单机数据库到分布式存储系统的发展历程
发表时间: 2022-06-21 15:41
日前,字节跳动技术社区 ByteTech 举办的第四期字节跳动技术沙龙圆满落幕,本期沙龙以《字节云数据库架构设计与实战》为主题。在沙龙中,字节跳动基础架构数据库开发工程师马浩翔,跟大家探讨了 《从单机到分布式数据库存储系统的演进》,本文根据分享整理而成。
存储系统是指能高效存储,持久化用户数据的一系列系统软件。在众多的存储系统中,以下是三类比较主流的存储产品及其特点分析:
单机数据库存储,要从内存层和持久化层两个方面来解析。在内存层,仅说关系型数据库,其内存数据结构特点可以总结为:一切都是“树”。我们以最常见的 B+ 树为例,B+ 树具有以下突出的特点:
仅有内存数据结构当然是不够的,我们还需要设计高效的磁盘数据结构,下图展示了从内存数据结构到磁盘数据结构的数据持久化过程:
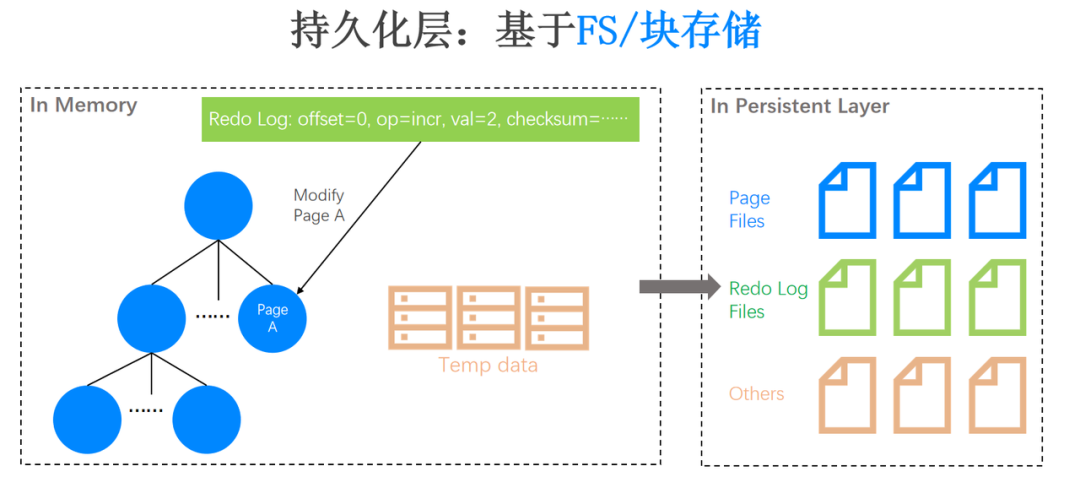
左边虚线框描绘的是 In Memory 结构示意图。举个例子,如果我们要修改 Page A 的某一行数据,对其中的一个字段进行自增,自增值是 2。自然而然会产生一个数据库的物理操作日志,即 Redo Log,用来描述我们对 Page A 的修改。同时,在数据库的事务执行过程中,可能还会产生大量临时数据(图里的 Temp data),当内存不够用的时候也需要将其持久化。
