运维专家的自我提升之路
发表时间: 2022-02-09 17:53
作者:huashionxu,腾讯 TEG 业务运维专家
运维同学作为站在研发团队背后的男人们,一直在担任着举重若轻的角色,而这两年盛行的 Devops、研效变革也直接影响到运维同学岗位职责的变化, 腾讯云架平技术运维副总监 huashion 近十年运维领域的自我修养体会,清晰运维人的工作职责定位,文化准则,与大家共同探讨的职业发展,Devops 引发的职位变更等当下乐问热点,本文旨在为所有可能看到的技术运维鹅们带来一些成长的启示。
世界上第一个运维人名叫 Margaret Hamilton,为什么说她是世界上第一个运维呢?其中是有一段故事的。

Margaret 是在 NASA 工作,一次她带着她的小女儿 Lauren 去工作的地方玩,期间 Lauren 误触了控制台,引发程序崩溃,Margaret 思考在火箭飞行过程中也有可能发生这样的错误,于是她在火箭飞行手册中添加了一段文字,提醒宇航员不要误触发 P01 程序,并给出了恢复手段。Apollo 8 执行飞行任务时,结果真的有人误触发了 P01 程序,幸好有 Margaret 之前给出的恢复手册,最终才化险为夷。
在今天来看,当时 Margaret 做的工作其实就是在做预案,这跟我们现在运维做的工作是如出一辙的,所以从这个意义上讲,她可以被认为是世界上第一个业务运维。
当时她还说了这样一段话,“无论对一个软件系统运行原理掌握得多么透彻,也不能阻止人犯意外错误。”这其实就是运维的思想,也是我们每天在干的事情。

很多人认为运维应该是在机房搬服务器,插拔网线,调试网络,或者修电脑的。但我们自己觉得运维应该是个比较“高雅”的职业,每天状态是在办公室,泡杯茶或咖啡,面对电脑处理着工作....但实际上呢,其实还是挺苦的,很多运维同事都是救火的状态,觉得特像消防员,每天都是在面对各种线上问题,半夜还要值告警,特别辛苦同时压力也会很大。
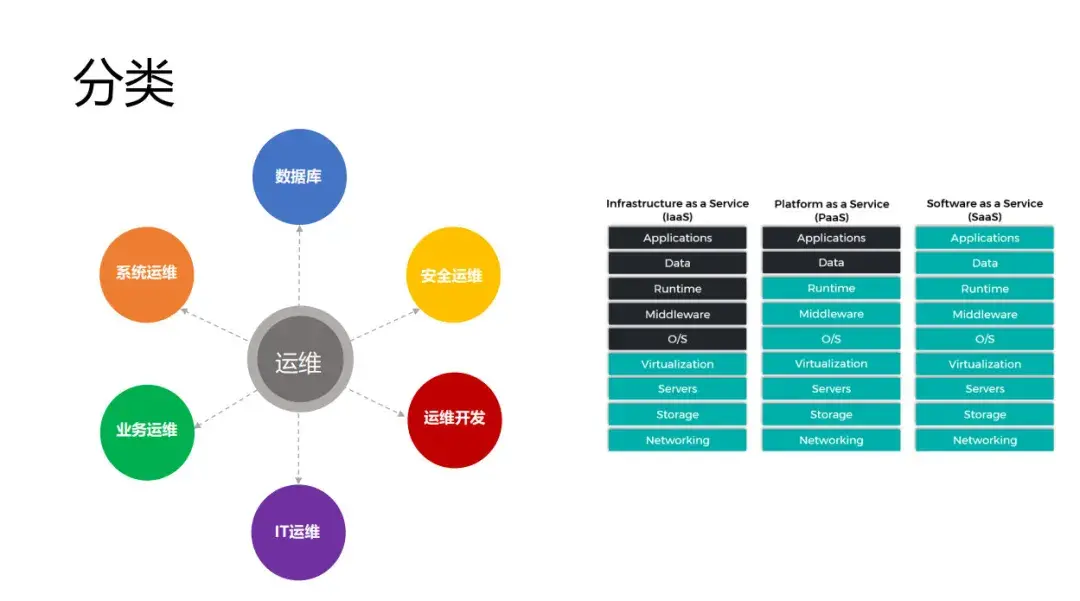
运维这个职业有很多工种,比如说我自己是做业务运维,主要是面向业务的;还有系统运维,比如负责网络,操作系统的、底层 IaaS 的等等;还有一类是数据库 DBA,是专门负责数据库;还有专门负责安全的安全运维;还有运维开发,Devops(AIOps)负责开发运维工具和平台;还有像我们 8000 的小伙伴,做IT运维。
因为现在大部分的基础设施都云化了,如果按照云的维度来看,又可以分为 SaaS、PaaS 和 IaaS 运维。

运维的工作职责和定位通常是:第一个定位 质量守门人,运维最核心的 OKR 或 KPI 就是围绕质量,负责所有线上的问题;
第二个定位是效率提升者,运维需要对日常的一些重复工作去开发各种各样的工具,提升整体运维效率,这样才能更好的去驱动质量的提升;
第三个定位是口碑维护者,很多运维同学都是要接触业务,不管是负责内部自研业务还是外部云客户,都需要深入业务做好服务,在 TEG 很多同事都承担了这样的职责,这就是左边的圈。
