2021年最受欢迎的20个数据库学习技巧,你掌握了吗?
发表时间: 2022-05-24 17:03
数据库有多重要就不用我说了吧,懂得都懂!
今天就来看看 2021 最热门的数据库有哪些,该怎么学怎么用,文章开始之前先来看看这张图
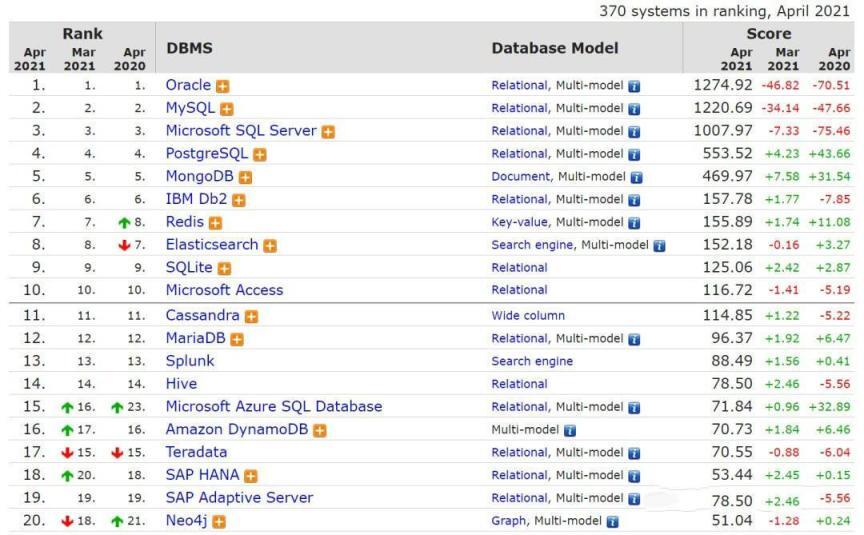
从图中数据可以看到,稳居前三的 Oracle、MySQL 和 Microsoft SQL Server 分数出现了较大幅度的下跌,分别减少 46.82、34.14 和 7.33 分。
其中 SQL Server 分数已经连续下跌了两个月。若与去年同期的数据相比,三者下跌的分数平均已达到 64 分。
后起之秀 PostgreSQL 和 MongoDB 依旧保持着稳步上升的趋势,分数与上个月相比有小幅度增加,与去年同期相比也平均增加了 40 分左右。
这个系列主要讲一讲常年混迹前列的三大数据库——即 Oracle、MySQL 和 Microsoft SQL Server 该怎么学习,学习资料也给大伙整理好了,需要的可以直接点击领取。
篇幅所限,本文就先讲一下 MySQL,有时间再发文讲讲其他的数据库,大伙感兴趣的话可以关注一波我
好了,话不多说,坐稳扶好,发车喽!
数据库——DataBase——DB,数据仓库,用于存储和管理数据。
稳定版本:5.7 ,8.0
体积小、速度快,成本底、招人成本底
安装建议:尽量不要使用 exe 安装,因为删除麻烦,且会进入注册表,尽可能使用压缩包安装。
MySQL 8.0 压缩包版的安装方法
配置文件如下:
[mysql]# 设置mysql客户端默认字符集default-character-set=utf8[mysqld]# 设置3306端口port = 3306# 设置mysql的安装目录basedir=D:\Program Files (x86)\mysql\mysql-8.0.19-winx64 # 设置mysql数据库的数据的存放目录,数据库会自动生成,不需要我们创建文件夹datadir= D:\Program Files (x86)\mysql\mysql-8.0.19-winx64\data# 允许最大连接数max_connections=20# 服务端使用的字符集默认为8比特编码的latin1字符集character-set-server=utf8# 创建新表时将使用的默认存储引擎default-storage-engine=INNODB# 跳过登录密码验证 在修改完密码后要把这句注释掉#skip-grant-tablesskip-grant-tables复制代码
update mysql.user set password=PASSWORD('123456')where User='root';flush privileges;复制代码
alter user 'root'@'localhost' identified by '123456'; 复制代码
#注意-p后不能加空格直接输入密码mysql -u root -p123456mysql -u root -p#再输入密码复制代码
可以查看历史执行记录,包括创建表,数据库等记录,比如 navicat 详细。
sc delete mysql 清空服务,立即删除 mysql
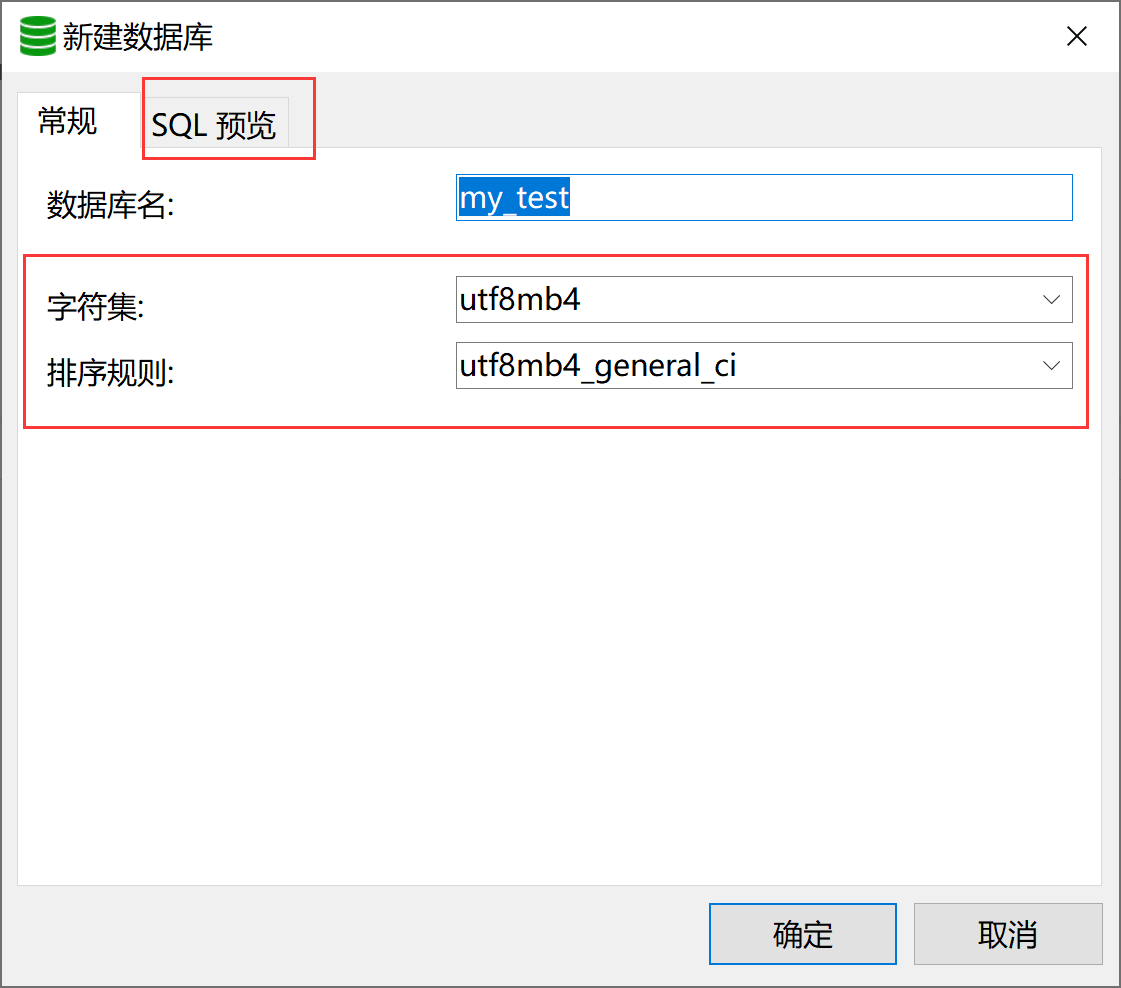
默认创建数据库字符集编码和排序规则如下
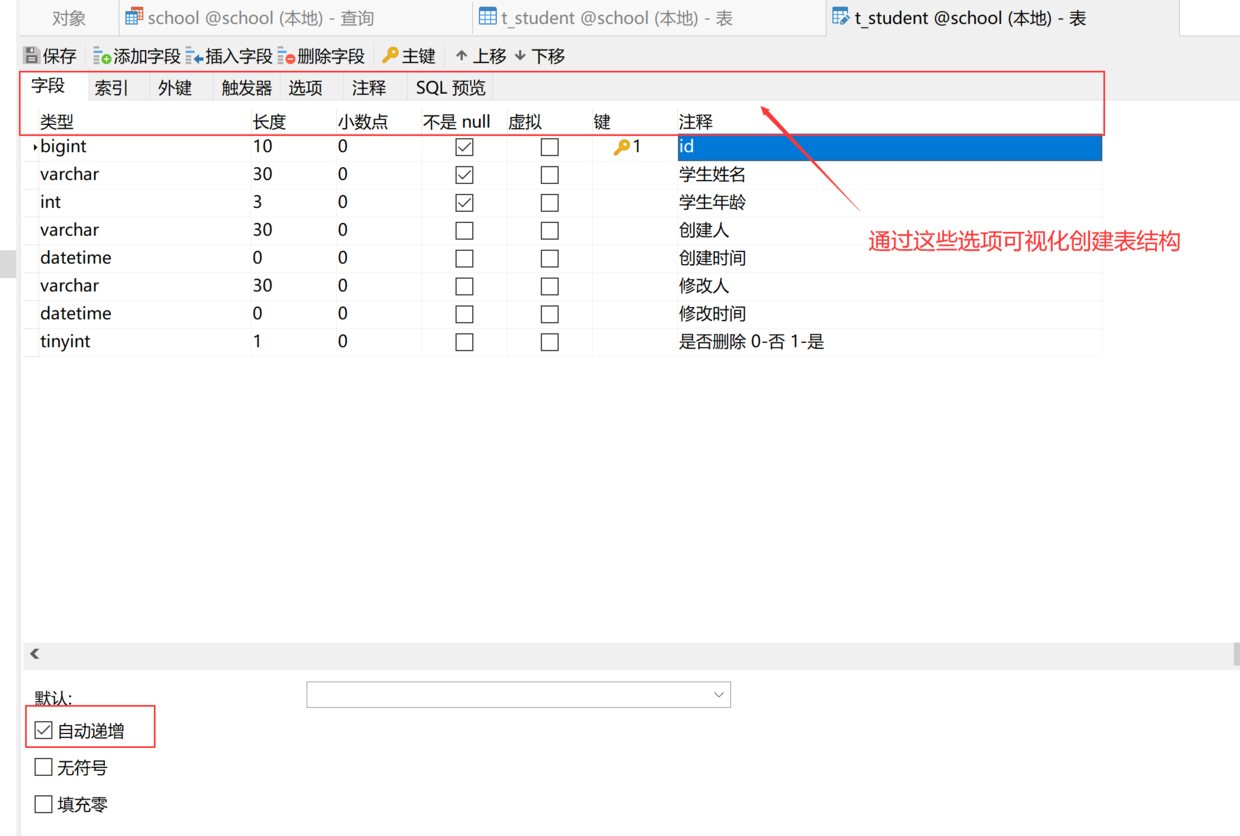
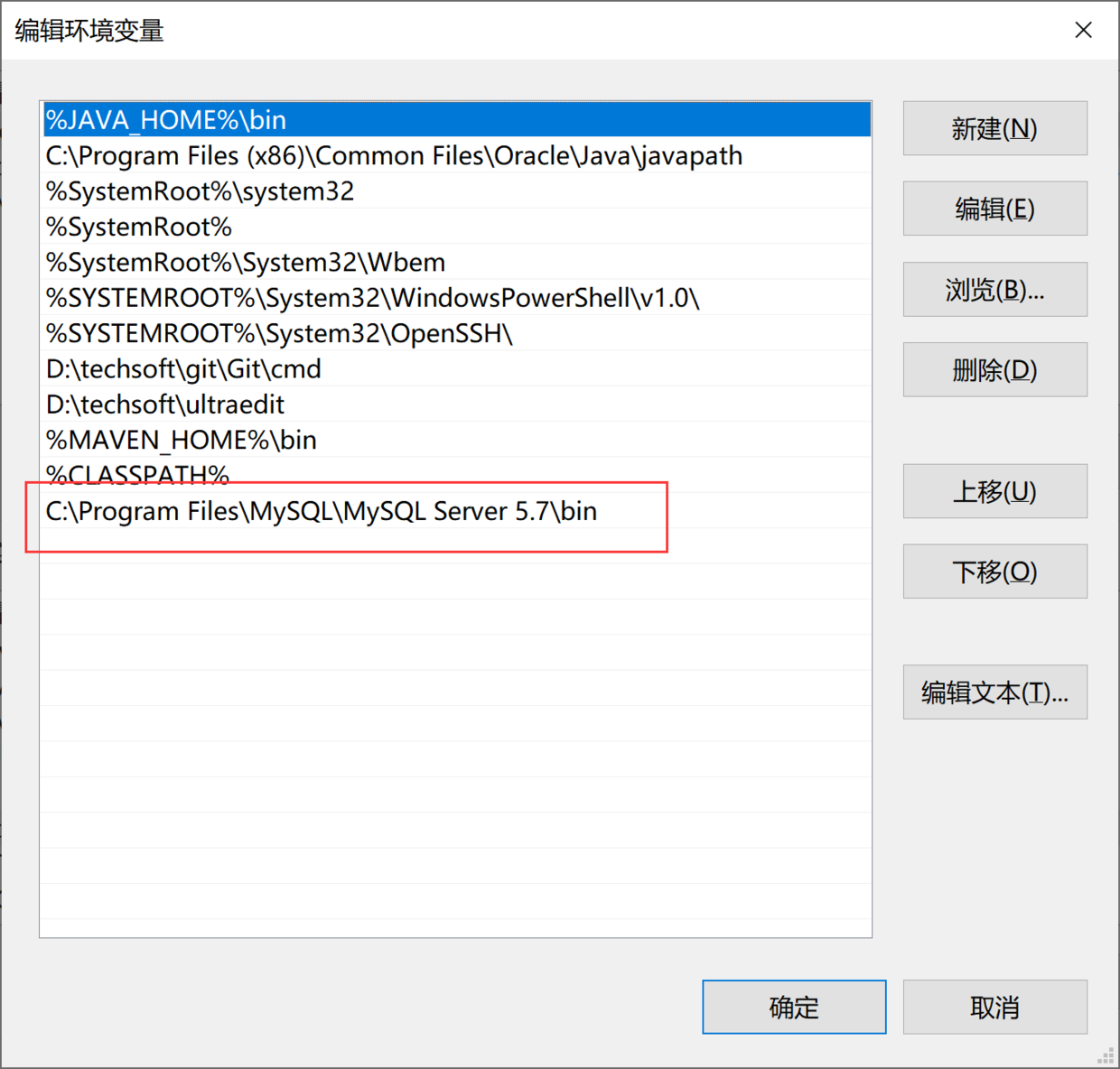
当执行命令行连接数据库报错'mysql' 不是内部或外部命令,也不是可运行的程序时,是因为我们没有配置好 mysql 的环境变量,这时候就需要我们往 path 上添加 mysql 的安装地址到 bin 文件夹路径到 path 上。
-- 在客户端查看mysql安装目录的语句show variables like "%char%";复制代码
#有以下两种命令行连接数据库的方法,第一种需要我们回车后输入密码mysql -u root -pmysql -u root -p123456复制代码

-- 5.7.29-log 查看mysql版本SELECT VERSION();-- 创建数据库CREATE DATABASE `my_test` CHARACTER SET utf8 COLLATE utf8_general_ci;-- 第二种CREATE DATABASE `my_test` CHARSET= utf8 COLLATE utf8_general_ci;-- 展示所有的数据库SHOW DATABASES;-- 切换数据库USE school;-- 创建表sql 我们一般通过navicat等定义创建表,上生产时再执行创建表的sql语句CREATE TABLE `t_student` ( `id` bigint(10) NOT NULL AUTO_INCREMENT COMMENT 'id', `name` varchar(30) NOT NULL COMMENT '学生姓名', `age` int(3) NOT NULL COMMENT '学生年龄', `create_user` varchar(30) DEFAULT NULL COMMENT '创建人', `crreate_tim` datetime DEFAULT NULL COMMENT '创建时间', `update_user` varchar(30) DEFAULT NULL COMMENT '修改人', `update_time` datetime