提升JavaScript调用速度的40%实践方法
发表时间: 2021-02-20 12:52
参数适配器机制不仅复杂,而且成本很高。
本文最初发表于 v8.dev(Faster JavaScript calls),基于 CC 3.0 协议分享,由 InfoQ 翻译并发布。
JavaScript 允许使用与预期形式参数数量不同的实际参数来调用一个函数,也就是传递的实参可以少于或者多于声明的形参数量。前者称为申请不足(under-application),后者称为申请过度(over-application)。
在申请不足的情况下,剩余形式参数会被分配 undefined 值。在申请过度的情况下,可以使用 rest 参数和 arguments 属性访问剩余实参,或者如果它们是多余的可以直接忽略。如今,许多 Web/Node.js 框架都使用这个 JS 特性来接受可选形参,并创建更灵活的 API。
直到最近,V8 都有一种专门的机制来处理参数大小不匹配的情况:这种机制叫做参数适配器框架。不幸的是,参数适配是有性能成本的,但在现代的前端和中间件框架中这种成本往往是必须的。但事实证明,我们可以通过一个巧妙的技巧来拿掉这个多余的框架,简化 V8 代码库并消除几乎所有的开销。
我们可以通过一个微型基准测试来计算移除参数适配器框架可以获得的性能收益。
console.time();function f(x, y, z) {}for (let i = 0; i < N; i++) { f(1, 2, 3, 4, 5);}console.timeEnd();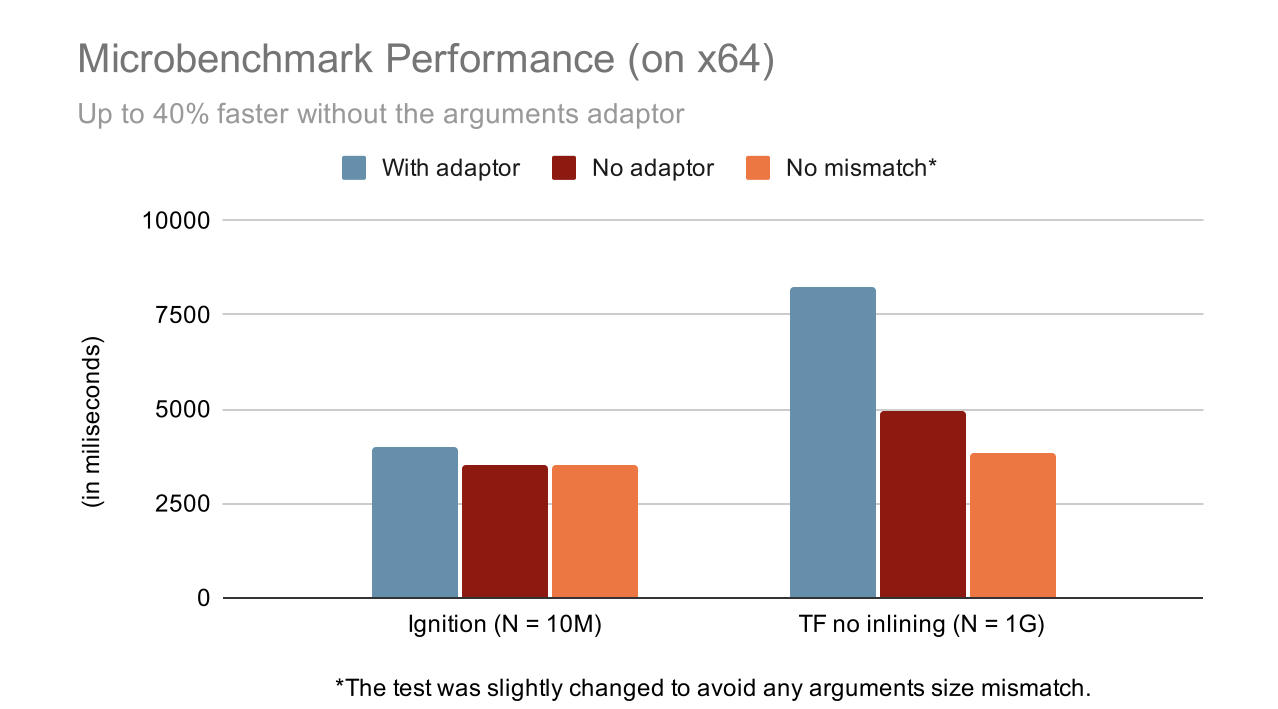
移除参数适配器框架的性能收益,通过一个微基准测试来得出。
上图显示,在无 JIT 模式(Ignition)下运行时,开销消失,并且性能提高了 11.2%。使用 TurboFan 时,我们的速度提高了 40%。
这个微基准测试自然是为了最大程度地展现参数适配器框架的影响而设计的。但是,我们也在许多基准测试中看到了显著的改进,例如我们内部的 JSTests/Array 基准测试(7%)和 Octane2(Richards 子项为 4.6%,EarleyBoyer 为 6.1%)。
