《Node.js应用故障排查手册:如何正确使用Chrome devtools》
发表时间: 2019-04-04 13:20
前面的预备章节中我们大致了解了如何在服务器上的 Node.js 应用出现问题时,从常规的错误日志、系统/进程指标以及兜底的核心转储这些角度来排查问题。这样就引出了下一个问题:我们知道进程的 CPU/Memory 高,或者拿到了进程 Crash 后的核心转储,要如何去进行分析定位到具体的 JavaScript 代码段。
其实 Chrome 自带的 Devtools,对于 JavaScript 代码的上述 CPU/Memory 问题有着很好的原生解析展示,本节会给大家做一些实用功能和指标的介绍(基于 Chrome v72,不同的版本间使用方式存在差异)。
本书首发在 Github,仓库地址:
https://github.com/aliyun-node/Node.js-Troubleshooting-Guide,云栖社区会同步更新。
I. 导出 JS 代码运行状态
当我们通过第一节中提到的系统/进程指标排查发现当前的 Node.js 应用的 CPU 特别高时,首先我们需要去通过一些方式将当前 Node.js 应用一段时间内的 JavaScript 代码运行状况 Dump 出来,这样子才能分析知道 CPU 高的原因。幸运的是,V8 引擎内部实现了一个 CPU Profiler 能够帮助我们完成一段时间内 JS 代码运行状态的导出,目前也有不少成熟的模块或者工具来帮我们完成这样的操作。
v8-profiler 是一个老牌的 Node.js 应用性能分析工具,它可以很方便地帮助开发者导出 JS 代码地运行状态,我们可以在项目目录执行如下命令安装此模块:
npm install v8-profiler --save
接着可以在代码中按照如下方式获取到 5s 内地 JS 代码运行状态:
