深度解析:AIGC版权问题的全面指南
发表时间: 2023-07-27 12:14

伴随着 AIGC 技术的强势出圈,大家在惊叹 AI 技术强大的同时,也有越来越多的人开始讨论关于由此带来的版权问题:我们通过 AI 生成的图像属于平台还是个人?目前 AI 作品版权在法律上是如何界定的?又该如何避免引起 AI 版权的纠纷?
实际情况是怎样的呢?我们再来看看平台方在这方面的规定。根据 Midjourney 在平台规则手册中标注的信息中,明确标注了除非是高收入的公司用户,正常情况下付费会员制作的 AI 图像是拥有完全所有权的,可以自由使用创作的图片。这表明了Midjourney作为开发者方自主放弃了生成图像的所有权。
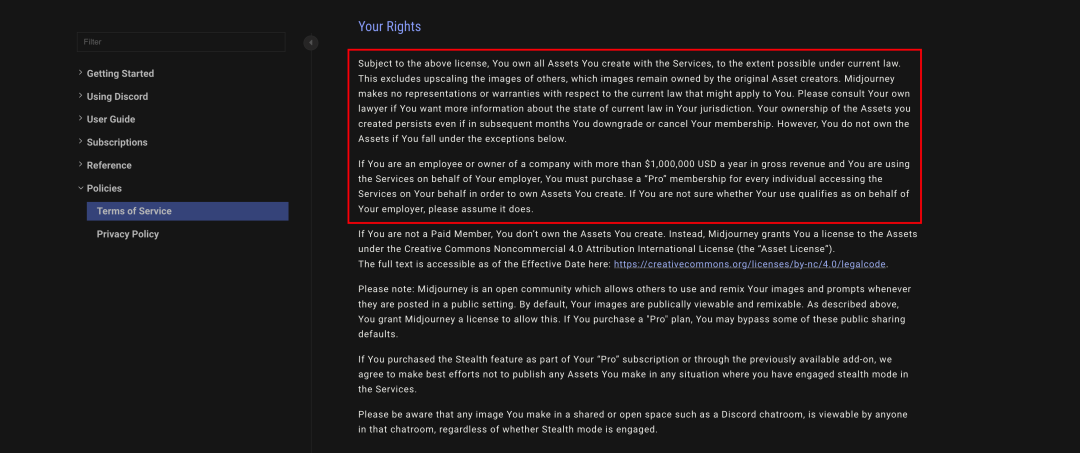
图像来源:Midjourney 服务条款-用户权益
从平台声明来看,似乎创作者可以完全放心的使用 Midjourney 生成的 AI 作品,但是事实真的如此吗?
近期就有 3 位艺术家代表美国加州艺术家群体起诉Stability AI、Midjourney及DeviantArt公司的 AIGC 技术,控诉他们未经原创作家许可,便贸然使用网络上的 50 亿张图像进行 AI 训练。
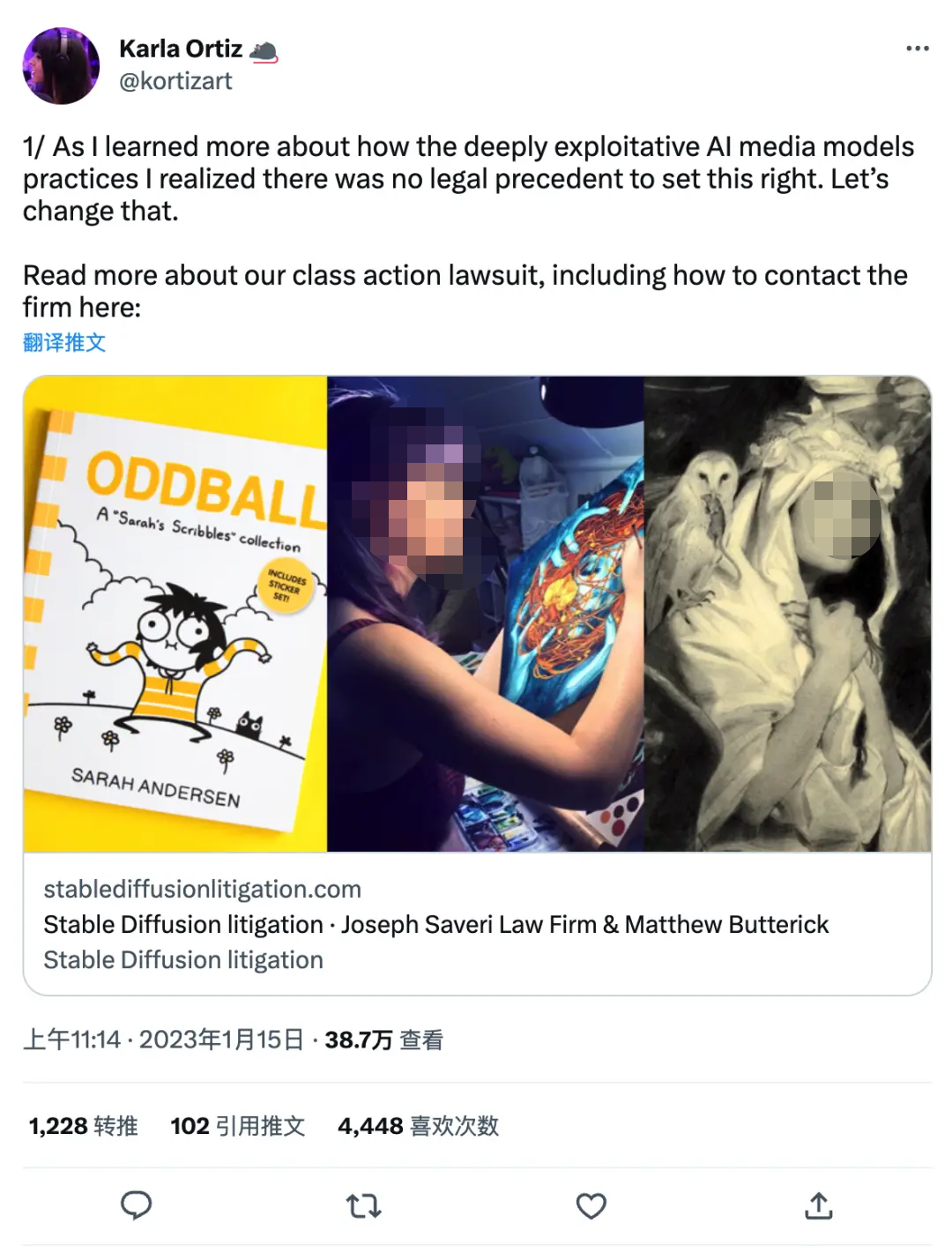
艺术家 Karla Ortiz 在评论中说到:我很自豪能成为这起集体诉讼的原告之一。我很自豪能与同行一起做这件事,我们将为可能受到影响的数千名艺术家发声。我很自豪在公共领域而且在法庭上为我们的权利而战!
想要真正理解事情的发展缘由,需要了解 AI 绘图创作过程中可能会产生侵权问题的行为,目前主要有 2 个阶段会引起版权争议的问题:分别是模型训练阶段和图像输出阶段。
首先,AI 技术想要发展和提升必须有体量极度庞大的数据库进行模型训练,这个过程中数据库会不可避免的包含很多受版权保护的作品。可能大家对数据在 AI 领域的重要性并不太清楚?可以这么说,数据是一切人工智能的基础。体现在很多行业中,数据都是影响企业竞争的重要壁垒之一,比如特斯拉在自动驾驶领域的数据积累和科大讯飞在智慧教育领域的题库积累等。
以 ChatGPT 为例,根据 OpenAI 公司的透露,他们在训练过程中使用45TB的数据,包含近1万亿个单词,这个数字差不多抵得上牛津词典单词量的 1300 倍。根据麻省理工大学的Pablo Villalobos等6位计算机科学家就预测,到2026年,ChatGPT等大型语言模型的训练就将耗尽互联网上的可用文本数据,届时将没有新的训练数据可供使用。
图片来源:OpenAI 官网 ChatGPT训练模型
而目前AI模型的数据来源包括以下几类:公共数据集、公共网站、自有数据、众包数据、合成数据等。除了合成数据没有版权争议外,其他数据都是通过采集互联网获得,而合成数据目前还处于初步发展阶段,没办法大规模应用到当前市场中。
