Python编程:算法与数据结构概述
发表时间: 2019-12-24 16:19
问题一:1+2+3+4+5+…+10000=?
第一种解法:
1+2=3,3+3=6,6+4=10,10+5=15…
这是要算到猴年马月的节奏呀 果断弃之
第二种解法:
聪明的高斯,这样玩:
(1+10000)×10000÷2=50005000 (1+10000)\times10000\div2=50005000(1+10000)×10000÷2=50005000
在这一问题的解答上,高斯的方法真香!

问题二:冬天里,你和小红玩猜数字,小红随便想一个1~100的数字。你的目标是以最少的次数猜到这个数字。你每次猜测后,小红会说小了、大了或对了。在10次内猜对了,小红就答应今晚用你暖床。是不是听着很刺激
第一种解法:
你从1开始依次往上猜,猜测过程会是这样,小红皱着眉不断说小了
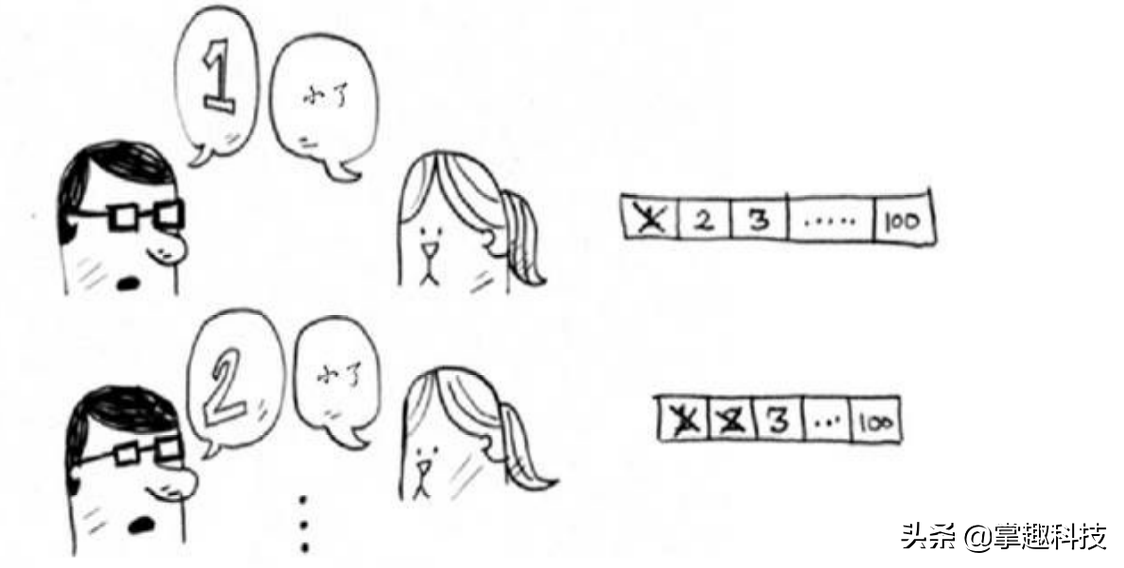
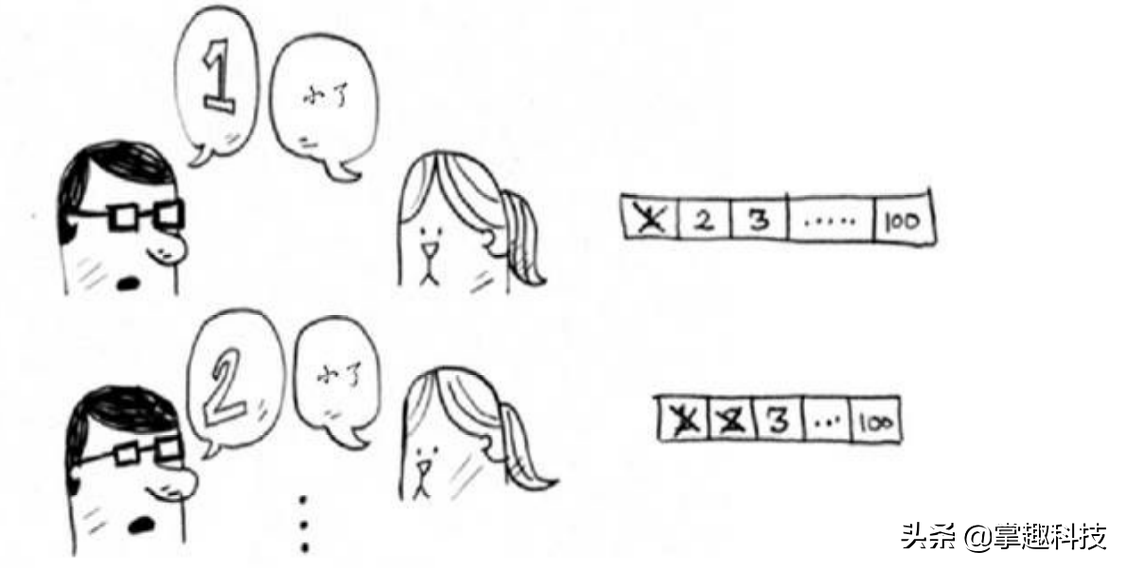
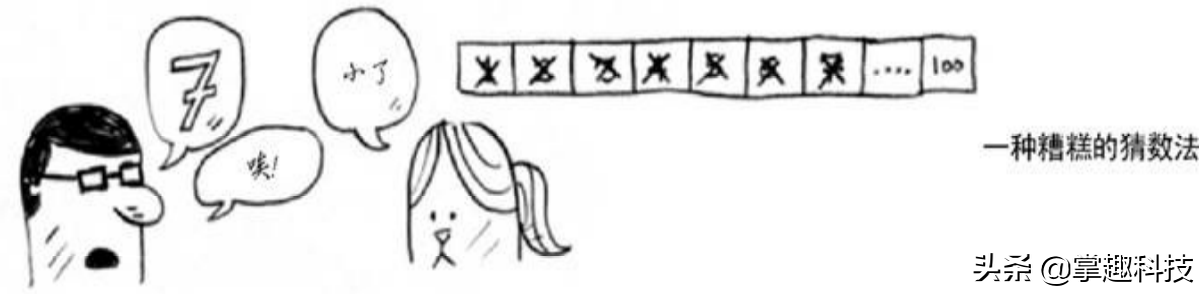
这是简单查找,更准确的说法是傻找 。每次猜测都只能排除一个数字。如果小红想的数字是99,你得猜99次才能猜到!,注定今晚你和小红无缘了
第二种解法:
你从50开始,小红笑着说小了,你接着说75…
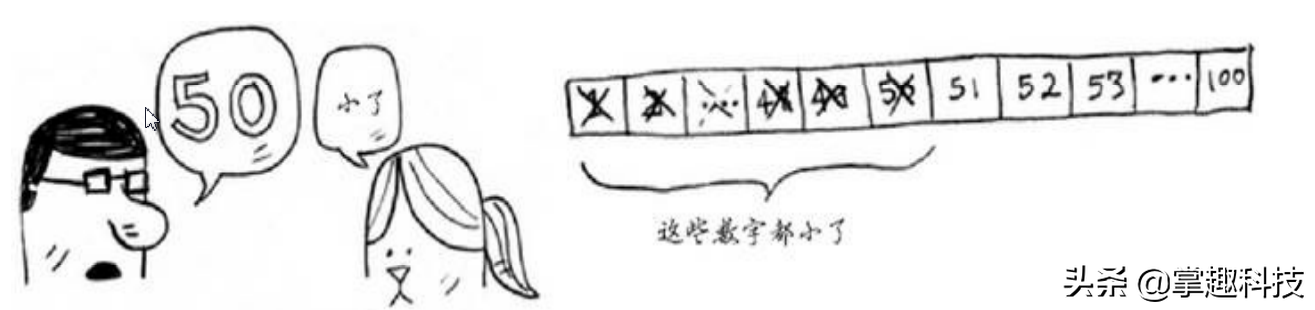
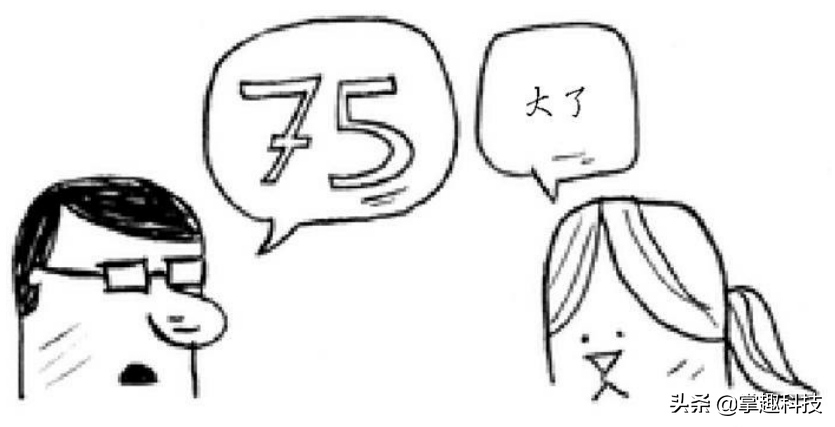
你每次猜测的是中间的数字,从而每次都将余下的数字排除一半。接下来,你猜63(50和75中间的数字)…这就是二分查找,每次猜测排除的数字个数如下:

不管小红心里想的是哪个数字,你在7次之内都能猜到,因为每次猜测都将排除很多数字!恭喜你,小红今晚是你的人了。
解析:对于包含n 个元素的有序列表,用二分查找最多需要log2n log_2 nlog2n步1,而简单查找最多需要n 步。
二分查找的python实现
def binary_search(list1, item):