DEFAULT NULL COMMENT '修改时间', `delete_flag` tinyint(1) DEFAULT NULL COMMENT '是否删除 0-否 1-是', PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='学生表';-- 修改用户密码USE mysql;UPDATE user SET password=PASSWORD('123456') WHERE user='root';-- 刷新权限FLUSH PRIVILEGES;show variables like "%char%";-- 查看数据库所有的表SHOW TABLES;-- 查看数据库中指定表的表结构信息DESCRIBE t_student;-- 退出数据库连接exit;-- 单行注释/*多行注释*/复制代码
utf8mb4 的编码,mb4 就是 most bytes 4 的意思,专门用来兼容四字节的 unicode。 为了节省空间,一般情况下使用 utf8 也就够了。 但是为了获取更好的兼容性,应该总是使用 utf8mb4 而非 utf8. 对于 CHAR 类型数据,utf8mb4 会多消耗一些空间,根据 Mysql 官方建议,使用 VARCHAR 替代 CHAR。
参考
首先,ci 是 case insensitive, 即 "大小写不敏感", a 和 A 会在字符判断中会被当做一样的; bin 是二进制, a 和 A 会别区别对待。所以我们在用 sql 进行匹配查找的时候,如果是 ci,则无论大小写都可以匹配出来,而如果是 utf8_bin 中的 bin 是二进制,则会区分大小写,这时候就只能唯一匹配到精确的那个值。
参考
参考
用来创建数据库中的各种对象-----表、视图,DDL 操作是隐性提交的!不能 rollback 。
CREATE,ALTER,DROP,TRUNCATE,COMMENT ,RENAME复制代码
数据的增删改。
INSERT,UPDATE,DELETE,EXPLAIN, PLAN复制代码
数据的查询
SELECT复制代码
用来设置或更改数据库用户或角色权限的语句,包括(grant,deny,revoke 等)语句 。
GRANT,REVOKE复制代码
数据库事务的控制语言。
COMMIT,SAVEPOINT,ROLLBACK,SET TRANSACTION复制代码
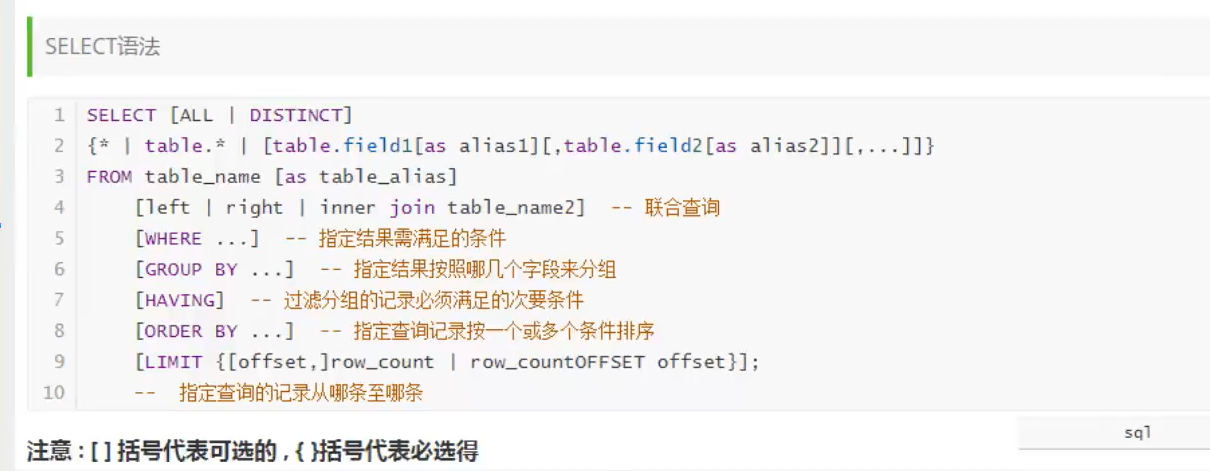
操作数据库> 操作数据库中的表> 操作数据库中的表的数据
-- 创建数据库 IF NOT EXISTS 表示不存在则创建,存在则跳过CREATE DATABASE IF NOT EXISTS `my_test` CHARACTER SET utf8 COLLATE utf8_general_ci;-- 删除数据库DROP DATABASE IF EXISTS `my_test`;-- 使用数据库USE school;-- 查看数据库SHOW DATABASES;复制代码
数值类型
注:在金融等金额计算时,一般使用 decimal 来表示金额大小,因为使用 double 会有精度问题,而使用字符串形式的浮点数则可以完整得表示出金额的大小。
字符串
日期时间
注:yyyy-MM-dd HH:mm:ss 表示年月日时分秒。月:用 MM 大写表示是与时间单位的 mm 作为区别,而时:HH 用大写表示 24 小时制,用小写 hh 则是 12 小时制。
VARCHAR :varchar 在 mysql 中满足最大行限制,也就是 65535(16k)字节,在 mysql 中使用 uft-8(mysql 中的 utf-8 和我们正 常的编码 utf-8 不同)字符集一个字符占用三个字节。
①使用 utf-8 字符编码集 varchar 最大长度是 (65535-1)/3=21844 个字符(由于会有 1 字节的额外占用空间开销, 所以减 1)。②使用 utf-8mb4 字符集(mysql 中 utf-8mb4 字符集也就是我们通常使用的 utf-8 字符集),mysql 中使用 utf8mb4 字符集一个字符占用 4 个字节,所以 varchar 最大长度是(65535-1)/4=16383 个字符(由于 1 字节额外占用空间开销,所以减 1)。
TEXT :最大限制是 64k, 采用 utf-8 字符集,(262144-1)/3=87381 个字符。采用 utf-8mb4 字符集,(262144-1)/4=65535 个字符。参考
无符号——Unsigned
0 填充——zerofill
自增——AUTO_INCREMENT
非空 NULL NOT NULL
默认——DEFAULT
id 主键version 版本号,用于乐观锁delete_flag 删除状态,用于伪删除gmt_create 创建时间gmt_update 修改时间复制代码
Q:int(5)以及 varchar(20)长度表示的是什么?
A:int 数据类型是固定的 4 个字节;
但是 int(5)和 int(11)区别在于,显示的数据位数一个是 5 位一个是 11 位,在开启 zerofill(填充零)情况下,若 int(5)存储的数字长度是小于 5 的则会在不足位数的前面补充 0,但是如果 int(5)中存储的数字长度大于 5 位的话,则按照实际存储的显示(数据大小在 int 类型的 4 个字节范围内即可),也就是说 int(M)的 M 不代表数据的长度;varchar(20)中的 20 表示的是 varchar 数据的数据长度最大是 20,超过则数据库不会存储,直接报错;
总结:
int(M) M 表示的不是数据的最大长度,只是数据宽度,跟 0 填充有关,并不影响存储多少位长度的数据;
varchar(M) M 表示的是 varchar 类型数据在数据库中存储的最大长度,超过则不存;参考
DECIMAL(M,D) 中,M 就是总长度,D 就是小数点后面的长度,超出范围或者长度不够会被截断或补位 。比如: DECIMAL(5,4)=>总长度不超过 5 位数字,并且小数点后头必须要 4 位数字:1.2345 DECIMAL(14,9)=>总长度 5 位数字,整数 5 位,小数点后 9 位:12345.123456789
-- 注意点-- 表内容在英文()里,表名、字段名和索引名尽量用``括起来-- AUTO_INCREMENT 自增-- 字符串使用时用 ''括起来-- 所有语句后面都要加英文逗号 ,最后一句不用加-- PRIMARY KEY 主键,一张表一般一个唯一主键CREATE TABLE IF NOT EXISTS `t_student` ( `id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 'id', `name` VARCHAR(20) NOT NULL DEFAULT '佚名' COMMENT '姓名', `age` INT(3) DEFAULT NULL COMMENT '年龄', `gender` TINYINT(2) DEFAULT NULL COMMENT '性别', `birthday` DATETIME DEFAULT NULL COMMENT '出生日期', PRIMARY KEY(`id`), KEY `idx_name`(`name`)) ENGINE= INNODB AUTO_INCREMENT=1000 DEFAULT CHARACTER SET utf8mb4 COLLATE = utf8mb4_general_ci COMMENT '学生表';CREATE TABLE IF NOT EXISTS `t_student` ( `id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 'id', `name` VARCHAR(20) NOT NULL DEFAULT '佚名' COMMENT '姓名', `age` INT(3) DEFAULT NULL COMMENT '年龄', `gender` TINYINT(2) DEFAULT NULL COMMENT '性别', `birthday` DATETIME DEFAULT NULL COMMENT '出生日期', PRIMARY KEY(`id`), KEY `idx_name`(`name`)) ENGINE= INNODB AUTO_INCREMENT=1000 DEFAULT charset=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='学生表';复制代码
注:[表类型][字符集设置] [表名注释]通常不写默认是数据库的默认配置
CREATE TABLE IF NOT EXISTS `表名` (`字段名` 列类型 [属性] [注释], `字段名` 列类型 [属性] [注释]) [表类型] [字符集设置] [表名注释]复制代码
-- 查看t_student表的创建语句SHOW CREATE TABLE t_student;-- 查看创建数据库的语句SHOW CREATE DATABASE school;-- 显示表结构DESC t_student;复制代码
存储引擎是针对表的,每张表都可以设置自己的存储引擎。我们对数据库会设置默认的存储引擎,当我们建表时没有明确指定表的存储引擎时默认就是数据库设置的存储引擎。比较常见的存储引擎有:
MyISAM——节约空间,速度较快
InnoDB——安全性高,支持事务和多表多用户操作
Mysql 数据库的文件存储在装目录下的 data 文件夹下,一个数据库对应一个文件夹,如数据库 school 对应 data 目录下的 school 文件夹,因此数据库本质还是文件的存储。
#mysql数据存储位置,安装目录下的data文件夹下C:\ProgramData\MySQL\MySQL Server 5.7\Data复制代码
一张表对应两个文件分别是:
一张表对应两个文件分别是:
在创建表结构时设置如下,建议使用这个:
DEFAULT CHARSET=utf8mb4复制代码
不设置会是 mysql 默认的字符集编码,Mysql 默认字符集编码是 Latin1,不支持中文。
第二种设置字符集编码是在 mysql 的配置文件 my.ini 中设置默认的字符集编码为 utf8mb4。建议使用第一种在表结构文件中设置,这样在其他服务器的 mysql 中就一定是我们设置的字符集编码,因为别人不一定在配置文件中设置了默认的字符集编码为 utf8mb4。
character-set-server=utf8mb4复制代码
修改
-- 修改表名 ALTER TABLE 旧表名 RENAME AS 新表名;ALTER TABLE t_student RENAME AS student;-- 增加表字段 ALTER TABLE 表名 ADD 字段名 列属性ALTER TABLE student ADD address VARCHAR(30) DEFAULT NULL COMMENT '地址';-- 修改表字段 ALTER TABLE 表名 MODIFY 字段名 [列属性];ALTER TABLE student MODIFY address TIMESTAMP ;-- CHANGE 字段可以重命名和修改约束, MODIFY 只能修改约束ALTER TABLE student CHANGE update_time update_date date ;-- 删除表字段 ALTER TABLE 表名 DROP 字段名;ALTER TABLE student DROP address;复制代码