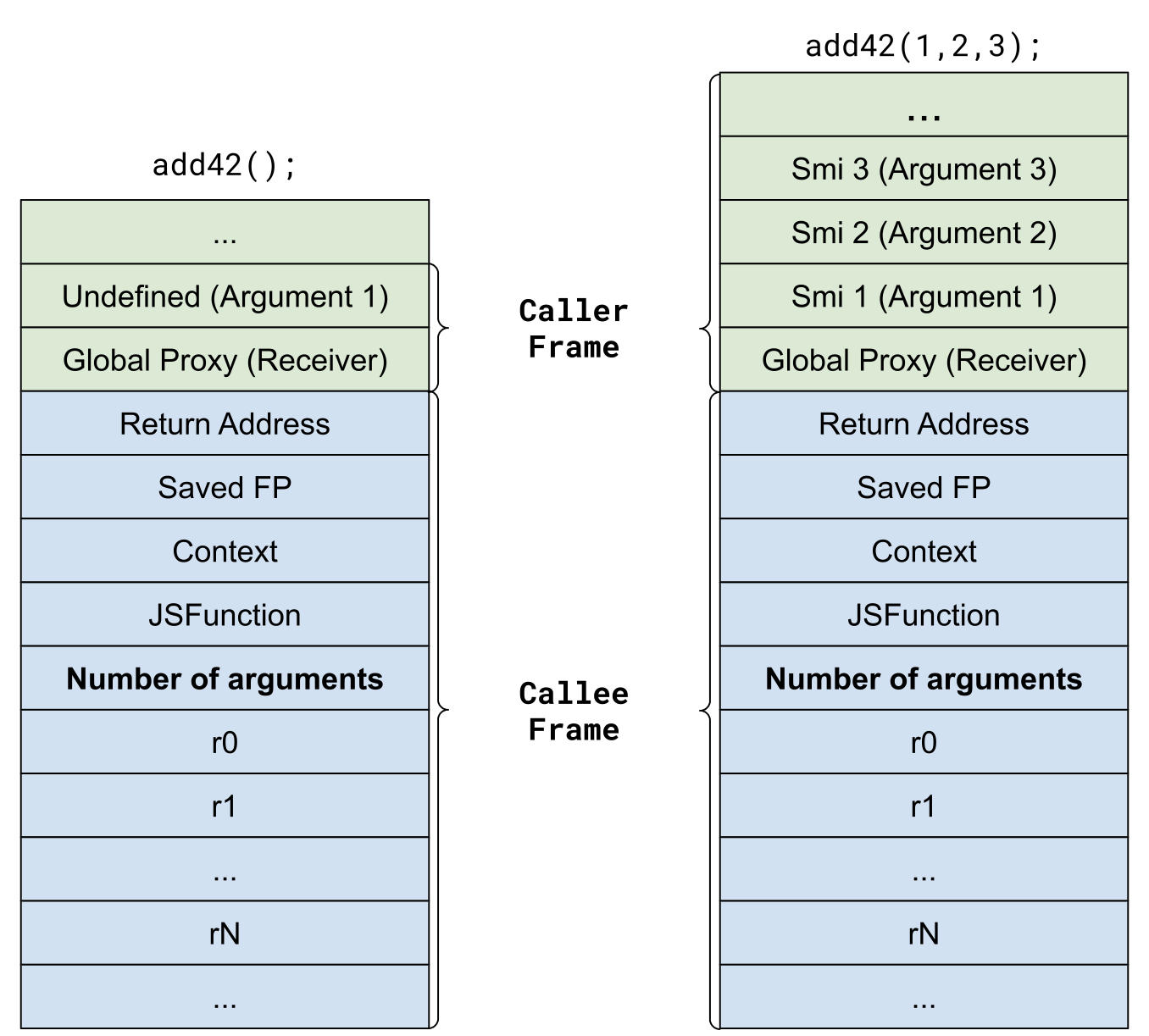
这个项目的重点是移除参数适配器框架,这个框架在访问栈中被调用者的参数时为其提供了一个一致的接口。为此,我们需要反转栈中的参数,并在被调用者框架中添加一个包含实际参数计数的新插槽。下图显示了更改前后的典型框架示例。
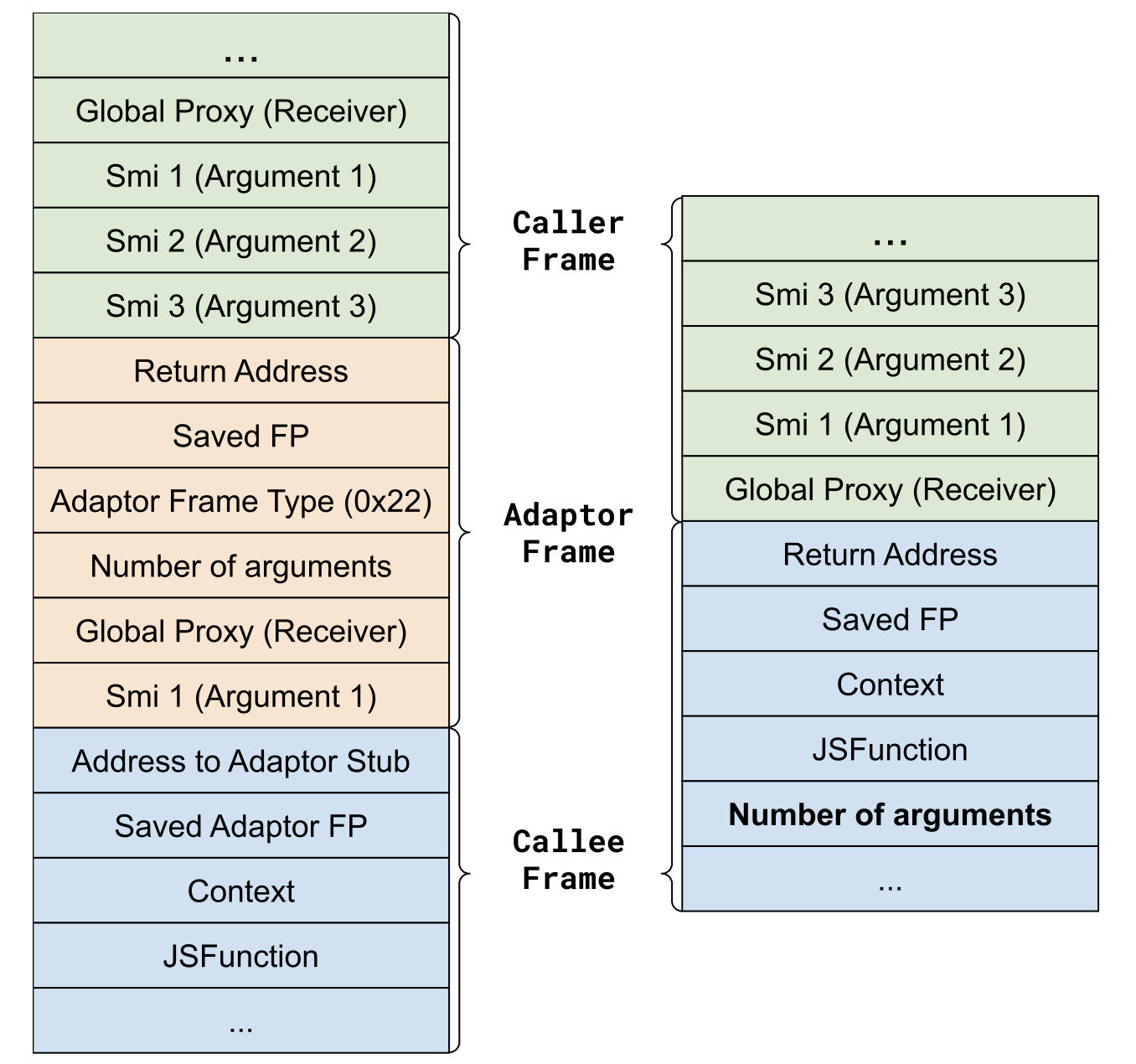
移除参数适配器框架之前和之后的典型 JavaScript 栈框架。
为了讲清楚我们如何加快调用,首先我们来看看 V8 如何执行一个调用,以及参数适配器框架如何工作。
当我们在 JS 中调用一个函数调用时,V8 内部会发生什么呢?用以下 JS 脚本为例:
function add42(x) { return x + 42;}add42(3);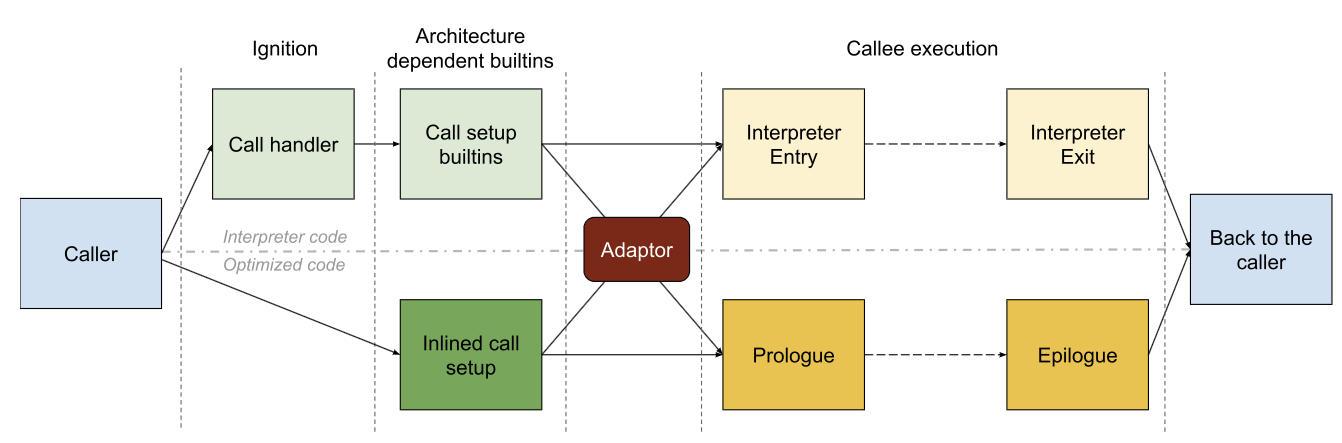
在函数调用期间 V8 内部的执行流程。
V8 是一个多层 VM。它的第一层称为 Ignition,是一个具有累加器寄存器的字节码栈机。V8 首先会将代码编译为 Ignition 字节码。上面的调用被编译为以下内容:
0d LdaUndefined ;; Load undefined into the accumulator26 f9 Star r2 ;; Store it in register r213 01 00 LdaGlobal [1] ;; Load global pointed by const 1 (add42)26 fa Star r1 ;; Store it in register r10c 03 LdaSmi [3] ;; Load small integer 3 into the accumulator26 f8 Star r3 ;; Store it in register r35f fa f9 02 CallNoFeedback r1, r2-r3 ;; Invoke call调用的第一个参数通常称为接收器(receiver)。接收器是 JSFunction 中的 this 对象,并且每个 JS 函数调用都必须有一个 this。CallNoFeedback 的字节码处理器需要使用寄存器列表 r2-r3 中的参数来调用对象 r1。
