系统延迟:了解你的网络延迟是否在合理范围内
发表时间: 2024-07-13 16:15

本文来自微信公众号:云算计(ID:gh_0068c4e23a81),作者:曹亚孟,原文标题:《从1纳秒到2天,谈IT系统的延迟指标》,题图来自:视觉中国
前言一、为什么要谈延迟
我一直就想写一篇技术分析文章,介绍从1纳秒开始,IT系统内经历了多少次刹那芳华、多少种白驹过隙。最近看了一本谈IT技术架构的电子书(thebyte.com.cn),其2.1章节就是“了解各类延迟指标”,我一时技痒,决定写下这篇文章。
了解掌握IT系统中各种常见动作的延迟指标,并不是卖弄技巧和炫耀专业性。这些延迟指标,和性能调优、流程和资源优化都有着巨大的关联:各种技术评估和产品设计,都必须符合IT时延的自然规律。
产品优化、技术评估的方法论必须和IT技术常识结合,才能做出有可行性的判断和行为。比如,因为有光速限制,且北京到广州的直线距离是1800km,我们就算再舍得砸钱买设备,也不可能让北京到广州的延迟低于6毫秒。
前言二、模糊指标也够用
限于篇幅和时间原因,本文对这些延迟指标也并未特别严谨的考证,特别是纳秒和微秒区的延迟,更是缺乏相关资料。还好我手头有本拆解操作系统的纸质书,也有通义千问这类AI帮我找数据。
这些“延迟指标”并没有明确的定义规范,有些指标只是一两个具体的软硬件动作,而有些延迟指标是一套完整的逻辑事件,所以这些延迟指标只有“参考价值”,但没有明确的“可比性”。
这些模糊参考的延迟指标做科普,就足以规避一些离谱的设计问题。比如我们做个时延排序:纳秒级内存无论具体数值是否精确,这几个时延的差值都是十倍以上的。
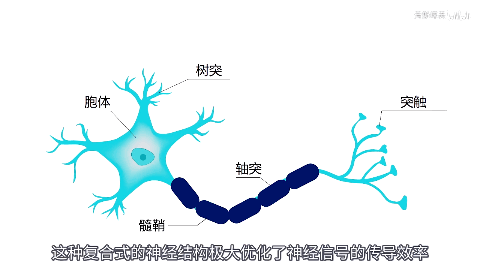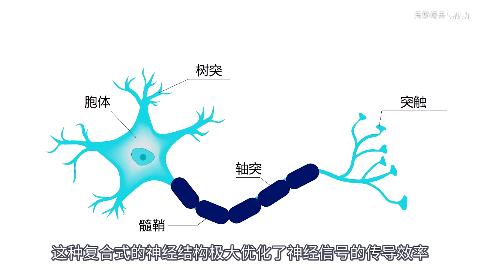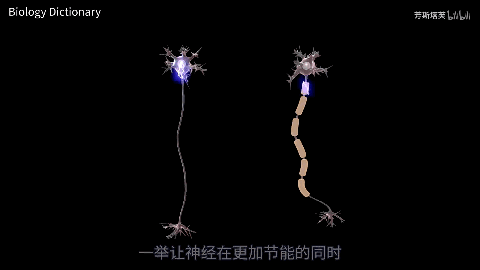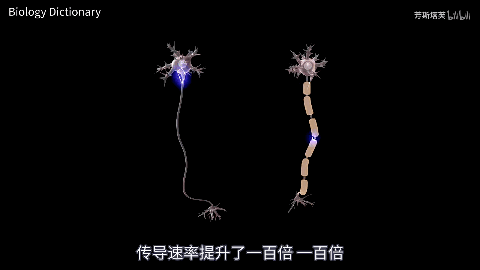
脊椎动物能称霸生物圈的诀窍就是“巨大且灵活的体型”,而节肢动物、软体动物体型一变大就会运动缓慢。脊椎动物祖上积德,演化出了包裹了髓鞘的神经,信号传输速率是节肢和软体动物的100倍。我们人类保持着接近2米的巨大体型,靠低延迟神经指挥,可以灵活出掌打死体型几毫米的蚊子。
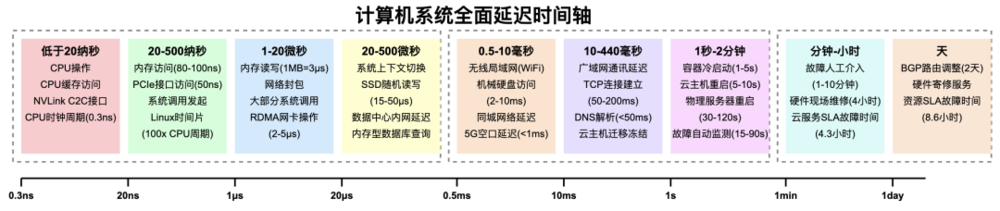
一、低于20纳秒
只有CPU能保持20纳秒以下的延迟,99%的工作没资格埋怨CPU的速度慢。
物理学中对时间的定义有个最小尺度,叫做“普朗克时间”,意为科学范畴内不存在比其更短的时间尺度了。IT系统中的“普朗克时间”,就是“CPU时钟周期”。用1秒钟(1G纳秒)除以CPU的主频就能得到CPU的时钟周期,一般CPU的主频约为3G左右,所以IT系统中的最短时间周期约为0.3纳秒。
CPU需要从寄存器、一级缓存、二级缓存、三级缓存中读取数据才能进行计算,CPU计算的内容也不止步于“与或非简单运算”,还会做一些分支预测和加锁解锁。这些工作的延迟约为1—20纳秒,且受到不同架构、不同硬件、不同指令集和编译器的影响。这1—20纳秒的速度确实拖了CPU的后腿,但和后续各种微秒、毫秒的工作比,简直是快如闪电。
我对GPU硬件的了解不多,据说NVLink C2C接口的连接延迟能达到5纳秒,确实只有这么低的延迟,才能保证CPU和GPU同时操作内存时的数据一致性。
99%的应用程序只要没有Bug、没弱鸡到汗颜的垃圾代码,都不会触发CPU的性能瓶颈。我工作中遇到特别消耗CPU的任务,多是科学计算、实时生成3D共享地图的游戏服务端、编解码这类业务。
二、20到500纳秒
只有主板总线、内存、PCIE接口能保持500纳秒以下的延迟,操作系统也开始关注这个延迟量级的行为动作。