右边虚线框描绘的是 In Persistent Layer 的示意图。假设我们使用比较友好的文件系统来将内存数据持久化,我们需要设置不同的文件,让它们各司其职。例如图里的蓝色文件存储 Page,绿色文件存储 Redo Log,粉色文件存储临时数据。如果数据库发生 crash ,在恢复阶段我们就在各类文件中进行数据定位,结合 Redo Log File 和 Page File ,进行数据库的数据恢复。除此之外,如果直接基于块存储进行持久化,就需要数据库本身的存储引擎管理好 LBA,需要在用户态里面实现 buffer cache 等逻辑,这也是可行的。
那么基于单机的 FS / 块存储去做持久化,我们会遇到哪些问题呢?通过下面的单机数据库系统的典型架构图,我们可以发现三个问题:

为了解决单机数据库存储系统面临的问题和挑战,字节跳动的数据库团队调研了一些业界主流的分布式数据库方案。
需要说明的是,MyRocks 不是分布式数据库或者分布式解决方案,它是单机 SQL over kv 的典型代表。
基于上述字节数据库团队的调研结果,我们设计了 veDB 分布式存储系统以解决单机数据库存储系统面临的问题与挑战,本节将主要介绍 veDB 分布式存储系统的系统目标与核心技术特点。
在设计理念上,我们期望存储系统能够实现以下四个主要目标:
基于以上系统目标,数据库团队设计并开发了 veDB 分布式存储系统,如下图所示:
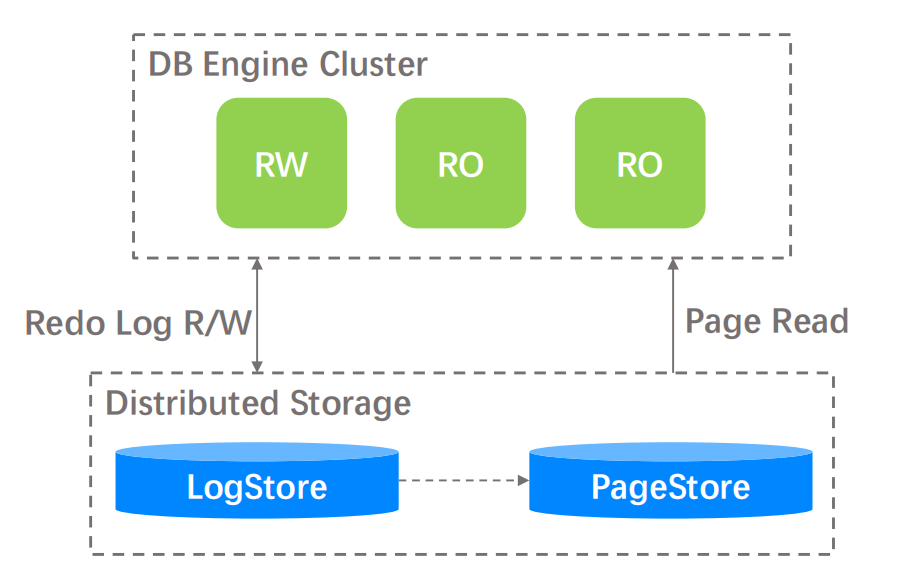
从图中可以看出,分布式存储层基于 LogStore 和 PageStore 这两个子系统构建,其系统特点与我们的设计目标相互呼应。
