你的数据库已经“云原生”了吗?
发表时间: 2020-11-17 10:58
2020 年 9 月 16 日,云原生数据库厂商 Snowflake 在纽交所上市,总市值超 700 亿美元,成为有史以来规模最大的软件 IPO,“云原生数据库”一词也随之成为炙手可热的话题。
“Snowflake 解决的需求本质上就是 Oracle、DB2 解决的需求,只不过时代和环境变了——市场需求在爆发,技术在更迭。核心是如何在云环境下保证弹性和扩展性的同时保证高性能。”偶数科技创始人常雷评价到。
偶数科技对标 Snowflake。11 月 4 日,偶数科技宣布完成金山云领投的 B 轮融资,成为国内第一家拿下独立云厂商投资的云原生数据库公司。近期,InfoQ 采访了偶数科技创始人 & CEO 常雷,就云原生数据库主题进行了深入交流,以飨读者。
读完本文你将收获:
云原生数据库的核心是存储与计算分离,同时还必须具备高性能、高可扩展、一致性、符合标准、容错、易于管理和多云支持等特性。
"数据库的本质是一个数据管理的工具,例如'关系型数据库'可以简单理解为装满了 Excel 表格的仓库。"常雷表示。
以网状数据库,关系型数据库,大数据应用(主要指 SQL-on-Hadoop 和 MPP 数据库)和云原生数据库为代表,数据库发展到今天经历了四个重要的时期。
20 世纪 70 年代巴赫曼的网状数据库创造了一种新的数据管理范式,正如巴赫曼本人在图灵奖颁奖演讲中所说——这是从地心说到日心说的变迁。
20 世纪 80 年代,埃德加·科德提出了关系型数据库并因此获得 1981 年图灵奖。关系型数据库模型简单明了,并且有坚实的数学基础,一度在学术界和产业界引起轰动。后来基于他的理论,诞生了很多世界级的数据库公司,比如一直占据全球过半数据库市场份额的 Oracle。
同样在 20 世纪 80 年代,为了满足企业级的数据分析需求,出现了数据仓库。典型代表有 Oracle、DB2、Teradata,虽然数仓的出现使得报表分析更加便捷,但传统数仓对云环境的支持很差,扩展困难,也没有存算分离的技术。
2000 年左右大数据开始出现并普及,SQL-on-Hadoop 和基于 X86 的 MPP 数据库成为大数据分析的热门应用。前者利用 HDFS 作为存储,节点规模可以扩展到数千,但单节点性能较差且 SQL 兼容性不好,典型代表如 Hive、SparkSQL;后者利用了高速的网络传输和分布式技术,将任务并行分散到多个节点,独立计算后汇总得出最终结果,单节点性能优良且能很好的兼容 SQL,但是节点扩展能力较差而且云环境支持不如 SQL-on-Hadoop,典型代表有 Greenplum 和 Vertica。
2015 年前后云原生数据库的出现,在“存算分离”的基础上结合 SQL-on-Hadoop 和 MPP 数据库的优点。弹性高可扩展,并具有优秀的性能、SQL 兼容性以及云环境的支持性。
OushuDB 正是这个时期的典型产品。偶数科技成立于 2016 年年底,创始人常雷是北大计算机系博士,毕业后供职于 EMC,致力于大数据和云计算方面的研究。