删除
--删除表 如果存在则删除DROP TABLE IF EXISTS student;复制代码
CREATE TABLE IF NOT EXISTS `t_grade` ( id BIGINT(10) NOT NULL AUTO_INCREMENT COMMENT '年级id', grade_name VARCHAR(30) NOT NULL COMMENT '年级名', PRIMARY KEY (`id`)) ENGINE=INNODB CHARSET=utf8mb4 COMMENT '年级表';-- 创建外键方式1 -- 1、学生表的grade_id字段要添加年级表的外键索引-- 2、给这个外键添加约束(执行引用)CREATE TABLE IF NOT EXISTS `t_student` ( `id` BIGINT ( 10 ) NOT NULL AUTO_INCREMENT COMMENT 'id', `name` VARCHAR ( 30 ) NOT NULL COMMENT '学生姓名', `age` INT ( 3 ) NOT NULL COMMENT '学生年龄', `grade_id` BIGINT ( 10 ) NOT NULL COMMENT '年级id', `create_user` VARCHAR ( 30 ) DEFAULT NULL COMMENT '创建人', `crreate_time` datetime DEFAULT NULL COMMENT '创建时间', `update_user` VARCHAR ( 30 ) DEFAULT NULL COMMENT '修改人', `update_time` datetime DEFAULT NULL COMMENT '修改时间', `delete_flag` TINYINT ( 1 ) DEFAULT NULL COMMENT '是否删除 0-否 1-是', `address` VARCHAR ( 30 ) DEFAULT NULL COMMENT '地址', PRIMARY KEY ( `id` ) , KEY (`fk_grade_id`) , CONSTRAINT `fk_grade_id` FOREIGN KEY `grade_id` REFERENCES `t_grade`(`id`)) ENGINE = INNODB DEFAULT CHARSET = utf8mb4 COMMENT = '学生表';-- 创建外键方式2ALTER TABLE t_student ADD CONSTRAINT `fk_grade_id` FOREIGN KEY(`grade_id`) REFERENCES `t_grade`(`id`);复制代码
注意:外键是物理外键,属于数据库级别的外键,必须管理关系导致的问题。每次做 delete 或 update 时都要考虑外检约束,导致开发和测试都不方便。因此强制不得使用外键和级联,一切外键概念必须在应用层解决。
-- 插入语句 -- 格式 insert into 表名([字段名1,字段名2,字段名3...]) values (值1,值2,值3...), (值1,值2,值3...);-- 插入表的字段如果省略不写则需要在传入值时要所以字段值都填上并且与字段顺序一一对应匹配-- Column count doesn't match value count at row 1 INSERT INTO t_student VALUES (null,'艾米');INSERT INTO t_student VALUES (6,'艾米2',18,1,'2002-10-10');-- 对于自增主键我们在插入时可以使用null代替,这样数据库会自增帮我们插入INSERT INTO t_student VALUES (null,'艾米2',18,1,'2002-10-10');insert into t_student(`name`,age) values('大青山',19);-- 插入多条数据用(),()隔开insert into t_student(`name`,age) values('池傲天',20),('霍恩斯',200);复制代码
-- 修改-- 语法 UPDATE 表名 SET column_name=value,[column_name=value] where [条件]UPDATE t_student SET `name`= '年轻的艾米',`age`=6 WHERE id =1;UPDATE t_student SET `name`= '年轻的艾米',`age`=6 WHERE id = null;-- 不加where条件的话则更新全部数据,所以要注意UPDATE t_student SET `name`= '年轻的艾米',`age`=6 ;-- 修改id=2到5之间的数据,是闭区间update t_student set grade_id = '7' where id between 2 and 5;-- or 或update t_student set grade_id='8' where id=1 or id =6;-- and 和update t_student set grade_id='9' where id=1 and age=20;-- 设置的value值可以是一个具体的值,也可以是变量update t_student set crreate_time = CURRENT_TIME where id=1 and age=20;update t_student set update_time = t_student.crreate_time where id=1 and age=20;复制代码