在深入研究字节码处理器之前,请先注意寄存器在字节码中的编码方式。它们是负的单字节整数:r1 编码为 fa,r2 编码为 f9,r3 编码为 f8。我们可以将任何寄存器 ri 称为 fb - i,实际上正如我们所见,正确的编码是- 2 - kFixedFrameHeaderSize - i。寄存器列表使用第一个寄存器和列表的大小来编码,因此 r2-r3 为 f9 02。
Ignition 中有许多字节码调用处理器。可以在此处查看它们的列表。它们彼此之间略有不同。有些字节码针对 undefined 的接收器调用、属性调用、具有固定数量的参数调用或通用调用进行了优化。在这里我们分析 CallNoFeedback,这是一个通用调用,在该调用中我们不会积累执行过程中的反馈。
这个字节码的处理器非常简单。它是用 CodeStubAssembler 编写的,你可以在此处查看。本质上,它会尾调用一个架构依赖的内置
InterpreterPushArgsThenCall。
这个内置方法实际上是将返回地址弹出到一个临时寄存器中,压入所有参数(包括接收器),然后压回该返回地址。此时,我们不知道被调用者是否是可调用对象,也不知道被调用者期望多少个参数,也就是它的形式参数数量。
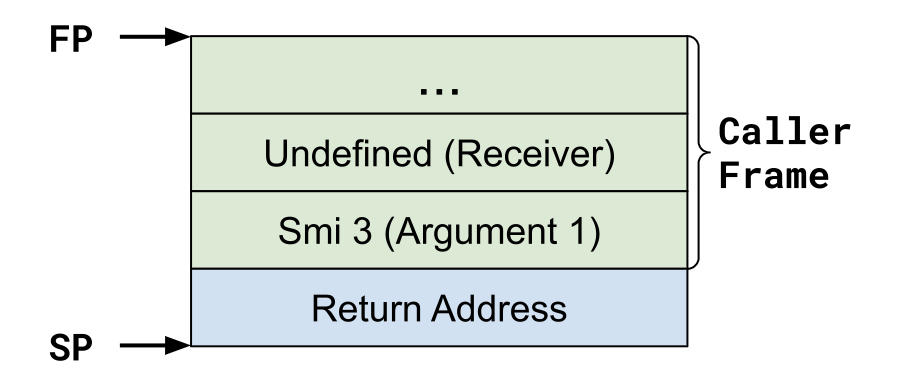
内置 InterpreterPushArgsThenCall 执行后的框架状态。
最终,执行会尾调用到内置的 Call。它会在那里检查目标是否是适当的函数、构造器或任何可调用对象。它还会读取共享 shared function info 结构以获得其形式参数计数。
如果被调用者是一个函数对象,它将对内置的 CallFunction 进行尾部调用,并在其中进行一系列检查,包括是否有 undefined 对象作为接收器。如果我们有一个 undefined 或 null 对象作为接收器,则应根据 ECMA 规范对其修补,以引用全局代理对象。
执行随后会对内置的 InvokeFunctionCode 进行尾调用。在没有参数不匹配的情况下,InvokeFunctionCode 只会调用被调用对象中字段 Code 所指向的内容。这可以是一个优化函数,也可以是内置的
InterpreterEntryTrampoline。
