掌握这些性能规则,让你成为Ruby on Rails开发的高手
发表时间: 2023-12-21 23:17
本文将带领你深入了解HTTP、Ruby on Rails和数据库的最佳实践,探讨何时应遵循规则,以及何时打破规则可能使你的代码脱颖而出。
原文链接:https://www.rorvswild.com/blog/2023/everyday-performance-rules-for-ruby-on-rails-developers
未经允许,禁止转载!
本文将带领你深入了解HTTP、Ruby on Rails和数据库的最佳实践,探讨何时应遵循规则,以及何时打破规则可能使你的代码脱颖而出。
这里我们讨论的是你可以放心遵循的性能规则。就像任何规则一样,你也可以打破它们。但你需要充分的理由。
在本文中,我们将讨论关于HTTP、Ruby和数据库层的最佳实践,这样大多数流量较大的应用程序都可以改进响应时间。一些最佳实践对于经验丰富的开发人员来说是显而易见的。如果你已经知道并使用了它们,那么你的Rails应用程序已经做得很好。
所有资源都应该来自CDN。它能减少访问者的延迟,减少发送到服务器的请求数。更重要的是,CDN可以提供比服务器更多的带宽。
CDN并不昂贵,而且它们的费率是渐进的。设置也非常简单:
除了仅在私有网络上运行的应用程序外,我们想不到任何不使用它们的充分理由。
一个资源被缓存就意味着客户端和服务器之间少了一个请求,因此加载时间更快。
显然,所有通过CDN传递的资源都应启用缓存。
Cache-Control头可以向浏览器和CDN提供指令。检查一下你的响应中是否有这样的头部 Cache-Control "max-age=86400, public"。max-age是以秒为单位的持续时间,在这个例子中即为24小时。你可以决定是否需要更激进的缓存。
对于私有资源,请使用 Cache-Control: private 头部关闭缓存。
Keep-alive连接可以重复利用。它们可以防止重新建立连接以及SSL协商,能减少由多个资源组成的所有页面的延迟时间。
默认情况下,Web服务器通常会启用它们。你可以验证以下头部的 Keep-Alive timeout=5, max=100。在此示例中,连接在5秒的不活动后关闭,并且可以重复使用100次。
尽量将任何繁重或会导致延迟的任务放在后台运行。发送电子邮件就是一个例子。
与HTTP请求的持续时间相比,这是一个相对较长的任务。此外,因为需要网络连接,此类任务的持续时间是不可预测的。另一方面,电子邮件并不一定要在HTTP请求期间发送。因此,从Rails控制器中使用 deliver_later 方法是一个好习惯。
除了减少响应时间外,这样做还不需要一个Web进程或线程来处理后续请求。因此,应用程序可以处理更大的数据量。此外,这种实现还不容易受到拒绝服务攻击的影响。
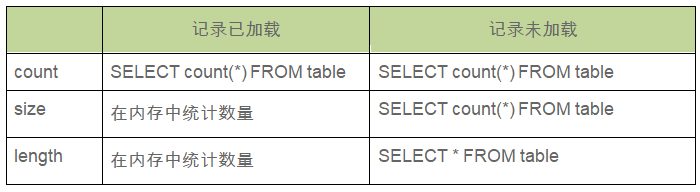
