Redis缓存雪崩、穿透、击穿:一张图让你一目了然
发表时间: 2020-10-27 04:24

作者 | 雷架
文章来源 | 爱笑的架构师 (id :DancingOnYourCode)

缓存异常场景分类
在实际生产环境中有时会遇到缓存穿透、缓存击穿、缓存雪崩等异常场景,为了避免异常带来巨大损失,我们需要了解每种异常发生的原因以及解决方案,帮助提升系统可靠性和高可用。

缓存穿透
缓存穿透是指用户请求的数据在缓存中不存在即没有命中,同时在数据库中也不存在,导致用户每次请求该数据都要去数据库中查询一遍,然后返回空。
如果有恶意攻击者不断请求系统中不存在的数据,会导致短时间大量请求落在数据库上,造成数据库压力过大,甚至击垮数据库系统。
(1)布隆过滤器(推荐)
布隆过滤器(Bloom Filter,简称BF)由Burton Howard Bloom在1970年提出,是一种空间效率高的概率型数据结构。
布隆过滤器专门用来检测集合中是否存在特定的元素。
如果在平时我们要判断一个元素是否在一个集合中,通常会采用查找比较的方法,下面分析不同的数据结构查找效率:
当需要判断一个元素是否存在于海量数据集合中,不仅查找时间慢,还会占用大量存储空间。接下来看一下布隆过滤器如何解决这个问题。
布隆过滤器设计思想
布隆过滤器由一个长度为m比特的位数组(bit array)与k个哈希函数(hash function)组成的数据结构。位数组初始化均为0,所有的哈希函数都可以分别把输入数据尽量均匀地散列。
当要向布隆过滤器中插入一个元素时,该元素经过k个哈希函数计算产生k个哈希值,以哈希值作为位数组中的下标,将所有k个对应的比特值由0置为1。
当要查询一个元素时,同样将其经过哈希函数计算产生哈希值,然后检查对应的k个比特值:如果有任意一个比特为0,表明该元素一定不在集合中;如果所有比特均为1,表明该集合有可能性在集合中。为什么不是一定在集合中呢?因为不同的元素计算的哈希值有可能一样,会出现哈希碰撞,导致一个不存在的元素有可能对应的比特位为1,这就是所谓“假阳性”(false positive)。相对地,“假阴性”(false negative)在BF中是绝不会出现的。
总结一下:布隆过滤器认为不在的,一定不会在集合中;布隆过滤器认为在的,可能在也可能不在集合中。
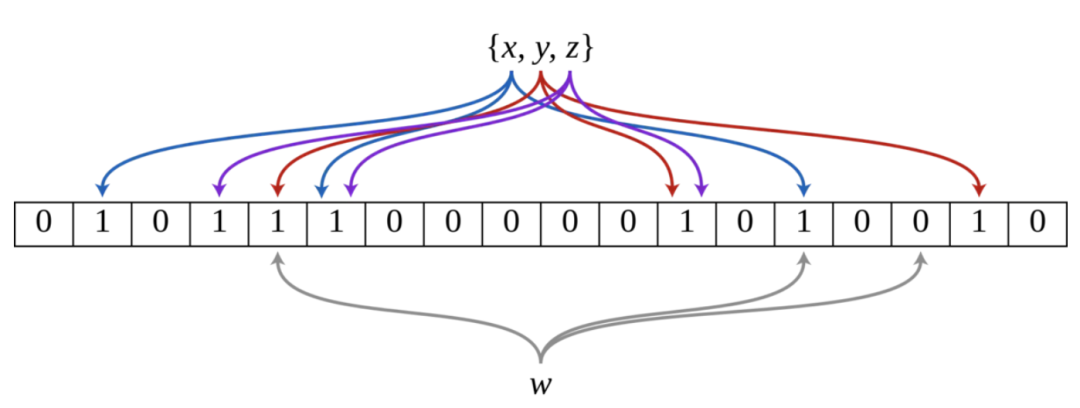
举个例子:下图是一个布隆过滤器,共有18个比特位,3个哈希函数。集合中三个元素x,y,z通过三个哈希函数散列到不同的比特位,并将比特位置为1。当查询元素w时,通过三个哈希函数计算,发现有一个比特位的值为0,可以肯定认为该元素不在集合中。
布隆过滤器优缺点
优点:
缺点:
布隆过滤器适用场景
(2)返回空对象
当缓存未命中,查询持久层也为空,可以将返回的空对象写到缓存中,这样下次请求该key时直接从缓存中查询返回空对象,请求不会落到持久层数据库。为了避免存储过多空对象,通常会给空对象设置一个过期时间。
这种方法会存在两个问题:

缓存击穿
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
数据库瞬时压力骤增,造成大量请求阻塞。
使用互斥锁(mutex key)
这种思路比较简单,就是让一个线程回写缓存,其他线程等待回写缓存线程执行完,重新读缓存即可。
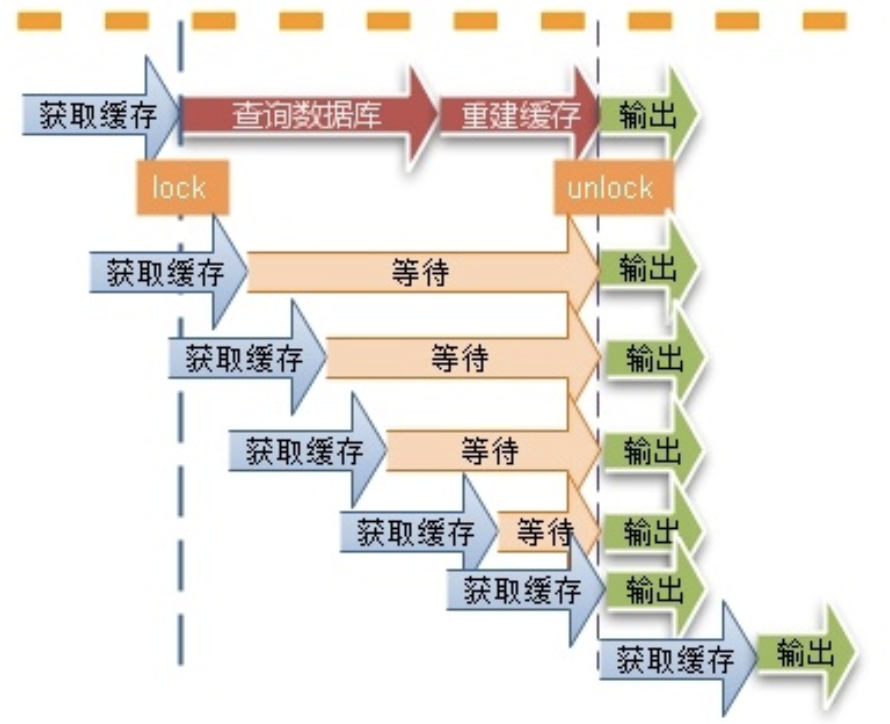
同一时间只有一个线程读数据库然后回写缓存,其他线程都处于阻塞状态。如果是高并发场景,大量线程阻塞势必会降低吞吐量。这种情况如何解决?大家可以在留言区讨论。
如果是分布式应用就需要使用分布式锁。
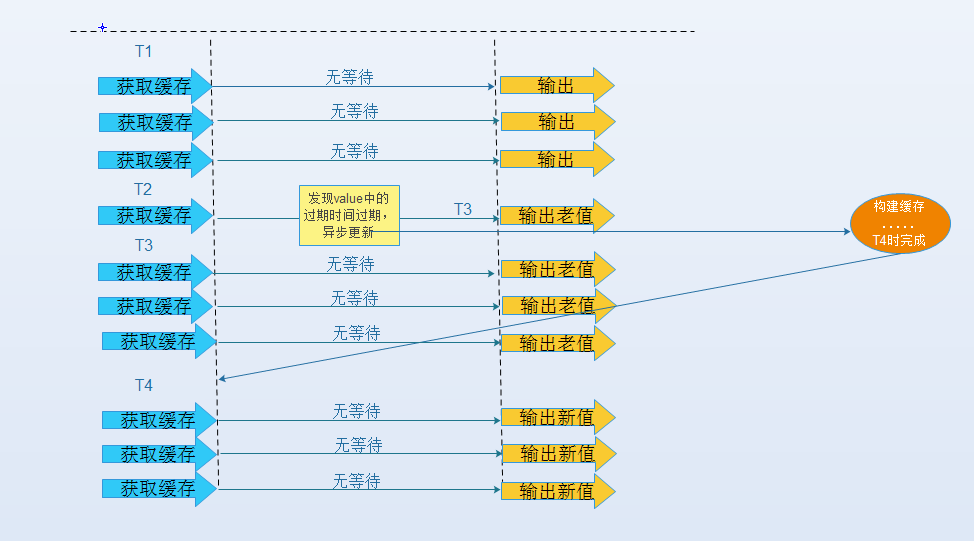
热点数据永不过期
永不过期实际包含两层意思:

缓存雪崩
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,请求直接落到数据库上,引起数据库压力过大甚至宕机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
常用的解决方案有:
(1)均匀过期
设置不同的过期时间,让缓存失效的时间点尽量均匀。通常可以为有效期增加随机值或者统一规划有效期。
(2)加互斥锁
跟缓存击穿解决思路一致,同一时间只让一个线程构建缓存,其他线程阻塞排队。
(3)缓存永不过期
跟缓存击穿解决思路一致,缓存在物理上永远不过期,用一个异步的线程更新缓存。
(4)双层缓存策略
使用主备两层缓存:
主缓存:有效期按照经验值设置,设置为主读取的缓存,主缓存失效后从数据库加载最新值。
备份缓存:有效期长,获取锁失败时读取的缓存,主缓存更新时需要同步更新备份缓存。
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统,这样就可以避免在用户请求的时候,先查询数据库,然后再将数据回写到缓存。
如果不进行预热, 那么 Redis 初始状态数据为空,系统上线初期,对于高并发的流量,都会访问到数据库中, 对数据库造成流量的压力。

缓存降级
缓存降级是指缓存失效或缓存服务器挂掉的情况下,不去访问数据库,直接返回默认数据或访问服务的内存数据。
在项目实战中通常会将部分热点数据缓存到服务的内存中,这样一旦缓存出现异常,可以直接使用服务的内存数据,从而避免数据库遭受巨大压力。
降级一般是有损的操作,所以尽量减少降级对于业务的影响程度。

点分享声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号