技术汇总:Android音视频开发全解析
发表时间: 2023-07-31 20:28
现在市面上的图像,音视频软件越来越多,最近两年也是直播,短视频的红利期。而图像、音视频一直是互联网视觉的入口,掌握并熟练运用音视频、图像技术已经是当前互联网时代不可或缺的技能,而且这个技能是具有沉淀性质的。
目前市面上的学习资料参差不齐,我觉得想要开启音视频的学习之路,先得了解整体流程上会涉及的技术点,再一个个击破。我也是音视频方面的小白,最近公司要做一个视频换脸的应用,目前处于技术调研期。趁此空档,我准备开始我的音视频学习之路。
图像类:


音频类:


视频类:


以手机直播为例,其整体流程如下:
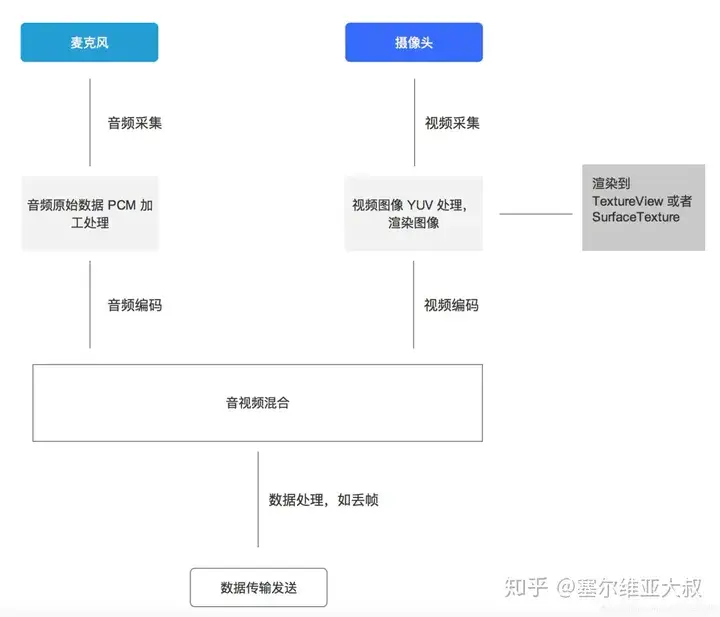
1. 音频采集
音频采集涉及到以下几点:
在 Android 系统中,一般使用 AudioRecord 或者 MediaRecord 来采集音频。AudioRecord 是一个比较偏底层的 API,它可以获取到一帧帧 PCM 数据,之后可以对这些数据进行处理。而 MediaRecorder 是基于 AudioRecorder 的 API (最终还是会创建AudioRecord 用来与 AudioFlinger 进行交互) ,它可以直接将采集到的音频数据转化为执行的编码格式,并保存。
相关学习资料推荐,点击下方链接免费报名,先码住不迷路~】
音视频免费学习地址:
FFmpeg/WebRTC/RTMP/NDK/Android音视频流媒体高级开发
【免费分享】音视频学习资料包、大厂面试题、技术视频和学习路线图,资料包括(C/C++,Linux,FFmpeg webRTC rtmp hls rtsp ffplay srs 等等)有需要的可以点击788280672加群免费领取~
2. 视频采集
视频采集涉及到以下几点:
在 Android 系统下有两套 API 可以进行视频采集,它们是 Camera 和 Camera2 。Camera是以前老的 API ,从 Android 5.0(21) 之后就已经放弃了。和音频一样,也有高层和低层的 API,高层就是 Camera 和 MediaRecorder,可以快速实现编码,低层就是直接使用 Camera,然后将采集的数据进行滤镜、降噪等前处理,处理完成后由 MediaCodec 进行硬件编码,最后采用 MediaMuxer 生成最终的视频文件。
1. 音频处理
可以对音频的原始流做处理,如降噪、回音、以及各种 filter 效果。
2. 视频处理
现在抖音、美图秀秀等,在拍摄,视频处理方面,都提供了很多视频滤镜,而且还有各种贴纸、场景、人脸识别、特效、添加水印等。
其实对视频进行美颜和添加特效都是通过 OpenGL 进行处理的。Android 中有 GLSurfaceView,这个类似于 SurfaceView,不过可以利用 Renderer 对其进行渲染。通过 OpenGL 可以生成纹理,通过纹理的 Id 可以生成 SurfaceTexture,而 SurfaceTexture 可以交给 Camera,最后通过纹理就将摄像头预览画面和 OpenGL 建立了联系,从而可以通过 OpenGL 进行一系列的操作。
