缓存穿透
高并发下查询一个值,缓存中没有,数据库中也没有,布隆过滤器
解决方案:
- 如果数据库中值为空,把空写入缓存即可。
- 也可以把所有的可能存在的key放入到一个大的Bitmap中,查询时通过该Bitmap过滤
缓存雪崩
缓存中大量数据同时到期,高并发下,所有请求都走向数据库
解决方案:
尽量不要把所有缓存都设置在同一时间过期, 通过加锁或者队列只允许一个线程查询数据库和写缓存, 其他线程等待.
通过加锁或者队列只允许一个线程查询数据库和写缓存,其他线程等待。
热点缓存(缓存击穿)
双重检测锁解决热点缓存问题,需要加volatile防止指令重排
高并发下,一个热点缓存到期,然后去数据库中去取,当还没有放入缓存中时,大量请求过来
解决方案:
Integer count = redis.get("key");if (count == null) { synchronized { count = redis.get("key"); if (count == null) { count = repo.getCount(); redis.put("key", count); } }}
if (redis.setnx(lockKey, requestId, NX, PX) == 1) {}
缓存双写一致性
解决方案:
延时双删策略, 先更新数据库,再删缓存
public void write(String key,Object data){ redis.delKey(key); db.updateData(data); Thread.sleep(1000); redis.delKey(key);}
Redis简介
Redis是一种用C语言开发的,高性能的,键值对key-value形式的noSql数据库
支持5种string, hash, set, list, 有序集合类型(sorted set, 简称zset)等数据类型
劣势就是存储的数据缺少结构化
应用场景:
- 内存数据库(登录信息,购物车信息,用户浏览记录)
- 缓存信息
- 解决分布式架构中的session分离问题
redis常用命令
- redis-server
- redis-client
- 性能测试工具redis-benchmarkredis-benchmark -q(Quiet. Just show query/sec values) -n(default 100000 requests)-h <hostname> Server hostname (default 127.0.0.1) -p <port> Server port (default 6379) -s <socket> Server socket (overrides host and port) -a <password> Password for Redis Auth -c <clients> Number of parallel connections (default 50) -n <requests> Total number of requests (default 100000) -d <size> Data size of SET/GET value in bytes (default 2) -dbnum <db> SELECT the specified db number (default 0) -k <boolean> 1=keep alive 0=reconnect (default 1) -r <keyspacelen> Use random keys for SET/GET/INCR, random values for SADD Using this option the benchmark will expand the string rand_int inside an argument with a 12 digits number in the specified range from 0 to keyspacelen-1. The substitution changes every time a command is executed. Default tests use this to hit random keys in the specified range. -P <numreq> Pipeline <numreq> requests. Default 1 (no pipeline). -q Quiet. Just show query/sec values --csv Output in CSV format -l Loop. Run the tests forever -t <tests> Only run the comma separated list of tests. The test names are the same as the ones produced as output. -I Idle mode. Just open N idle connections and wait.
- redis-check-aofaof文件检查的工具
- redis-check-dumprdb文件进行检查的工具
- redis-sentinel启动哨兵监控服务
redis数据类型及常用操作
- string set key value, get key, getset key value, incr key(必须为整数), incrby key increment, decr key, decrby incrementsetnx key value, append key value, strlen key, mset key1 value2 key2 value2..., mget key1, key2 ...