了解这三种方法之间的差异很重要,可以确保触发尽可能少或最优化的SQL查询。
count 方法始终触发 SELECT count(*) FROM table 查询。
length 方法确保关系已加载到内存中,在内存中统计数量。
size 方法适应于关系的加载。如果尚未加载,将触发查询;如果已加载,则在内存中统计数量。
以下是汇总表格:
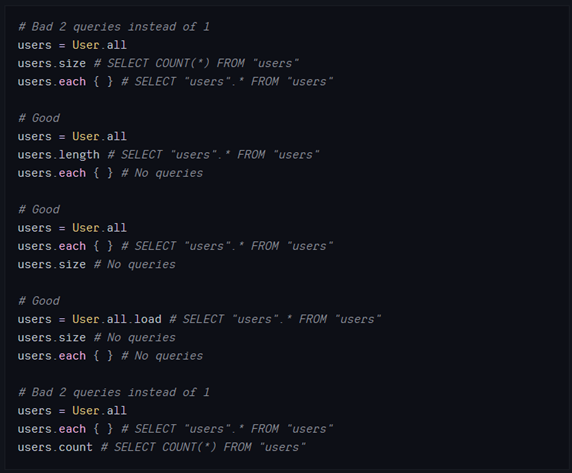
在计数和枚举时,一定要在加载关系之后再调用 size。这样做的目的是保证只需一个请求就能完成。
与 count、size 和 length一样,了解这些方法的微妙之处非常重要,可以触发尽可能少且最有效的查询。
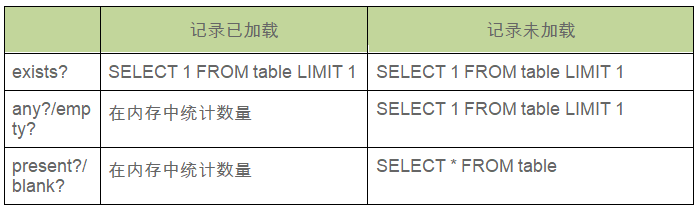
exists? 方法始终触发查询,但经过可优化,因为一旦找到一行就会停止。
present? 和 blank? 方法确保在检查它们在内存中的存在或不存在之前已经执行了查询。
any? 和 empty? 方法会自动检测关系是否已加载。
以下是汇总表格:
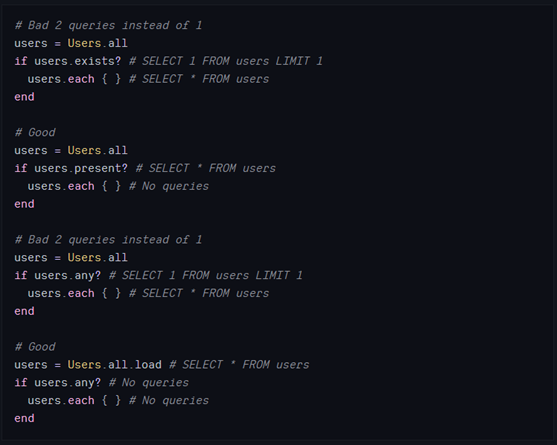
了解这些,在需要根据记录的存在情况调用时,就可以选择更好的方式。
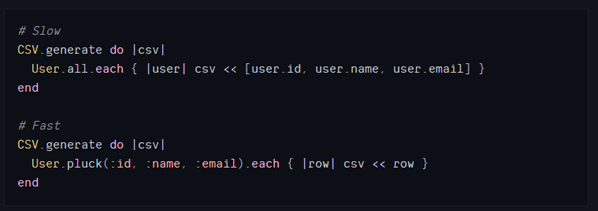
pluck可以获取SQL查询的原始结果,从而避免创建ActiveRecord实例。由于执行的操作较少,因此速度更快且更节省内存。另一方面,你无法再享有ActiveRecord模型的全部功能。因此,在不需要使用模型方法时使用它是个好主意。一个明显的例子就是导出数千行的CSV或文本文件。
在需要获取大量记录时,可以试着使用pluck。
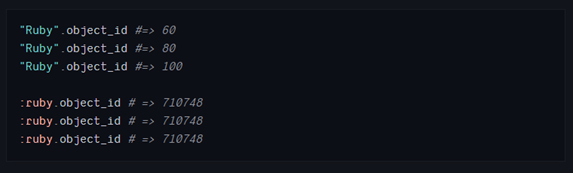
默认情况下,Ruby会为字符串字面量创建新的实例,但符号不会。
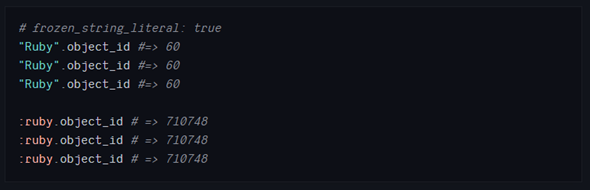
如上所示,相同的字符串被创建了三次,这是一种浪费,而符号会被重复利用。所以符号的效率更高。在文件开头添加注释可以告诉Ruby冻结并重用字符串字面量。
但是,这样做字符串就不能再被修改了。将一个冻结的字符串传递给不属于你的方法,可能会导致FrozenError异常。你需要明确地复制一次。
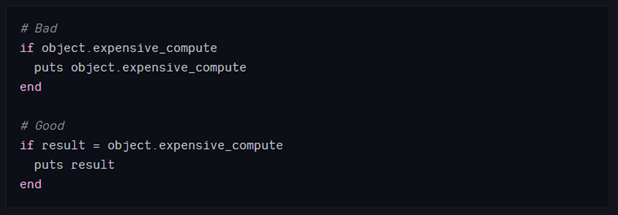
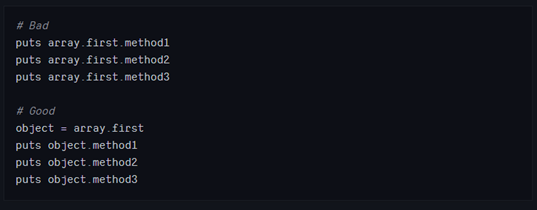
虽然这一条很显然,但我们经常会读到下面这种代码:
即使是非常简单的方法,重复也是浪费:
这样并不会让代码更复杂,有时候还会变得简单一些。
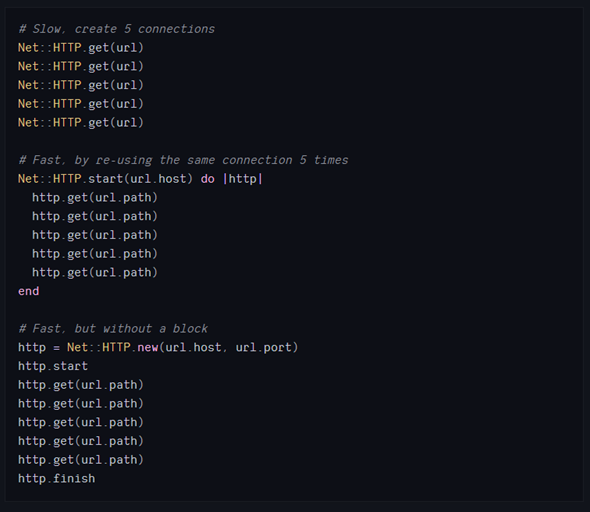
前面介绍过,使用同一个HTTP连接执行多个请求会更有效率。每次都可以节省下建立连接和SSL协商的时间。