同时我们日常开展工作锁围绕的三个生命周期(右边的圆圈):
第一个故障生命周期,故障生命周期就是从一个故障最开始的发生,到发现,到定位,到分析,到最后恢复;
第二个应用生命周期,所有线上跑的应用 APP,从最开始的发布评审,到发布上线,到监控,包括做资源,后面预案,都是围绕应用生命周期;
第三个资源生命周期,资源生命周期和应用生命周期还是有些区别。因为运维还管了很多设备,包括硬件设备,IT,实例资源,那就要去做资源生命周期的相关工作,包括资源的申请、报备......所以运维的职责大致就可以用这两个圈来概括。

具体工作基本围绕质量、成本、效率、安全,大家每年在写 OKR 或做规划都是围绕这几方面来做,质量提升、性能优化、成本优化和安全优等等。
运维跟研发,或者研究等其他岗位是有些差别,我大致总结了几点。

第一种 故障文化,江湖人称运维叫“背锅侠”,这大概就是我们运维人的常态。“不在复盘,就在去复盘的路上。” 特别是做云的小伙伴,基本上每天都在复盘,只要线上出了问题,先录单,录完后,QA 就会来说“我们复盘吧”,然而这个问题还没有复盘完,又出现新问题了,复盘完了之后又继续……所以基本就是每天“不在复盘就在复盘的路上”。
大家都说“没有经历过大的故障的运维,不能称得上是一个好运维”。相信每个运维人都会经历过很多的故障,但对于运维岗位,我们在做问题复盘时,是真正意义上的“对事不对人”,这里不会去计较为什么是这个人犯的错、出的问题、写 bug,重要的是为什么会出这个问题,出问题后能否更快发现和恢复,或从流程机制上保证下次不再同样犯错,所以在运维的文化里面重要的一点。运维都够做到真正的对事不对人,关注问题和关注事情本身。
同时重要的是,大家是在故障中成长,在复盘中变强。这里给大家讲 3 个让我印象非常深刻的例子。
第一个例子是发生在我自己身上的,在上家公司大概入职 2 年多的时候,有一天接到一个磁盘告警要去清理磁盘,然后我马上进入服务器根目录下敲了行代码“rm -rf *”。过了三秒钟自己反应过来,刚刚好像是在根目录底下运行下删除,当时是立马按 Ctrl C 恢复,但其实已经删了一些内容。但很诡异的是当时没有出现任何问题,但我依然很害怕,就赶紧给模块的研发打电话,说把根目录给删了,他也慌了马上与我一起复盘;在复盘的时我们发现没出问题,因为当时很多的程序直接加载在内存中运行,所以没有影响线上服务,这个也是不幸中的万幸......记得当时公司有个叫鸡翅文化,就是如果你犯小错误就请所有人吃鸡翅,我当时是请研发同学们吃鸡翅,这是我人生第一次也是唯一一次请研发吃鸡翅。这次事情让我记忆深刻后来我把这个案例写到了中心的新人培训材料分享出去,想不到后来真的有同学去试了一遍,把仓库删掉了:( 这真是一个很常见、容易犯的错误。