比如著名的 AI绘图工具Stable Diffusion,它的模型训练数据源是包含了上亿图像的LAION-5B数据库,该数据库本身并不储存网络图像本体,而是作为各类版权作品的在线索引,在训练模型时需要先将作品下载到本地储存为副本,那这个下载过程本身就包含了对版权作品的使用。

图像来源:LAION-5B 官网《开放大规模多模态数据集的新时代》,作者 Romain Beaumont
接着在图像输出阶段, AI 模型会将数据库中的资源进行算法解析,组合生成新的图像。目前 AI生成绘画图像 主要有 3 种方式:图片滤镜、笔触临摹和关键词模态转化。
但是不管是通过哪种方式生成的 AI 图像,必然会包含数据库中版权作品的部分特征,考虑到最终生成图像和原版权作品的相似性,是有可能对原创作品产生抄袭嫌疑的。
这时候有人可能会说,AI 的训练数据数以亿计,担心最终生成的图像和其中几张相似也太过于杞人忧天了。然而在最新一项以Stable Diffusion等AI扩散生成模型为研究对象的实验中,马里兰大学和纽约大学的联合研究团队指出:利用Stable Diffusion模型生成的内容与数据集作品相似度超过50%的可能性达到了1.88%。此外,考虑到实验中样本量只使用了 1200 万张图片和全世界庞大的用户使用量,AIGC 作品的侵权行为很可能比我们想象中要大得多。(信息来源:腾讯研究院)
去年年底,国外艺术作品平台 ArtStation 上的画师们发起了联合抵制 AI作品的活动,集体在官网打出“NO TO AI GENERATED IMAGES” 的标语。作为职业画师社交网站,它的存在本身就是为了展示绘画创作者的创意和技法,提升自己的行业影响力,但是 AI 作品的出现打破了这种行业平衡。
去年,纽约艺术家 Kashtanova 利用 Midjourney 创作了一份有 18 页组成的漫画书《Zarya of the Dawn》,并在 9 月为此申请了版权。然而到今年 2 月份的时候,美国版权局在了解到 K女士详细的制作过程后进行了回信并进行了详细说明,回信中的内容总结来说就是:由 Midjourney 生成的作品并不由人类直接创作,所以不受版权保护。但是创作过程中的文字、收集的素材、元素排版、整理等工作内容受版权的保护。
在回信中,美国版权局为此还进行了详细说明:首先 AI 生成图像是随机的,整个过程不像传统创作那样完全被创作者掌控。在创作过程中人类只是从AI生成的图像中选择了一个最合适的,期间并没有人类主体创作的过程,虽然最后 K 女士有使用 Phootoshop 进行修正,但是修改的内容太少,也不属于版权保护的范围。此外用来生成图像的关键词本身也不具备版权保护。
在这个案例中我们可以发现目前来看国外官方对于 AI 版权的态度并不是全盘否定的,对于人类参与创作的部分还是保持肯定的。那我国目前在 AI 作品上是如何判定版权的呢?
