打造高性能、可扩展的Node.js应用:一步步指南
发表时间: 2018-10-23 20:27

作者|Virgafox
译者|姚佳灵
出处丨前端之巅
说明:本文根据原文作者的系列文章编辑而成,略有删改。
在这篇文章中,我们将介绍关于开发 Node.js web 应用程序的一些最佳实践,重点关注效率和性能,以便用更少的资源获得最佳结果。
提高 web 应用程序吞吐量的一种方法是对其进行扩展,多次实例化其以平衡在多个实例之间的传入连接,接来下我们要介绍的是如何在多个内核上或多台机器上对 Node.js 应用程序进行水平扩展。
在强制性规则中,有一些好的实践可以用来解决这些问题,像拆分 API 和工作进程、采用优先级队列、管理像 cron 进程这样的周期性作业,在向上扩展到 N 个进程 / 机器时,这不需要运行 N 次。
水平扩展是复制应用程序实例以管理大量传入连接。 此操作可以在单个多内核机器上执行,也可以在不同机器上执行。
垂直扩展是提高单机性能,它不涉及代码方面的特定工作。
在同一台机器上的多进程
提高应用程序吞吐量的一种常用方法是为机器的每个内核生成一个进程。 通过这种方式,Node.js 中请求的已经有效的“并发”管理(请参见“事件驱动,非阻塞 I / O”)可以相乘和并行化。
产生大于内核的数量的大量进程可能并不好,因为在较低级别,操作系统可能会平衡这些进程之间的 CPU 时间。
扩展单机有不同的策略,但常见的概念是,在同一端口上运行多个进程,并使用某种内部负载平衡来分配所有进程 / 核上的传入连接。

下面所描述的策略是标准的 Node.js 集群模式以及自动的,更高级别的 PM2 集群功能。
原生集群模式
原生 Node.js 群集模块是在单机上扩展 Node 应用程序的基本方法(请参阅
https://Node.js.org/api/cluster.html)。 你的进程的一个实例(称为“master”)是负责生成其他子进程(称为“worker”)的实例,每个进程对应一个运行你的应用程序的核。 传入连接按照循环策略分发到所有 worker 进程,从而在同一端口上公开服务。
该方法的主要缺点是必须在代码内部管理 master 进程和 worker 进程之间的差异,通常使用经典的 if-else 块,不能够轻易地修改进动态进程数。
下面的例子来自官方文档:
const cluster = require(‘cluster’);const http = require(‘http’);const numCPUs = require(‘os’).cpus().length;if (cluster.isMaster) { console.log(`Master ${process.pid} is running`); // Fork workers. for (let i = 0; i < numCPUs; i++) { cluster.fork(); } cluster.on(‘exit’, (worker, code, signal) => { console.log(`worker ${worker.process.pid} died`); });} else { // Workers can share any TCP connection // In this case it is an HTTP server http.createServer((req, res) => { res.writeHead(200); res.end(‘hello world\n’); }).listen(8000); console.log(`Worker ${process.pid} started`);}PM2 集群模式
如果你在使用 PM2 作为你的流程管理器(我也建议你这么做),那么有一个神奇的群集功能可以让你跨所有内核扩展流程,而无需担心集群模块。 PM2 守护程序将承担“master”进程的角色,它将生成你的应用程序的 N 个进程作为 worker 进程, 并进行循环平衡。
通过这个方法,只需要按你为单内核用途一样地编写你的应用程序(我们稍后再提其中的一些注意事项),而 PM2 将关注多内核部分。
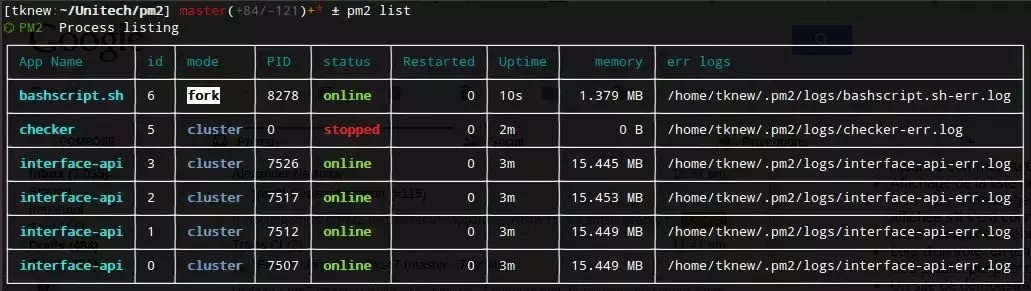
在集群模式下启动你的应用程序后,你可以使用“pm2 scale”调整动态实例数,并执行“0-second-downtime”重新加载,进程重新串联,以便始终至少有一个在线进程。
在生产中运行节点时,如果你的进程像很多其他你应该考虑的有用的东西一样崩溃了,那么 PM2 作为进程管理器将负责重新启动你的进程。
如果你需要进一步扩展,那么你也许需要部署更多的机器。
具有网络负载均衡的多台机器
跨多台机器进行扩展的主要概念类似于在多内核上进行扩展,有多台机器,每台机器运行一个或多个进程,以及用于将流量重定向到每台机器的均衡器。
一旦请求被发送到特定的节点,刚才所提到的内部均衡器发送该流量到特定的进程。
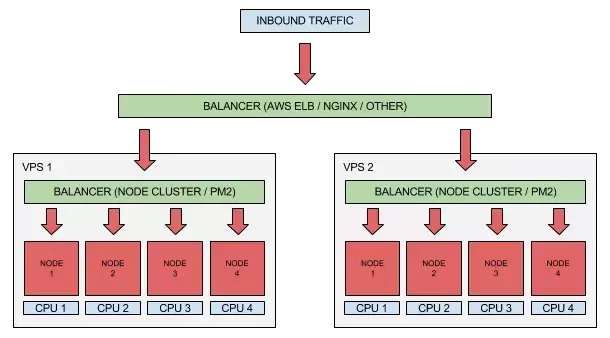
可以以不同方式部署网络平衡器。 如果使用 AWS 来配置你的基础架构,那么一个不错的选择是使用像 ELB(Elastic Load Balancer,弹性负载均衡器)这样的托管负载均衡器,因为它支持自动扩展等有用功能,并且易于设置。
但是如果你想按传统的方式来做,你可以自己部署一台机器并用 NGINX 设置一个均衡器。 指向上游的反向代理的配置对于这个任务来说非常简单。 下面是配置示例:
http { upstream myapp1 { server srv1.example.com; server srv2.example.com; server srv3.example.com; } server { listen 80; location / { proxy_pass http://myapp1; } }}通过这种方式,负载均衡器将是你的应用程序暴露给外部世界的唯一入口点。 如果担心它成为基础架构的单点故障,可以部署多个指向相同服务器的负载均衡器。
