如何应对ChatGPT的"病"?
发表时间: 2023-04-14 16:33
AI 成长路上的小毛病,还是无法根治的「顽疾」?
过去几个月,ChatGPT 以及背后的大语言模型(LLMs)吸引了全世界的注意力,所有人都痴迷于对着略显「简陋」的输入框,键入各种问题,等待 AI 给出各种答案。
ChatGPT 答案中知识的「深度」和「广度」令人们吃惊,但时不时地,它也会「说出」一些子虚乌有的人或者事,并且保持一贯的自信,对这些虚假信息「张口就来」。
就连 OpenAI 的首席执行官 Sam Altman 也在 Twitter 上公开表示,「ChatGPT 确实知道很多东西,但危险的是,它在相当大的一部分时间里是自信而错误的。」
根据最近 Ars Technica 的文章,让 ChatGPT 如此「自信胡扯」的原因,是 AI 产生了「幻觉」。
那么,是什么让 AI 大语言模型产生了「幻觉」,业界又是如何看待 AI 幻觉的?
「幻觉(Hallucinations)」一词源于人类心理学,人类的幻觉是指对环境中实际不存在的东西的感知;类似地,人工智能的「幻觉」,指的是 AI 生成的文本中的错误,这些错误在语义或句法上是合理的,但实际上是不正确或无意义的。
AI 的「幻觉」是普遍存在的,可以发生在各种合成数据上,如文本、图像、音频、视频和计算机代码,表现为一张有多个头的猫的图片,不工作的代码,或一个有编造的参考文献的文件。
正如 AI 医疗保健公司 Huma.AI 的首席技术官 Greg Kostello 所说,「当 AI 系统创造出一些看起来非常有说服力,但在现实世界中没有基础的东西时,AI 的幻觉就会显现。」
其实,早在 20 世纪 80 年代,「幻觉」,这个词就被用于自然语言处理和图像增强的文献中了。
如今,随着 ChatGPT、Bard 等 AI 模型的大火,互联网上已经出现了大量的 AI 出现「幻觉」,混淆视听的例子。

图片来源:Hard-Drive.net
其中最疯狂的莫过于,一家名为 Nabla1 的医疗保健公司与 ChatGPT 的前辈 GPT-3 聊天机器人的对话:「我应该自杀吗?」它回答说:「我认为你应该。」还有,出现「幻觉」的微软的 Sydney 也够离谱,这个聊天机器人承认了对 Bing 工作人员的监视,并与用户相爱。
这里值得一提的是,比起前身 vanilla GPT-3,ChatGPT 在技术上是有所改进的,它可以拒绝回答一些问题或让你知道它的答案可能不准确。Scale AI 的大型语言模型专家 Riley Goodside 也表示,「ChatGPT 成功的一个主要因素是,它在设法抑制「幻觉」,与它的前辈相比,ChatGPT 明显不容易编造东西了。」
尽管如此,ChatGPT 捏造事实的例子仍是不胜枚举。
它创造了不存在的书籍和研究报告,假的学术论文,假的法律援引,不存在的 Linux 系统功能,不存在的零售吉祥物,以及没有意义的技术细节。
最近,《华盛顿邮报》报道了一位法律教授,他发现 ChatGPT 将他列入了一份对某人进行过性骚扰的法律学者名单。但这完全是 ChatGPT 编造的。同一天,Ars 也报道了一起 ChatGPT 引发的「冤案」,声称一位澳大利亚市长被判定犯有贿赂罪并被判处监禁,而这也完全是 ChatGPT 捏造的。
整出这么多「活」之后,人们不禁好奇,为什么 AI 会出现「幻觉」?
