数据结构学习笔记(二):深入理解算法与数据结构
发表时间: 2022-05-15 19:55
为什么要学习算法,无论从理论还是实践的角度,学习算法是必须的,因为它可以培养人们的分析能力,算法可以看作解决问题的一类特殊方法,它虽然不是问题的答案,但它是经过准确定义以获得答案的过程。所以,没有算法,就没有计算机程序。
大卫.柏林斯基说过,有两种思想,就像放在天鹅绒上的宝石那样熠熠生辉,一个是微积分,另一个是算法。微积分以及在微积分基础上建立起来的数据分析体系造就了现代科学,而算法则造就了现代世界。
那算法与数据结构有什么关系?数据结构指的是“一组数据的存储结构”,算法指的是“操作数据的一组方法”。数据结构是为算法服务的,算法是要作用在特定的数据结构上的。
1、算法定义
算法是一系列解决问题的明确指令,也就是说,对于符合一定规范的输入能够在有限时间内获得要求的输出。在计算机中表现为指令的有限序列,并且每条指令表示一个或多个操作。
算法有简单的,也有复杂的,如读小学时,老师就提出一道题,从1+2+3+4+5 .....一直加到10000的结果 ,看大家谁能最快算出来?
我们的一般的思维,就是:1+2+3,3+3=6,6+4=10......,结果老师刚说完,有一个小朋友就说:“老师,我算出来,50 005 000.”我们都很惊讶,他是怎么算出来的,这么快?原来他学习过高斯算法:
1 + 10000 = 10001
2 + 9999 = 10001
3 + 9998 = 10001
••••••,
5000 + 5001 = 10001
一共有多少组这样的结果,10000÷2=5000组,所以1到10000相加的结果可以这样计算:(10000)x (10000÷2) = 50005000。
这是数据领域的算法,但跟计算机领域的算法也有很多相似之处,如我们生活中:从A城市到B城市的最短路线?建立一栋房子如何合理安排工期?随机给大家发红包,如何实现它的算法?
我们从高斯算法中得知,好的算法,不但速度高效,节省资源,而且迅速得到得到我们想要的结果,因此学好数据结果和算法,就能帮助我们解决很多生活和工作中的问题。
2、算法的特性
(1)输入输出:输入是指算法具有零个或多个输入,有些输入,参数是必须的,但个别的输入,如打印“Hello”这个的代码,不需要任何参数;输出是指算法至少有一个或多个输出。
(2)有穷性:是指算法在执⾏有限的步骤之后,⾃动结束⽽不是出现⽆限循环,并且每⼀个步骤在可接受的时间内完成。
(3)确定性:是指算法执⾏的每⼀步骤在⼀定条件下只有⼀条执⾏路径,也就是相同输⼊只能有⼀个唯⼀的输出结果,不会出现二义性。
(4)可⾏性:是指算法每⼀步骤都必须可⾏,能够通过有限的执⾏次数完成。也就是说可行性意味着算法可以转换程序上机运行,并得到正确的结果。
3、算法的设计要求
(1)正确性:算法的正确性是指算法至少应该具有输入、输出和加工处理无歧义性、能正确反映问题的需求、能够得到问题的正确答案。
但是算法的“正确”通常在用法上有很大的差别,大体分为以下四个层次:
• 算法程序没有语法错误。
• 算法程序对于合法的输入数据能够产生满足要求的输出结果。
• 算法程序对于非法的输入数据能够得出满足规格说明的结果。
• 算法程序对于精心选择的,甚至故意刁难的测试数据都有满足要求的输出结果。
一般情况下,我们把第3点作为一个算法是否正确的标准。
(2)可读性:我们写代码的目的,一方面是为了让计算机执行,但还有一个重要目的是为了便于他人阅读,让人理解和交流,自己将来也能阅读,如果可读性不好,时间长了自己都不知道写了什么。可读性是算法(也包括实现它的代码)好坏很重要的标志。
(3)健壮性:当输入数据不合法时,算法也能做出相关处理,而不是产生异常或莫名其妙的结果。