为了在均衡器之间分配流量(每个均衡器都有自己的 IP 地址),可以向主域添加多个 DNS“A”记录,从而 DNS 解析器将在你的均衡器之间分配流量,每次都解析为不同的 IP 地址。通过这种方式,还可以在负载均衡器上实现冗余。
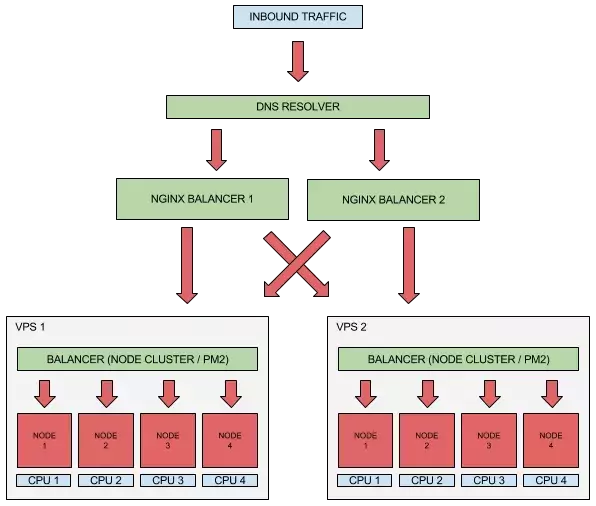
我们在这里看到的是如何在不同级别扩展 Node.js 应用程序,以便从你的基础架构(从单节点到多节点和多均衡器)获得尽可能高的性能,但要小心:如果想在多进程环境中使用你的应用程序,必须做好准备,否则会遇到一些问题和不期望的行为。
在向上扩展你的进程时,为了避免出现不期望的行为,现在我们来谈谈必须考虑到的一些方面。
从 DB 中分离应用程序实例
首先不是代码问题,而是你的基础结构。
如果希望你的应用程序能够跨不同主机进行扩展,则必须把你的数据库部署在独立的机器上,以便可以根据需要自由复制应用程序机器。
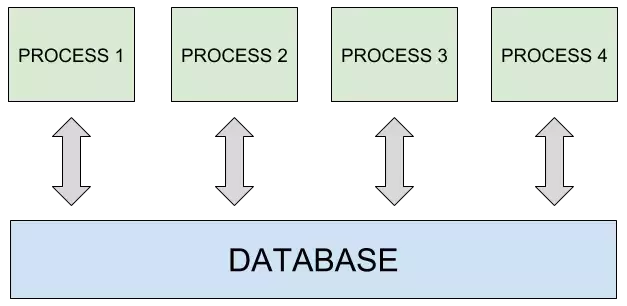
在同一台机器上部署用于开发目的的应用程序和数据库可能很便宜,但绝对不建议用于生产环境,其中的应用程序和数据库必须能够独立扩展。 这同样适用于像 Redis 这样的内存数据库。
无状态
如果生成你的应用程序的多个实例,则每个进程都有自己的内存空间。 这意味着即使在一台机器上运行,当你在全局变量中存储某些值,或者更常见的是在内存中存储会话时,如果均衡器在下一个请求期间将您重定向到另一个进程,那么你将无法在那里找到它。
这适用于会话数据和内部值,如任何类型的应用程序范围的设置。对于可在运行时更改的设置或配置,解决方案是将它们存储在外部数据库(存储或内存中)上,以使所有进程都可以访问它们。
使用 JWT 进行无状态身份验证
身份验证是开发无状态应用程序时要考虑的首要主题之一。 如果将会话存储在内存中,它们将作用于这单个进程。
为了正常工作,应该将网络负载均衡器配置为,始终将同一用户重定向到同一台机器,并将本地用户重定向到同一用户始终重定向到同一进程(粘性会话)。
解决此问题的一个简单方法是将会话的存储策略设置为任何形式的持久性,例如,将它们存储在 DB 而不是 RAM 中。 但是,如果你的应用程序检查每个请求的会话数据,那么每次 API 调用都会进行磁盘读写操作(I / O),从性能的角度来看,这绝对不是好事。
更好,更快的解决方案(如果你的身份验证框架支持)是将会话存储在像 Redis 这样的内存数据库中。 Redis 实例通常位于应用程序实例外部,例如 DB 实例,但在内存中工作会使其更快。 无论如何,在 RAM 中存储会话会在并发会话数增加时需要更多内存。
如果想采用更有效的无状态身份验证方法,可以看看 JSON Web Tokens。
