后端技术深度解析:产品经理必读
发表时间: 2019-07-03 14:38
在上一篇文章中,笔者分享了web前端的相关知识与应用(写给产品经理的技术分享–前端篇),这篇文章是对上一篇文章的补充,主要分享后端、以及前后端交互相关知识及其在产品工作中的应用。

API这个词,我想所有的产品经理都听过无数次。
上一篇分享中,我们提及了一种用于前后端通信的API,其作用方式之一是:前端随请求将要传递的数据打包并发送到服务器,服务器执行相应处理程序,并将程序的输出发回前端。
前端通常使用这种方式从服务器请求最新数据,因为这些工作涉及到前后端配合,因而在实际工作中还需要产出相应的API文档(甚至于在一些公司是由产品经理去输出API文档),指明随请求发送的参数、请求方法,传回的参数等。
除了这种用于前后端通信的API,还有很多其他类型的API,例如:我们调用支付宝、微信等第三方应用的API,从而为自己的应用增加支付、分享等功能。
在《headfirst python》这本书中,通过一个具体的例子,更加透彻的讲解了API的由来:
在编程中,通过定义函数,可以减少重复代码;将函数保存在一个脚本文件中,使之转化为模块;将模块放入文件夹,同时增加元数据文件,就可以将模块打包准备发布;在web上发布你的文件(也就是API),以供他人下载、安装和使用,其他开发者可以使用API所提供的函数为产品增加功能。
为了让更多人以不同方式更加灵活的调用API,我们在定义函数时可以使用可选参数(也就是为参数提供默认值),通过使用参数控制函数的行为与表现。
即便不需要写API文档,产品经理对于API及其调用方式也需要有基本的认知,进行考虑并体现在产品设计方案或者PRD中。
以调用QQ分享接口为例进行说明:我们需要查看QQ开放平台API调用说明,明确各种API调用的效果以最终确定要选取的API,以及该API需要自定义哪些参数。
下图是我的PRD的截图,指明了调用的API、调用效果以及需要自定义的参数值。
在上一篇讲前后端通信的时候,已经初步提及了web应用的工作方式。
这里再大概陈述一下:
MVC即模型-视图-控制器(model-view-controller),这是一种常用的开发模式,有助于将代码分解为易于管理、维护、扩展的功能模块。
其中:
在互联网早期,后端做了绝大部份工作,也就是模型、视图、控制器代码都由后端完成。
后端会建立数据模型,通过视图代码对HTML标记进行拼接,通过控制器代码将模型数据填充到页面视图中并打印出来,这些输出作为响应发回浏览器,浏览器再将页面显示出来。
这种模式的缺点在于:每次请求都要返回一个新页面,这会降低浏览器的响应性;另外,许多前端页面存在大量重复代码,但是还要一遍一遍重复生成。
而现在,这一情况已经改变,视图代码和部分控制器代码已经运行在前端,模型和部分控制器代码则运行在后端。
在这种模式下,后端不再需要每次都返回一个完整页面,只需传送数据(通常为JSON格式);前端定义好页面样式,从服务端获取数据并根据业务逻辑填充到页面中。这可以提高页面的响应速度,并且高效利用了不同页面的重复代码。
举个例子:比如我们的网站有一个这样的页面,用户输入某一个歌手,我们的网站就为其展示该歌手的所有歌曲名。那么前后端分别需要编写哪些代码模块呢?