不同主频、不同世代的内存,其访问时延会有一定的差异,日常做科普预估时,CPU通过总线访问内存的时延约为80到100纳秒。
PCIE5.0接口本身的访问时延能控制在50纳秒左右,但是这仅仅是接口自身的时延,接口对端的设备可能速度很快或者很慢。当PCIE接口对接GPU时,读写延迟就是50纳秒,但对接一块网卡或者SSD时,读写延迟就是微秒级了。
操作系统玩来玩去,关注的就是CPU、内存和IO接口。因为内存和IO接口能达到50到100纳秒的访问速度,所以操作系统发起系统调用的时间,也能控制在500纳秒以内。注意这仅仅发起系统调用的时间,并不代表调用成功或者超时失败。Linux系统中可设置的进程时间片最小长度约为CPU时钟周期的100倍,也大致能归结到该时间周期内。
三、1到20微秒
在1到20微秒的区间里,我们已经可以完成内存读写、网络封包和大部分系统调用。
当在同一个进程内操作同一份内存数据时,比如从内存中顺序读取1MB数据,大约需要3微秒,且随着内存工艺的进步,该时间还在减少。我们做各种性能优化时,只要把负载从硬盘挪到内存,性能就有大幅度提升,就是因为是内存的寻址定位和读写速度,比SSD要快上十倍,比机械硬盘要快上数百倍。
对于和内存操作强相关的系统调用,比如进程控制、内存管理,都可以在10微秒内完成。前言第二段已经提到,既然有基于网络的分布式块存储,为什么没有基于网络的分布式内存?因为操作系统处理缺页中断时,留给分配内存的时间窗口只有几微秒,如果依赖网络做了个“分布式内存”,肯定会系统等待超时,然后OOM kill掉这个进程。
网卡将数据封包后发到网线、将光电信号转化为数据包都有延迟。普通以太网卡的延迟超过了15微秒,RDMA(InfiniBand)网卡的操作延迟大约是2微秒,RDMA(RoCE)网卡的操作延迟也可以低于5微秒。因此客户在必须在GPU群集里做分布式显存池时,只能采用昂贵的RDMA网络。此外,据说某些云厂商还在研发速度更快的网卡。
四、20到500微秒
在20到500微秒这个时间段里,终于开始出现一些读者们更熟悉、更容易观测的角色了,比如系统上下文切换、SSD盘随机读写、同数据中心的内网延迟、内存型数据库的常规查询速度。
从工程师的视角看,此时此刻终于是可观测的了。无论是操作系统还是一些应用程序,它们的时间戳都可以记录到微秒。我们做系统调优开始关注上下文切换的频率,下文提到的ping测的时间戳就是微秒,Redis的慢查询定义标准也是微秒。
SSD盘的随机读取数据时,定位到数据的延迟大约是15微秒,从SSD盘顺序读取1M的数据,用时不超过50微秒。SSD盘微秒级的响应速度,和传统SATA盘毫秒级的响应速度,完全就不是一个量级。因此可以引出一个梗头:15年前的DBA经常在优化机械硬盘的磁头,但是随着SSD的普及,大量数据库优化工作直接消失了。
同数据中心的内网延迟,一般能控制在500微秒以下。在公有云语境中,同可用区两台云主机互ping,可以观测到不超过500微秒的延迟。已知每一次网卡收发都有几微秒到十几微秒的延迟,一条链路要经过多台交换机,外加VPC封包解包也有延迟,这个测试数值就是相对合理的。请注意,VPC网络内经常使用分布式网关,如果云主机ping测网关,可能是本宿主机的OVS代为应答了,延迟会低于100毫秒。
内存型数据库和基于SSD盘的数据库做一些常规查询操作,比如在小数据库里内查询很短的Key值,其操作过程就是从内存中读取数据,然后给读到的数据加个简单的包头包尾,这个过程只有几十微秒。Nginx在已经建立的链接中,解析一个简单的HTTP请求,也能达到这个延迟标准。
五、0.5到10毫秒
访问时延符合0.5到10毫秒的IT行为很多,但常见的就三大类:无线局域网、机械硬盘和同城网络。