2011 年,由于 Hadoop 在扩展性方面的缺陷难以满足大数据时代的应用需求,常雷在一个研究课题中提出了新一代 SQL 引擎,这个引擎成为了 HAWQ 的前身。同年,EMC收购Greenplum,常雷加入 Greenplum 部门并组建数据库团队将 HAWQ 产品化。而后的 2015 年,HAWQ 捐赠到 Apache 基金会,成为中国第一个 Apache 数据库顶级项目。
“那时候 Hadoop 领域已经有两家上市公司,但都没有做的很好。从商业角度看,交易型(OLTP)数据库的需求本质是记录交易结果,因此仅记录最后一笔数据,而分析型数据库(OLAP)是帮助用户做业务决策,应用几乎无处不在。”常雷表示。之后的 2016 年,常雷认为时机已经成熟,便从 EMC 出走,创立了偶数科技。
由理论到实践,常雷完成了一个产品产业化的全过程,而后历经四年的创业实战,凭借 OushuDB 使得偶数科技成为云原生数据库的先锋。常雷认为,此时提出云原生数据库的定义是比较合适的。
“我喜欢看事物的本质,比如一个产品不管说的再好,我更关注它满足了什么需求。”常雷认为,云原生数据库是在公有云、私有云和混合云等新型动态环境中,基于存储与计算分离架构的,存储和计算可以独立弹性扩展的松散耦合数据库系统。同时,云原生数据库还需具有高性能、高可扩展、一致性保证、符合标准、容错、易于管理和多云支持等特性。
在“支持多云”这一特性上,为了让客户能享受中立的云数据库服务,我们会支持所有主流公有云平台。
2016 年,在成功将 HAWQ 产品化之后,常雷认为时机已经成熟,随后从 EMC 出走创立了偶数科技。如今 3 年多过去,偶数科技已发展成国内云原生数据库头部玩家,并且是第一个将产品卖到美国的国产云原生数据库公司。
OushuDB 包含计算层和存储层,存储和计算分离,可以独立扩容。
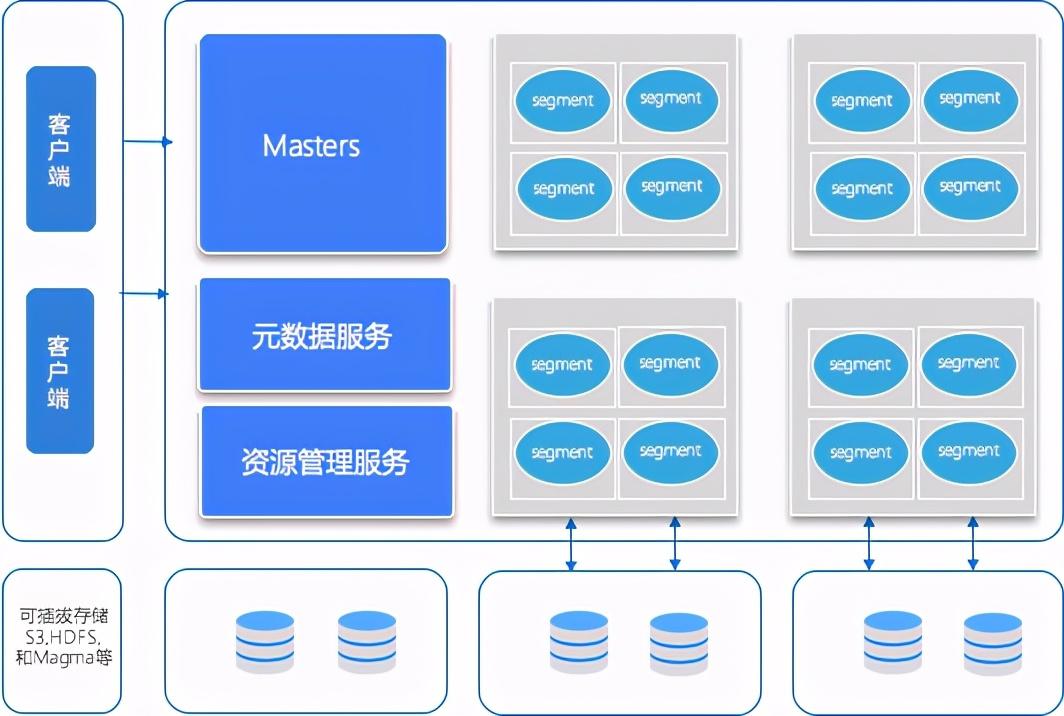
OushuDB 的计算层结构
一个 OushuDB 的计算层有多个 OushuDB Master 节点,内部包含了元数据管理服务和资源管理服务。其他节点为 Slave 节点,每个 Slave 节点上安装有一个 OushuDB Segment,用于实现 OushuDB 的计算。
在 OushuDB master 节点内部有几个重要组件:查询解析器(Parser/Analyzer),优化器,资源管理器,容错服务,查询派遣器,事务管理器,元数据服务。在查询执行时,针对一个查询,弹性执行引擎会启动多个虚拟 Segment 同时执行查询,节点间数据交换通过 Interconnect(高速互联网络)进行。
OushuDB Segment 在执行查询的时候会在资源容器中启动多个 QE (Query Executor, 查询执行器)。而节点可以动态的加入集群,并且不需要数据重新分布。当一个节点加入集群时,他会向 OushuDB Master 节点发送心跳,然后就可以接收未来查询了。