前端需要编写视图(View)相关代码,提供一个表单页面让用户输入歌手名;前端还需要编写一部分控制器(controller)代码,用于创建请求,随请求将用户的输入以键值对的形式(例如 singer:“周杰伦”)发送到服务端,另外还需要编写数据到达时的处理程序,在服务端数据到达时,对歌曲数据进行处理并以一定的结构增加到页面中。
后端需要有一个数据模型(model),该模型以一定的结构存储了许多歌手及其歌曲数据,还定义了获取业务所需数据的方法或者说函数(在这个例子中就是通过歌手的名字,获取该歌手的所有歌曲);后端还需要有一个控制层(controller),用于处理前端发来的请求并进行响应,在这里就需要获取用户输入的歌手名(同样是使用键获取对应的值),调用数据模型及相应函数,并将歌手名传入函数。该函数会获取模型数据并进行处理,最终输出该歌手对应的歌曲列表,作为响应发回前端。
通过以上的例子,我们就可以看出:前后端在软件开发中角色的分工与配合方式,知道了目前前后端的分工原则后,我们在和前后端的沟通中就应该相应有所侧重。
着重像前端展示页面的结构、样式、交互,指明页面数据来源;着重向后端展示,哪些数据来源于后端,这些数据的计算规则(如上文所言,复杂的数据逻辑运算一般发生在服务端),和现有数据的关联等。
了解前后端的分工不仅可以帮助我们更好的推动产品方案落地,还有助于在出现bug时,更加快速定位到问题来源与对应开发人员。
在这里还要强调一下:无论是“模型-视图-控制器”这一开发模式,还是上述的前后端的分工方式,都不是唯一正确答案,这种划分也不是非黑即白的。我们要明确其间的区别,但更要知道其中的联系。
前面已经提到了数据在前后端之间的传递,在上一篇讲本地存储的时候也提及了可以使用local storage(本地存储)、session storage(会话存储)将数据存储在浏览器本地。但是,绝大多数用户数据、内容信息是存储在服务端的数据库中。
数据库的类型主要有关系型数据库和非关系型数据库。
关系型数据库是一种基于关系模型的数据库,这种关系模型是对现实中实体关系的抽象表达。非关系型数据库,在存储的数据结构上没有那么严格的约束和规范,以更加灵活的方式定义数据存储。
常用的数据库管理系统(软件)包括:Oracle、MySQL、MongoDB等。
可以这样理解数据库和数据库管理软件的关系,数据库就是一个类似Excel文件的数据文件,里面包含很多的数据表,这些文件会放在web应用的根文件夹下,以便在运行程序时进行访问;数据库管理系统类似于Excel软件,可以可视化的查看并管理数据库文件。
在这里我们仅对关系型数据库进行讲解。
这里以python编程为例,讲解服务端程序与数据库如何进行交互。python的数据库API提供了一种操作数据库的标准机制,如下图(注意这并不是与数据库进行交互的唯一方式)