low = 0 # low和high用于跟踪要在其中查找的列表部分
high = len(list1) - 1
while low <= high:
mid = (low + high) // 2
guess = list1[mid]
if guess == item: # 猜对了
return mid # 返回位置
elif guess > item: # 猜大了
high = mid - 1
else: # 猜小了
low = mid + 1
return None # 没有找到
my_list = [i for i in range(1,100)] # 列表推导式生成0-100个数
print(binary_search(my_list, 3)) # 别忘了索引从0开始
回到前面的二分查找。使用它可节省多少时间呢?简单查找逐个地检查数字,如果列表包含100个数字,最多需要猜100次。如果列表包含40亿个数字,最多需要猜40亿次。换言之,最多需要猜测的次数与列表长度相同,这被称为线性时间(linear time)。
二分查找则不同。如果列表包含100个元素,最多要猜7次;如果列表包含40亿个数字,最多需猜32次。厉害吧?二分查找的运行时间为对数时间 (或log loglog时间)。
算法
在计算机领域,我们同样会遇到各种高效和拙劣的算法。衡量算法好坏的重要标准有两个。通常指最糟的情形下的:
时间复杂度(采用大O表示法)
空间复杂度(采用大O表示法)
理解:小明和小刚都是初入IT的新人,一天老板给他们布置了同一个需求让他们用代码实现出来,小明的代码运行一次要花100ms,占用内存5MB。小刚的代码运行一次要花100s,占用内存500MB。于是……小刚第二天就从公司消失了

你经常会遇到的5种大O运行时间:
O (logn log nlogn),也叫对数时间,这样的算法包括二分查找
O (n),也叫线性时间,这样的算法包括简单查找
O (n∗logn n * log nn∗logn),这样的算法包括快速排序——一种速度较快的排序算法。
O (n2 n ^2n2),这样的算法包括选择排序——一种速度较慢的排序算法。