第二个故障是我入职时导师讲的,有个同学半夜接到电话说某一批机器的分区要满了,那个同学动作很快马上写了一个脚本开始批量删除,结果不小心把历史网页库的 1/3 全部删除了。因为很多历史网页实际上现在已经没了(原站已经关停了),所以他这次操作基本上把中国互联网过去十年前 1/3 网页干掉了,但当时 leader 跟我说这个同学还在公司,而且发展还不错已经是经理了。这个例子让我震撼的是,虽然运维做错删库了(任何一个人都有可能犯错误),但只要不是故意不管是主观还是客观原因,至少大家对于运维都不会去针对人,还是聚焦事情本身。
第三个是 2018 年我遇到,印象很深刻是这个故障发生后,我去北京做行业认证,刚好遇到国家部委工信部的同事来详细地了解情况,后来工信部的同事把这个故障涉及的流程规范写进行业认证的规范中。那时我在想,由于一个问题出现竟然可以影响或者改变行业的一些东西。
所以总结来说,故障文化就是运维需要认真地去针对每一次故障、事情和问题本身、以及针对性的解决方案和故障预防或规避流程。

第二个是 线上文化。通常来说,运维对线上是最敏感的,比如最近在做春保,不知道大家有没有去好好拜拜服务器(玩笑),这里不得不提大家常讲的一个词叫敬畏心,亦或是对线上的敬畏心。
敬畏心到底是什么?我尝试做下总结:
不轻易去改变线上当前稳定的运行状态;如果要去改变,一定要多次验证,并且是可逆的;
因为它现在运行得好好的不动就不会出问题,一动就有可能会出问题,所以你去真正改变线上稳定运行状态的时候,要想如果我改变了之后可能会有问题,能不能再恢复到原来状态。原来我理解敬畏心很抽象,但落到日常的具体工作中,这其实就是运维具备的基本常识(有些研发在出问题的时候可能第一反应是 debug 或者 fix,而运维会优先止损),所以这里也是我认为运维这个职业跟大家很不一样的地方,比如在做发布变更的时候,要有灰度意识,所有不经过灰度直接发布是不能接受的,稳定性更不用说了,线上的稳定是运维的底线或者是生命,所以运维的线上文化是很重要的。

下面我想跟大家分享下准则,每个行业都有自己的祖师爷,逢年过节要去拜一拜。运维这行应该拜谁(祖师爷)?我上面列了三张图,第一个是墨菲。因为我以为做运维一定要相信墨菲定律。什么是墨菲定律?其实墨菲定律本身是一个心理效应。大概讲的是:
● 首先,任何事情都没有你表面看上去那么简单。
● 第二,所有的事情基本上都会比你预估的时间要长。
● 第三,你以为会出错的终归会出错。
● 第四,如果你担心某件事情发生,它就一定会发生。
经常我们关注的可能是第三点和第四点,就是小概率事情一定会发生。所以为什么运维要信墨菲定律?其实逻辑很简单,本身我们职业的特殊性,就决定一个应用程序或者一个配置真正到线上生效,我们是最后一道屏障。
我记得很清楚,有时研发同学在跟我们复盘时,经常说这个 bug 是一个小概率事件,它触发的场景非常有限,但是这不能放到运维身上来,因为运维是线上的最后一道屏障,兜底的,如果从我们这边露出小概率事件,有可能真的会导致故障。所以作为运维一定不能容忍所谓的小概率事件,只要这里有个隐患,我就不能偷个懒,就不要想着故障可能不会出现;要想着如果有隐患不解决它就一定会出问题。不要轻易的把一些所谓的小概率事件漏掉,这是墨菲定律。