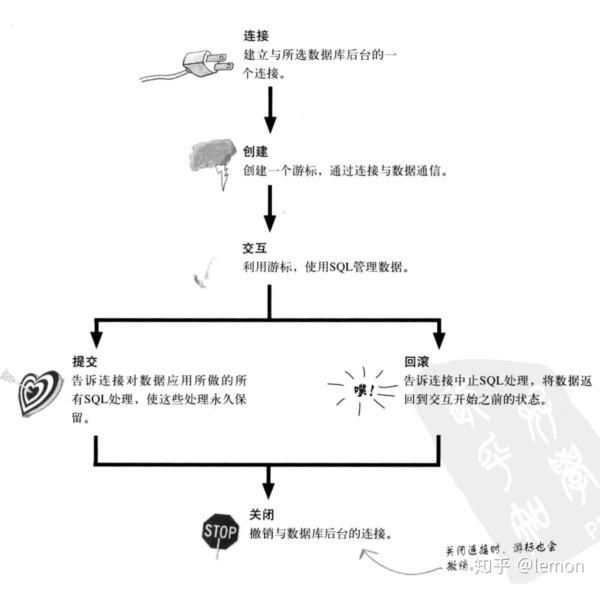
以上流程翻译成python代码是这样的:

关系型数据库是由一张张相互关联的数据表构成的,对数据库的设计也就是设计数据表的结构和关联。我们现在来设计一个数据库,并使用python真正建立这个数据库。
现在我们设计了一个名为runningdata的数据库,里面包含两张数据表,一张表记录每个用户的基本信息(姓名和出生日期),另一张表记录每个用户的跑步时间数据。
两张数据表分别如下:
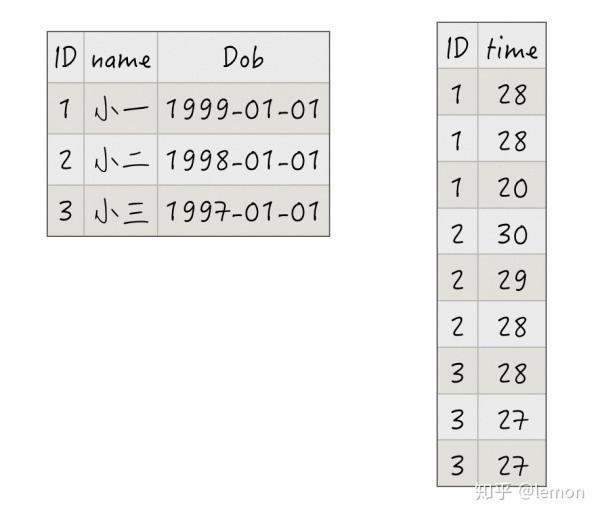
可以看到,这两张表通过用户ID进行关联,这种表的结构和关联应该是具有逻辑意义、现实意义、业务导向、支持扩展的。
上面是对数据表的设计,那么如何通过python建立上面的数据表,并进行数据插入和查询等操作呢?
首先套用3.2中的流程,建立与数据库的连接、创建数据游标,然后使用create语句创建两个数据表。使用SELECT语句对数据表进行查询并获取结果,使用INSERT语句分别向表增加数据(其中用户ID可以自动生成,我们使用第一个表生成的用户ID填充第二个表,使之关联起来),然后提交修改并关闭连接。
建立后的数据库一般长这个样子:
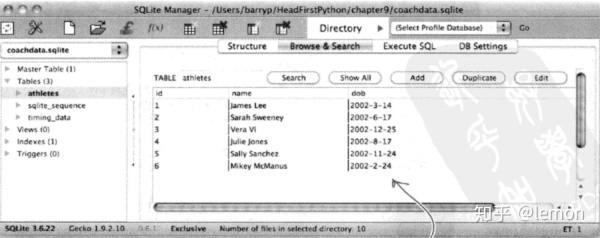
上面讲MVC(模型-视图-控制器)时我们提到,模型代码用来存储并提供数据。所以,我们只需在模型(model)中编写上述代码,让其帮助我们创建数据库,并定义相关的数据处理方法。这样在控制器代码进行响应时就可以调用该方法,使之返回我们需要的数据。
产品经理对于数据库的设计方式、作用方式有一定的了解,有助于评估产品功能的实现对现有数据库的影响,以及新的设计对原有数据的兼容性问题。
另一方面,现在的产品设计往往需要参考大量的用户行为数据,进行下一步优化。这些用户数据往往存储在数据库中,产品经理有时需要使用SQL语句对数据库进行查询,因而对于数据库的了解也是大有帮助的。
本文主要讲解了三个方面的内容:
通过这些内容简单介绍了服务端的基本知识,以及与产品工作的联系。
我个人对于服务端技术的学习是通过《Head First Python》这本书,因此写这篇文章,也算是抛砖引玉。后端的内容非常之庞大,我虽诚惶诚恐,还是大胆把自己有所感悟的写了下来,欢迎大家与我探讨或者批评指正。
这两篇文章讲解了web应用开发所涉及的基本知识,希望大家看完之后有所收获,也建议产品经理们去看一下技术相关的书籍,甚至于写一个自己的应用,体会一下开发的过程,思考产品设计与技术实现的关系,思考产品经理与开发人员的协作方式。
本文由 @lemon 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号