美颜的整个过程无非是根据 Camera 预览的纹理通过 OpenGL 中 FBO 技术生成一个新的纹理,然后在 Renderer 中的onDrawFrame() 使用新的纹理进行绘制。添加水印也就是先将一张图片转换为纹理,然后利用 OpenGL 进行绘制。添加动态挂件特效则比较复杂,先要根据当前的预览图片进行算法分析识别人脸部相应部位,然后在各个相应部位上绘制相应的图像,整个过程的实现有一定的难度,人脸识别技术目前有 OpenCV、Dlib、MTCNN 等。
1. 音频编码
Android 中利用 AudioRecord 可以录制声音,录制出来的声音是 PCM 声音,使用三个参数来表示声音,它们是:声道数、采样位数和采样频率。如果音频全部用 PCM 的格式进行传输,则占用带宽比较大,因此在传输之前需要对音频进行编码。
现在已经有一些广泛使用的声音格式,如:WAV、MIDI、MP3、WMA、AAC、Ogg 等等。相比于 PCM 格式而言,这些格式对声音数据进行了压缩处理,可以降低传输带宽。对音频进行编码也可以分为软编和硬编两种。软编则下载相应的编码库,写好相应的 JNI,然后传入数据进行编码。硬编则是使用 Android 自身提供的 MediaCodec。
硬编码和软编码的区别是:软编码可以在运行时确定、修改;而硬编码是不能够改变的。
2. 视频编码
在 Android 平台上实现视频的编码有两种实现方式:一种是软编,一种是硬编。软编的话,往往是依托于 cpu,利用 cpu 的计算能力去进行编码。比如我们可以下载 x264 编码库,写好相关的 JNI 接口,然后传入相应的图像数据。经过 x264 库的处理以后就将原始的图像转换成为 h264 格式的视频。
硬编则是采用 Android 自身提供的 MediaCodec,使用 MediaCodec 需要传入相应的数据,这些数据可以是 YUV 的图像信息,也可以是一个 Surface,一般推荐使用 Surface,这样的话效率更高。Surface 直接使用本地视频数据缓存,而没有映射或复制它们到 ByteBuffers;因此,这种方式会更加高效。在使用 Surface 的时候,通常不能直接访问原始视频数据,但是可以使用ImageReader 类来访问不可靠的解码后 (或原始) 的视频帧。这可能仍然比使用 ByteBuffers 更加高效,因为一些本地缓存可以被映射到 direct ByteBuffers。当使用 ByteBuffer 模式,可以利用 Image 类和 getInput/OutputImage(int) 方法来访问到原始视频数据帧。
下面我盗了一张图,画图实在太费时间:
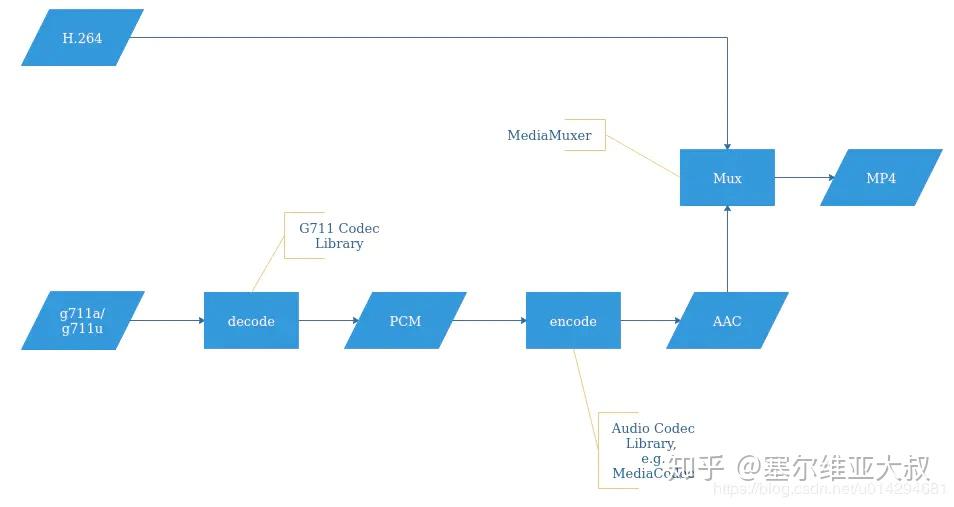
以合成 MP4 视频为例:
涉及到如下技术,我将从图像、音频、视频的顺序来罗列:
后面我将针对这些技术,总结下音视频相关的技术,有需要的可以点赞关注下。
原文
https://zhuanlan.zhihu.com/p/145102951
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号