新视角解读ChatGPT的变笨:AI改变世界,训练环境已非昔日
发表时间: 2024-01-02 19:45
 防走失,电梯直达安全岛报人刘亚东A
防走失,电梯直达安全岛报人刘亚东A 
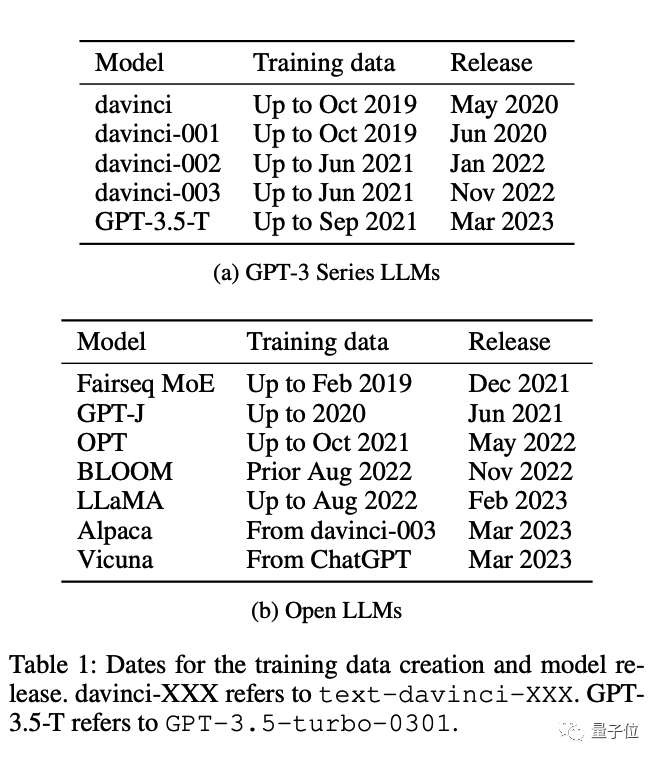
在训练数据截止之前的任务上,大模型表现明显更好。

这是所有不具备持续学习能力模型的命运。

检查训练数据:直接搜索有没有相应的任务示例
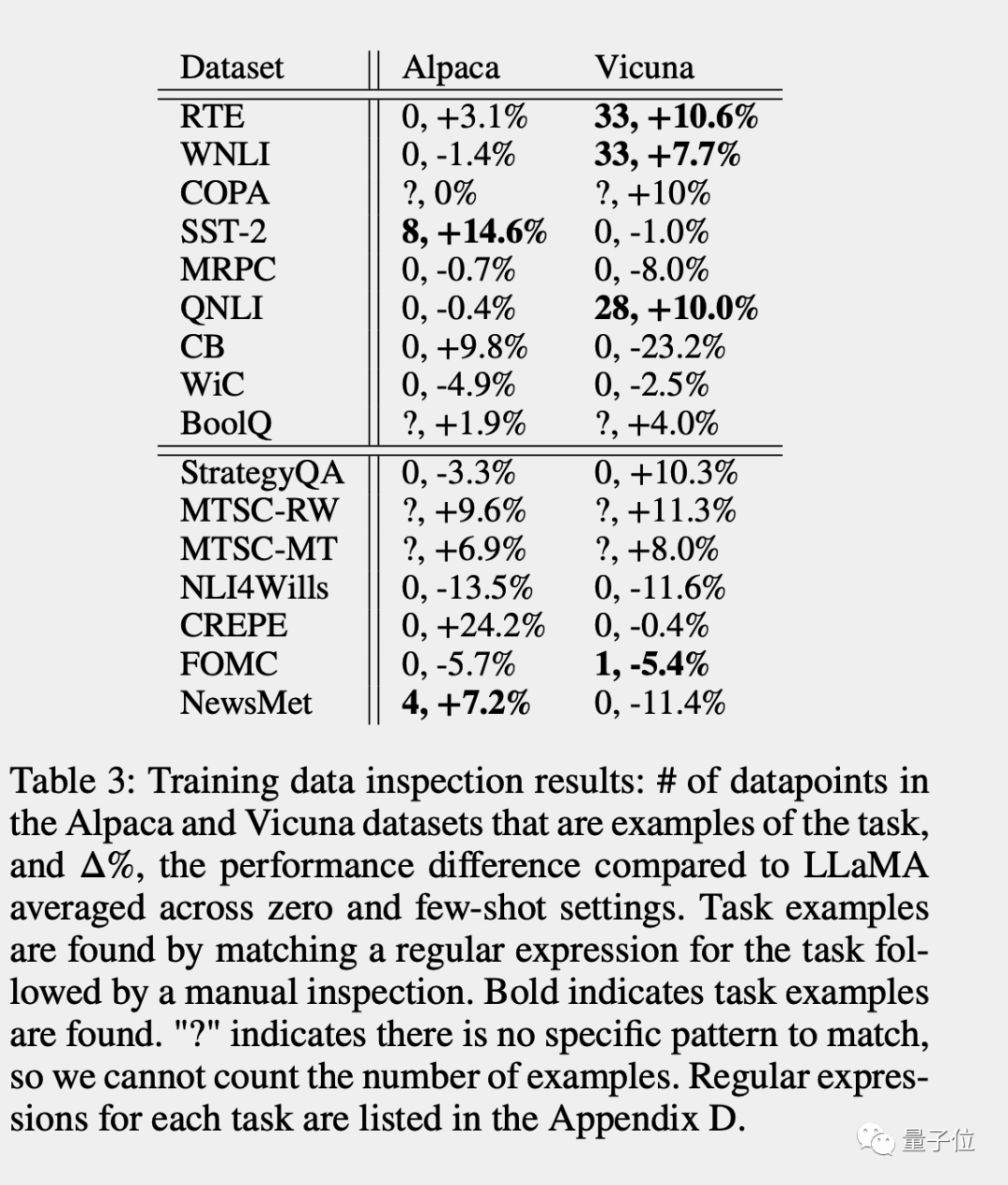
提取任务示例:通过调整提示词,让模型自己把训练数据中的任务示例背出来