-- 语法 DELETE FROM 表名 [WHERE 条件]-- 删除指定条件下的数据DELETE FROM t_student WHERE id =2;-- 删除所有数据,避免使用DELETE FROM t_student ;-- 更好的表数据删除使用TRUNCATE语句-- TRUNCATE 表名 -- TRUNCATE 完全清空数据库表truncate t_student;复制代码
当重启数据库时,InnoDB 的自增列会归零,因为计数器存在内存中,断电即失;而 MyISAM 计数器存放在文件中,不会断电或者重启丢失。
-- 查询表全部字段全部数据 SELECT * from student;-- 查询指定字段SELECT studentno,studentname FROM student;-- 字段和表都可以起别名,可以用as 或者空格SELECT studentno as 学号,studentname 姓名 FROM student s;-- 拼接函数 concat-- 姓名:张伟前来报到,联系号码:13800001234SELECT CONCAT('姓名:',studentname,'前来报到,联系号码:',phone) FROM student;-- DISTINCT去重SELECT DISTINCT r.studentno FROM result r;复制代码
-- 查看系统版本,(函数)形式-- 5.7.17-logSELECT VERSION();-- 用于计算,(表达式) -- 300SELECT 100*5-200 AS 结果;SELECT 100*5-200 AS total;-- 查看自增的步长,即每次自增多少,(变量)-- 1SELECT @@auto_increment_increment;-- 筛选出成绩加1分查看 SELECT s.studentno `no` , s.studentresult + 1 score FROM result s;SELECT s.studentno , s.studentresult/10 as score FROM result s;复制代码
MySQL5.7官网方法与函数操作符地址
where 条件结果问布尔值,由一个或多个表达式组成。
逻辑运算符 与或非可以使用下面两种语句都行,尽量使用第一种英文。
-- 与或非的其他写法展示-- and 与SELECT * FROM result s where s.studentresult >1 && s.studentresult <80;-- or 或SELECT * FROM result s where s.studentresult =70 || s.studentresult =68;-- not 非SELECT * FROM result s where not s.studentresult =70;复制代码
-- 模糊查询 like %表示0到任意个字符, _表示一个字符-- 查询姓张,名字为2个字的学生SELECT * FROM student s where s.studentname like '张_';-- 查询名字中带伟的学生SELECT * FROM student s where s.studentname like '%伟%';-- in 查询SELECT * FROM student s where s.studentno in(1000,1001);复制代码
-- 左联、右联等外联是要用on来关联否则报错,on确定主表,无论条件如何主表数据都会返回然后进行筛选。SELECT * FROM student s LEFT JOIN result r on s.studentno = r.studentno where s.studentname='张伟';-- 内联时用on或者where进行关联都可以SELECT * FROM student s INNER JOIN result r where s.studentno = r.studentno and s.studentname='张伟';SELECT * FROM student s JOIN result r where s.studentno = r.studentno and s.studentname='张伟';-- 联表查询思路/*1、分析需求要的字段来自哪些表2、确定使用哪种连接查询3、确定交叉点,比如订单号id4、判断的条件*/-- 学生年级联表查询select s.studentno,s.studentname,g.gradename,r.studentresult,sub.subjectname from student s INNER JOIN grade g ON s.gradeid = g.gradeid INNER JOIN result r ON s.studentno = r.studentno left JOIN `subject` sub ON sub.subjectno = r.subjectno;-- 自连接,设计表时把有父子关系的两种层级表合并成一张表-- 进行查询时自己和自己关联查询SELECT a.categoryname 父类别,b.categoryname 子类别 from category a,category b where a.categoryid= b.pid;复制代码