'use strict';const v8Profiler = require('v8-profiler');const title = 'test';v8Profiler.startProfiling(title, true);setTimeout(() => { const profiler = v8Profiler.stopProfiling(title); profiler.delete(); console.log(profiler);}, 5000);那么我们可以看到,v8-profiler 模块帮我导出的代码运行状态实际上是一个很大的 JSON 对象,我们可以将这个 JSON 对象序列化为字符串后存储到文件:test.cpuprofile 。注意这里的文件名后缀必须为 .cpuprofile ,否则 Chrome devtools 是不识别的。
注意:v8-profiler 目前也处于年久失修的状态了,在 Node.js 8 和 Node.js 10 上已经无法正确编译安装了,如果你在 8 或者 10 的项目中想进行使用,可以试试看 v8-profiler-next。
II. 分析 CPU Profile 文件
借助于 v8-profiler 拿到我们的 Node.js 应用一段时间内的 JS 代码运行状态后,我们可以将其导入 Chrome devtools 中进行分析展示。
在 Chrome 72 中,分析我们 Dump 出来的 CPU Profile 的方法已经和之前有所不同了,默认工具栏中也不会展示 CPU Profile 的分析页面,我们需要通过点击工具栏右侧的 更多 按钮,然后选择 More tools -> JavaScript Profiler 来进入到 CPU 的分析页面,如下图所示:
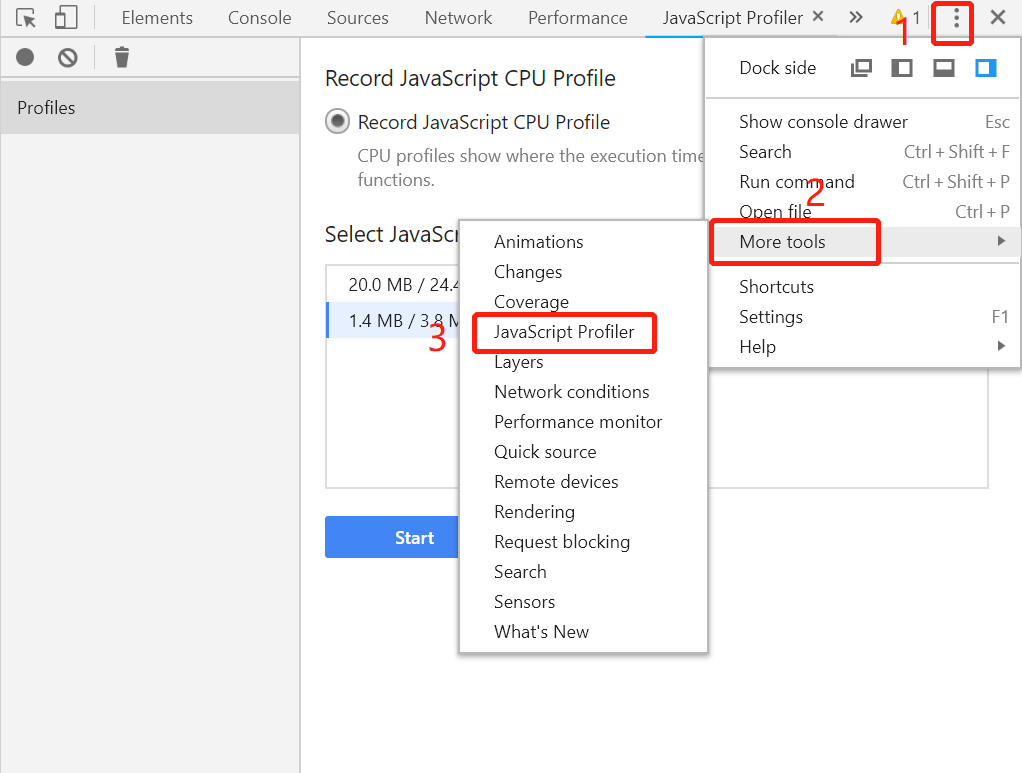
选中 JavaScript Profiler 后,在出现的页面上点击 Load 按钮,然后将刚才保存得到的 test.cpuprofile 文件加载进来,就可以看到 Chrome devtools 的解析结果了:
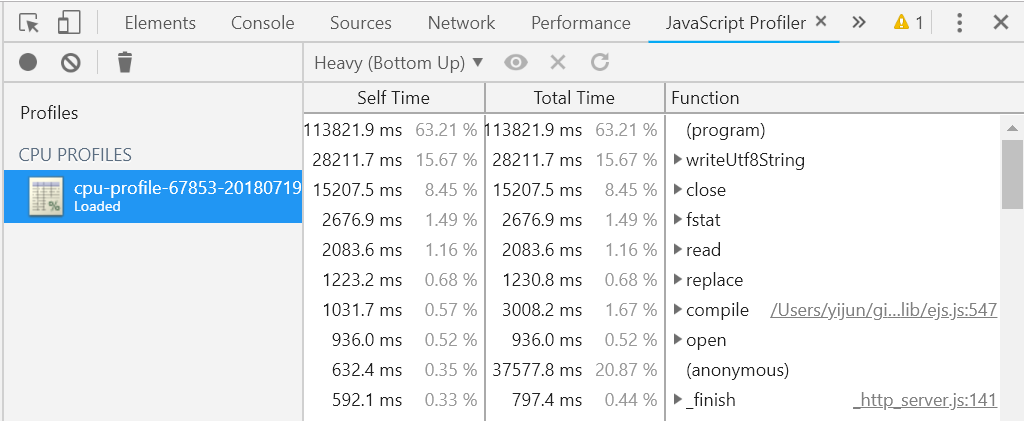