- hash散列类型,如(people --> name --> "chris")字段的名只能用stringhset key field value, hget key field, hmset ..., hsetnx key field value(同hset,但是如果field存在,则不执行任何操作),hmget 批量取, hdel key, hincrby key field increment, hexists key field, hkeys key, hvals key, hlen key, hgetall key
- list类型(链表实现的)lpush/rpush, lrange, lpop/rpop, llen, lrem key count value当count>0时,从左边开始删,删除在count范围内,值为value的元素当count<0时,从右边开始删当count=0时,删除所有值为value的元素lindex, lset key index value, ltrip key start stop, linsert key before|after "specified value" value, rpoplpush,
- set类型 不重复且没有顺序(指放入和取出的顺序不一致)sadd,srem key value, smembers key, sismember key value, sdiff A B(A - B), sinter A B(A ∩ B), sunion A B(A ∪ B),scard key(获取元素个数),spop(从集合中随机选择一个元素弹出)
- zset类型(为每个元素都关联一个分数) 有序集合和list对比相同点:两者都有序,两者都可以获得某一范围内的元素区别:列表访问两边数据很快,访问中间数据很慢。有序集合都很快有序列表可以调整元素位置,通过分数实现;有序集合耗内存zadd key score member, zrange/zrevrange key start stop [withscores],zscore key,zrem, zrangebyscore key min max, zincrby key increment member, zcard key(当前集合中元素数量)zcount key min max(指定分数范围内元素的个数), zremrangebyrank key start stop, zrank/zrevrank key member
- 通用命令keys, del, exists, expire key, ttl key(剩余生存时间), persist key(清除生存时间), pexpire key milliseconds(生存时间设置单位为毫秒), rname oldkey newkey, type key,
redis事务介绍(指一组命令的集合)
redis使用multi, exec, discard, watch, unwatch实现事务
redis不支持事务回滚
执行multi后,Redis会将命令逐个放入队列中,然后用exce执行这个队列中的命令
而watch是在multi之前,watch某个属性,表示我这个multi块中可能要修改该属性,如果multi块中的命令在未执行前有客户端修改了该请求,那么该multi块中的命令就会执行失败。
redis持久化(指的是持久化到磁盘)
redis持久化的方式有两种,RDB和AOF
RDB(redis默认方式)
rdb是使用快照(snapshotting)的方式进行持久化的
触发快照的时机
- 符合自定义的快照规则
- 执行save或者bgsave命令注: save命令是阻塞的,执行bgsave时会fork出一个进程进行保存,非阻塞的
- 执行flushall命令注:线上一般要禁止掉flushall(删除所有数据库的所有 key),flushdb(删除当前数据库的所有key), keys *等命令在redis配置文件中添加:rename-command FLUSHALL "" rename-command FLUSHDB "" rename-command KEYS ""
- 执行主从复制操作
redis获取所有数据库:
config get databases(默认有16个数据库,index从0开始)
select 0选择数据库
快照规则(或的关系)
save 900 1 “**15分钟内有1次修改就进行快照”**
save 300 10 “**5分钟内有10次修改就进行快照”**
save 60 10000 “**1分钟内有10000次修改就进行快照”**
dir ./ 指定快照地址(rdb文件地址)
dbfilename dump.rdb
快照过程
- Redis调用系统fork函数复制出一份当前进程的副本(子进程)
- 子进程开始将内存中的数据写入到硬盘中的临时文件
- 用临时文件替代旧的rdb文件(经过压缩的二进制文件)
优缺点
- 缺点: 一旦Redis异常退出,就将丢失最后一次快照后更改的所有数据
- 优点: rdb可以最大化Redis的性能
AOF
AOF: 每执行一条更改,Redis就会将该命令写入AOF文件. 实际上是先写入到硬盘缓存,然后通过硬盘缓存刷新机制保存到文件。
appendfsync always
appendfsync everysec(默认)
appendfsync no(由系统进行sync)
默认关闭,打开是appendonly yes
在数据量比较大的时候,频繁的写入和修改,aof文件会变得非常臃肿,所以我们可以设置重写规则:
- auto-aof-rewrite-min-size:64m
- auto-aof-rewrite-percentage:100
RDB 和 AOF比较
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。
数据库备份和灾难恢复
定时生成RDB 快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快。
Redis 支持同时开启 RDB 和 AOF,系统重启后,Redis 会优先使用 AOF 来恢复数据,这样丢失的数据会最少。
RDB 和 AOF ,我应该用哪一个
如果你非常关心你的数据,但仍然可以承受数分钟以内的数据丢失, 那么你可以只使用 RDB 持久。
AOF 将 Redis 执行的每一条命令追加到磁盘中,处理巨大的写入会降低 Redis 的性能,不知道你是否可以接受。
redis主从复制
- 只需要在从服务器的配置文件中添加:slaveof 192.168.1.123 6379
- 主从复制保证了即使有服务器宕机,也能保证对外提供服务。
- 当进行主从复制时,不会阻塞。
- 一个从服务器也可能是另一台服务器的主
原理:
分为全量同步和增量同步
- 全量同步是当第一次从服务器连接上主服务器时进行的同步,在全量同步期间,主服务器还会有新的写操作过来,这时候主服务器会把这些操作放入到缓冲区。master创建快照并发送给slave(将此期间的写入放入缓冲区)master向slave同步缓冲区的写操作命令同步增量阶段
- 增量同步是全量同步之后的一个正常操作的过程master每执行一个写操作,都会将该命令发送到slave
redis哨兵机制
- redis主从复制的缺点是当有Redis主服务器进行宕机时,不能进行动态的选举。需要使用Sentinel机制完成动态选举。
- 因此Sentinel进程的作用:监控master的状态(实际上也可以监控slave),在master宕机之后完成动态的选举。
- 如果有master或者slave宕机,可以通过脚本向管理员发送通知(短信或邮件)。即Monitoring 和 Notification.