按照5G网络的定义标准,其5G空口延迟需要低于1毫秒。(“空口”就是“空中接口”,就是“空气版网线”加上天线网卡)。Wifi网络的标准版本很多,我的电脑和Wifi5路由器实测的连接延迟在10毫秒左右。一个关注网络延迟的应用,用户直接用5G网络就会比用Wifi的速度更快。
2019年推出5G网络时,很多人把低时延当做重大产品卖点,但是大部分网络应用不太在意5G空口节省的10毫秒延迟,所以我们一直没找到爆款5G应用。
机械硬盘的寻址速度,理想化情况下是2毫秒,但实测经常能到10毫秒。当服务程序需要机械硬盘做读写定位操作时,无论操作的数据量有多小,都要做好10毫秒延迟的准备。依赖机械硬盘的数据库或大数据群集,其查询操作被机械硬盘拖累,通常延迟会达到10毫秒以上。但这些重IO负载的应用一般会频繁读写大量数据,所以就会只计算IO带宽,不会刻意关注读写延迟了。
我的书中介绍IaaS云产品时,多次提到同Region不同AZ的概念。AZ有两种,第一种是同一地域、未必能错开供电的AZ,这种AZ的直线距离很近,延迟不超过3毫秒;第二种AZ是同城但不同地域,错开了上游电站的AZ,这种AZ的延迟约为3到10毫秒。本地Region和本地CDN覆盖的个人用户,也能达到10毫秒以内的网络延迟。
六、10到440毫秒的网络延迟
IT系统中大于10毫秒的技术延迟,最常见的就是广域网通讯延迟。网卡封包只是个微秒级操作,所以网络延迟主要受限于光速和实际网络拓扑的长度。客户看似无法承受一点点的网络延迟,但那都是被供应商惯出来的,其实大家都能承受很高的网络延迟。
光纤中的光速是每秒钟20万公里,但因为网络拓扑不是直线,转发设备也比较多,所以我们做网络延迟预估时,无论是云内同Region裸纤、常规网络覆盖还是普通的长途专线,一般都可以按照“直线距离每增加50公里就增加1毫秒延迟”进行延迟估算。也有极少数例外,比如跨大洋海缆布设时走直线、转发设备也比较少,所以传输速度超过了每毫秒50公里。
广域网通讯主要影响到的是客户端自然人的感受。常规的网络应用,比如访问网页、在线交易、棋牌游戏、追剧、看直播,可以认为是对网络延迟没有要求,100毫秒延迟的带宽足以覆盖全国。对于人跟人之间快速交互的业务场景,比如竞技网游、云游戏云桌面、视频会议,客户能流畅交互的时间周期约为80毫秒。这个交互周期包括客户端计算、服务端计算、两次网络往返传输数据,一般留给网络延迟的时间约为20毫秒。
虽然厂商都在宣传视频会议不卡顿,但那是在北上广之间不卡顿。如果连麦双方必须保持很远的物理距离(比如中美、中欧),用户也就习惯了数百毫秒的高延迟。
结合上面两种需求,如果我们将网络延迟限定在20毫秒,在北京、上海、广州、武汉、成都、沈阳、西安画几个1000公里的大圆圈,这几个圆圈足覆盖90%的国内网民,延迟也足以满足99.9%的业务需求。大家习惯用CDN加速,主要不是为了降低网络延迟,而是因为CDN带宽的价格比BGP带宽更便宜。各种CDN比延迟大赛,其实是云厂商在盲目内耗。
当用户能接受网络延迟大于100毫秒时,我们就可以用一国网络来覆盖全球了。距离中国最远的国家是阿根廷,2.2万公里的距离就是440毫秒的延迟。对于看视频、看网页、文字聊天、棋牌游戏这类需求来说,440毫秒的延迟并非不能接受,大家不信的话可以打开阿根廷的网站看一看。
东数西算的西部节点,本来因为天然的延迟问题,只能定位成价格偏低的冷备节点。但是国运来谁都挡不住,对话式大模型的交互过程不要求快速实时响应,这些电费便宜网络缓慢的西部节点,突然就能扛起线上实时业务的重担了。
七、大于10毫秒的连接延迟
上一节的内容太多了,所以我将大于10毫秒的连接延迟单独整理成了一个章节。大家看下文内容也能发现,延迟超过10毫秒的业务,大多是被网络传输延迟拖累的。