这里默认的视图是 Heavy 视图,在这个视图下,Devtools 会按照对你的应用的影响程度从高到低,将这些函数列举出来,点击展开能够看到这些列举出来的函数的全路径,方便你去代码中对应的位置进行排查。这里解释两个比较重要的指标,以便让大家能更有针对性地进行排查:
像在上述地截图例子中,ejs 模块在线上都应该开启了缓存,所以 ejs 模块的 compile 方法不应该出现在列表中,这显然是一个非常可疑的性能损耗点,需要我们去展开找到原因。
除了 Heavy 视图,Devtools 实际上还给我们提供了火焰图来进行更多维度的展示,点击左上角可以切换:
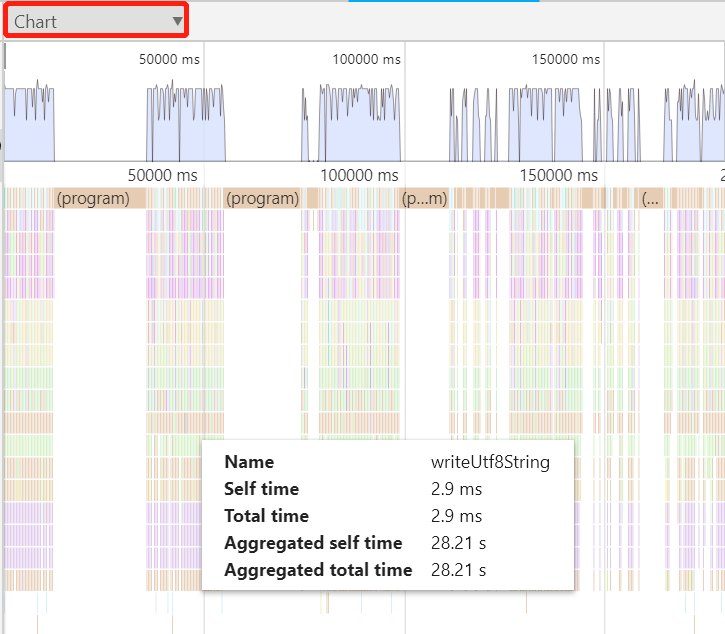
火焰图按照我们的 CPU 采样时间轴进行展示,那么在这里我们更容易看到我们的 Node.js 应用在采样期间 JS 代码的执行行为,新增的两个指标这边也给大家解释一下其含义:
综上,借助于 Chrome devtools 和能够导出当前 Node.js 应用 Javascript 代码运行状态的模块,我们已经可以比较完备地对应用服务异常时,排查定位到相应的 Node.js 进程 CPU 很高的情况进行排查和定位分析了。在生产实践中,这部分的 JS 代码的性能的分析往往也会用到新项目上线前的性能压测中,有兴趣的同学可以更深入地研究下。
I. 判断是否内存泄漏
在笔者的经历中,内存泄漏问题是 Node.js 在线上运行时出现的问题种类中的重灾区。尤其是三方库自身的 Bug 或者开发者使用不当引起的内存泄漏,会让很多的 Node.js 开发者感到束手无策。本节首先向读者介绍下,什么情况下我们的应用算是有很大的可能在发生内存泄漏呢?
实际上判断我们的线上 Node.js 应用是否有内存泄漏也非常简单:借助于大家各自公司的一些系统和进程监控工具,如果我们发现 Node.js 应用的总内存占用曲线 处于长时间的只增不降 ,并且堆内存按照趋势突破了 堆限制的 70% 了,那么基本上应用 很大可能 产生了泄漏。
当然事无绝对,如果确实应用的访问量(QPS)也在一直增长中,那么内存曲线只增不减也属于正常情况,如果确实因为 QPS 的不断增长导致堆内存超过堆限制的 70% 甚至 90%,此时我们需要考虑的扩容服务器来缓解内存问题。
