作FCI(Fast Cache Instance)。访问Memory有三个重要参数,read,write和setup。这三个参数可以是同样的时间,也可以不一样。对于一级缓存来说基本用的是同样的时间,并且是一个时钟周期,而且这当中没法流水化。从A73开始,我看到后端的关键路径都是卡在访问一级缓存上。也就是说,这段路径能做多快,CPU就能跑到多快的频率,而一级缓存的大小也决定了索引的大小,越大就越慢,频率越低,所以ARM的高端CPU一级缓存都没超过64KB,这和后端紧密相关。当然,一级缓存增大带来的收益本身也会非线性减小。之后的二三级缓存,可以使用多周期访问,也可以使用多bank交替访问,大小也因此可以放到几百KB/几MB。
逻辑和内存统称为Physical Library,物理库,它是根据工厂给的每个工艺节点的物理开发包(PDK)设计的,而Library是一个Fabless芯片公司能做到的最底层。能够定制自己的成熟物理库,是这家公司后端领先的标志之一。
最后一行,Margin。这是指的工厂在生产过程中,肯定会产生偏差,而这行指标定义了偏差的范围。如下图:
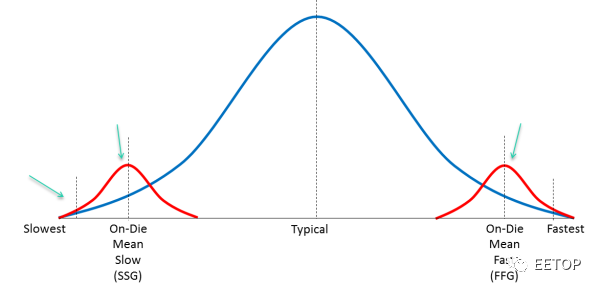
蓝色表示我们刚才说的一些Corner的分布,红色表示生产偏差Variation。必须做一些测试芯片来矫正这些偏差。SB-OCV表示stage-based on-chip variation,和其他的几个偏差加在一起,总共+-7%,也就是说会有7%的芯片不在后端设计结束时确定的结果之内。
后面还有一些setup UC之类的,表示信号建立时间,保持时间的不确定性(Uncertainty),以及PLL的抖动范围。
至此,一张报告解读完毕,我们再看看对应的低功耗版实现版本:
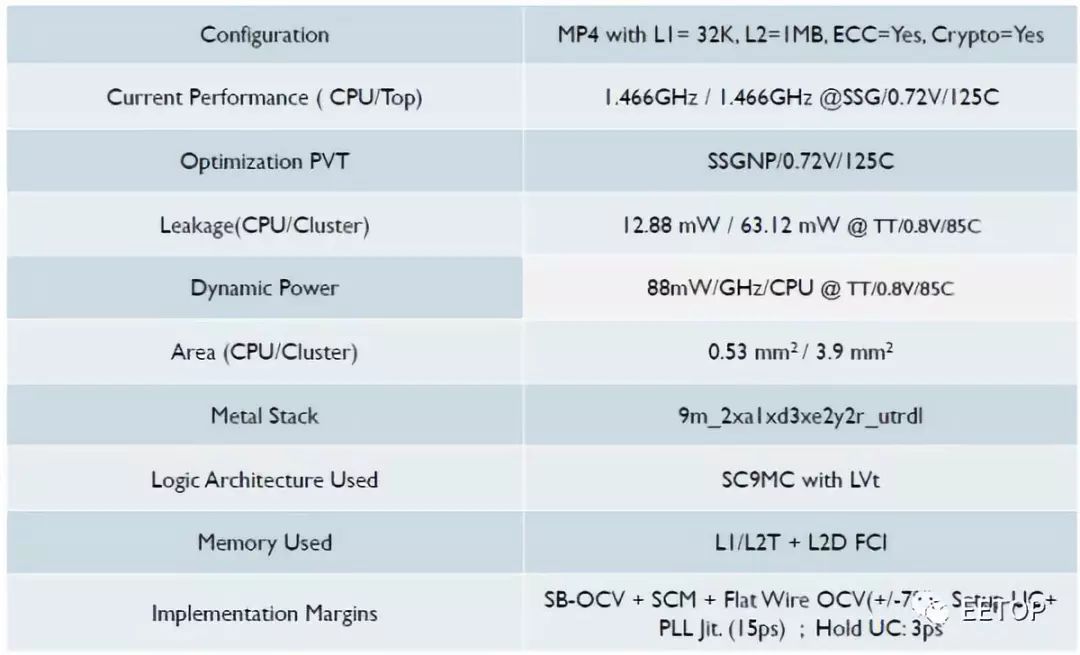
这里频率降到1.5G左右,每Ghz动态功耗少了10%,但是静态降到了12.88mW,只有25%。我们可以看到,这里使用了LVT,没有uLVT,这就是静态能够做低的原因之一。由于面积不是优化目标,它基本没变,这个也是可以理解的,因为Channel宽度没变,逻辑的面积没法变小。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号