TCP是严谨的有状态协议,客户端需要三次握手才能和服务端建立链接,每次握手都要加上一次网络延时。在健康稳定的网络里,建立一次TCP链接需要50到200毫秒,而在劣质网络中(比如4G信号时断时续的地铁里),建立一个TCP链接可能需要几秒钟。TLS加密协议(前身是SSL协议)一般也是基于TCP协议进行通讯,所以TLS一次握手也需要同样漫长的时间。
相比之下,UDP传输数据报文没有握手过程,客户端直接对着服务端抛数据就行了,UDP相比TCP天然节省60%的网络延迟。这些年很多轻量级创新通讯方式(比如Quic、WebRTC、DTLS和一些IOT协议),就是在用UDP取代TCP,那些原本由TCP完成的校验和流控等工作,统统改由应用层自行完成。
DNS解析既可以基于TCP也可以基于UDP,且在本网络乃至本机由多级缓存,所以DNS的解析时间能控制在50毫秒以内。但HTTP_DNS本质上是HTTP,且一般做了TLS加密,其解析速度就要参考TCP的通讯延迟了。
除了广域网传输延迟之外,也有一种常见的迁移冻结延迟。当云厂商需要“无缝迁移”云主机时,需要在云主机迁移的瞬间冻结系统,以保证新旧主机的内存一致性。这个迁移操作并不是完全真的无缝无感,而是会导致云主机的系统hang机100到200毫秒,而云主机内的GuestOS很难感知到时间被暂停过的。
八、从1秒到2天
从1秒钟秒到2天,这些时间刻度属于工程师们关注的范围,这些工作和产品设计的关联不大,但当我们面对各种技术实施工作时,就需要掌握从1秒到2天的种种IT时刻,才能避免违背常识为难工程师。
在宿主机上冷启动一个常规容器,需要花费1到5秒的时间;如果将一台云主机重启,需要花费5—10秒时间;如果新建一台云主机,需要5到15秒时间。在关闭内存校验、跳过磁盘检查的情况下,如果一台物理服务器重启或冷启动,需要花费30到120秒的时间。因为很多IT服务的健康检查周期是5到30秒,所以重启云主机和重启物理机的影响并不相同。
自动监控系统发现故障的时间一般为15到90秒,这个告警阈值不能设置的比15秒更短,太短的告警阈值会频繁的触发误报,最终导致工程师忽略真正的故障。参照一些SRE技术执行标准,1分钟发现故障、5分钟定位故障、10分钟解决故障就是自然人工程师干预故障的生理极限了。
云厂商采购的机柜、带宽这类云资源,一般就是99.9%的SLA,这代表着全年允许故障时间是8.6小时;云厂商将不稳定的资源包装成云产品后,一般对外承诺99.95%的SLA,全年允许故障时间是4.3个小时。最贵的硬件保修是维保方承诺4小时内(连堵车都考虑到)带着备件到机房现场替换,云厂商一般采购的是“报修后下一工作日上门”服务,但也有更便宜但速度更慢的批量寄修维保服务。
海外网络维护时,网络工程师需要经常调整BGP路由广播。这个调整工作一般需要等待24小时路由生效、再观察24小时确认调整效果,做一次调整的累计时间至少2天。所以读者朋友们不要看到海外带宽可以自主发送BGP广播,就误以为调整网络是个很简单的高频操作。
结束语
写清楚这些延迟、读这篇文章,都不是太容易的事,但有难度也有用途的知识,才更有含金量啊。
为了撰写本文,我特地完整的读了一本谈系统原理的书;我借助了AI搜集了很多相关信息,但AI给的答案,我都要再复核检查来源信息网页。
我很清楚,至少90%的产品经理不知道自家产品的常见动作响应延迟。但我们也莫笑产品经理是水货,因为90%的程序员也不关注自己写的软件有多高的访问延迟。
但这个工作非常有用,当我们对一个IT服务提出有可行性的性能需求时,或者要在性能不变的前提下做成本优化时,都需要掌握了解这些和性能有关的延迟信息。
本文来自微信公众号:云算计(ID:gh_0068c4e23a81),作者:曹亚孟
本内容为作者独立观点,不代表虎嗅立场。未经允许不得转载,授权事宜请联系 hezuo@huxiu.com
正在改变与想要改变世界的人,都在 虎嗅APP
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号