II. 导出 JS 堆内存快照
如果确认了 Node.js 应用出现了内存泄漏的问题,那么和上面 CPU 的问题一样,我们需要通过一些办法导出 JS 内存快照(堆快照)来进行分析。V8 引擎同样在内部提供了接口可以直接将分配在 V8 堆上的 JS 对象导出来供开发者进行分析,这里我们采用 heapdump 这个模块,首先依旧是执行如下命令进行安装:
npm install heapdump --save
接着可以在代码中按照如下方法使用此模块:
'use sytrict';const heapdump = require('heapdump');heapdump.writeSnapshot('./test' + '.heapsnapshot');这样我们就在当前目录下得到了一个堆快照文件:test.heapsnapshot ,用文本编辑工具打开这个文件,可以看到其依旧是一个很大的 JSON 结构,同样这里的堆快照文件后缀必须为 .heapsnapshot ,否则 Chrome devtools 是不识别的。
III. 分析堆快照
在 Chrome devtools 的工具栏中选择 Memory 即可进入到分析页面,如下图所示:
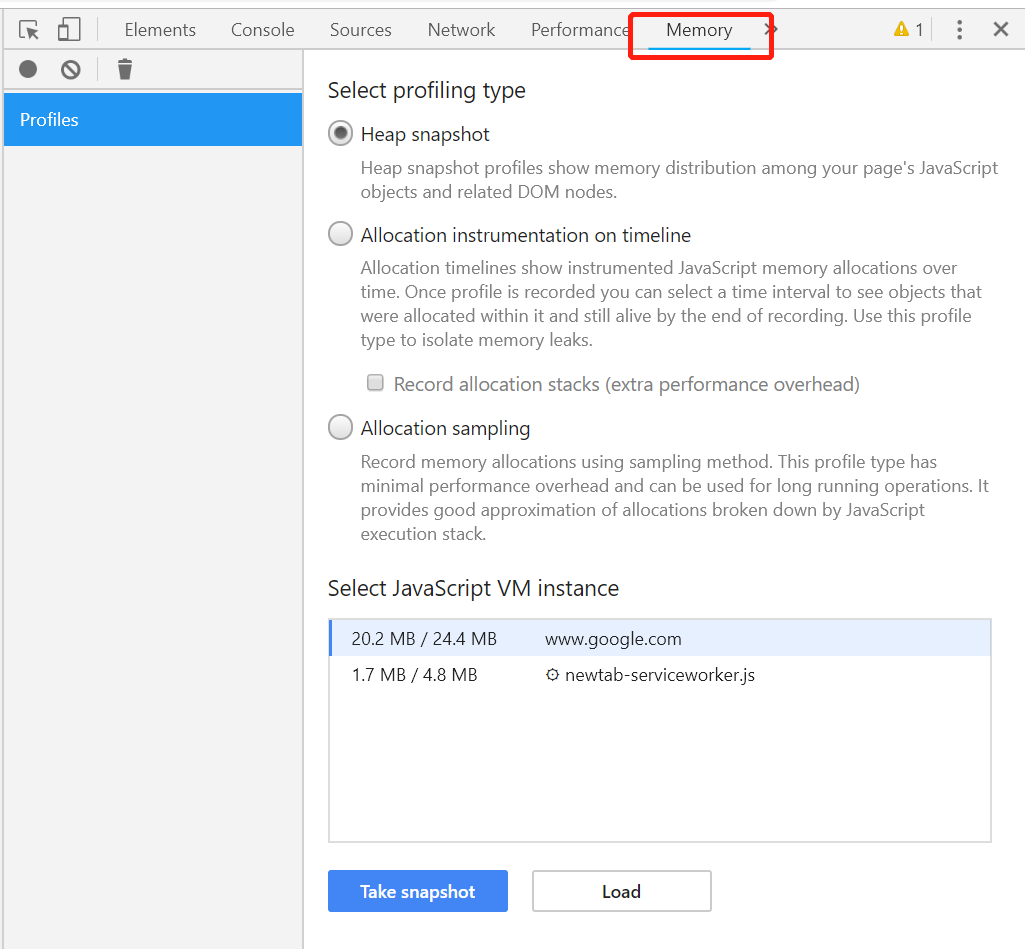
然后点击页面上的 Load 按钮,选择我们刚才生成 test.heapsnapshot 文件,就可以看到分析结果,如下图所示:
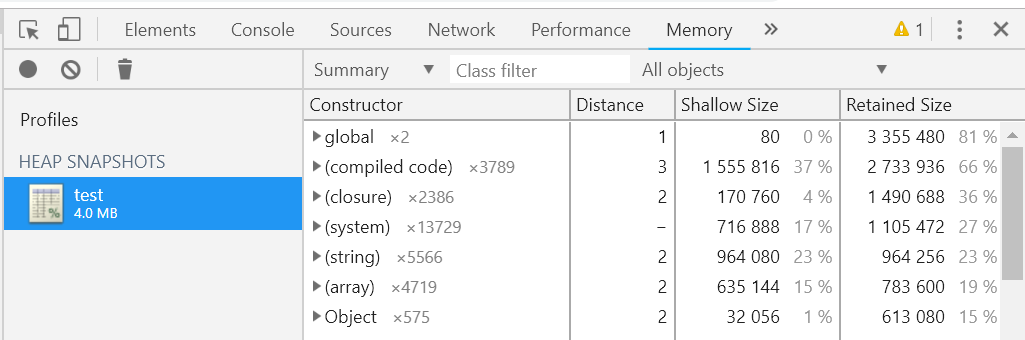
默认的视图其实是一个 Summary 视图,这里的 Constructor 和我们编写 JS 代码时的构造函数并无不同,都是指代此构造函数创建的对象,新版本的 Chrome devtools 中还在构造函数后面增加 * number 的信息,它代表这个构造函数创建的实例的个数。
实际上在堆快照的分析视图中,有两个非常重要的概念需要大家去理解,否则很可能拿到堆快照看着分析结果也无所适从,它们是 Shallow Size 和 Retained Size ,要更好地去理解这两个概念,我们需要先了解 支配树。首先我们看如下简化后的堆快照描述的内存关系图:
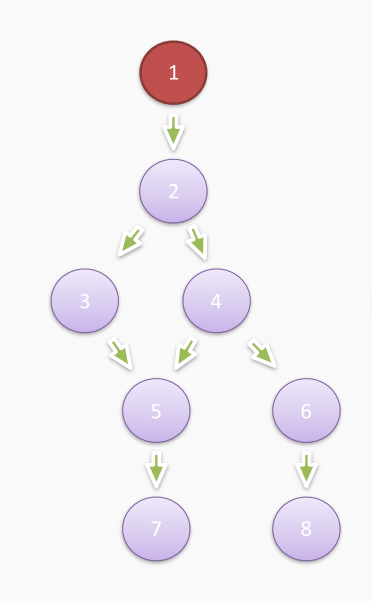
这里的 1 为根节点,即 GC 根,那么对于对象 5 来说,如果我们想要让对象 5 回收(即从 GC 根不可达),仅仅去掉对象 4 或者对象 3 对于对象 5 的引用是不够的,因为显然从根节点 1 可以分别从对象 3 或者对象 4 遍历到对象 5。因此我们只有去掉对象 2 才能将对象 5 回收,所以在上面这个图中,对象 5 的直接支配者是对象 2。照着这个思路,我们可以通过一定的算法将上述简化后的堆内存关系图转化为支配树:
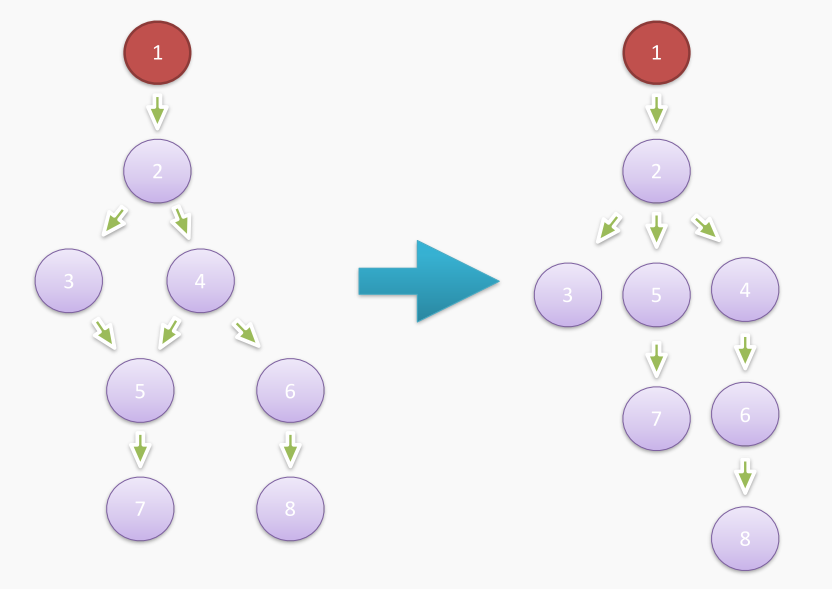
对象 1 到对象 8 间的支配关系描述如下:
好了,到这里我们可以开始解释什么是 Shallow Size 和 Retained Size 了,实际上对象的 Shallow Size 就是对象自身被创建时,在 V8 堆上分配的大小,结合上面的例子,即对象 1 到 8 自身的大小。对象的 Retained Size 则是把此对象从堆上拿掉,则 Full GC 后 V8 堆能够释放出的空间大小。同样结合上面的例子,支配树的叶子节点对象 3、对象 7 和对象 8 因为没有任何直接支配对象,因此其 Retained Size 等于其 Shallow Size。
将剩下的非叶子节点可以一一展开,为了篇幅描述方便,SZ_5表示对象 5 的 Shallow Size,RZ_5 表示对象 5 的 Retained Size,那么可以得到如下结果:
这里可以发现,GC 根的 Retained Size 等于堆上所有从此根出发可达对象的 Shallow Size 之和,这和我们的理解预期是相符合的,毕竟将 GC 根从堆上拿掉的话,原本就应当将从此根出发的所有对象都清理掉。
理解了这一点,回到我们最开始看到的默认总览视图中,正常来说,可能的泄漏对象往往其 Retained Size 特别大,我们可以在窗口中依据 Retained Size 进行排序来对那些占据了堆空间绝大部分的对象进行排查:
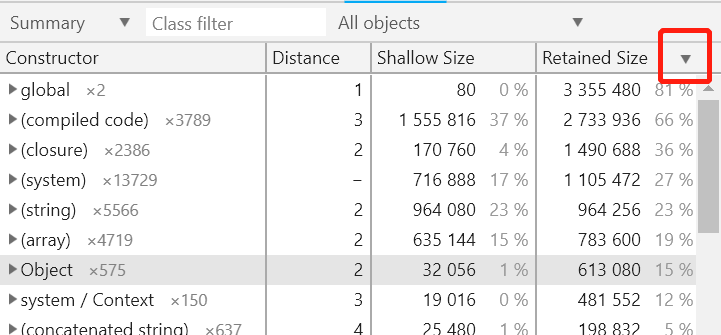
假如确认了可疑对象,Chrome devtools 中也会给你自动展开方便你去定位到代码段,下面以 NativeModule 这个构造器生成的对象 vm 为例:
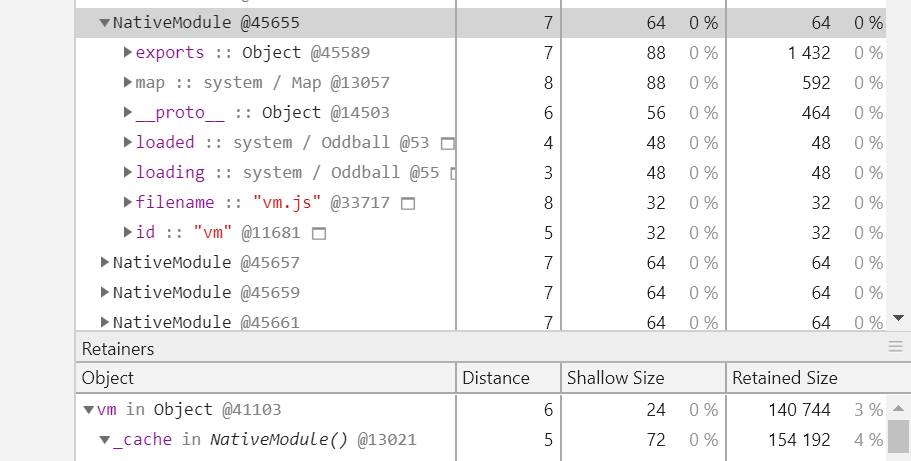
这里上半部分是顺序的引用关系,比如 NativeModule 实例 @45655 的 exports 属性指向了对象 @45589,filename 属性则指向一个字符串 "vm.js";下半部分则是反向的引用关系:NativeModule 实例 @13021 的 _cache 属性指向了 Object 实例 @41103,而 Object 实例 @41103 的 vm 属性指向了 NativeModule 实例 @45655。
如果对这部分展示图表比较晕的可以仔细看下上面的例子,因为找到可疑的泄漏对象,结合上图能看到此对象下的属性和值及其父引用关系链,绝大部分情况下我们就可以定位到生成可疑对象的 JS 代码段了。
实际上除了默认的 Summary 视图,Chrome devtools 还提供了 Containment 和 Statistics 视图,这里再看下 Containment 视图,选择堆快照解析页面的左上角可以进行切换,如下图所示:
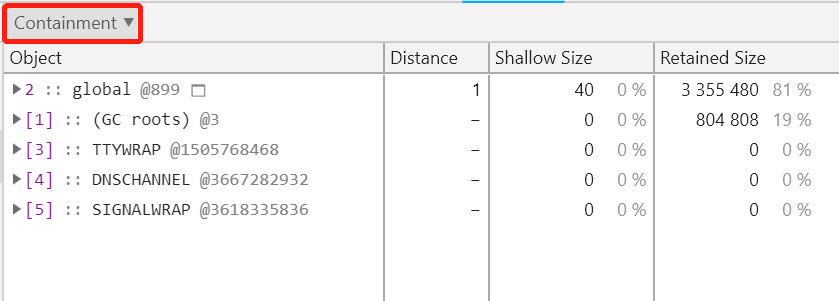
这个视图实际上是堆快照解析出来的内存关系图的直接展示,因此相比 Summary 视图,从这个视图中直接查找可疑的泄漏对象相对比较困难。
Chrome devtools 实际上是非常强大的一个工具,本节也只是仅仅介绍了对 CPU Profile 和堆快照解析能力的介绍和常用视图的使用指南,如果你仔细阅读了本节内容,面对服务器上定位到的 Node.js 应用 CPU 飙高或者内存泄漏这样的问题,想必就可以做到心中有数不慌乱了。
作者:奕钧
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号