成员推断(只适用于生成任务):检查模型生成的答案是否与原始数据完全相同
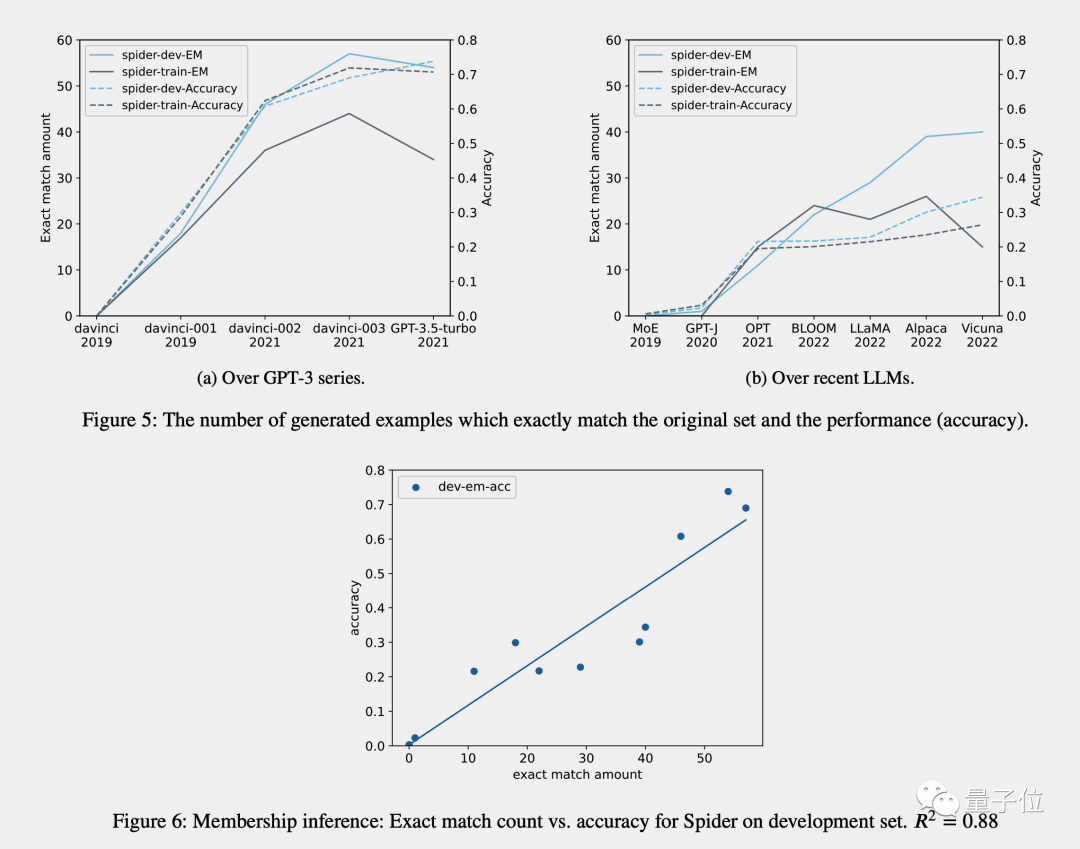
按时间顺序分析:对于已知训练数据收集时间的模型,测量已知发布时间数据集上的表现并使用按时间顺序的证据检查数据污染证据
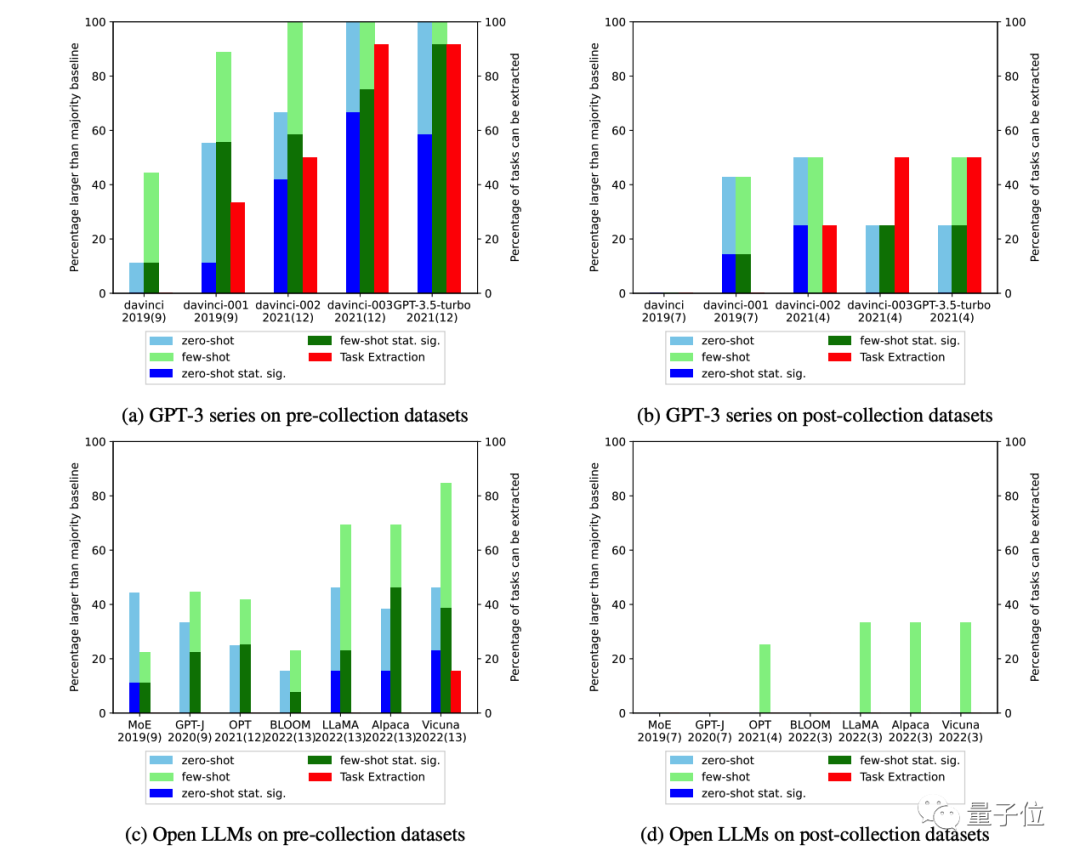
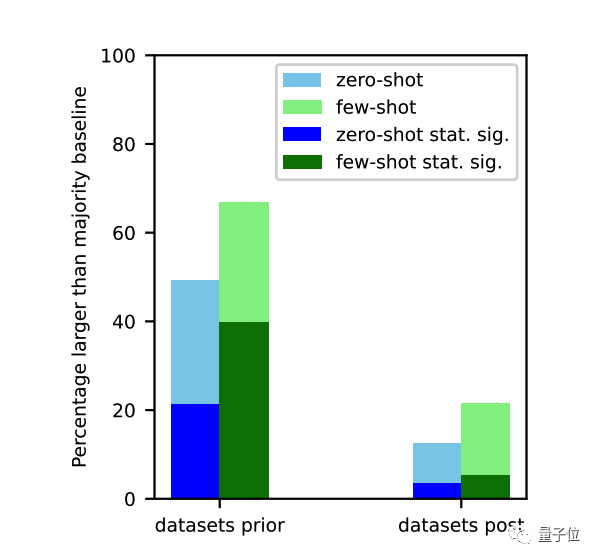
由于任务污染,闭源模型可能会在零样本或少样本评估中表现的比实际好,特别是经过RLHF微调的模型。污染的程度仍不清楚,因此我们建议谨慎行事。
在实验中,对于没有任务污染可能性的分类任务,大模型很少在零样本和少样本设置中表现出相对于大多数基线具有统计学意义的显著改进。
随着时间推移,观察到GPT-3系列模型在许多下游任务的的零样本或少样本性能有所增加,这可能是由于任务污染造成的。
即使对于开源模型,检查训练数据的任务污染也很困难。
鼓励公开发布训练数据,以便检查任务污染问题。

用现有数据训练AI
人们过多使用AI,以至于改变了现实世界
AI无法适应改变后的世界,变得低效

声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号