如果我们假设要调用的函数尚未优化,则 Ignition trampoline 将设置一个 IntepreterFrame。你可以在此处查看V8 中框架类型的简短摘要。
接下来发生的事情就不用多谈了,我们可以看一个被调用者执行期间的解释器框架快照。
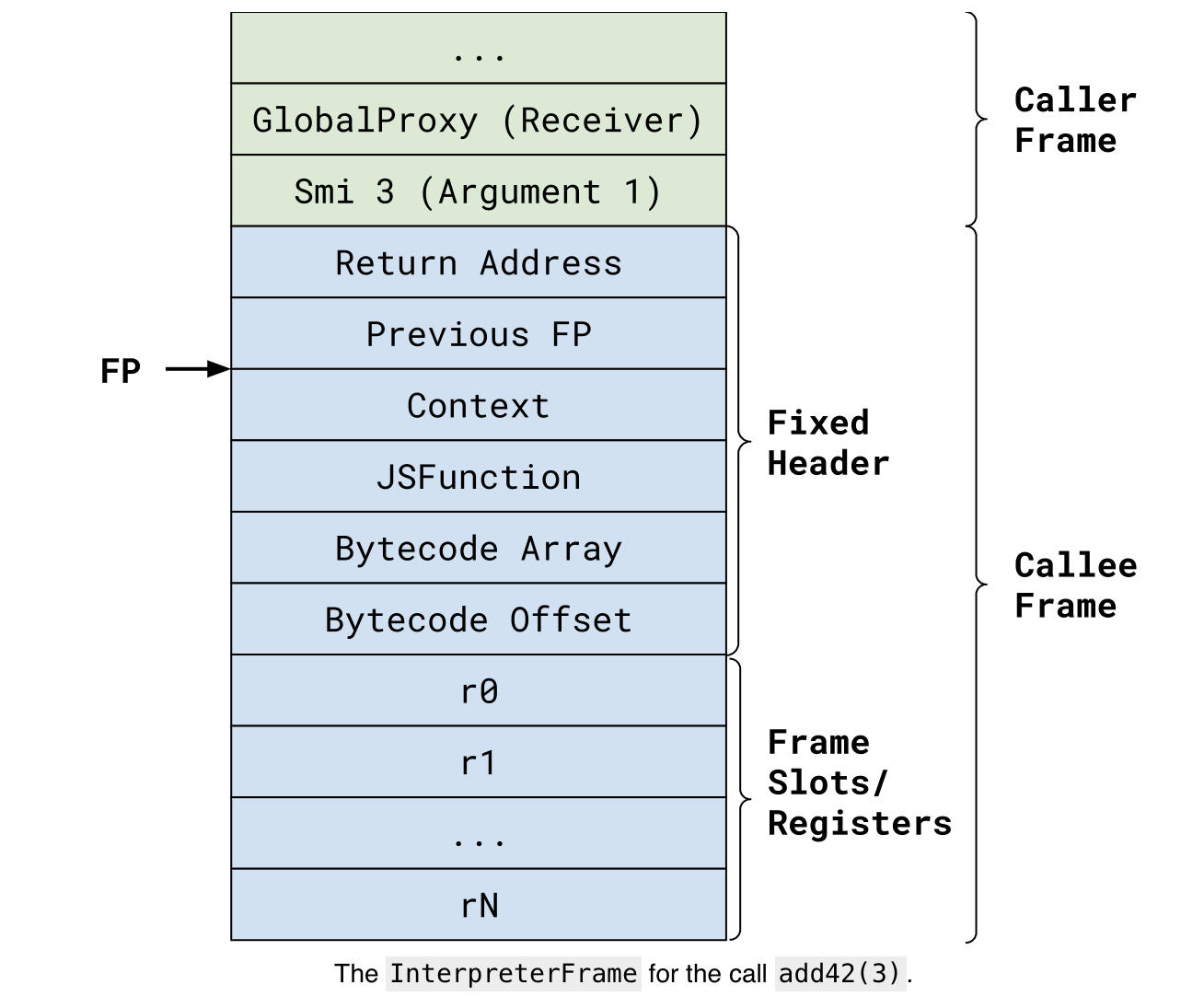
我们看到框架中有固定数量的插槽:返回地址、前一个框架指针、上下文、我们正在执行的当前函数对象、该函数的字节码数组以及我们当前正在执行的字节码偏移量。最后,我们有一个专用于此函数的寄存器列表(你可以将它们视为函数局部变量)。add42 函数实际上没有任何寄存器,但是调用者具有类似的框架,其中包含 3 个寄存器。
如预期的那样,add42 是一个简单的函数:
25 02 Ldar a0 ;; Load the first argument to the accumulator40 2a 00 AddSmi [42] ;; Add 42 to itab Return ;; Return the accumulator请注意我们在 Ldar(Load Accumulator Register)字节码中编码参数的方式:参数 1(a0)用数字 02 编码。实际上,任何参数的编码规则都是[ai] = 2 + parameter_count - i - 1,接收器[this] = 2 + parameter_count,或者在本例中[this] = 3。此处的参数计数不包括接收器。
现在我们就能理解为什么用这种方式对寄存器和参数进行编码。它们只是表示一个框架指针的偏移量。然后,我们可以用相同的方式处理参数/寄存器的加载和存储。框架指针的最后一个参数偏移量为 2(先前的框架指针和返回地址)。这就解释了编码中的 2。解释器框架的固定部分是 6 个插槽(4 个来自框架指针),因此寄存器零位于偏移量-5 处,也就是 fb,寄存器 1 位于 fa 处。很聪明是吧?
但请注意,为了能够访问参数,该函数必须知道栈中有多少个参数!无论有多少参数,索引 2 都指向最后一个参数!
Return 的字节码处理器将调用内置的 LeaveInterpreterFrame 来完成。该内置函数本质上是从框架中读取函数对象以获取参数计数,弹出当前框架,恢复框架指针,将返回地址保存在一个暂存器中,根据参数计数弹出参数并跳转到暂存器中的地址。