JWT 背后的想法很简单:当用户登录时,服务器生成一个令牌,该令牌本质上是包含有效负载的 JSON 对象的 base64 编码,加上签名获得的哈希,该负载具有服务器拥有的密钥。 有效负载可以包含用于对用户进行身份验证和授权的数据,例如 userID 及其关联的 ACL 角色。 令牌被发送回客户端并由其用于验证每个 API 请求。
当服务器处理传入请求时,它会获取令牌的有效负载并使用其密钥重新创建签名。 如果两个签名匹配,则可以认为有效载荷有效并且不被改变,并且可以识别用户。
重要的是要记住 JWT 不提供任何形式的加密。 有效负载仅用 base64 编码,并以明文形式发送,因此如果需要隐藏内容,则必须使用 SSL。
被 jwt.io 借用的以下模式恢复了身份验证过程:

在认证过程中,服务器不需要访问存储在某处的会话数据,因此每个请求都可以由非常有效的方式由不同的进程或机器处理。 RAM 中不保存数据,也不需要执行存储 I / O,因此在向上扩展时这种方法非常有用。
S3 上的存储
使用多台机器时,无法将用户生成的资产直接保存在文件系统上,因为这些文件只能由该服务器本地的进程访问。 解决方案是,将所有内容存储在外部服务上,可以存储在像 Amazon S3 这样的专用服务上,并在你的数据库中仅保存指向该资源的绝对 URL。
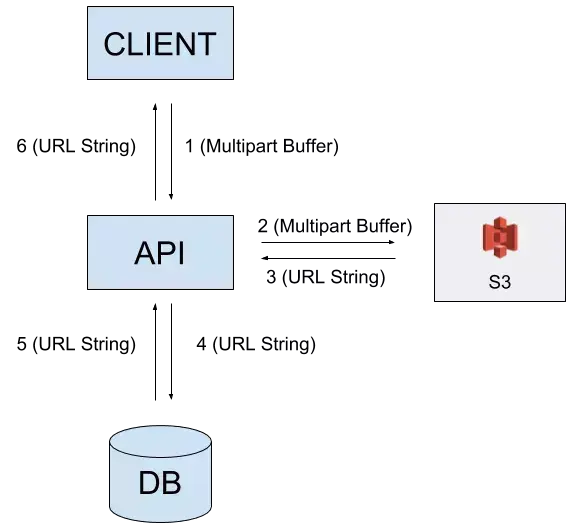
然后,每个进程 / 机器都可以以相同的方式访问该资源。
使用 Node.js 的官方 AWS sdk 非常简单,可以轻松地将服务集成到你的应用程序中。 S3 非常便宜并且针对此目的进行了优化。即使你的应用程序不是多进程的,它也是一个不错的选择。
正确配置 WebSockets
如果你的应用程序使用 WebSockets 进行客户端之间或客户端与服务器之间的实时交互,则需要链接后端实例,以便在连接到不同节点的客户端之间正确传播广播消息或消息。
Socket.io 库为此提供了一个特殊的适配器,称为 socket.io-redis,它允许你使用 Redis pub-sub 功能链接服务器实例。
为了使用多节点 socket.io 环境,还需要强制协议为“websockets”,因为长轮询(long-polling)需要粘性会话才能工作。
以上这些对于单节点环境来说也是好的实例。
接下来,我们将介绍一些可以进一步提高效率和性能的其他实践。
Web 和 worker 进程
你可能知道,Node.js 实际上是单线程的,因此该进程的单个实例一次只能执行一个操作。 在 Web 应用程序的生命周期中,执行许多不同的任务:管理 API 调用,读取 / 写入 DB,与外部网络服务通信,执行某种不可避免的 CPU 密集型工作等。
虽然你使用异步编程,但将所有这些操作委派给响应 API 调用的同一进程可能是一种非常低效的方法。
一种常见的模式是基于两种不同类型的进程之间的职责分离,这两种类型的进程组成了你的应用程序,通常是 Web 进程和 worker 进程。
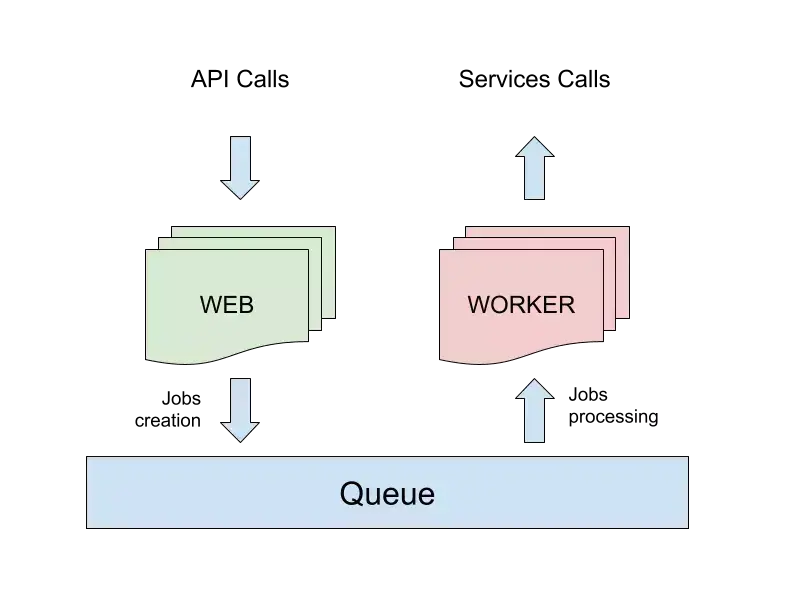