- sentinel动态选举过程(Automatic failover):检测到master出现异常将其中一个slave复制为新的master当有slave请求master时返回新的master地址注: master和slave的redis.conf,和sentinel.conf都会发生变化,
- sentinel故障分析过程sentinel会以每秒1次的频率发送ping命令到Master, Slave 和 其他Sentinel若回复ping命令超时(sentinel.conf文件中指定的down-after-milliseconds),则该实例会被标记为SDOWN(主管下线)如果有足够数量(sentinel.conf中指定的)的Sentinel都将该实例标记为SDOWN,则该实例变为ODOWN
- 监控的主机名称为master,地址和IP,当有2个quorum认为mymaster失联时,则标记为ODOWN sentinel monitor mymaster 127.0.0.1 6379 2注意:虽然没有写监控slave,但是slave是被自动检测的虽然指定了ODOWN的数量,但是还是需要大多数的Sentinel同意来开启故障转移
sentinel一些配置
- port 26379(default)
- dir /tmp(工作目录)
- 当实例开启了requirepass foobared,需要在sentinel.conf中添加如下配置sentinel auth-pass <master-name> <password>sentinel down-after-milliseconds <master-name> <milliseconds>sentinel parallel-syncs <master-name> <numreplicas> 当master发生故障时,最多有几个slave同时对master进行更新
- sentinel failover-timeout mymaster 180000(这个超时时间有4种用途)所有slave对新的master进行更新时所需的最大时间,如果超过这个时间,则parallel-syncs无效,变为一次只能有一个更新同一个Sentinel对同一个master两次failover之间的间隔时间取消一个正在failover的实例所允许的最大时间(取消的前提是配置文件还未发生变化)slave从一个错误的master同步数据到纠正为从正确的master同步数据所需要的最大时间
- 脚本脚本返回1,则会重试,默认重试10次脚本返回值 > 2,不重试脚本执行中中断,则和返回1效果一样当一个脚本执行超过60秒,则会被一个SIGKILL信号终止,然后重试
- 通知型脚本sentinel notification-script mymaster /var/redis/notify.sh当系统有sdown或者ODOWN时会向管理员发送短信或邮件,该通知接收两个参数,事件类型和事件描述注:如果配置了该脚本,那么该脚本必须存在且是可执行的,否则无法启动Sentinel
- 客户端重新配置主节点参数脚本sentinel client-reconfig-script <master-name> <script-path>当master发生改变,执行该脚本通知客户端主机的新地这些参数将会被传递到该脚本:<master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>state 一直是 failoverrole 是 observer或者leaderfrom-:老的master的IP和端口号,to-:新的master的IP和端口号
Redis 集群
redis 集群保证了高可用
- Redis集群特点集群中的各个实例(节点)彼此互联,通过ping-pong机制节点失效判断(fail): 需要集群中所有的master投票, 经过半数以上的节点检测失效时才生效
- 客户端与Redis节点是直连,不需要经过任何代理
- Redis-cluster把所有物理节点映射到[0-16383]slot上,cluster负责维护node -- slot -- value注:redis集群内置了16384个slot,当客户端保存一个key-value时,redis先对key使用crc16算法算出一个结果,然后把结果对16384取余,Redis会把16384个slot均等的分配到各个节点上。每个节点都包含了一个各个node的信息
- 集群失效判断如果集群任意master挂掉,且该master没有slave时。集群挂掉。因为16384个hash槽不完整集群超过半数的master挂掉,不管是否有slave。
- 注: 为什么是16384个槽?(自我描述: redis对一个key进行crc16算法, 产生一个16位(bit)的hash值, 那么该算法可以产生65536个值, 但为什么不是65536个槽, 而是16384个槽呢? 原因有几点: 1. 与Redis的心跳机制有关, redis两个节点在发生心跳的时候, 消息头中包含如myslots[CLUSTER_SLOTS/8], 所以如果发送65536个这样的信息, 就需要65536 * 8 * 1024 = 8K, 太大, 浪费带宽; 2. 实际16384个槽已经足够用, 因为当redis的节点超过1000时, 整个集群的效率会非常低, 会造成网络拥堵. 因此作者建议不要超过1000个节点)
客户端连接集群
- ./redis-cli -h 127.0.0.1 -p 7001 -c
- 添加新的节点:./redis-trib.rb add-node 127.0.0.1:7007 127.0.0.1:7001./redis-trib.rb reshard 127.0.0.1:7001(连接上任一节点即可)./redis-trib.rb add-node --slave --master-id 主节点id 新节点的IP和端口 旧节点ip和端口(集群中任一节点都可以)
redis实现分布式锁
- 单应用一般用synchronize,ReentrantLock实现锁