这套流程很棒!但是,当我们调用一个实参数量少于或多于其形参数量的函数时,会发生什么呢?这个聪明的参数/寄存器访问流程将失败,我们该如何在调用结束时清理参数?
现在,我们使用更少或更多的实参来调用 add42:
add42();add42(1, 2, 3);JS 开发人员会知道,在第一种情况下,x 将被分配 undefined,并且该函数将返回 undefined + 42 = NaN。在第二种情况下,x 将被分配 1,函数将返回 43,其余参数将被忽略。请注意,调用者不知道是否会发生这种情况。即使调用者检查了参数计数,被调用者也可以使用 rest 参数或 arguments 对象访问其他所有参数。实际上,在 sloppy 模式下甚至可以在 add42 外部访问 arguments 对象。
如果我们执行与之前相同的步骤,则将首先调用内置的
InterpreterPushArgsThenCall。它将像这样将参数推入栈:
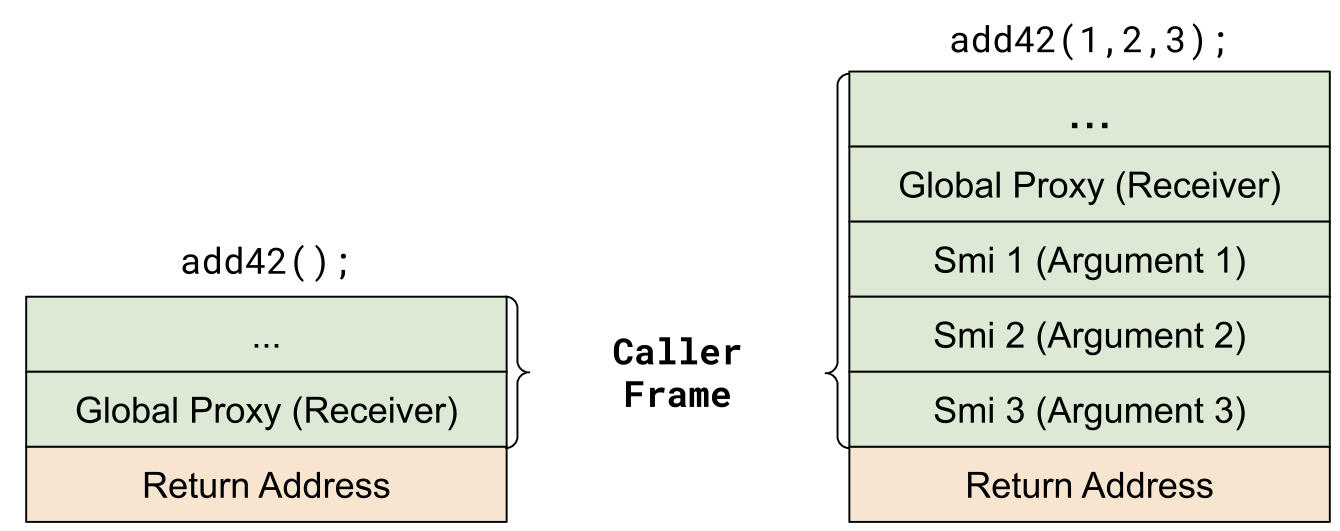
内置 InterpreterPushArgsThenCall 执行后的框架状态。
继续与以前相同的过程,我们检查被调用者是否为函数对象,获取其参数计数,并将接收器补到全局代理。最终,我们到达了 InvokeFunctionCode。
在这里我们不会跳转到被调用者对象中的 Code。我们检查参数大小和参数计数之间是否存在不匹配,然后跳转到
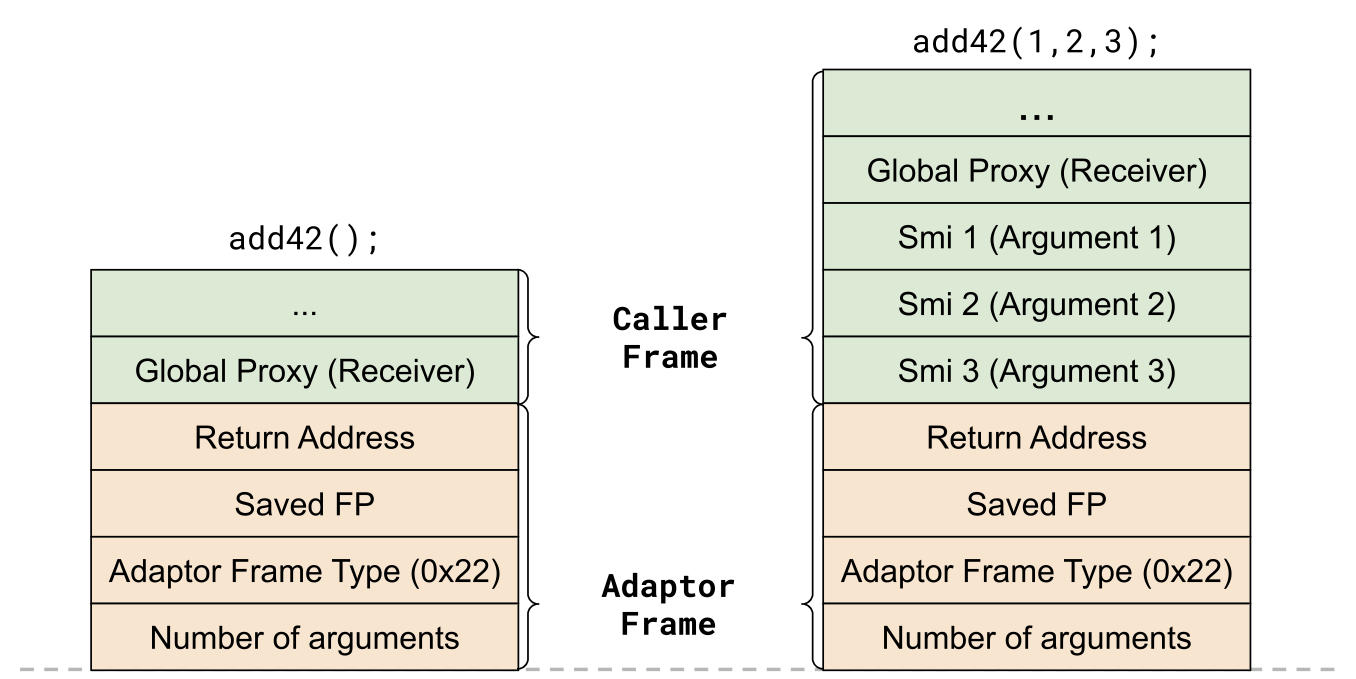
ArgumentsAdaptorTrampoline。
在这个内置组件中,我们构建了一个额外的框架,也就是臭名昭著的参数适配器框架。这里我不会解释内置组件内部发生了什么,只会向你展示内置组件调用被调用者的 Code 之前的框架状态。请注意,这是一个正确的 x64 call(不是 jmp),在被调用者执行之后,我们将返回到
ArgumentsAdaptorTrampoline。这与进行尾调用的 InvokeFunctionCode 正好相反。