第二个 是个德国工程师的海恩法则,是个关于飞机飞行安全的故事,德国人非常严谨,海恩在经过研究发现每一起严重的飞行安全事故,背后一定有 29 起轻微事故,以及 300 起未遂先兆,以及 1000 起事故隐患。量化的数字可能是经过科学分析的,但实际上他想强调两点:首先事故发生一定是量变引起质变的,是一个积累的过程;第二是再好的技术、再完美的规章在操作层面,也无法替操作人的素质。
总结海恩法则,在日常工作中,发现一个故障,再去做复盘,你会发现是因为他前面每一层都在出问题,一点一点,有很多先兆。
第三个是灰犀牛理论,这个理论实际上最早用于金融界,但是你会发现,不管是造飞机,心理学,金融界,跟我们工作都很有关系。灰犀牛理论跟海恩法则有些类似。黑天鹅事件大家应该都知道,黑天鹅其实是一种偶发性、不可预见的,之所以叫黑天鹅,就是因为它突然出现,无法预防。但是灰犀牛实际上是一个你能够看见、显而易见、很大的一个危机。
所谓的灰犀牛事件,出现时不是随机突发的,前面有一系列的警示与告知,最后才慢慢变成一个黑天鹅事件。所谓黑天鹅事件,或者故障,是想告诉大家,在出现这些迹象和这些警示的时候,我们不应该掉以轻心。有时你会偷懒,会得过且过,但实际上前面有很多地方不应该去轻视它,要去解决它。跟海恩法则会有一些类似。大家以后逢年过节,或者重大保障之前,除了拜服务器也可以拜一拜这三位,千万不要出问题。
这些所谓的原则准则,希望能够变成大家的职业习惯,变成潜意识去主动思考问题。首先不要相信小概率事件,该发生的一定会发生。第二,要去重视一些潜在的东西,出现隐患时要及时解决,不要让它变成真正的一个故障。
运维人跟其他人除了在工作职责上有区别之外,在特质或者素质上有什么不一样?我总结出 2 个特质,也许可以帮助大家更好的去工作。

鲸鱼是地球上最大的哺乳动物。鲸鱼的心脏是世界上最大的,据说有 800 公斤。而作为运维人来说,我认为也需要有这样强大心脏。
首先是线上操作,很多时候,即使你知道接下来这个操作非常重要,操作下去可能会出重大的问题,比如说把某一个服务重启,但如果在前期做好评估,预案也已想清楚,前面所有都做了,就应该有自信,线上操作胆大心细。
第二个,当真的出问题了所有人都很慌乱时,在整个产品或团队中唯一不能够慌乱的那个人就是运维。因为本身你更清楚监控更清楚预案,清楚如何操作,如果连你的手都在抖,都在害怕,那这个问题大概率没人能够靠得住。
第三,复盘和故障是家常便饭,每天都在出故障,有时大家会常常因为某些故障很懊恼很纠结,但是我觉得大家要习惯,我们应该越挫越勇。 出问题没有关系,通过流程和工具把这些问题彻底解决掉,不用太纠结;对于已经入行和即将入行的,或者未来大家想继续发展的,我觉得这一点特质非常重要。
第二和重要特质,强迫症。 为什么要有强迫症?有时看到一些隐患或者不好的操作习惯,甚至一些不好的流程等,这时我们不应该容忍,特别是有些问题或隐患可能涉及到线上,更不可以,应该立刻解决。第二个,运维工作本身挺繁琐的,包括有很多重复劳动,第一遍第二遍,会做很多遍。对这些 Dirty work 我们也不能容忍,应该想法做工作做平台去提升效率。第三个,如果大家做出来的这些流程,没有人遵守,或者因为各种各样的特殊流程去跳过某一个的,这个流程本身就没什么存在意义,所以在执行的时就应该是一步都不能少。