(4)时间效率高和存储量低:生活中,我们都希望自己能做自己喜欢的事,又能早早实现财务自由。所以在设计算法时尽量考虑这两方面的问题,时间效率指的是算法的执行时间,对于同一个问题,如果有多个算法能够解决,执行时间短的算法效率高,反之效率低。存储量是指算法在执行过程中需要的最大存储空间,主要指算法程序运行时所占用的内存或外部硬盘存储空间。设计算法应该尽量满足时间效率高和存储量低的需求。
算法的设计取决于数据(逻辑)结构,算法的实现取决于所采用的存储结构。数据的存储结构本质上是其逻辑结构在计算机存储器中的实现。为了全面反映一个数据的逻辑结构,它在内存中的映像包括两个方面,即数据元素之间的信息和数据元素之间的关系。
不同的数据结构有相应的操作。数据的操作是在数据的逻辑结构上定义的操作算法,如检索、插入、删除、更新和排序。
4、算法效率的度量方法
度量算法效率的方法有两种:
(1)事后计算的方法,即先实现算法,然后运行程序,测算其时间和空间的消耗。这种度量方法有很多弊端,由于算法的运行与计算机的软硬件等环境因素有关,不容易发现算法本身的优劣。同样的算法用不同的编译器编译出的目标代码不一样多,完成算法所需的时间也不同,并且当计算机的存储空间小时,算法运行时间就会延长。
(2)事前分析估算的方法,这种度量方法是通过比较算法的复杂性来评价算法的优劣。算法的复杂性与计算机软硬件无关,仅与计算时间和存储需求有关。算法复杂性的度量可以分为空间复杂度度量和时间复杂度度量。经分析,一个高级语言编写的程序在计算机上运行所消耗的时间取决以下列因素:
• 算法采用的策略和方案
• 编译产生的代码质量
• 问题的输入规模
• 机器执行指令的速度
一般来说,要抛开某些与计算机硬件,软件有关的因素,一个程序的运行时间依赖于算法的好坏和问题的输入规模(输入量的多少)。因而研究算法的复杂度,侧重的是研究算法随着输入规模的扩大增长量的一个抽象,而不是精确的定位需要执行多少次。
所以,我们不关心编写程序所用的语言是什么,也不关心这些程序将跑在什么样的计算机上,我们只关心它所实现的算法。这样,不计算那些循环索引的递增和循环终止条件、变量声明、打印结果等操作。最终,在分析程序的运行时间时,最重要的是把程序看成是独立于程序设计语言的算法或一系列步骤。
5、函数的渐近增长
先看一个示例:
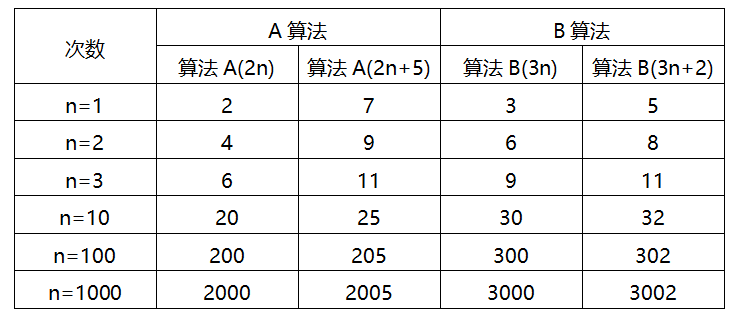
当n=1时,算法A效率不如算法B,而当n=2时,二者效率相同;当n>2时,算法A就开始优于算法B了,随着n的增长,算法A比算法B愈来愈好了。因而咱们能够得出结论,算法A整体上要比算法B好。
此时能够得出这样的结论:输入规模n在没有限制的状况下,只要超过一个数值N,这个函数就一直大于另外一个函数,这种情况称函数是渐近增加。
渐近增加函数的定义:给定两个函数f(n)和g(n),若是存在一个整数N,使得对于全部的n>N,f(n)老是比g(n)大,那么咱们说f(n)的增加渐近快于g(n)。
判断一个算法的效率时,函数中的常数和其余次要项经常能够忽略,如A(2n+5)后面的常数5,B(3n+2)后面的常数2都可以忽略不计,而更应该关注主项(最高阶项)n的阶数。
6、算法的时间复杂度
(1)算法时间复杂度定义
在进行算法分析时,程序语句总的执行次数 T(n)是关于问题规模n的函数,记作:T(n)=O(f(n))。它表示随着问题规模n的增大,算法执行时间的增长率和f(n)的增长率相同。叫做算法的渐近时间复杂度。也简称时间复杂度。
(2)求解算法的时间复杂度的具体步骤:
① 用常数1取代运行时间中的全部加法常数;
② 在修改后的运行次数函数中,只保留最高阶项;
③ 若是最高阶项存在且不是1,则去除与这个项相乘的常数。
(3)常数阶
如下面的例子,这个算法时间复杂度不是O(3),而是O(1)
