数据工程师必备:关键数据结构和算法解析
发表时间: 2023-03-09 11:21
关注留言点赞,带你了解最流行的软件开发知识与最新科技行业趋势。
数据工程是有效管理大量数据的实践,从存储和处理到分析和可视化。因此,数据工程师必须精通数据结构和算法,以帮助他们有效地管理和操作数据。
本文将探讨数据工程师应该熟悉的一些最重要的数据结构和算法,包括它们的用途和优势。
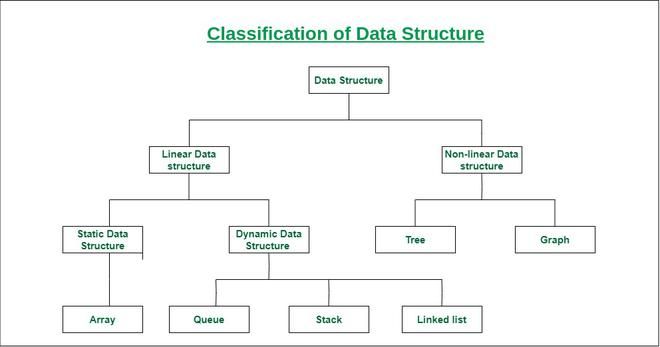 数据结构
数据结构 关系数据库
关系数据库关系数据库是数据工程师最常用的数据结构之一。关系数据库由一组表组成,表之间定义了关系。这些表用于存储结构化数据,例如客户信息、销售数据和产品库存。
关系数据库通常用于电子商务平台或银行应用程序等交易系统。它们具有高度可扩展性,提供数据一致性和可靠性,并支持复杂的查询。
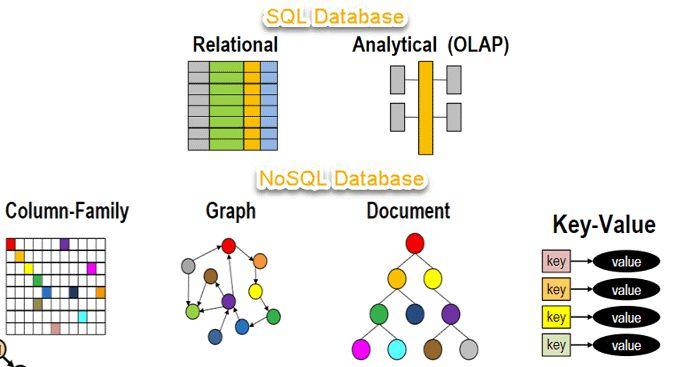 NoSQL 数据库
NoSQL 数据库NoSQL 数据库是一种非关系型数据库,用于存储和管理非结构化或半结构化数据。与关系数据库不同,NoSQL 数据库不使用表或关系。相反,它们使用文档、图形或键值对存储数据。
NoSQL 数据库具有高度可扩展性和灵活性,使其非常适合处理大量非结构化数据,例如社交媒体提要、传感器数据或日志文件。它们还具有很强的故障恢复能力,提供高性能,并且易于维护。
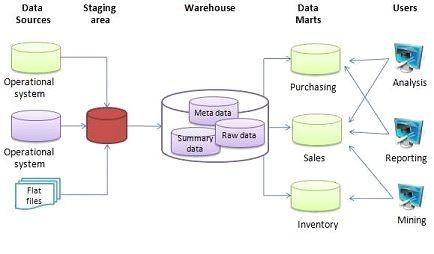
数据仓库是专为存储和处理来自多个来源的大量数据而设计的专用数据库。数据仓库通常用于数据分析和报告,可以帮助简化和优化数据处理工作流程。
数据仓库具有高度可扩展性,支持复杂查询,并且性能良好。它们还非常可靠,支持数据整合和规范化。
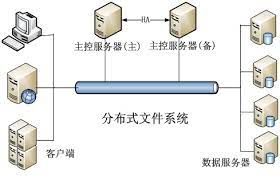
Hadoop 分布式文件系统(HDFS)等分布式文件系统用于跨多台计算机存储和管理大量数据。此外,这些高度可扩展的文件系统提供容错并支持批处理。
分布式文件系统用于存储和处理大量非结构化数据,例如日志文件或传感器数据。它们还具有高度的故障恢复能力并支持并行处理,使其成为大数据处理的理想选择。
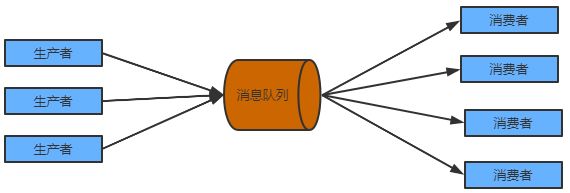 消息队列
消息队列消息队列用于管理数据处理管道的不同组件之间的数据流。它们有助于解耦系统的不同部分,提高可扩展性和容错性,并支持异步通信。
消息队列用于实现分布式系统,例如微服务或事件驱动架构。它们具有高度可扩展性,支持高吞吐量,并提供对系统故障的恢复能力。