我们创建了另一个框架,该框架复制了所有必需的参数,以便在被调用者框架顶部精确地包含参数的形参计数。它创建了一个被调用者函数的接口,因此后者无需知道参数数量。被调用者将始终能够使用与以前相同的计算结果来访问其参数,即[ai] = 2 + parameter_count - i - 1。
V8 具有一些特殊的内置函数,它们在需要通过 rest 参数或 arguments 对象访问其余参数时能够理解适配器框架。它们始终需要检查被调用者框架顶部的适配器框架类型,然后采取相应措施。
如你所见,我们解决了参数/寄存器访问问题,但是却添加了很多复杂性。需要访问所有参数的内置组件都需要了解并检查适配器框架的存在。不仅如此,我们还需要注意不要访问过时的旧数据。考虑对 add42 的以下更改:
function add42(x) { x += 42; return x;}现在,字节码数组为:
25 02 Ldar a0 ;; Load the first argument to the accumulator40 2a 00 AddSmi [42] ;; Add 42 to it26 02 Star a0 ;; Store accumulator in the first argument slotab Return ;; Return the accumulator如你所见,我们现在修改 a0。因此,在调用 add42(1, 2, 3)的情况下,参数适配器框架中的插槽将被修改,但调用者框架仍将包含数字 1。我们需要注意,参数对象正在访问修改后的值,而不是旧值。
从函数返回很简单,只是会很慢。还记得 LeaveInterpreterFrame 做什么吗?它基本上会弹出被调用者框架和参数,直到到达最大形参计数为止。因此,当我们返回参数适配器存根时,栈如下所示:
被调用者 add42 执行之后的框架状态。
我们需要弹出参数数量,弹出适配器框架,根据实际参数计数弹出所有参数,然后返回到调用者执行。
简单总结:参数适配器机制不仅复杂,而且成本很高。
我们可以做得更好吗?我们可以移除适配器框架吗?事实证明我们确实可以。
我们回顾一下之前的需求:
如果要消除多余的框架,则需要确定将参数放在何处:在被调用者框架中还是在调用者框架中。
假设我们将参数放在被调用者框架中。这似乎是一个好主意,因为无论何时弹出框架,我们都会一次弹出所有参数!
