MySQL数据库架构详解:全面了解查询执行流程与SQL解析顺序
发表时间: 2019-04-16 00:05
关于mysql数据库的学习,建议先从架构框架入手,然后逐步细化分支,下面先介绍下mysql数据库架构,然后对其中的查询执行流程做分析,最后看下sql解析顺序。
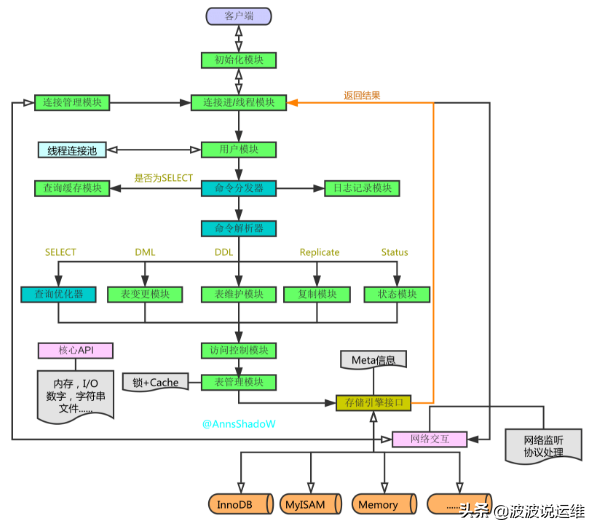
从上图中我们可以看到,整个架构分为两层,上层是MySQLD的被称为的‘SQL Layer’,下层是各种各样对上提供接口的存储引擎,被称为‘Storage Engine Layer’。其它各个模块和组件,从名字上就可以简单了解到它们的作用
查询执行的流程如下:

1.连接
1.1客户端发起一条Query请求,监听客户端的‘连接管理模块’接收请求
1.2将请求转发到‘连接进/线程模块’
1.3调用‘用户模块’来进行授权检查
1.4通过检查后,‘连接进/线程模块’从‘线程连接池’中取出空闲的被缓存的连接线程和客户端请求对接,如果失败则创建一个新的连接请求
2.处理
2.1先查询缓存,检查Query语句是否完全匹配,接着再检查是否具有权限,都成功则直接取数据返回
2.2上一步有失败则转交给‘命令解析器’,经过词法分析,语法分析后生成解析树
2.3接下来是预处理阶段,处理解析器无法解决的语义,检查权限等,生成新的解析树
2.4再转交给对应的模块处理
2.5如果是SELECT查询还会经由‘查询优化器’做大量的优化,生成执行计划
2.6模块收到请求后,通过‘访问控制模块’检查所连接的用户是否有访问目标表和目标字段的权限
2.7有则调用‘表管理模块’,先是查看table cache中是否存在,有则直接对应的表和获取锁,否则重新打开表文件
2.8根据表的meta数据,获取表的存储引擎类型等信息,通过接口调用对应的存储引擎处理
2.9上述过程中产生数据变化的时候,若打开日志功能,则会记录到相应二进制日志文件中
3.结果
3.1Query请求完成后,将结果集返回给‘连接进/线程模块’
3.2返回的也可以是相应的状态标识,如成功或失败等
3.3‘连接进/线程模块’进行后续的清理工作,并继续等待请求或断开与客户端的连接
SQL语言不同于其他编程语言,最明显的不同体现在处理代码的顺序上。在大多数编程语言中,代码按编码顺序被处理。但在SQL语言中,第一个被处理的子句总是FROM子句。下面显示了逻辑查询处理的顺序以及步骤的序号。

执行顺序如下:
1 FROM <left_table> 2 ON <join_condition> 3 <join_type> JOIN <right_table> 4 WHERE <where_condition> 5 GROUP BY <group_by_list> 6 HAVING <having_condition> 7 SELECT 8 DISTINCT <select_list> 9 ORDER BY <order_by_condition>10 LIMIT <limit_number>
可以看到一共有11个步骤,最先执行的是FROM操作,最后执行的是LIMIT操作。每个操作都会产生一张虚拟表,该虚拟表作为一个处理的输入。这些虚拟表对用户是透明的,只有最后一步生成的虚拟表才会返回给用户。如果没有在查询中指定某一子句,则将跳过相应的步骤。
篇幅有限,关于mysql优化方面的内容就介绍到这了,后面会分享更多DBA方面内容,感兴趣的朋友可以关注下!

声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号