排序算法用于按特定顺序排列数据。排序是数据工程中必不可少的操作,因为它可以显着提高各种操作(例如搜索、合并和连接)的性能。排序算法可以分为两类:基于比较的排序算法和非基于比较的排序算法。
基于比较的排序算法,例如冒泡排序、插入排序、快速排序和合并排序,比较数据中的元素以确定顺序。这些算法的时间复杂度在平均情况下为 O(n log n),在最坏情况下为 O(n^2)。
非基于比较的排序算法(例如计数排序、基数排序和桶排序)不比较元素来确定顺序。因此,这些算法在平均情况和最坏情况下的时间复杂度均为 O(n)。
排序算法用于各种数据工程任务,例如数据预处理、数据清理和数据分析。
搜索算法用于查找数据集中的特定元素。搜索算法在数据工程中是必不可少的,因为它们可以从大型数据集中高效地检索数据。搜索算法可以分为两类:线性搜索和二分搜索。
线性搜索是一种简单的算法,它检查数据集中的每个元素,直到找到目标元素。线性搜索在最坏情况下的时间复杂度为 O(n)。
二进制搜索是一种更有效的算法,适用于排序的数据集。二分搜索在每一步将数据集分成两半,并将中间元素与目标元素进行比较。在最坏的情况下,二分查找的时间复杂度为 O(log n)。
搜索算法用于各种数据工程任务,例如数据检索、数据查询和数据分析。
散列算法用于将任意大小的数据映射到固定大小的值。哈希算法在数据工程中是必不可少的,因为它们可以实现高效的数据存储和检索。散列算法可以分为两类:加密散列和非加密散列。
SHA-256 和 MD5 等加密哈希算法用于安全数据存储和传输。这些算法产生一个固定大小的散列值,该散列值对于输入数据是唯一的。因此,无法通过反转哈希值来获得原始输入数据。
MurmurHash 和 CityHash 等非加密哈希算法用于高效的数据存储和检索。这些算法根据输入数据生成固定大小的哈希值。哈希值可用于快速搜索大型数据集中的输入数据。
哈希算法用于各种数据工程任务,例如数据存储、数据检索和数据分析。
图算法用于分析可以表示为图的数据。图用于表示数据元素(例如社交网络、网页和分子)之间的关系。图算法可以分为两类:遍历算法和寻路算法。
广度优先搜索 (BFS) 和深度优先搜索 (DFS) 等遍历算法用于访问图中的所有节点。遍历算法可用于查找连通分量、检测循环和执行拓扑排序。
Dijkstra 算法和 A* 算法等寻路算法用于寻找图中两个节点之间的最短路径。例如,寻路算法可用于寻找道路网络中的最短路径,为送货卡车寻找最佳路线,为机器人寻找最高效的路径。
数据结构和算法是数据工程师必不可少的工具,使他们能够构建可扩展、高效和优化的解决方案来管理和处理大型数据集。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号