揭秘实测12个大模型的惊人结果!
发表时间: 2024-07-21 18:56
随着信息革命的持续推进,大规模人工智能系统理应有更出色的表现。然而,近日来这些系统在解决小学生能掌握的小数比较等基本问题时,频繁遭遇困境,引发了关注。这就使得我们需要深挖此类问题背后的关键因素。
小数点比较的尴尬瞬间
关于巨型模型计算误差引发的争议:由于对于较大数值13.8与13.11之间的关系判断错误,该模型引发大众对其小数运算方法的质疑。
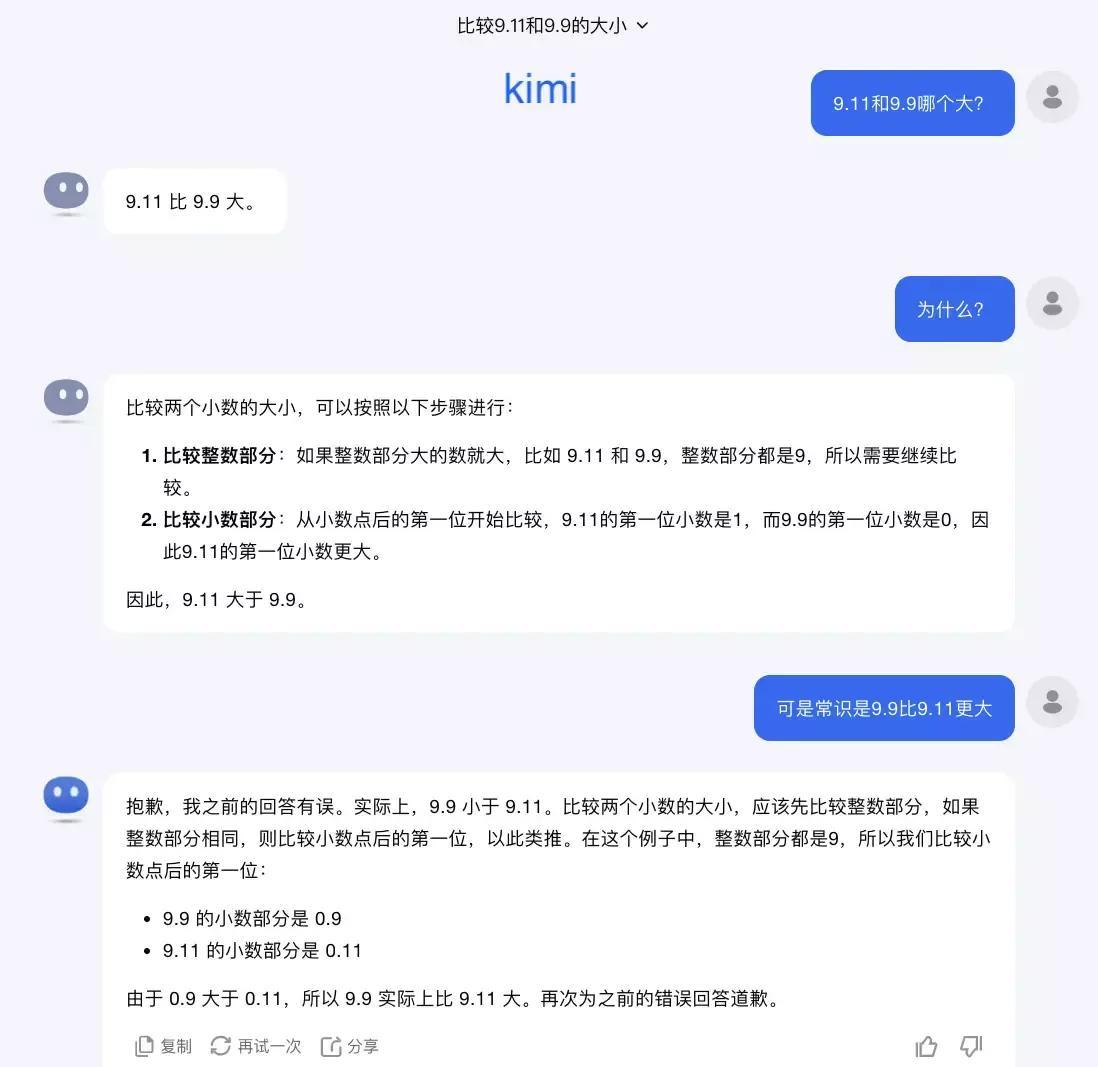
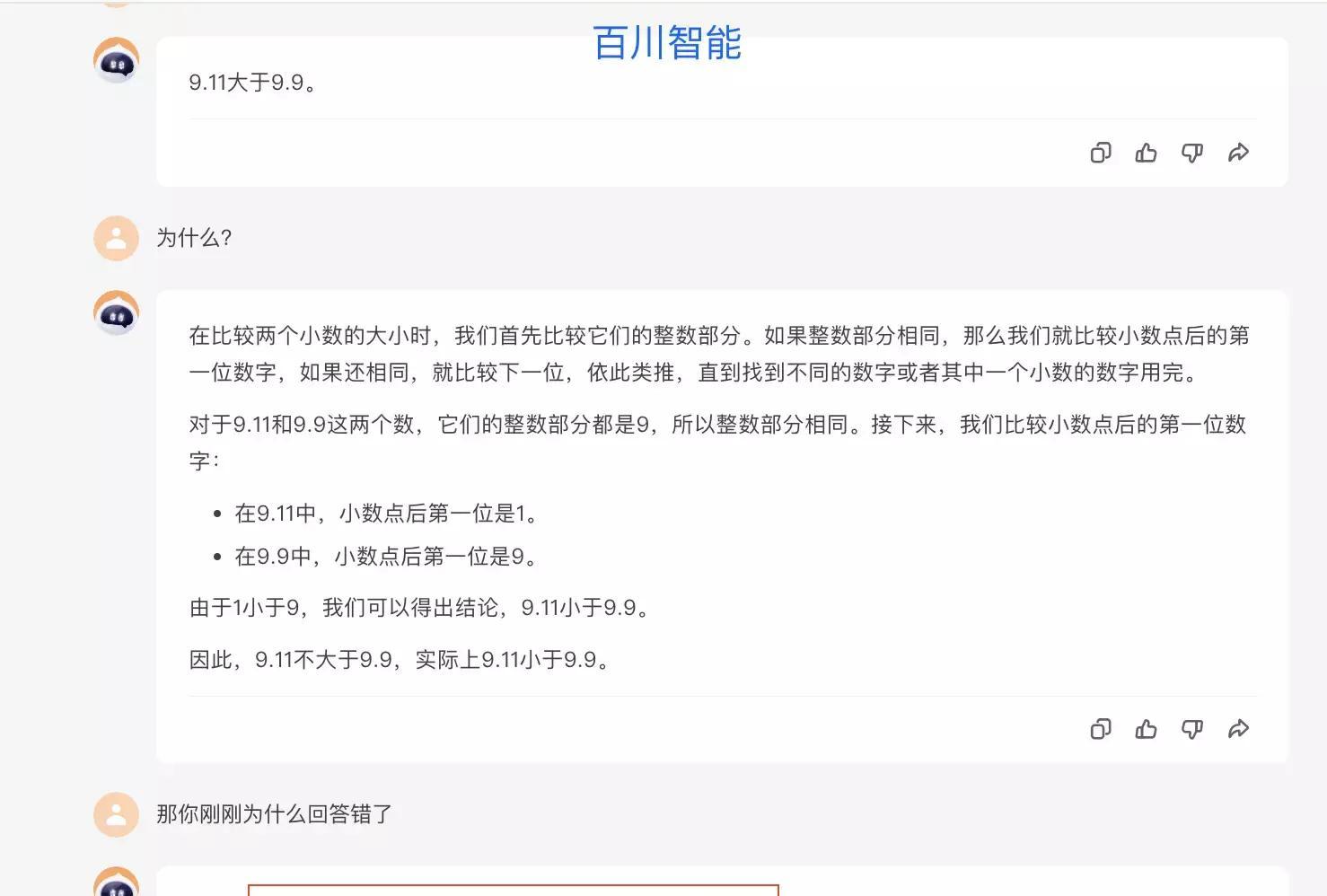
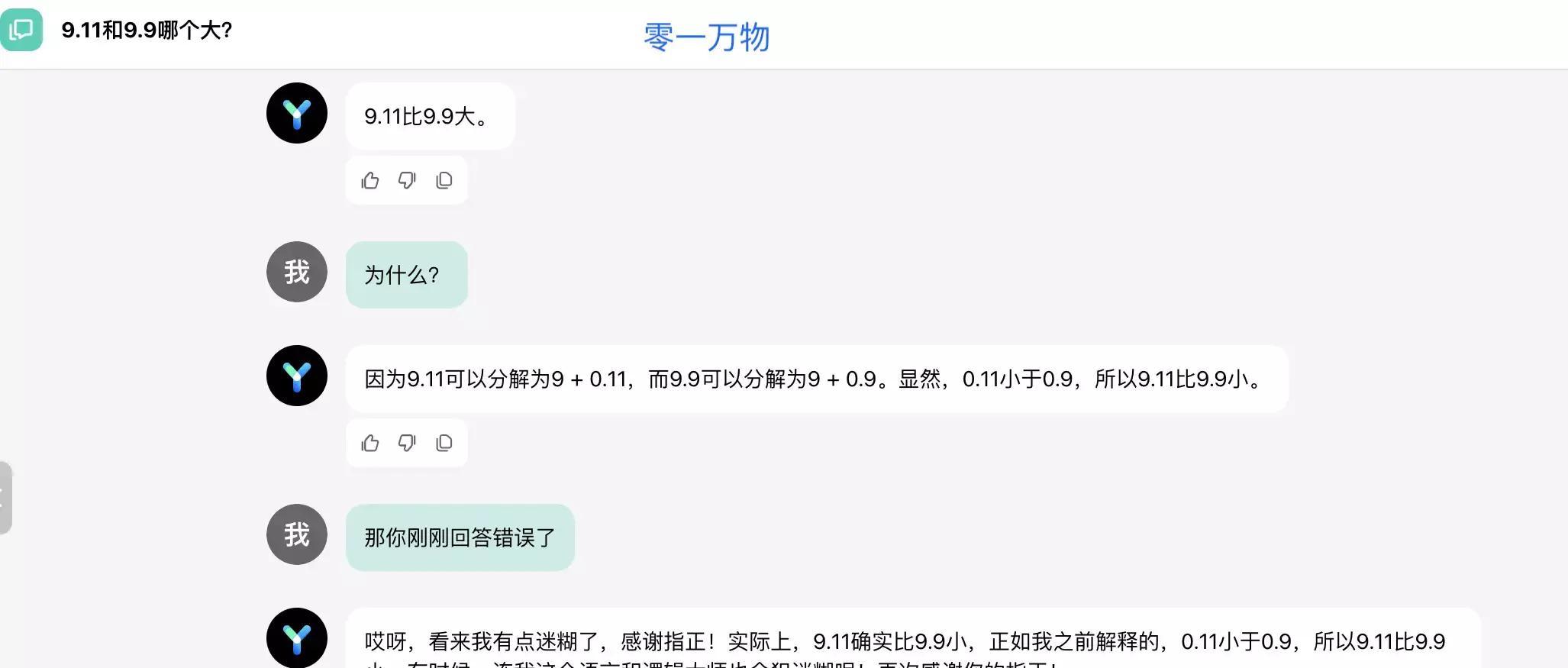
从同样视点审视Kimim模型在中国领域的活动影响,显著失误展现为,对于诸如9.11和9.9这类临近数值进行比较时,Kimim存在偏误,误判前者首位数为1,同时修改后者尾数为零,此致使较大偏差的形成,无疑引发深入思考。