1000 张伟 大二 85 高等数学-11000 张伟 大二 70 高等数学-21000 张伟 大二 68 高等数学-31000 张伟 大二 98 高等数学-41000 张伟 大二 58 C语言-1复制代码
参考
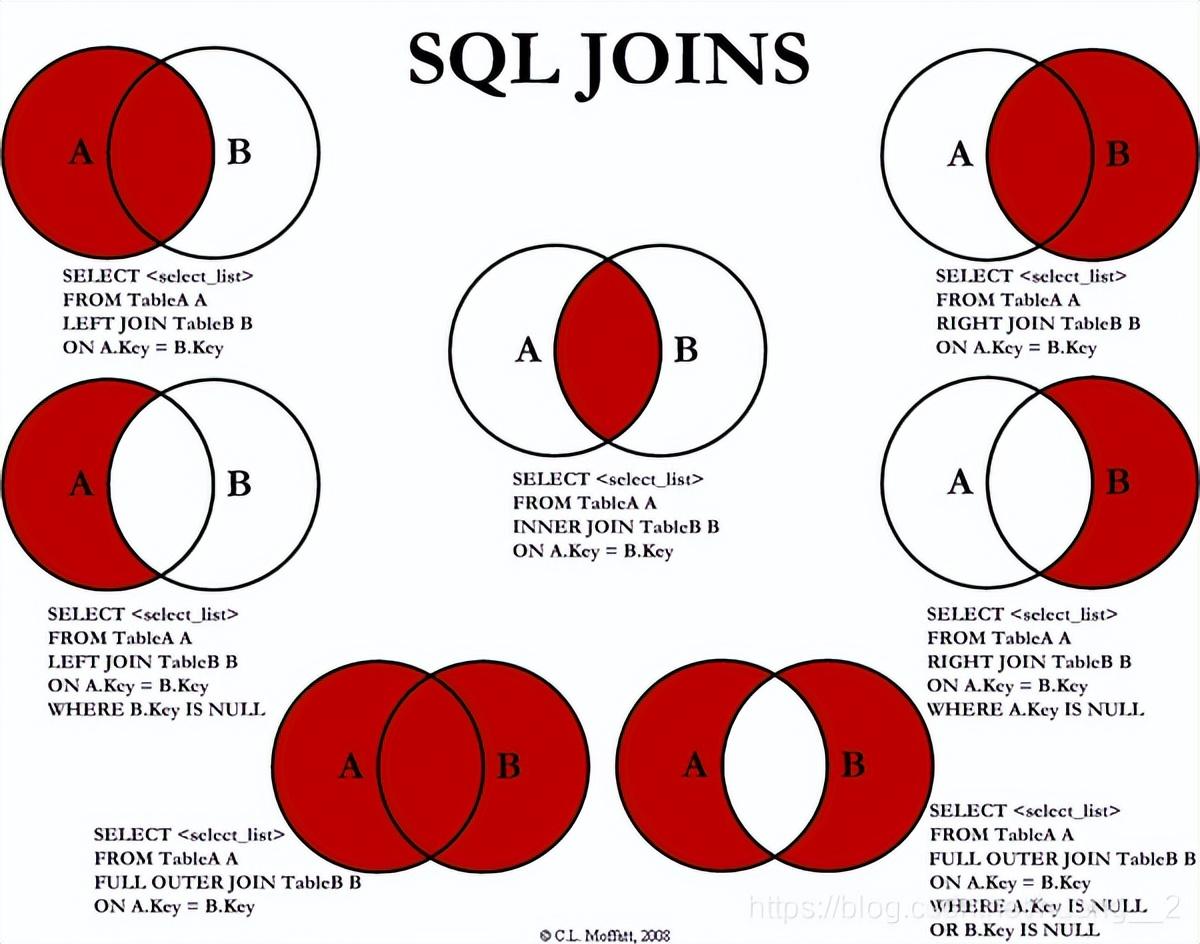
Join 时 where 和 on 的区别关键在于 left join,right join,full join(inner join)的特殊性,不管 on 上的条件是否为真都会返回 left 或 right 表中的记录,full 则具有 left 和 right 的特性的并集。 而 inner jion 没这个特殊性,则条件放在 on 中和 where 中,返回的结果集是相同的。
在使用 mysql 数据库时,使用 left join 或者 right join 都必须要使用关键字 on,否则就 sql 执行就报错。可以这样理解:on 是建立外连的桥,两张表如何连接就靠 on 后面的条件。因为外连分主次表,数据以主表为基础,次表对应连接,如果没有 on 来建立连接,那么次表的数据就不知道如何对应上主表。而内连,又称为直连,不存在主次表之分,取得是两者的交集,因此不需要 on。
外连接时,on 条件是在生成临时表时使用的条件,它不管 on 中的条件是否为真,都会返回左边表中的记录。而 where 条件是在临时表生成好后,再对临时表进行过滤的条件。
参考
参考2
缓解数据库压力,体验更好,返回数据更快,瀑布流方式分页
-- 排序 ORDER BY 字段名 DESC -- 升序 ASC ,降序 DESCSELECT * FROM result r ORDER BY r.studentresult DESC;-- 分页 limit offset,pagesize 参数描述:(起始值,从0开始),(页面大小) SELECT * FROM result r ORDER BY r.studentresult DESC LIMIT 0,2;SELECT * FROM result r ORDER BY r.studentresult DESC LIMIT 2,2;复制代码

/** * 当前分页总页数 */ default long getPages() { if (getSize() == 0) { return 0L; } long pages = getTotal() / getSize(); if (getTotal() % getSize() != 0) { pages++; } return pages; } /** * 计算当前分页偏移量 */ default long offset() { long current = getCurrent(); if (current <= 1L) { return 0L; } return (current - 1) * getSize(); }复制代码
-- 子查询关联查询SELECT DISTINCT s.studentno,s.studentname FROM student s INNER JOIN result r on s.studentno=r.studentnoWHERE r.studentresult >=80 and r.subjectno=(SELECT subjectno from `subject` sub where sub.subjectname='高等数学-4');-- 多张表联表查询 SELECT DISTINCT s.studentno,s.studentname FROM student s INNER JOIN result r on s.studentno=r.studentnoINNER JOIN `subject` sub ON sub.subjectno=r.subjectnoWHERE r.studentresult >=80 and sub.subjectname='高等数学-4';-- 嵌套查询SELECT DISTINCT s.studentno,s.studentname FROM student s where s.studentno IN(SELECT r.studentno FROM result r WHERE r.studentresult >=80 and r.subjectno =(SELECT subjectno from `subject` sub where sub.subjectname='高等数学-4'))复制代码



where 的条件不能用聚合函数,要改用 having 过滤。

-- 通过分组查询各个科目的最高分平均分等聚合统计-- GROUP BY r.subjectno 通过什么字段来分组,该字段 不需要是在展示的列名上SELECT s.subjectname , MAX(r.studentresult) max, min(r.studentresult) min, avg(r.studentresult) avg FROM result r INNER JOIN`subject` s ON r.subjectno = s.subjectno GROUP BY r.subjectno HAVING avg >=80;复制代码
count(列名)会忽略字段中数据为 null 的值,这时候不会计入总数,而 count(1)、count(*) 不会忽略 null 值,只要这一行有数据就会计数,本质是计算行数。
执行效果上:
执行效率上:
什么是 MD5?