O (n! n !n!),这样的算法包括旅行商问题的解决方案——一种非常慢的算法.
假设你要绘制一个包含16格的网格,且有5种不同的算法可供选择:


时间复杂度的概念明白了,那空间复杂度呢:
问题三:给出下图所示的n个整数,其中有两个整数是重复的,要求找出这两个重复的整数。

第一种解法:
你采用双重循环,遍历整个数列,每遍历到一个新的整数就开始回顾之前遍历过的所有整数,看看这些整数里有没有与之数值相同的,第1步,遍历整数3,前面没有数字,所以无须回顾比较。第2步,遍历整数1,回顾前面的数字3,没有发现重复数字。后续步骤类似,一直遍历到最后的整数2,发现和前面的整数2重复。
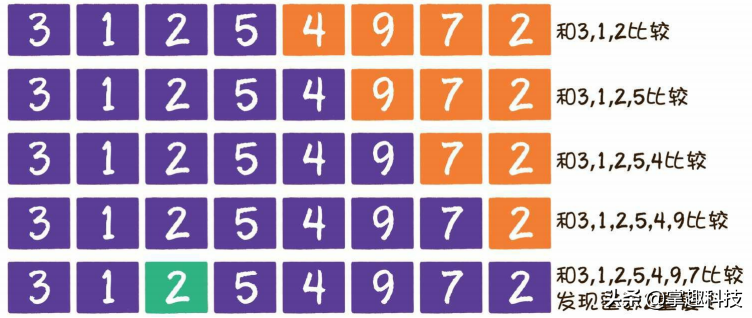
这个算法的时间复杂度是O(n2) O(n^2)O(n2)
第二种解法:
当你遍历整个数列时,每遍历一个整数,就把该整数存储起来,就像放到字典中
一样。当遍历下一个整数时,不必再慢慢向前回溯比较,而直接去“字典”中查找,看看有没有对应的整数即可。“字典”左侧的Key代表整数的值,“字典”右侧的Value代表该整数出现的次数(也可以只记录Key)。当遍历到最后一个整数2时,从“字典”中可以轻松找到2曾经出现过,问题也就迎刃而解了。
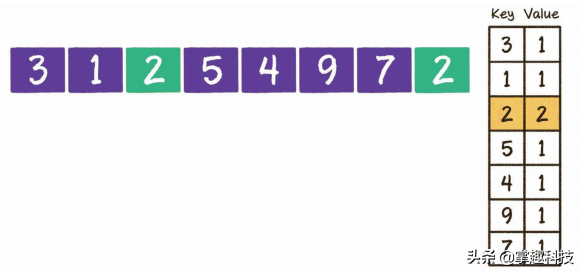
读写“字典”本身的时间复杂度是O(1) O(1)O(1),所以整个算法的时间复杂度是O(n) O(n)O(n)
第二种解法采用的这个所谓的“字典”,是一种特殊的数据结构,叫作散列表。这个数据结构需要开辟一定的内存空间来存储有用的数据信息。
计算机的内存空间是有限的,在时间复杂度相同的情况下,算法占用的内存空间自然是越小越好。如何描述一个算法占用的内存空间的大小呢?这就用到了算法的另一个重要指标——空间复杂度(space complexity)。
常量空间,当算法的存储空间大小固定,和输入规模没有直接的关系时,空间复杂度记作O(1) O(1)O(1)
线性空间,当算法分配的空间是一个线性的集合(如数组),并且集合大小和输入规模n成正比时,空间复杂度记作O(n) O(n)O(n)