- 分布式分布式锁注意事项:互斥性:即在任一时刻只有一个客户端能持有锁同一性:加锁和解锁必须是同一客户端可重入性:即使一个客户端没有主动解锁(崩溃等),也能保证后续其他客户端能加锁(超时时间)
- 基于数据库的乐观锁实现分布式锁
- zookeeper临时节点的分布式锁
- 基于Redis的分布式锁使用set key value [ex seconds] [px milliseconds] [NX|XX]ex和px都表示过期时间,单位不一样NX是在不存在时设置,XX是在存在时设置public static boolean getLock(String lockKey, String requestId, int expireTime) {
String result = jedis.set(lockKey, requestId, "NX", "EX", expireTime);
return "OK".equals(result);
}释放锁public static void releaseLock(String requestId, String lockKey) {
if (requestId.equals(jedis.get(lockKey))) {
jedis.del(lockKey);
}
}
redis 过期策略
- 定期删除+ 惰性删除 + 内存淘汰机制定期删除: Redis默认是每隔100ms就随机抽取一些设置了过期时间的key. 假如redis中有100万个key, 都设置了过期时间,那么肯定不会每隔100毫秒就遍历100万个key然后删除过期了的key. 当get某个key的时候, redis会检测该key有没有过期, 如果过期,就删除, 然后返回空.这就是惰性删除. 但是内存中如果有10万个key没有被访问到, 不可能让他们长期在内存中消耗内存, 这时候就需要走内存淘汰机制内存淘汰机制: noeviction:当内存不足以容纳新写入数据时,新写入操作会报错,这个一般没人用吧allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key,这个一般没人用吧volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key(这个一般不太合适)volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个keyvolatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除
redis cluster对mget的操作
Redis cluster不支持mget操作. 最初是facebook, 2010年使用memcache作缓存, 共有3000个节点. 发现节点太多, 连接频率下降. 继续增加节点, 并没有改善, 是因为IO的成本已经超过数据传输.
所以redis cluster也因此不支持mget操作.redis引入cluster模式后, 是将数据hash到16384个slot上, 每个node负责一部分slot.
mget优化方案:
- n个key, 传统IO, 分别获取, 时间复杂度为O(n)
- n个key, 通过Redis的hash算法可以得出各个key所对应的节点, 这样时间复杂度就位O(node.size())
- 在B方案的基础之上并发处理
redis的redlock
- redlock的前提是有N个redis的master, 这些节点之间没有主从复制, 或者其他集群协调机制.
- client从N个节点尝试获取锁, 只要有N/2 + 1个节点获取成功, 那么便获取成功; 如果最终获取失败, 客户端应该在所有的节点上进行解锁.
- redlock的出发点是为了解决Redis集群环境下, 出现的分布式锁的问题(client1获取锁, master 宕机, slave变成master, client2获取到锁). 但是redlock的出现并没有解决这样的问题.
Martin和Redis作者antirez之间的争辩:
martin挑了两个缺点:
1. 对于提升效率的场景, redlock太重
2. 对于正确性要求极高的场景, redlock并不能保证正确性;
问题: 在client1获取锁之后, 由于某种原因发生系统停顿, 锁过期, 然后client1执行操作; client2这时候也会拿到锁, 就会出现问题)
问题: A, B, C, D, E 5个redis节点,如果C的时间走得快, client1拿到锁(A, B, C), C节点先过期, client2又拿到了(C, D, E)这样就出问题了;
所以Redis从根本上来说是AP, 而分布式锁是要求CP的.
redis各种数据类型的数据结构
Redis的底层数据结构
- 简单动态字符串sds(Simple Dynamic String)
- 双端链表(LinkedList)
- 字典(Map)
- 跳跃表(SkipList)
redis各种数据类型使用的数据结构
- String, SDS(simple dynamic string) 简单动态字符串, 包含len(字符串长度), free(空闲的字节数量), buf(字节数组,存储数据)
- List, 使用压缩列表(数据集比较少的时候, 列表中单个数据小于64字节或者列表中数据个数少于512个)和双向循环链表, 包含pre, next, value
- hash, 使用压缩列表(键和值的大小小于64字节, 列表中键值对个数小于512个)和散列表
- Set, 有序数组(个数不超过512)和散列表
- Zset, 压缩列表(数据小于64字节或者个数小于128个)和跳跃表
用ziplist代替key-value减少80%内存占用的案例
背景: 因业务原因, 需要大量存储key-value数据, key和value都为string, 如果存储1千万条数据,占用了redis共计1.17G的内存. 当数据量变成1个亿时,实测大约占用8个G. 但是修改为key(int), value 为ziplist时, 内存占用为123M, 减少了85%.