参数必须位于保存的框架指针和框架末尾之间的某个位置。这就要求框架的大小不会被静态地知晓。访问参数仍然很容易,它就是一个来自框架指针的简单偏移量。但现在访问寄存器要复杂得多,因为它会根据参数的数量而变化。
栈指针总是指向最后一个寄存器,然后我们可以使用它来访问寄存器而无需知道参数计数。这种方法可能行得通,但它有一个关键缺陷。它需要复制所有可以访问寄存器和参数的字节码。我们将需要 LdaArgument 和 LdaRegister,而不是简单的 Ldar。当然,我们还可以检查我们是否正在访问一个参数或寄存器(正或负偏移量),但这将需要检查每个参数和寄存器访问。显然这种方法太昂贵了!
好的,如果我们在调用者框架中放参数呢?
记住如何计算一个框架中参数 i 的偏移量:[ai] = 2 + parameter_count - i - 1。如果我们拥有所有参数(不仅是形式参数),则偏移量将为[ai] = 2 + parameter_count - i - 1.也就是说,对于每个参数访问,我们都需要加载实际的参数计数。
但如果我们反转参数会发生什么呢?现在可以简单地将偏移量计算为[ai] = 2 + i。我们不需要知道栈中有多少个参数,但如果我们可以保证栈中至少有形参计数那么多的参数,那么我们就能一直使用这种方案来计算偏移量。
换句话说,压入栈的参数数量将始终是参数数量和形参数量之间的最大值,并且在需要时使用 undefined 对象进行填充。
这还有另一个好处!对于任何 JS 函数,接收器始终位于相同的偏移量处,就在返回地址的正上方:[this] = 2。
对于我们的第 1 和第 4 条要求,这是一个干净的解决方案。另外两个要求又如何呢?我们如何构造 rest 参数和 arguments 对象?返回调用者时如何清理栈中的参数?为此,我们缺少的只是参数计数而已。我们需要将其保存在某个地方。只要可以轻松访问此信息即可,具体怎么做没那么多限制。两种基本选项分别是:将其推送到调用者框架中的接收者之后,或被调用者框架中的固定标头部分。我们实现了后者,因为它合并了 Interpreter 和 Optimized 框架的固定标头部分。
如果在 V8 v8.9 中运行前面的示例,则在 InterpreterArgsThenPush 之后将看到以下栈(请注意,现在参数已反转):
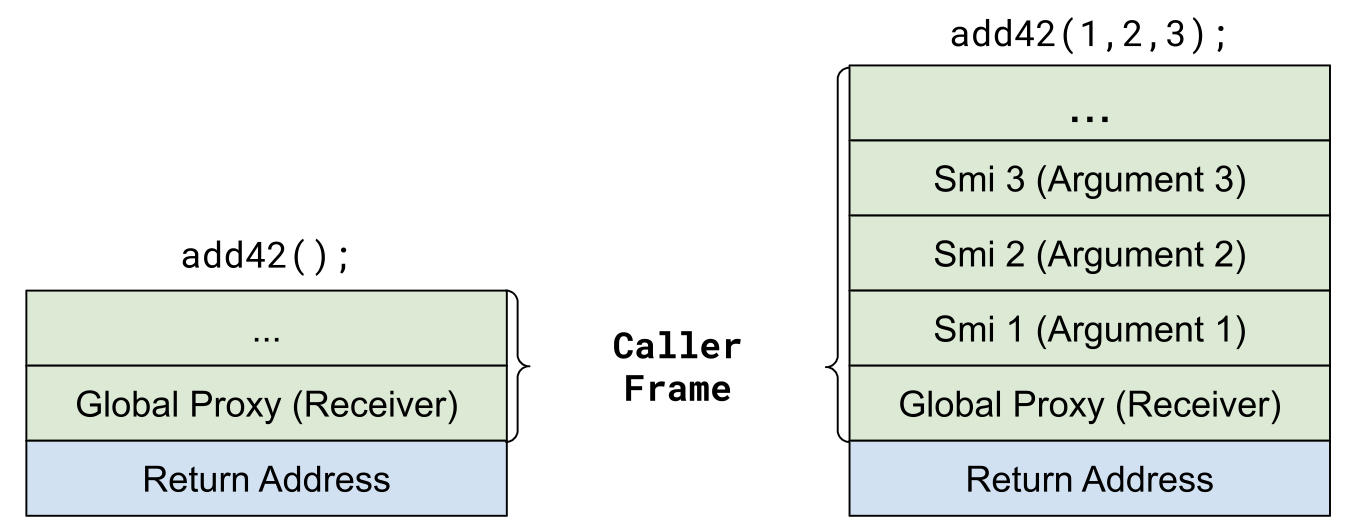
内置 InterpreterPushArgsThenCall 执行后的框架状态。
所有执行都遵循类似的路径,直到到达 InvokeFunctionCode。在这里,我们在申请不足的情况下处理参数,根据需要推送尽可能多的 undefined 对象。请注意,在申请过度的情况下,我们不会进行任何更改。最后,我们通过一个寄存器将参数数量传递给被调用者的 Code。在 x64 的情况下,我们使用寄存器 rax。
如果被调用者尚未进行优化,我们将到达
InterpreterEntryTrampoline,它会构建以下栈框架。
没有参数适配器的栈框架。
被调用者框架有一个额外的插槽,其中包含的参数计数可用于构造 rest 参数或 arguments 对象,并在返回到调用者之前清除栈中参数。
返回时,我们修改 LeaveInterpreterFrame 以读取栈中的参数计数,并弹出参数计数和形式参数计数之间的较大数字。
那么代码优化呢?我们来稍微更改一下初始脚本,以强制 V8 使用 TurboFan 对其进行编译:
function add42(x) { return x + 42; }function callAdd42() { add42(3); }%PrepareFunctionForOptimization(callAdd42);callAdd42();%OptimizeFunctionOnNextCall(callAdd42);callAdd42();在这里,我们使用 V8 内部函数来强制 V8 优化调用,否则 V8 仅在我们的小函数变热(经常使用)时才对其进行优化。我们在优化之前调用它一次,以收集一些可用于指导编译的类型信息。在此处阅读有关 TurboFan 的更多信息(
https://v8.dev/docs/turbofan)。
这里,我只展示与主题相关的部分生成代码。
movq rdi,0x1a8e082126ad ;; Load the function object <JSFunction add42>push 0x6 ;; Push SMI 3 as argumentmovq rcx,0x1a8e082030d1 ;; <JSGlobal Object>push rcx ;; Push receiver (the global proxy object)movl rax,0x1 ;; Save the arguments count in raxmovl rcx,[rdi+0x17] ;; Load function object {Code} field in rcxcall rcx ;; Finally, call the code object!尽管这段代码使用了汇编来编写,但如果你仔细看我的注释应该很容易能懂。本质上,在编译调用时,TF 需要完成之前在