我希望大家在工作时该有这样的强迫症,对线上负责,去消灭一些问题,提升效率;做流程时也严格执行,流程一步都不能少。
接下来,我分享下运维人的技术和个人成长部分,因为运维人员本身工作很琐碎,所以大家就更关心里面有没有成长,每天都在发变更,日复一日,年复一年,会非常焦虑。
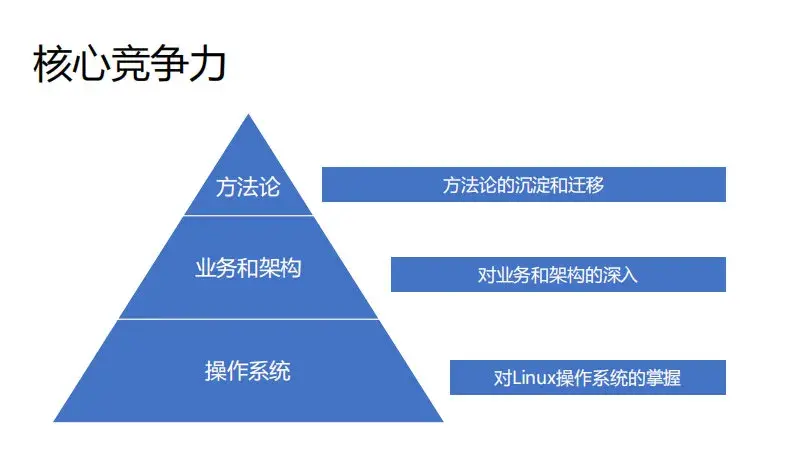
运维人的核心竞争力是什么,所谓核心竞争力是不可替代性,应该怎样去做?我认为:
第一个 核心竞争力是对操作系统掌握。 原来最早做运维的人就是所谓的古典派,他们对操作系统是非常深入的。我们现在很多应用和服务还是跑在 Linux 或者 unix 操作系统上,所以对应出现问题应该怎么去排查,性能怎么去优化,监控怎么去做,而这些都是需要对操作系统原理和架构清楚的,所以操作系统是很核心很基础的。
第二个 核心竞争力是对业务和架构的深入掌握。 运维会负责不同产品,它们之间的区别到底是什么,我觉得就是对所负责的业务和架构的深入理解。比如我是做存储的,对整个存储的架构,整个链路,底层的理解,以及关联的存储网络、存储硬件的了解和掌握,是你不可替代的部分。这是未来你再去找工作,大家最看重的东西。因为只有你深入的去做这个业务,做了很多年,你脑子里有很多东西是别人不知道的或者是别人容易忽略的。如果说有一个新的业务,也要做这一块的业务,就非常需要这样的人,不管是运维体系,还是丰富的线上运维经验。
到底怎么深入,大致可以用这样一个路径。比如一个开源软件,开始做肯定从网上找一些资料部署起来,稍微改一改,可以运行起来其实这才仅仅是第一层;然后你发现这个性能好像上不去,那就去研究哪些配置可以深入优化下、适配业务,所以第二个层次是能够做些配置的优化;第三个层次,是发现有一些功能没有,比如可能会基于它的源码做一些插件,去实现它的更多功能;再往下深入,就是让自己要去重新造跟这个一样的东西(原来我们也干过这个事情,比如说重新写一个做接入程序,有没有这样的能力能够把他包起来)所以它是一层一层往后去深入的,大家可以看下到底现在在哪一层,就可以很清晰地知道应该再往哪一层去深入。
第三个,方法论。 用我个人的经验来说,我原来一直做存储,然后 19 年 leader 让我去负责数据库,当时我并没有数据库的背景,基本上就是知道最基础的操作而已,这种水平让我就很虚。但后来去做了我发现很多事情其实是差不多的。
首先 数据库业务也要关注故障生命周期,都要做监控、定位、预案恢复;当然也有不一样的地方,原来存储我们巡检的是硬问题、存储节点状态,数据库巡检是主从状态(是不是断开了,是不是延迟),这就是业务差异化的内容;所以我就把原来做存储的一些思路,拿来去做数据库,除可能有一些上层的业务不太了解,其他还是能够复用的。专业和业务层面也不用当心,会有专门的同学来帮助我们学习。