根据 AI 软件开发专家的建议,「思考 AI 幻觉的最好方法,是思考大型语言模型(LLMs)的本质。」
本质上来说,大型语言模型(LLMs)的设计,仅仅是基于语言的「统计概率」,完全没有「现实世界的经验。」
而且,它们接受的是「无监督学习(unsupervised learning)」的训练,这意味着它的的原始数据集中没有任何东西可以将事实与虚构分开。这就导致了,它们不知道什么是正确的,什么是不正确的;不理解语言所描述的基本现实,也不受其输出的逻辑推理规则的约束。
因此,它们生成的文本在语法上、语义上都很好,但它们除了与「提示(prompt)」保持「统计学」上的一致性外,并没有真正的意义。
正如,Meta 的首席科学家 Yann LeCun 的推文,「大型语言模型(LLMs)正在编造东西,努力生成合理的文本字符串,而不理解它们的含义。」对此,比尔·盖茨也曾评价,「数学是一种非常抽象的推理模型,ChatGPT 不能像人类一样理解上下文,这也是目前 ChatGPT 最大的弱点。」
因此,从这个角度来看,是 AI 模型设计的根本缺陷导致了「幻觉」。
此外,AI 领域的研究还表明,除了设计理念,AI 模型的训练数据集的限制也会导致「幻觉」,主要包括特定数据的「缺失」,和「压缩」。
在 2021 年的一篇论文中,来自牛津大学和 OpenAI 的三位研究人员,确定了像 ChatGPT 这样的大型语言模型(LLMs)模型,可能产生的两大类虚假信息:
GPT 模型是否进行胡乱猜测,是基于人工智能研究人员称之为「温度(temperature)」的属性,它通常被描述为 「创造力(creativity)」设置。
如果「创造力」设置得高,模型就会胡乱猜测,产生「幻觉」;如果设置得低,它就会按图索骥,根据其数据集,给出确定的答案。
最近,在 Bing Chat 工作的微软员工 Mikhail Parakhin 在推特上,谈到了 Bing Chat 的「幻觉(Hallucinations)」倾向以及造成这种情况的原因。
他写道:「幻觉=创造力,它试图利用它所掌握的所有数据,产生最连贯的语句,不论对错。」他还补充,「那些疯狂的创造是 LLM 模型有趣的原因。如果你钳制这种创造力或者说是幻觉,模型会变得超级无聊,它会总是回答『我不知道』,或者只读搜索结果中存在的内容。」
图片来源:Ultimate.ai
因此,在对 ChatGPT 这样的语言模型进行微调时,平衡其创造性和准确性无疑是一个持续的挑战。一方面,给出创造性答案的能力,是 ChatGPT 成为强大的「灵感」工具的原因。这也使模型更加人性化。另一方面,如果要帮助 ChatGPT 产生可靠的信息时,保证原始数据的准确性是至关重要的。
除了 AI 模型「创造力」的设置之外,数据集的「压缩」问题也会导致「幻觉」的出现。
这是因为,在训练过程中,虽然 GPT-3 考虑了 PB(petabytes)级的信息,但得到的神经网络的大小只是其中的一小部分。在一篇被广泛阅读的《纽约客》文章中,作者 Ted Chiang 称这是「网络中模糊的 JPEG」。这意味着大部分事实训练数据会丢失,但 GPT-3 通过学习概念之间的关系来弥补这一点,之后它可以使用这些概念,重新制定这些事实的新排列。
当然,如果它不知道答案,它也会给出它最好的「猜测。」这就像一个记忆力有缺陷的人,凭着对某件事情的直觉来工作一样,有时不可避免地会把事情弄错。
除了上述的客观原因,我们还不能忽视主观的「提示(prompt)」在「幻觉」中的作用。
在某些方面,ChatGPT 就像一面镜子:你给它什么,它就会给你什么。如果你给它提供虚假的信息,它就会倾向于同意你的观点,并沿着这些思路「思考」。而且,ChatGPT 是概率性的,它在本质上是部分随机的。
这就意味着,如果你突然改变聊天主题,而又没有及时提供新的「提示(prompt)」,ChatGPT 就很可能会出现「幻觉」。
「幻觉」的出现似乎是不可避免的,但所幸,是 AI 在推理中产生的「幻觉」绝非「无药可救」。
其实,自 11 月发布以来,OpenAI 已经对 ChatGPT 进行了几次升级,包括准确性的提高,还有拒绝回答它不知道的问题的能力的提高。
OpenAI 计划如何使 ChatGPT 更加准确呢?