二维空间,当算法分配的空间是一个二维数组集合,并且集合的长度和宽度都与输入规模n成正比时,空间复杂度记作O(n2) O(n^2)O(n2)
递归空间,递归是一个比较特殊的场景。虽然递归代码中并没有显式地声明变量或集合,但是计算机在执行程序时,会专门分配一块内存,用来存储“方法调用栈”。执行递归操作所需要的内存空间和递归的深度成正比。纯粹的递归操作的空间复杂度也是线性的,如果递归的深度是n,那么空间复杂度就是O(n) O(n)O(n)。
时间与空间的取舍:
人们之所以花大力气去评估算法的时间复杂度和空间复杂度,其根本原因是计算机的运算速度和空间资源是有限的。虽然目前计算机的CPU处理速度不断飙升,内存和硬盘空间也越来越大,但是面对庞大而复杂的数据和业务,我们仍然要精打细算,选择最有效的利用方式。
在寻找重复整数的问题三中,双重循环的时间复杂度是O(n2) O(n^2)O(n2),空间复杂度是O(1) O(1)O(1),这属于牺牲时间来换取空间的情况。相反,字典法的空间复杂度是O(n) O(n)O(n),时间复杂度是O(n) O(n)O(n),这属于牺牲空间来换取时间的情况。在绝大多数时候,时间复杂度更为重要一些,我们宁可多分配一些内存空间,也要提升程序的执行速度。
数据结构
算法的概念理解清楚了,下面就是数据结构。如果把算法比喻成美丽灵动的舞者,那么数据结构就是舞者脚下广阔而坚实的舞台。数据结构,对应的英文单词是data structure,是数据的组织、管理和存储格式,其使用目的是为了高效地访问和修改数据。
常见的数据结构:
线性结构,线性结构是最简单的数据结构,包括数组、链表,以及由它们衍生出来的栈、队列、哈希表。
树是相对复杂的数据结构,其中比较有代表性的是二叉树,由它又衍生出了二叉堆之类的数据结构。
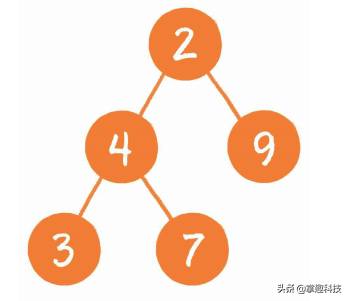
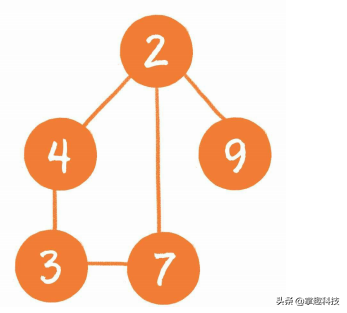
图是更为复杂的数据结构,因为在图中会呈现出多对多的关联关系。
山东掌趣网络科技有限公司
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号