根据李宗辉老师(南京航空航天大学网络与人工智能法治研究院副院长)刊登在2022年第3期《版权理论与实务》的杂志文章《论人工智能绘画中版权侵权的法律规制》中所述,目前我国版权法采用的是“思想与表达二分法”的基本原则,来作为判断 AI 绘画是否构成侵权的指导依据。
打个比方,前面我们提到 AI 绘画的 3 种方式时,其中对绘画特征的提取、笔触序列的提炼或者作品表达的情感这些还未落实成图像的算法内容,还是属于作品的思想阶段,并不会被判定为归原作者版权所有。但是当实际的图像生成时,如果判断AI 画作是否与某一部作品构成实质性相似适宜采用部分比对法,与多部作品进行判断时则应当采纳整体观感法。而一旦比对结果构成实质性相似,即应被认为构成复制侵权行为。
此外在生成图像的使用用途上,也会检测是否造成侵权。比如是完全商用还是适度饮用,是否会和原作品正常使用造成冲突,有没有损害原作者的合法权益等。
我们综合国内外的解释来看,目前的法律条文对于 AI 作品的版权界定主要停留在对创作者参与创作的比例以及相似度的主观判断上,对于参与多少可以受版权保护、相似度差异达到多少阈值的时候会判定为不侵权等问题还没有非常具体的判断条例。
这种情况也很正常,毕竟 AI 技术的发展过于迅速,当前的法律条文还未来得及覆盖人工智能领域的作品。但是我们作为 AIGC 技术的使用者需要意识到,在未来这段时间内通过 AIGC 生产的内容都存在对其他作品侵权的可能,同时自己的 AI 作品也不受版权保护,随时可能被其他人拿去使用。
不过我们也大可不必忽视 AIGC 的价值,完全抵制 AI 技术带来的生产力革新,我们更应该思考的是如何避免自己的 AI 作品产生侵权风险,以及保障自己作品的合法权益。
考虑到前面对侵权行为的判定标准,未来我们在使用 AIGC 的过程中可以注意以下几点:在工作中如果需要对 AI 作品商业化,需提前了解AI 工具平台方相关的使用手册或用户协议等文件,明确产出内容的所有权范围和用途,避免后期产生法律纠纷。
此外不要直接的将 AI作品 作为自己的最终成果,而是将 AIGC 技术作为实现目的工具,在其中尽可能增加自己的创作痕迹和想法,比如先用Midjourney 等 AI 工具生成众多风格的效果图,快速验证自己的灵感和产品方向,再以此为参考进行设计。这样既保证了作品的原创比例,同时也是体现设计师作为设计主体的核心价值。
此外,如果想彻底杜绝被原作者举证 AI 创作侵权的可能性,可以提前了解创作AI 模型的采集数据源,在使用参考图创作后标注原作来源或提前获得原作者的授权。
以上是我们作为 AI 技术的使用者需要了解的一些事项。而 AI 技术的开发者和平台方作为 AIGC 的最大受益者,更是需要担负起人工智能侵权行为的主要责任。他们是 AI 技术控制权的主体,应该主动公开说明使用过程中可能产生侵权风险的行为,并对产生侵权行为的算法漏洞及时维护和修补,只有这样才能真正保证 AIGC 技术做到互惠互利,持久发展。
以上就是关于 AI 作品版权问题的现状和给大家的一些建议。虽然目前 AI 侵权相关的法律条文还不成熟,需要经过多方考量和求证,但是未来针对 AIGC 作品的具体规范文件出台是大势所趋。我们既要肯定 AIGC 技术带来生产效率上的巨大提升,同时我们也要保证创作者的合法权益,毕竟版权保护的是每一位原创作者的劳动成果和智慧结晶,而不是人工智能本身。
本文由 @乐伊ROY 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号