以下主要从研发背景(Problem)、解决思路(Solution)、解决成效(Outcome)三个方面来分别介绍 veDB 分布式存储系统的五个核心技术。
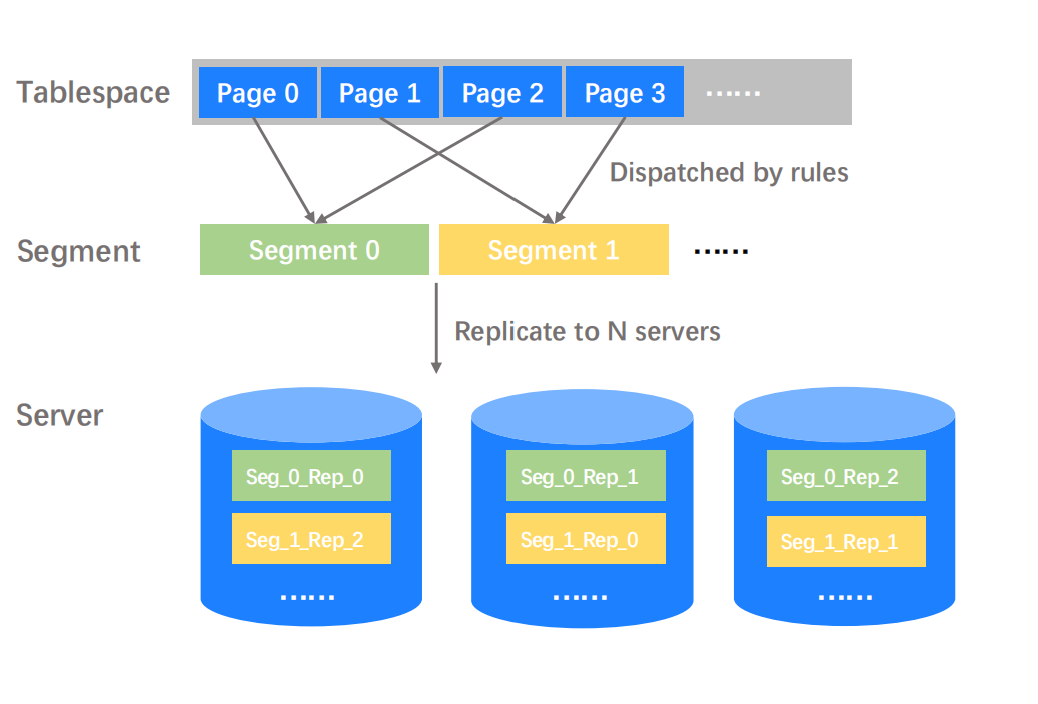
Problem:从单机 FS 到分布式存储,需要有高效的数据布局模型。基于单机的文件系统或块存储系统去实现数据持久化是比较简单的,我们可以直接通过申请一批 LBA 或者一批文件来存储数据,然后控制并发即可,但是这对于分布式存储并不容易。从上面的示意图可以看到,最上层的 Tablespace 代表一张数据库表,里面可能包含上百万甚至上千万的 Page data(数据库的基础管理单元)。然而存储系统的管理单元,却不可能是 Page —— Page 的粒度过小,往往只有 KB 级别,如果存储层以过小的粒度去管理数据,可能会造成元数据膨胀,增加管理成本。
Solution:Tablespace -> Segement 分布式映射。基于上述问题,我们可以在存储层利用相对大的管理单元 Segment 去进行数据管理。此时,数据库的管理单元是 Page,存储系统的管理单元是 Segement。Tablespace 和 Segement 之间必然要存在一层映射关系,该映射关系可以根据不同数据库引擎的数据管理空间大小要求进行设置,可能 MySQL 和 PostgreSQL 的映射规则就大不相同。上述示意图展示了最简单的模 2 规则,我们也可以发展出其他更加复杂的打散规则,此处不进行赘述。当我们将 Page 打散到对应的 Segement 之后,数据库就不需要管数据 Replication 的逻辑,不管底层存储是多副本还是 EC 策略,可以完全由存储系统来做透明的 Replication ,数据库就像在使用单机文件系统一样简单。