聊起 OushuDB 的特性,常雷脸上泛起一丝技术人特有的自豪,发自内心而略显腼腆。“OushuDB 的优点太多了,如果选 3 个的话,我认为是弹性,高性能和多云”。
作为工程师出身的创始人,常雷看待问题具有一种朴素实用的思维。“我喜欢看问题的本质和具体需求,而 OushuDB 的很多特性都是为了提高资源利用率,进而为客户降本增效。我认为一个优秀的云原生数据库应该具备良好的弹性扩展能力,而‘是否做到存储和计算的完全分离‘以及’产品执行引擎是否完全弹性’是判断一个云原生数据库的基本标准。只有具备这两点,一款数据库产品才能称得上真正发挥了上云的优势,才可以将数据和云更好地融合在一起,就可以说自己做好了云原生”。
自然数中奇数和偶数各占一半,偶数科技要做的就是要管理世界上一半的数据,这是一家伟大公司的使命所在。
目前,偶数科技客群分布在金融、运营商、能源和政府等多个行业,比如建设银行,中国移动、国家电网等。除此外也不乏一些跨国企业,比如全球分布式巨头 VMware 以及制造业巨头海尔集团。“我们的标杆客户中,一个非常有代表性的是美国的 VMware。首先,数据库作为刚需核心应用,涉及到企业数据管理最关键的存储环节。VMware 选择采购中国公司的产品,这本身就是一种突破;第二,VMware 是全球计算机软件巨头,本身拥有很强大的云计算团队,也很了解云原生数据库,选择 OushuDB 之前经历过严格的产品试用和采购评估环节。拿下 VMware 是偶数在获客道路上一次里程碑式的事件”。
VMware 过去利用 SAP HANA 做 BI 和报表分析。但当业务数据超过 100T 后,数据分析性能便难以满足需求。一开始 VMware 尝试使用 Greenplum 等经典的 MPP 数据库产品,但由于产品底层的存储和计算资源绑定,在集群弹性可扩展方面难以满足需求,只能继续寻求更合适的解决方案,后来曾尝试使用 Hive,但发现性能不满足需求。
2019 年,VMware 与偶数科技达成合作,应用数十个节点的 OushuDB 集群,运行在 VMware 的云平台上,处理对象存储中数百 TB 的数据。解决方案落地后,客户发现在同样节点集群和数百 TB 数据上,基于 OushuDB 的系统性能是 Hive 的数十倍,而且在不需要增加很多硬件的情况下,就可以完全满足 VMware 今后几年内数据持续增长条件下分析的时效性要求。
而且,由于 OushuDB 完善的遵从 ANSI SQL 标准(包括 SQL-92, SQL-99, SQL-2003)以及 OLAP 扩展函数,VMware 的数据科学家可以更容易地编写 SQL 语句,极大提升了系统的使用体验。
最终的客户收益主要有以下三个方面:
随着产品愈发成熟,大客户不断增多,近期偶数科技拿下了 B 轮融资。新一轮融资之后,偶数科技开始了更大力度的市场推广和拓客。正如常雷所言:“未来,偶数科技将通过新一代数据库技术解放人力,希望能管理全世界一半的数据,让企业决策易如反掌,并让更多人只为兴趣而工作”。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号