MD5 信息摘要算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数,可以产生出一个 128 位(16 字节)的散列值(hash value),用于确保信息传输完整一致。
MD5 不可逆,相同的密码值 MD5 是一样的,因此 MD5 破解网站的原理是后台存储了 MD5 的字典,用于匹配 MD5 加密后的值和加密前的值。
MD5 加盐:盐被称作“Salt 值”,这个值是由系统随机生成的,并且只有系统知道。即便两个用户使用了同一个密码,由于系统为它们生成的 salt 值不同,散列值也是不同的。
-- 创建用户表,测试md5加密CREATE table `user`(`id` BIGINT(8) UNSIGNED auto_increment NOT null COMMENT 'id',`name` varchar(20) NOT null COMMENT '姓名',`pwd` VARCHAR(50) NOT null COMMENT '密码',PRIMARY KEY(`id`))ENGINE=INNODB DEFAULT charset=utf8mb4;-- 明文密码insert into `user`(`name`,`pwd`)VALUES('艾米','123456'),('大青山','123456'),('霍恩斯','123456'),('雷葛','123456');-- 使用MD5加密-- 指定用户加密update `user` set pwd=MD5(pwd) where `name`='艾米';-- 更新所有用户加密 -- 注意加密后的MD5值是一样的,之所以艾米用户的值不一样是因为更新所有导致二次加密了update `user` set pwd=MD5(pwd) ;-- 插入时加密insert into `user`(`name`,`pwd`)VALUES('绿儿',MD5('123456'));-- 校验加密,相当于用户登录-- 将用户登录的密码用md5加密后与数据库的值比对SELECT * FROM `user` u where u.`name`='绿儿' and u.pwd = MD5('123456');复制代码
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
事务前后数据的完整性必须保持一致。
事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响
因为隔离性导致的脏读、幻读、不可重复读。
指一个事务读取了另外一个事务未提交的数据。
是指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致。(一般是行影响,多了一行)
在一个事务内读取表中的某一行数据,多次读取结果不同。(这个不一定是错误,只是某些场合不对)
set transaction isolation level 设置事务隔离级别 select @@tx_isolation 查询当前事务隔离级别
设置描述:Serializable 可避免脏读、不可重复读、虚读情况的发生。(串行化)Repeatable read 可避免脏读、不可重复读情况的发生。(可重复读)Read committed 可避免脏读情况发生(读已提交)。Read uncommitted 最低级别,以上情况均无法保证。(读未提交)
数据库ACID参考
-- 关闭事务自动提交SET autocommit =0;-- mysql默认开启事务自动提交 SET autocommit =1;START TRANSACTION;insert into `user`(`name`,`pwd`)VALUES('艾米','123456'),('大青山','123456'),('霍恩斯','123456'),('雷葛','123456');-- 成功提交事务持久化COMMIT;-- 回滚,一般用于失败后回滚数据ROLLBACK;-- 保存点SAVEPOINT a;-- 回滚到一个事务的保存点ROLLBACK TO SAVEPOINT a;-- 释放保存点RELEASE SAVEPOINT a;复制代码
MySQL 官方对索引的定义为:索引(Index)是帮助 MySQL 高效获取数据的数据结构。
索引的本质:索引是数据结构。

MySQL索引背后的数据结构及算法原理
一张图彻底搞懂MySQL的 explain

-- 测试表 CREATE TABLE `t_user` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id', `name` varchar(20) NOT NULL COMMENT '姓名', `email` varchar(50) DEFAULT NULL COMMENT '邮箱', `phone` varchar(20) DEFAULT NULL COMMENT '手机号码', `pwd` varchar(50) DEFAULT NULL COMMENT '密码', `age` TINYINT(3) DEFAULT NULL COMMENT '年龄', `create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `update_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHAstudent.gradeidRSET=utf8mb4 COMMENT='测试用户表';-- 插入100w数据函数-- 写函数前先更改mysql分隔符为$$ ,写函数标记DELIMITER $$ CREATE FUNCTION 100w_data() RETURNS INT BEGIN DECLARE num INT DEFAULT 1000000; DECLARE i INT DEFAULT 1; WHILE i<num DO INSERT INTO t_user(`name`,`email`,`phone`,`pwd`,`age`)VALUES(CONCAT('VIP客户',i),'884849324@qq.com',CONCAT('15',FLOOR(RAND()*1000000000)),UUID(),FLOOR(RAND()*100)); SET i =i+1;END WHILE;RETURN i;END-- 执行函数SELECT 100w_data();-- 删除函数DROP FUNCTION 100w_data;-- mysql8.0才能并行SELECT /*+PARALLEL(8)*/ 100w_data(); -- 未加索引前耗时1s。加索引后耗时0.01-0.02sSELECT * from t_user u where u.`name`='VIP客户100000'; -- 增加索引ALTER TABLE t_user ADD INDEX idx_name(`name`);复制代码