Outcome
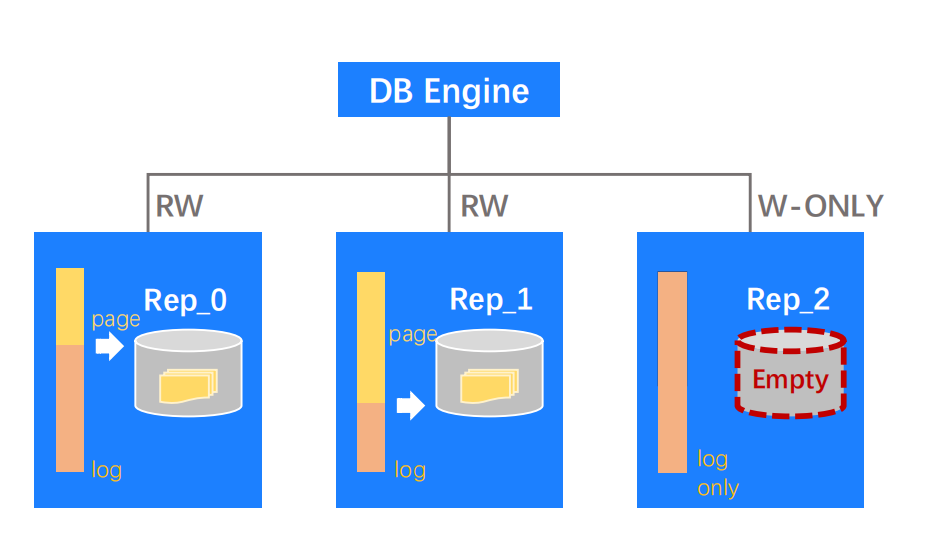
Problem:数据冗余成本高,需要降低存储成本。
Solution:开发 Log-Only Segement,节省非必要的 Page 副本空间。什么是 Log-only segement? 关系型数据库中往往都包含 Log 数据和 Page 数据。在存储层中,存了多副本的 Log 数据后,我们可以选择性地只回放一部分 Log 数据来生成 Page,让另一部分 Log 数据保持不动,不要生成任何 Page 数据。以上面的示意图为例,Rep_0 和 Rep_1 都是 Log 数据生成的各种版本 Page 数据,然而 Rep_2 是一个空的 Page 数据副本,它里面只有 Redo log。我们都知道 Redo log 和 Page data 的数据大小比例是比较夸张的,Page data 的大小可能是 Redo log 的几倍甚至十几倍,因此通过以上方法能够较大的节省单机的 Page 存储空间。
Outcome:结合单机引擎的压缩算法,能将存储空间放大倍数从 3.x -> 1.x,较好缓解成本问题。
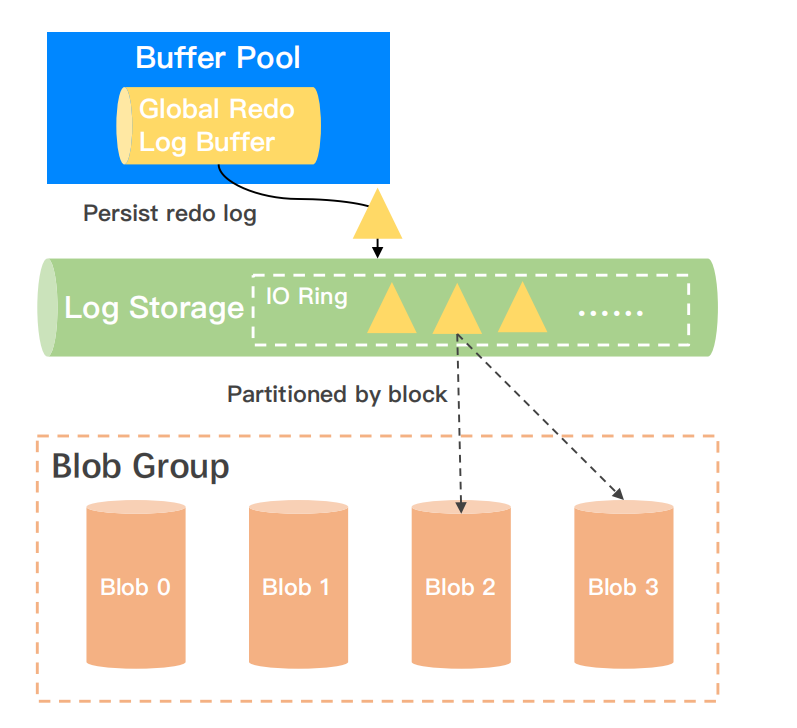
Problem:存储层写性能容易成为系统性能瓶颈,如何解决?