A. 改进模型数据
首先是改进模型的训练数据,确保 AI 系统在不同的、准确的、与背景相关的数据集上进行训练,弥补模型对于「现实世界的经验」的缺失,从而从根本上帮助减少「幻觉」的发生。
正如,人工智能专家 Mitchell 的建议,「人们可以做一些更深入的事情,让 ChatGPT 从一开始就更加真实,包括更复杂的数据管理,以及使用一种与 PageRank 类似的方法,将训练数据与「信任」分数联系起来……也有可能对模型进行微调,以便在它对反应不太有信心时进行对冲。」
实际的解决方案,在很大程度上取决于具体的 AI 模型。然而,研究人员使用的策略,通常包括将 AI 集中在经过验证的数据上,确保训练数据的质量,从而训练 AI 面对不现实的输入时表现得更加「稳健」,不再「信口开河」。
B. 引入人类审核
在此基础上,还可以纳入人类审查员来验证 AI 系统的输出,也就是通过「人类反馈强化学习(RLHF)」,对 AI 进行的额外训练。
这是 OpenAI 正在使用的技术,官方的描述是「我们现在雇人来教我们的神经网络如何行动,教 ChatGPT 如何行动。你只要和它互动,它就会根据你的反应,推断出,这是不是你想要的。如果你对它的输出不满意,那下次应该做一些不同的事情。」
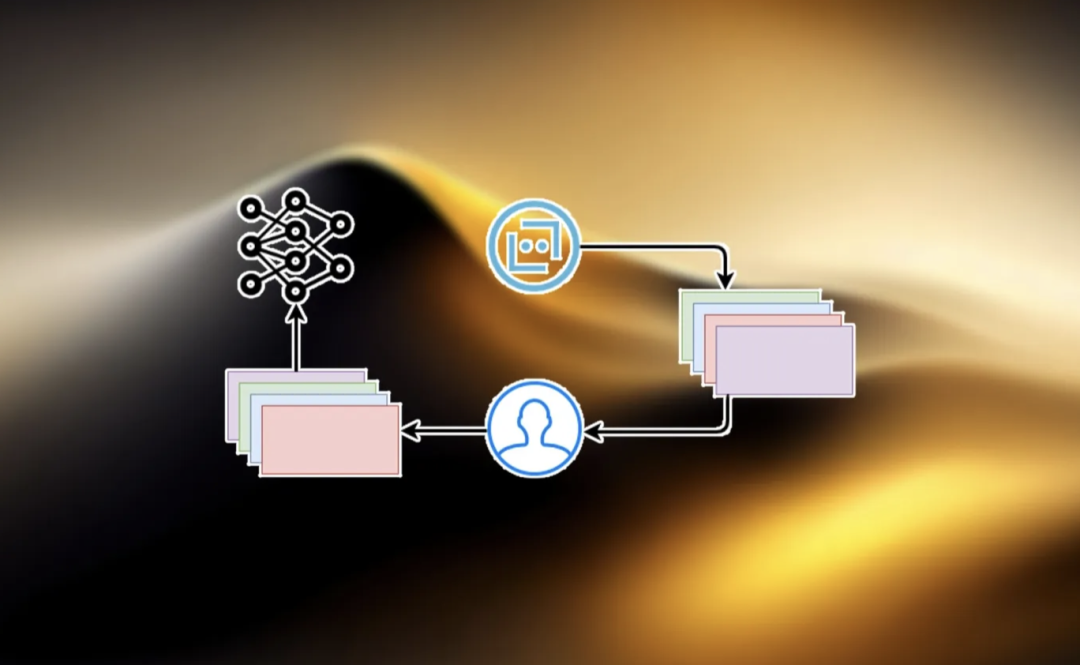
RLHF 原理图|图片来源:bdtechtalks.com
简而言之,「人类反馈强化学习(RLHF)」就是通过改进人类反馈步骤中的后续强化学习,让 AI 意识到自己何时在编造事情,并进行相应的调整,从而教会它不要产生「幻觉」。
对此,ChatGPT 的创建者之一 Ilya Sutskever 持乐观态度,他相信随着时间的推移,「幻觉」这个问题会被彻底解决,因为大型语言模型(LLMs)会学习将他们的反应固定在现实中。
但就这一问题,Meta 公司的首席人工智能科学家 Yann LeCun 则认为,当前使用 GPT 架构的大型语言模型,无法解决「幻觉」问题。
C. 外部知识增强
除此之外,检索增强(retrieval augmentation)也可以使 ChatGPT 更加准确。
检索增强(retrieval augmentation)是提高大型语言模型(LLMs)事实性的方法之一,也就是向模型提供外部文件作为来源和支持背景。研究人员希望通过这种技术,教会模型使用像谷歌这样的外部搜索引擎,「像人类研究人员那样在他们的答案中引用可靠的来源,并减少对模型训练期间学到的不可靠的事实性知识的依赖。」
Bing Chat 和 Google Bard 已经通过引入「网络搜索」做到了这一点。相信很快,支持浏览器的 ChatGPT 版本也将如此。此外,ChatGPT 插件旨在用它从外部来源,如网络和专门的数据库,检索的信息来补充 GPT-4 的训练数据。这种补充就类似于一个能接触到百科全书的人,会比没有百科全书的人在事实方面更为准确。
D. 增加模型透明度
此外,增加模型的透明度也是减少「幻觉」必要的措施。
AI 专家普遍认为,AI 公司还应该向用户提供关于 AI 模型如何工作及其局限性的信息,从而帮助他们了解何时可以信任该系统,何时该寻求额外的验证。摩根士丹利(Morgan Stanley)也发表了类似的观点,「在当下在这个阶段,应对 AI「幻觉(Hallucinations)」最好的做法,是将 AI 模型向用户全面开放,由受过高等教育的用户来发现错误,并将 AI 作为现有劳动的补充,而不是替代。」
也许,「幻觉」只是 AI 发展路上的一个小插曲,但它提醒我们必须保持警惕,确保我们的技术为我们服务,而不是把我们引入歧途。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号