步骤:
- 要将1千万个键值对, 放到N个bucket中, 但是为了防止ziplist变为hashtable, 每个bucket不能超过512个键值对, 1千万 / 512 = 19531. 将所有key hash到所有bucket中, 但由于hash函数的不确定性, 可能出现不均等分配, 可以分配25000个bucket, 或者30000个bucket.
- 选用hash算法, 决定将key放到哪个bucket. 这里我们采用高效而且均衡的知名算法crc32. 通过获取原有md5(key)的crc32后, 再对bucket的数量进行取余.
- 第2步确定了外层的key, 内部的field我们选用bkdr哈希算法. public static int BKDRHash(String str) {
int seed = 131;
int hash = 0;
for (int i = 0; i < str.length; i++) {
hash = (hash * seed) + str.charAt(i);
}
return (hash & 0X7FFFFFFF);
} - 测试装入1000万条数据, 内存降低了85%; 查询测试, 查100万条数据, 对比查询速度: key-value耗时:10653、10790、11318、9900、11270、11029毫秒 hash-field耗时:12042、11349、11126、11355、11168毫秒
Redis高延迟原因
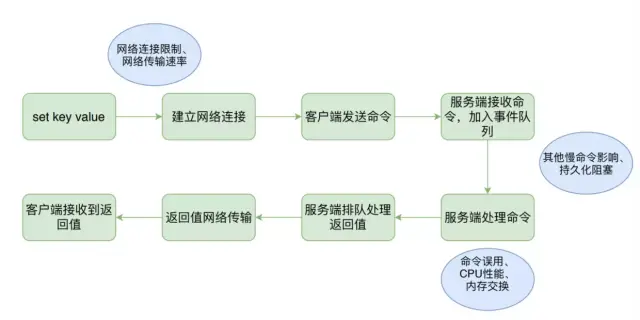
redis命令执行过程
蓝色的表示可能发生高延迟的地方
redis提供的慢查询统计功能: slowlog get {n}, 默认返回执行超过10ms(可配置)的命令.
- slowlog-log-slower-than, 配置超过几毫秒的数据被记录到慢查询队列中
- 慢查询队列的最大长度: slowlog-max-len
slowlog get会返回值如下:
> slowlog get1) (integer) 26 2) (integer) 1450253133 3) (integer) 43097 4) "flushdb"
redis高延迟原因
- 不合理的命令或者数据结构避免使用hgetall操作, redis提供发现各种数据结构中大对象的工具, redis-cli-h {ip} -p {port} bigkeys
- 持久化阻塞开启了持久化操作的redis, 当执行fork和AOF时会引起阻塞fork阻塞fork 操作发生在 RDB 和 AOF 重写时, Redis 主线程调用 fork 操作产生共享内存的子进程, 由子进程完成对应的持久化工作. 如果 fork 操作本身耗时过长, 必然会导致主线程的阻塞。AOF阻塞当我们开启AOF持久化功能时,文件刷盘的方式一般采用每秒一次, 后台线程每秒对AOF文件做 fsync 操作. 当硬盘压力过大时, fsync 操作需要等待,直到写入完成.内存交换内存交换(swap)对于 Redis 来说是非常致命的, Redis 保证高性能的一个重要前提是所有的数据在内存中. 如果操作系统把 Redis 使用的部分内存换出到硬盘, 由于内存与硬盘读写速度差几个数量级, 会导致发生交换后的 Redis 性能急剧下降. 识别 Redis 内存交换的检查方法如下:>redis-cli -p 6383 info server | grep process_id # 查询 redis 进程号
>cat /proc/4476/smaps | grep Swap # 查询内存交换大小
Swap: 0 kB
Swap: 4 kB
Swap: 0 kB
Swap: 0 kB如果交换量都是0KB或者个别的是4KB, 则是正常现象, 说明Redis进程内存没有被交换有很多方法可以避免内存交换的发生:保证机器充足的可用内存确保所有Redis实例设置最大可用内存(maxmemory), 防止极端情况下Redis内存不可控的增长降低系统使用swap优先级, 如 echo10>/proc/sys/vm/swappiness
 鲁公网安备37020202000738号
鲁公网安备37020202000738号