int sum = 0,n = 100; //执行一次sum = (1 + n) * 100/ 2; //执行一次printf("%d",sum); //执行一次这个算法的运行次数函数是f(n)=3,根据咱们推导大O阶的方法,第一步就是把常数项3改成1。在保留最高阶项时发现,它根本就没有最高阶项,因此这个算法的时间复杂度为O(1)。
上面这种与问题大小无关(n的多少),执行时间恒定的算法,咱们称之为具备O(1)的时间复杂度,又叫常数阶。
(4)线性阶
如下面例子,这个算法的时间复杂度为O(n),由于循环体中的代码要执行n次:
int i,n;for(i = 0;i < n;i++) //执行n次{ int sum = 0,n = 100; //执行一次 sum = (1 + n) * 100/ 2; //执行一次}(5)对数阶
下面这个算法的时间复杂度为O(logn)
int sum = 1,n; //执行一次while(sum < n){sum = sum * 2; //执行一次}因为每次sum乘以2以后,就距离n更近了一分。也就是说,有多个2相乘后大于n,则会退出循环。由 2x= n 获得x =log2n。因此,这个循环的时间复杂度为O(logn)。
(6)平方阶
下面这个循环嵌套,它的时间复杂度是O(算法分析" style="width: 37px; height: 28px;">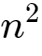
int i,j,n;for(i = 0; i < n; i++){ for(j = 0; j < n; j++){ sum = sum * 2; }}由于对于外层的循环,不过是内部时间复杂度为O(n)的语句,再循环n次,因此它的时间复杂度为O(算法分析" style="width: 37px; height: 28px;">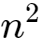
(7)常见的时间复杂度
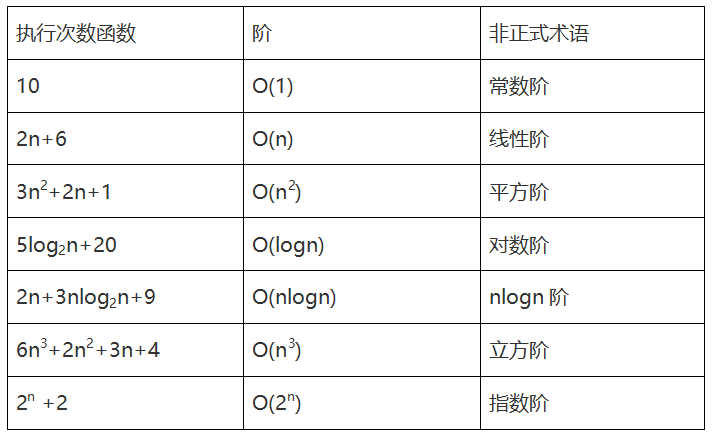
经常使用的时间复杂度所耗费的时间从小到大依次是:
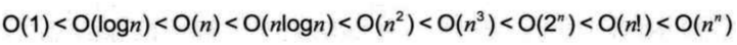
7、算法的空间复杂度
空间复杂度(Space Complexity)是对一个算法在运行过程中临时占用存储空间大小的量度。算法空间复杂度的计算公式为:S(n)=O(f(n))。其中,n为问题的规模,f(n)为语句关于n所占存储空间的函数。
一个算法在计算机存储器上所占用的存储空间,包括存储算法本身所占用的存储空间,算法的输入输出数据所占用的存储空间和算法在运行过程中临时占用的存储空间这三个方面。
存储算法本身所占用的存储空间与算法书写的长短成正比,要压缩这方面的存储空间,就必须编写出较短的算法。
算法的输入输出数据所占用的存储空间是由要解决的问题决定的,是通过参数表由调用函数传递而来的,它不随算法的不同而改变。
算法在运行过程中临时占用的存储空间随算法的不同而异,有的算法只需要占用少量的临时工作单元,而且不随问题规模的大小而改变,我们称这种算法是“就地"进行的,是节省存储的算法。有的算法需要占用的临时工作单元数与解决问题的规模n有关,它随着n的增大而增大,当n较大时,将占用较多的存储单元。如当一个算法的空间复杂度为一个常量,即不随被处理数据量n的大小而改变时,可表示为O(1);当一个算法的空间复杂度与以2为底的n的对数成正比时,可表示为O(log2n);当一个算法的空间复杂度与n成线性比例关系时,可表示为O(n)。
【参考文献】数据结构(C语言版)、大话数据结构、算法导论、算法设计与分析基础
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号