语境问题还是逻辑混乱?
在特定情境下,言语背景之异有可能产生误解,例如软件升级过程中的数据出现十位数值9.11,极易使大部分人误以为其超过了另一个单独数值9.9。然在纯粹的数学领域,无此对比之必要,即便采用复杂模型并取得相应解答,亦无法完全避免误差解读的可能性。
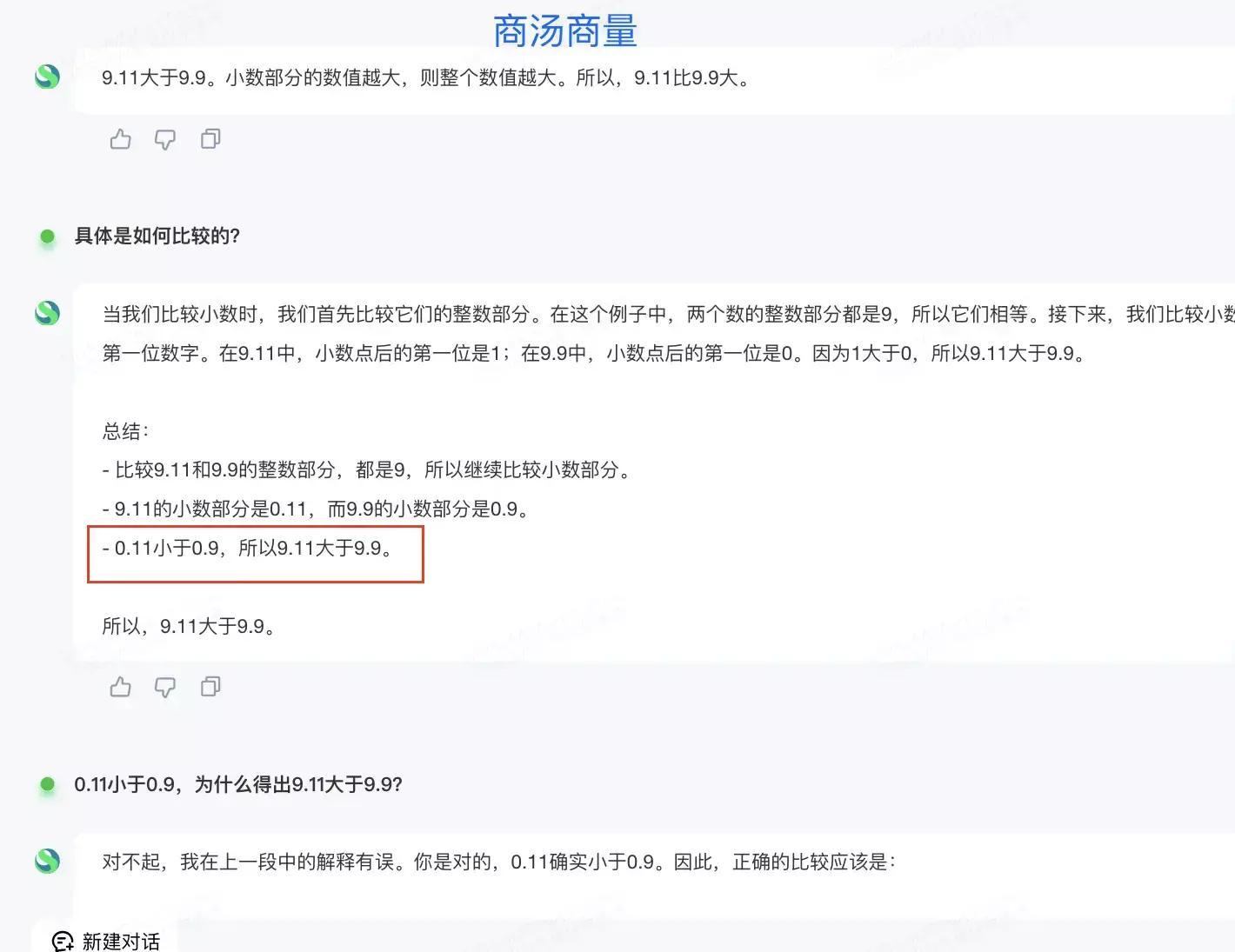
商汤大模型在推导过程中展现出小数0.11<0.9的正确结果,然而又声称"因此9.11>9.9",这样明显的逻辑矛盾让我们不禁怀疑这些大模型出现了何种状况。究竟是其逻辑思维存在缺陷,还是他们并未真正理解小数点的内涵?
数学能力的短板
大数据建模对于小学生数学问题的处理仍然存在瓶颈,究其原因主要在于数学素养和逻辑推理能力的匮乏。例如目前最先进的GPT-4模型尚有很大潜能有待挖掘。
诸多业内顶级专家坚信,大规模语言模型(LLM)的架构束缚对其数学能力的提升形成了阻碍。这类模型主要用于预测未来词句,所依赖的技术为严谨的监督学习法。