所以,当你做一个产品很久之后,有没有去总结这个产品,比如应该怎样去运维,如果给你一个新的产品,你能不能把你原来的经验抽象出并且把它复制到一个新的产品,把这个产品做好。比如存储做好了,可以经验复制到数据库,比如再去做 CDN 能不能做,只有你不停总结去提升,然后把它变成方法论,那你本身的能力就是在提高的,而且你的 scope 也变得越来越大,所以我觉得方法论其实是挺重要,特别是方法论本身的迁移的能力。
总结下,运维的核心,就是这三个(方法论、业务和架构、操作系统)。
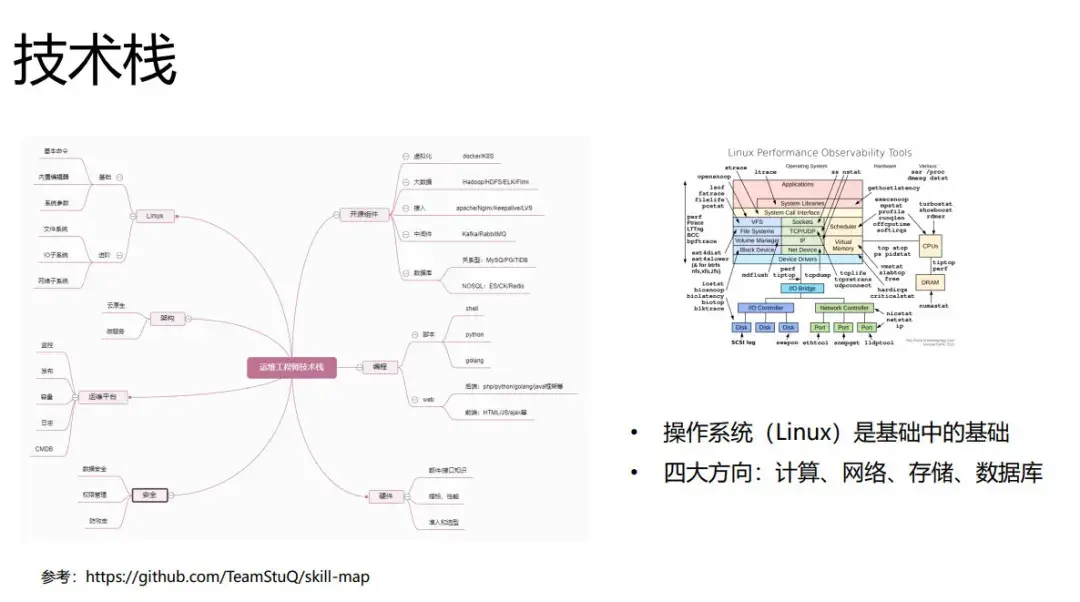
运维的技术栈比较杂比较广,我总结了一些,可以参考左边的这张图。
右边这个图很好,可以用来做 Linux 性能监测或者调优,Linux的体系架构是什么样,每一层应该去用什么工具去看,对应什么样的指标(这个图在网上找就能找到)。
前面我在讲基础的核心竞争力的时,已说道对 linux 的操作的掌握是基础。技术栈也是一样,操作系统一定是技术基础中的基础,然后涉及四大方向:计算、网络、存储、数据库。
如果你做业务运维偏向计算业务,那计算已经做得很厉害后,你还可以去拓展去做网络往深处去扩展,技术是不可能一成不变的,所以除了把基础打好了之外,可以往其他的方向去做扩展和补充。
技术成长也是很多同事在聊的话题,比如最近状态不好,每天都在这干一些重复的事情,也不知道有没有前途,也不知道技术该怎么发展。但其实关于技术成长有个很好的实践,就是公司 P 族的技术运营通道,通道给出了很详细的能力模型系统,分了很多的子通道,每个都有一套完整的模型和能立项。
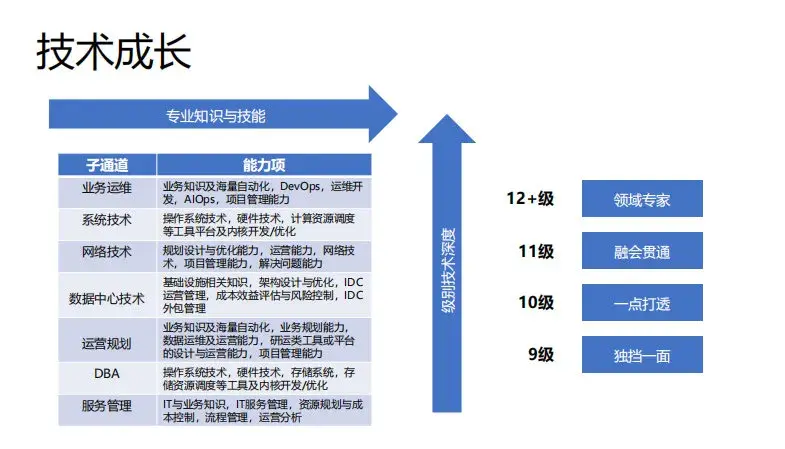
如果你不知道自己到底应该怎样规划技术成长或者技术路线中,可以参考技术运营通道的描述,其实就是是两个维度,第一个是专业知识,是横向的维度,第二是级别深度, 是纵向的深度。
从一个处理现网问题的运维工程师在不同级别的要求是不同的,可以看到对应 8 级或者 10 级的要求是完全不一样的技能
当然还有另一个最简单的方式,大家可以关注一下其他大公司的招聘要求,里面会很清楚的定义这个岗位和级别需要什么样的技术。
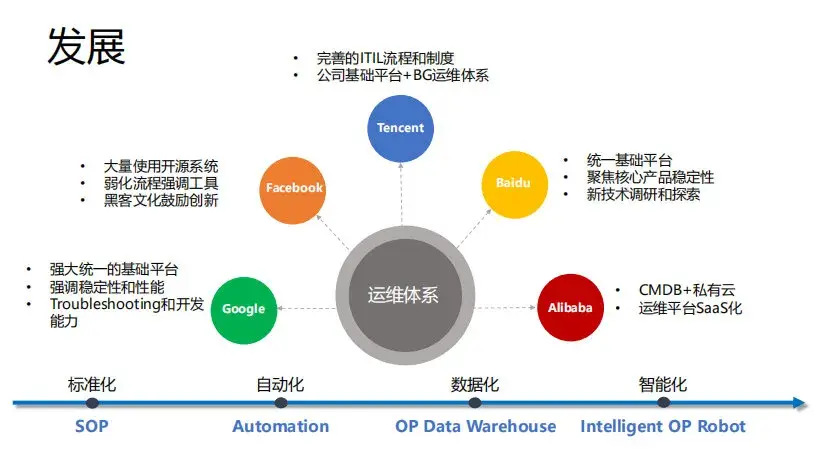
接下来是运维技术的发展和运维体系。运维技术的发展,大致经历了标准化、自动化、数据化、智能化这几个阶段,不同公司不同产品所处的阶段不尽相同。大家也可以对比下自己当前负责的产品处在哪个阶段。这里我总结了行业内不同公司的运维体系,从中可以看出不同公司的运维体系还是不太一样,但其实很难去说哪个运维体系先进。因为不同公司业务、所处的阶段不同,那么他所需要的运维体系可能就不一样。对于行业的趋势和最新的技术,大家还是需要保持学习和敏感度。
这个也是我想重点提的,最近很多同学很焦虑这个问题。首先说 SRE,PCG 有很多组织都已经改了,包括职责也有对应的转变。