InterpreterPushArgsThenCall、Call、CallFunction 和 InvokeFunctionCall 内置组件中完成的所有工作。它应该会有更多的静态信息来执行此操作并发出更少的计算机指令。
现在,让我们来看看参数数量和参数计数不匹配的情况。考虑调用 add42(1, 2, 3)。它会编译为:
movq rdi,0x4250820fff1 ;; Load the function object <JSFunction add42>;; Push receiver and arguments SMIs 1, 2 and 3movq rcx,0x42508080dd5 ;; <JSGlobal Object>push rcxpush 0x2push 0x4push 0x6movl rax,0x3 ;; Save the arguments count in raxmovl rbx,0x1 ;; Save the formal parameters count in rbxmovq r10,0x564ed7fdf840 ;; <ArgumentsAdaptorTrampoline>call r10 ;; Call the ArgumentsAdaptorTrampoline如你所见,不难为 TF 添加对参数和参数计数不匹配的支持。只需调用参数适配器 trampoline 即可!
然而这种方法成本很高。对于每个优化的调用,我们现在都需要进入参数适配器 trampoline,并像未优化的代码一样处理框架。这就解释了为什么在优化的代码中移除适配器框架的性能收益比在 Ignition 上大得多。
但是,生成的代码非常简单。从中返回非常容易(结尾):
movq rsp,rbp ;; Clean callee framepop rbpret 0x8 ;; Pops a single argument (the receiver)我们弹出框架并根据参数计数发出一个返回指令。如果实参计数和形参计数不匹配,则适配器框架 trampoline 将对其进行处理。
生成的代码本质上与参数计数匹配的调用代码相同。考虑调用 add42(1, 2, 3)。这将生成:
movq rdi,0x35ac082126ad ;; Load the function object <JSFunction add42>;; Push receiver and arguments 1, 2 and 3 (reversed)push 0x6push 0x4push 0x2movq rcx,0x35ac082030d1 ;; <JSGlobal Object>push rcxmovl rax,0x3 ;; Save the arguments count in raxmovl rcx,[rdi+0x17] ;; Load function object {Code} field in rcxcall rcx ;; Finally, call the code object!该函数的结尾如何?我们不再回到参数适配器 trampoline 了,因此结尾确实比以前复杂了一些。
movq rcx,[rbp-0x18] ;; Load the argument count (from callee frame) to rcxmovq rsp,rbp ;; Pop out callee framepop rbpcmpq rcx,0x0 ;; Compare arguments count with formal parameter countjg 0x35ac000840c6 <+0x86>;; If arguments count is smaller (or equal) than the formal parameter count:ret 0x8 ;; Return as usual (parameter count is statically known);; If we have more arguments in the stack than formal parameters:pop r10 ;; Save the return addressleaq rsp,[rsp+rcx*8+0x8] ;; Pop all arguments according to rcxpush r10 ;; Recover the return addressretl参数适配器框架是一个临时解决方案,用于实际参数和形式参数计数不匹配的调用。这是一个简单的解决方案,但它带来了很高的性能成本,并增加了代码库的复杂性。如今,许多 Web 框架使用这一特性来创建更灵活的 API,结果带来了更高的性能成本。反转栈中参数这个简单的想法可以大大降低实现复杂性,并消除了此类调用的几乎所有开销。
原文链接:
https://v8.dev/blog/adaptor-frame
延伸阅读:
关注我并转发此篇文章,即可获得学习资料~若想了解更多,也可移步InfoQ官网,获取InfoQ最新资讯~
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号