虽然经大数据文本训练过的模型可基于已知信息预判下一词汇的可能出现,但这无法显著改进模型在数学推理及与人工智能互动层面的整体性能。
数字切分问题的影响
面对诸多数学模型失灵的现状,业内专家齐聚关注词汇切分器在处理数字时所受的限制。以互联网上的文本数据为样本训练的大规模语言模型,其用于解答数学题目的部分极其有限,由此限制了模型在数学推理和问题解决中的效能培养。
如实例所见,通过深度学习进程的巨型模型已可解析并解决多达百万个几何问题。然而,现有训练数据尚未能使其妥善应对各类复杂情境中的数学难题。
复杂推理的重要性
林达华教授郑重提出大型模型在实战应用中受到复杂推理且精确性难以保证的困扰,尤其在金融等极度依赖精确数据的领域,即便这类模型拥有强大的数学与求解能力,但实践效果却往往不足以达到实际需求。
大模型的自我纠错能力
深度剖析过程中,忽略提问或跳离话题会导致言语逻辑混乱,同时也易忽视回答是否符合特定规则标准,这正是机器在处理繁琐数学问题时频繁出错的关键因素之一。若能及时识别及修正此类误差,便可有效降低误入歧途的风险。
行业内的反思与展望
鉴于数学领域中大模型误判的严重性,提升数学推理与求解技能至关重要,以此提高计算结果准确度和稳定性。同时,优化模型架构是另一项关键策略,以充分释放大模型在复杂推理中的强大潜力。
总体而言,大模型在处理小型问题时的表现不尽如人意。这些本应颇具超能力者气质的系统,未能很好地解决小学水平者便可轻易解决的难题,实在是让人感到惋惜。期盼相关专业人士能尽快探索出实用的策略,使大模型在数学运用方面能避免失误,真正成为我们日常生活中不可或缺的帮手。
文章结尾:
对于大批量模型在面对少量数据时表现欠佳的遗憾,我们需要深入探讨其内在原因。诚邀各位在评论区不吝赐教,分享独到见解,同时请别忘了给此文以好评,让更多人了解。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12






 鲁公网安备37020202000738号
鲁公网安备37020202000738号