到底什么是 SRE? 我的理解很简单:SRE 就是当你让一个软件工程师来带运维团队的产物。Google 的 VP Benjamin 在 2003 年加入谷歌时,当时 Boss 给他的任务是让他组建一个由 7 名工程师组成的生产团队(Production Team)。要知道,在这之前他一直都是个写代码的程序猿!所以他只能按照我自己对运维的理解和想法和组建和带领这个团队,这个团队就成了今天 Google 的 SRE 团队,这个团队也一直坚守着由一位终生程序猿设定的初心。
SRE 团队中的角色分为两类,其中 50%-60%的成员就是 Google 的软件工程师;其余 40%-50%的成员他们本身符合 85%-99% Google 软件工程师的招聘标准,但他们具备一些软件工程师没有的技能,例如 Unix 系统、网络(1 层-3 层)方面的专家,这些技能对 SRE 来说是非常有用的。所有的 SREer 都要求有能力和意识通过开发软件系统来解决负责问题。在 SRE 内部,通过跟踪调研以上两类成员的职业发展轨迹,我们发现并没有什么不同;事实上,不同背景的 SREer 让我们的团队产出了智能、高质量的运维系统。转型——不会开发的运维不是好产品经理。
第二个是 DevOps。 DevOps 我们团队涉及不多,现在的团队主要是做存储,基本上没有转型 DevOps,但实际上现在整个公司包括 TEG,大家都在往这条路上去走,所以这里我浅谈下自己的理解和看法。
我理解 DevOps 更多是一种能力模型。SRE,实际上是对 DevOps 的一个最佳实践。
SRE 更多针对 OKR,DevOps 我觉得更多像一个文化,或者是一种模型。他强调开发运维一体化,为什么要强调一体化?大家知道,在软件工程最有效率的一种组织架构,就是一个人从写代码、测试、开发、运维全部做完,因为他没有沟通,也不需要沟通。我们现在很多团队是 DO 分离的,DO 分离有个最大的问题,就是两个人天天吵架,我们 kpi 也不一样,会有各种各样的冲突,有很多其他成本,但是如果一个人很厉害全都搞定了那就非常有效率,所以 DevOps 最朴素的想法就是,围绕效率把开发和运维一体化。我认为 DevOps 这件事情更多是一种文化,衍生出来一些方法,组织形态,以及一些工具。
第三点,更高大上的一个词叫 AIOps。 这个词实际上提了好多年,但现在大家看你身边真的有很多 AIOps 吗?其实没有。
首先 AIOps,不管是岗位或本身,它是有专业门槛。因为大家做传统运维出身,可以搞定 Linux,写脚本。但如果想往 AIOps 发展,或想知道 AIOps 到底干什么,或需要具备什么能力,我以为大致有 3 点:
第一点,建模能力。 我们遇到的问题都是运维问题。比如快速恢复怎么监控怎么去管资源,但是 AIOps 每天是做的是数学问题(可能是一个分类问题或聚类问题)所以你要有能力能够把运维问题,抽象建模成数学问题,这是最基础的。如果你都不知道怎么把运维问题变成个数学问题,光会算法也不行。有很多同学原来在本科或者是研究生是学算法相关的,但他不懂运维,我们很懂运维但我们数学不太好,所以这里还是有一些专业门槛。