最简单的方法就是将一个块中的所有请求都传递给Net::HTTP.start,这样就不会忘记关闭连接。如果无法将一个块中的请求分组到一起,也可以手动start和end。
默认情况下,大多数数据库并不会根据使用情况和服务器的能力进行最优配置。如果自行管理数据库,微调至关重要的。如果数据库由第三方管理,那么检查是否已正确配置也同样重要。
幸运的是,有一些可用的工具可以帮助你实现这一目标。对于PostgreSQL,我们推荐使用PGTune。对于MySQL,有MySQLTunner,但我们还没有使用它的经验。
只需告知内存和CPU的数量,PGTune就可以为服务器提供最佳设置。非常容易。
然后,你只需将设置复制到配置文件中。
我们喜欢将这些设置存储在专用文件中,例如/etc/postgresql/16/main/conf.d/pgtune.conf。如果将来需要更改,我们只需替换整个文件。这样更容易维护。
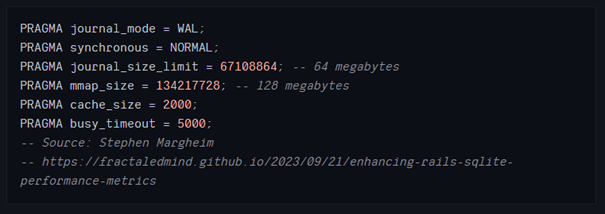
对于SQLite,在Rails 7.1以后,默认设置很好。如果不想使用默认设置,可以自行设置这些参数:
如果一个操作可以由数据库执行,也可以由代码执行,就让数据库来负责吧。由于操作是在数据所在的位置进行的,所以速度更快。这意味着会消耗更少的带宽,延迟也更低。而且,你的代码不太可能比数据库写得还好。
外键出现在 where 子句中的几率非常高。如果不是这样,那么可能这个外键根本没什么用。因此,毫无疑问,在添加外键时必须创建索引。
索引的缺点是导致表的写入速度减慢。但很多时候,读取的次数远远超过写入的次数。另一方面,如果某个索引从未被使用,那么就应该被删除。这个信息可以在 PostgreSQL 的内部表中找到。这个问题解释起来比较麻烦,但幸运的是,诸如PgHero 等工具使这变得非常容易。
因此,默认要对每个外键添加索引,然后删除那些从未被使用的索引。
数据库索引是一种B树结构。当数据具有较高的基数时,非常高效。然而,当一个列允许空值时,通常会成为最冗余的值。索引效率较低,占用更多的空间。除非 是一个不经常重复的值,否则对其进行索引只有坏处。
你可以在创建索引时使用 WHERE 子句排除。
或者用SQL:
原因与前一段相同。B-tree 索引在基数高时效果最好。因此,布尔类型列上的索引会非常差。因此,请勿为布尔类型添加索引。
与其他类型一样,如果重复性非常高的值,而从业务角度来看这些值并不重要,那么将它们从索引中排除可能是个不错的主意。特别是默认值:
或者用SQL:
这些规则还远远不够。欢迎您在下方留言,分享更多的规则。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12













 鲁公网安备37020202000738号
鲁公网安备37020202000738号