Solution:全异步 IO + 无锁结构 +并发打散。当数据库提交了一个 Redo log 到 Log Storage 之后,Log Storage 中会有一个无锁的 Ring buffer 去对 Redo log 进行有序组织,然后我们将 Redo Log 的 Ring buffer 进行线性的定长切割,并发打散到底层存储的 Blob 单元。
Outcome:4KB + depth 8,write latency ~100+us,较好支撑了数据库下发日志的性能刚需。
PITR(Point-in-time Recovery)是指我们都可以迅速地恢复在过去一段时间内某个时间点的数据库快照。
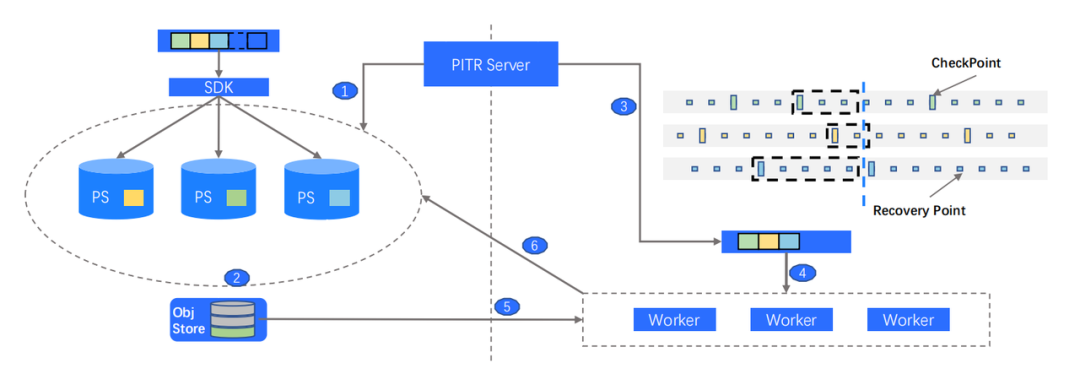
Problem:如何快速备份恢复,且降低对前台业务影响?
Solution:基于 Segement 的高并发 PITR 机制,Segement 间互不影响。之前提到存储层的管理单元是 Segement ,我们也可以基于 Segement 做备份恢复。这样做有两个好处:首先计算层是完全透明的,计算层完全不会感知,并且计算层的性能不会抖动。其次基于 Segment 可以做到天然的并发打散,因此备份恢复也可以做到并发恢复。
Outcome
Problem:数据库团队希望统一的存储层能够支持不同的数据库引擎,做到 100% 兼容和快速接入。
Solution:Write Ahead Log + Log Replay = 任意 Page Data。基于本地存储引擎的 k-v 结构,或者基于裸的块设备抽象出一种相对通用的数据结构,从而高效地存储 Page data。同时,我们在 SDK 侧和 Server 侧都做了 Log parse 的插件化,要接入新的数据库引擎只需要其提供适配存储接口的日志插件,从而可以快速接入各式各样的数据库计算引擎。
Outcome:
在谈及数据库存储的未来演进时,首先我们可以思考一下哪些因素会触发数据库存储架构的变革和演进?答案可能包含:存储架构自身的革命、数据库理论的突破、或者新硬件冲击引发存储系统架构迭代。基于这三个方向的思考,我们总结了以下几个数据库存储系统的演进趋势:
我们总结的第一个趋势即 HTAP/HSAP 系统将会逐渐爆发。在 HTAP/HSAP 系统中,“实时”是第一关键词。为了支持实时,存储系统可能会发生架构演进和变革,因此我们需要探索:
AI 技术运用领域广泛,具体在数据库存储领域,我们可以利用 AI 技术进行以下工作:
在硬件变革趋势上,我们总结了三个变革方向:
Database & Cloud Storage Team,服务于字节跳动全系产品。在这里,我们有丰富的云存储产品,负责治理数十 EB 级别的海量数据;有多种数据库产品,提供极致时延、超大吞吐的云原生数据库服务;有前沿的技术研究,探索新硬件与新软件架构的融合,打造下一代革命性的云存储与数据库产品。

以上内容整理自第四期字节跳动技术沙龙《字节云数据库架构设计与实战》,获取讲师 PPT 和回放视频,请在公众号“字节跳动技术团队”后台回复关键词“0416”。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号