第二点,数据。 现在很多算法最基础是要有数据,有些时候需要做训练,所以有时需要的是有标注的数据。如果你不知道怎么建模,也不知道用什么方法,你先把这些数据全部规划好存储起来,并且能够做好标注,那未来想拿这个数据做一些事情,你是有基础的。反过来如果你有算法,却发现真的要去做很多事情的时候没有数据,这是很致命的,所以我觉得数据对于 AIOps 来说也是很重要的。
第三点,算法。算法现在的平台化和工具化做得非常好,有各种各样的平台,想要什么算法,只要把数据往里面一丢,自己勾一下就行,再做一下调参,这个事情大概就搞定了。如果具体去做算法,或者说研究算法,那可能会比较难,但如果仅仅想用算法,我觉得现在其实门槛没有那么高,各种各样的平台和机器学习相关的一些插件已经很成熟了,所以算法其实还好。所以 AIOps 是的专业门槛的,大概需要把建模能力,数据能力把全部给做起来。
三、运维最终的出路是什么?
最后,也是现场一位同学问我说,运维最终出路是什么?
我的理解是,首先是这个问题在于说大家把自己的角色想得太局限了,总是认为自己是一个运维工程师,就应该天天去看监控、变更,故障处理等等。但实际上我觉得运维最终归宿一定是业务。举个很简单的例子。
第一个例子,原来在上家公司的时候,运维每天都要做告警轮值,这件事情不仅在运营团队,在研发团队,在各种团队都有需求,所以我们当时就把这个事情变成了一个平台,先给公司内部给所有的人用,后来把这个平台变成一个产品卖给其他的公司。因为每一个公司都要做轮值,然后再后来业界出现了个公司 PageDuty,他其实就是把运维的这件事情产品化了,去卖钱。
第二个例子,跟我专业相关的,我是做云盘 CBS,CBS 有不同的规格,有低性能、中性能、高性能。那我们做了很多迁移和调度的事情,比如说用户反馈性能有瓶颈,我可以把他从低性能迁移到高性能上面去,用户就没有问题了。如果我作为一个用户,本身业务是有峰谷的,如果买的高性能云盘,那就一直要按照高性能云盘付费。但晚上如果低峰期,那能不能在晚上把它降成低性能。第二天早上业务高峰期之前,再通过无缝迁移,继续迁移到高性能上去。在运维来看它其实就是一个迁移的工具,但是实际上如果能把它变成一个产品,可能就要一个自身的预判能力;对于用户是非常喜闻乐见,因为原来的成本是一条这样的曲线,通过我们的产品之后,可以变成另一条曲线,能够为用户节约成本。
所以,大家不要把自己想得局限,我们应该想怎么样把我们的运维能力、工具平台,往整个产品的主路径上去输出,产生更多的价值。站在更高的角度去想,能不能给产品增加的更多价值。
最后一句话,不会开发的运维不是好的产品经理。现在对运维的要求越来越高,你除了会运维之外,还要会开发,像 DevOps,结合业务,还是需要有很多的产品思维和产品能力,这样才能够不断拓宽你的职业道路!
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号