首选我们可以通过可视化工具进行用户的创建,权限的添加和删除。

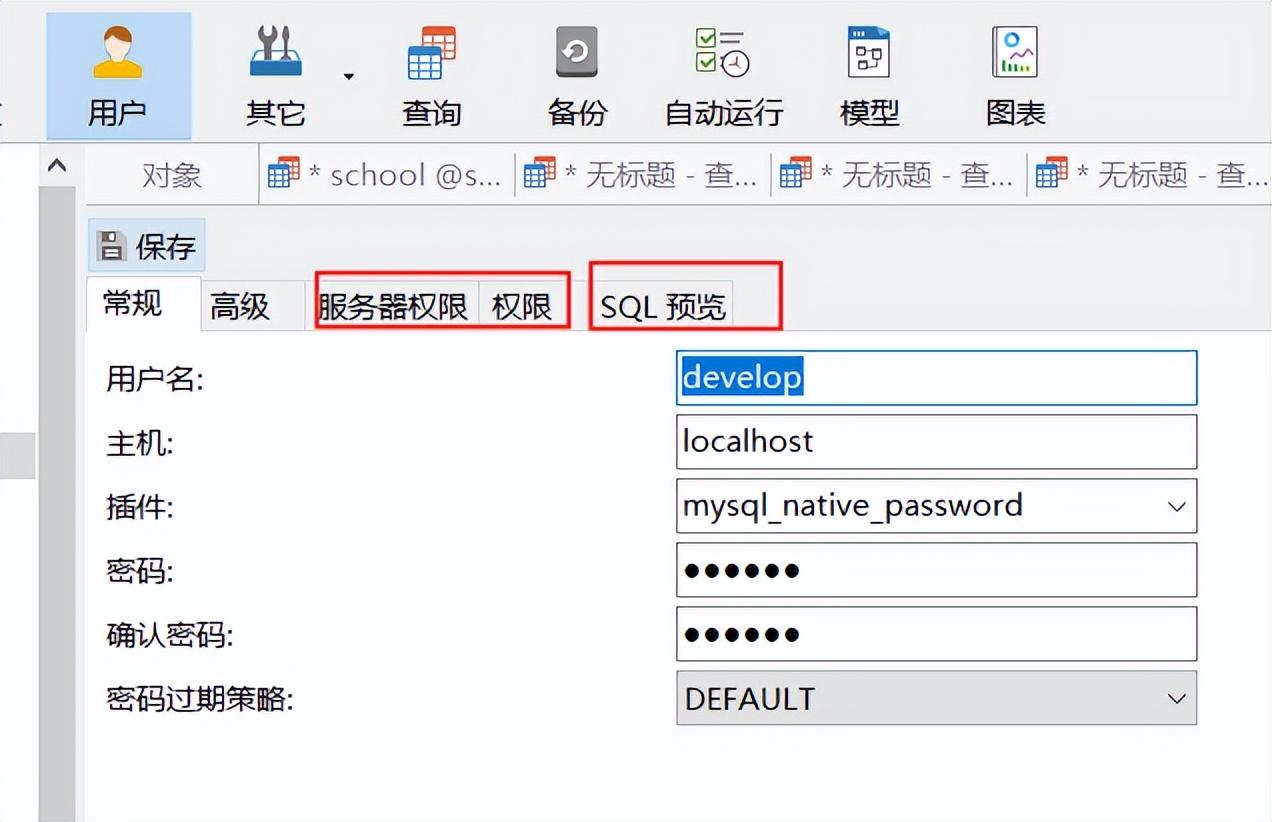
但在 Linux 服务器上我们没有可视化界面因此要使用 sql 语句执行。
-- % 是允许所有的主机都可以连接 CREATE USER `roy`@`localhost` IDENTIFIED BY '123456';GRANT Alter, Alter Routine, Create, Create Routine, Create Temporary Tables, Create User, Create View, Delete, Drop, Event, Execute, File, Grant Option, Index, Insert, Lock Tables, Process, References, Reload, Replication Client, Replication Slave, Select, Show Databases, Show View, Shutdown, Super, Trigger, Update ON *.* TO `roy`@`localhost`;-- 创建用户 CREATE USER develop IDENTIFIED by '123456';复制代码


为什么要备份:
MySQL 数据库备份的方式
右击要导出的数据库或表转存数据,可以转存表结构或者表结构及数据。
导入就直接把文件执行即可。
#mysqldump -h主机 -u用户名 -p密码 数据库 表名 >物理磁盘位置/文件名mysqldump -hlocalhost -uroot -p123456 school student >D:a.sql#导出整个数据库mysqldump -hlocalhost -uroot -p123456 school >D:a.sql#多张表导出,用空格隔开,命令行是用空格#mysqldump -h主机 -u用户名 -p密码 数据库 表1 表2 表3 >物理磁盘位置/文件名mysqldump -hlocalhost -uroot -p123456 school student >D:a.sql复制代码
#登录的情况下导入,先切换到指定的数据库#source 备份文件source d:a.sql#未登录状态 <表示导入 >表示导出#mysql -u用户名 -p密码 库名< 备份文件mysql -uroot -p123456 school student <D:a.sql复制代码


找技术的知识的话比如博客要找有例子的,这样看比较清楚简单一点。
原子性:保证每一列不可再分。
前提:满足第一范式
单一职责原则:每张表只描述一件事情。
前提:满足第一、第二范式
确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
也就是订单表里只能关联商品 id,而不能把商品价格、商品种类、商品名称等商品表信息都加进来。
原理如下代码,先判断出传入的保存/更新对象是否包含主键 id,包含的话执行根据 id 查询语句,如果得到数据则走更新操作,否则执行插入操作。
public boolean saveOrUpdate(T entity) { if (null == entity) { return false; } else { TableInfo tableInfo = TableInfoHelper.getTableInfo(this.entityClass); Assert.notNull(tableInfo, "error: can not execute. because can not find cache of TableInfo for entity!", new Object[0]); String keyProperty = tableInfo.getKeyProperty(); Assert.notEmpty(keyProperty, "error: can not execute. because can not find column for id from entity!", new Object[0]); Object idVal = ReflectionKit.getFieldValue(entity, tableInfo.getKeyProperty()); return !StringUtils.checkValNull(idVal) && !Objects.isNull(this.getById((Serializable)idVal)) ? this.updateById(entity) : this.save(entity); } }复制代码
本文先写到这吧 ,有人看的话写写其他的数据库。
都看到这了,点个赞加个关注不过分吧各位看官老爷们!
小伙伴们有兴趣想了解内容和更多相关学习资料的请点赞收藏+评论转发+关注我,后面会有很多干货。

版权声明: 本文为 作者【北游学Java】的原创文章。
原文链接:【
https://xie.infoq.cn/article/bd09ff84c77b365bf68f62dc5】。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号