Web 进程主要用于管理传入的网络呼叫,并尽快发送它们。 每当需要执行非阻塞任务时,例如发送电子邮件 / 通知、编写日志、执行触发操作,其结果是不需要响应 API 调用,web 进程将操作委派给 worker 进程。
Web 和 worker 进程之间的通信可以用不同的方式实现。 一种常见且有效的解决方案是优先级队列,如下一段所描述的 Kue 中实现的优先级队列。
这种方法的一大胜利是,可以在相同或不同的机器上独立扩展 web 和 worker 进程。
例如,如果你的应用程序是高流量应用程序,几乎没有生成的副作用,那么可以部署比 worker 进程更多的 web 进程,而如果很少有网络请求为 worker 进程生成大量作业,则可以重新分发相应的资源。
Kue
为了使 web 和 worker 进程相互通信,队列是一种灵活的方法,可以让你不必担心进程间通信。
Kue 是基于 Redis 的 Node.js 的通用队列库,允许你以完全相同的方式放入在相同或不同机器上生成的通信进程。
任何类型的进程都可以创建作业并将其放入队列,然后将 worker 进程配置为选择这些作业并执行它们。 可以为每项工作提供许多选项,如优先级、TTL、延迟等。
你生成的 worker 进程越多,执行这些作业所需的并行吞吐量就越多。
Cron
应用程序通常需要定期执行某些任务。 通常,这种操作通过操作系统级别的 cron 作业进行管理,从你的应用程序外部调用单个脚本。
在新机器上部署你的应用程序时,用此方法就需要额外的工作,如果要自动部署,这会使进程感到不自在。
实现相同结果的更自在的方法是使用 NPM 上的可用 cron 模块。 它允许你在 Node.js 代码中定义 cron 作业,使其独立于 OS 配置。
根据上面描述的 web / worker 模式,worker 进程可以创建 cron,它调用一个函数,定期将新作业放入队列。
使用队列使其更加干净,并可以利用 kue 提供的所有功能,如优先级,重试等。
当你有多个 worker 进程时会出现问题,因为 cron 函数会同时唤醒每个进程上的应用程序,并将多次执行的同一作业放入队列副本中。
为了解决这个问题,有必要确定将执行 cron 操作的单个 worker 进程。
领导者选举(Leader election)和 cron-cluster(cron 集群)
这种问题被称为“领导者选举”,对于这个特定的场景,有一个 NPM 包为我们做了一个叫做 cron-cluster 的技巧。
它暴露了为 cron 模块提供动力的相同 API,但在设置过程中,它需要一个 redis 连接,用于与其他进程通信并执行领导者选举算法。
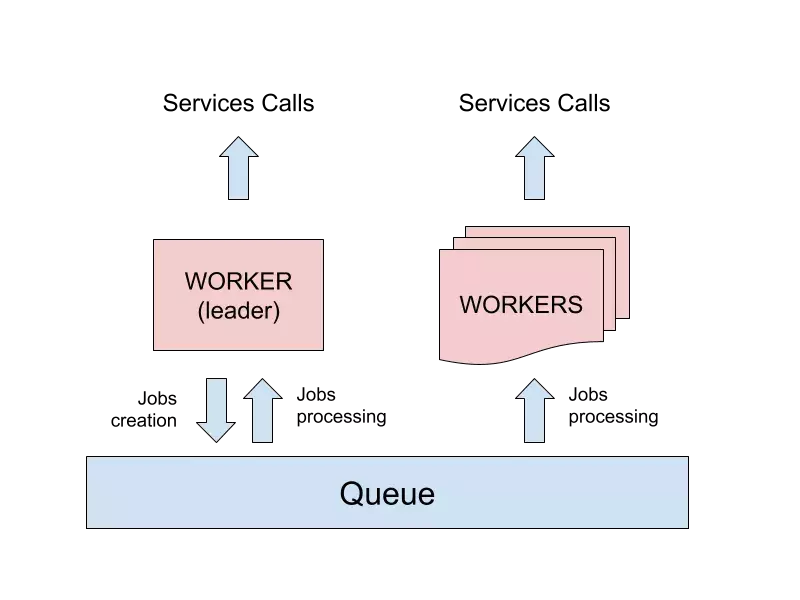
使用 redis 作为单一事实来源,所有进程都会同意谁将执行 cron,并且只有一份作业副本将被放入队列中。 之后,所有 worker 进程都将有资格像往常一样执行作业。
缓存 API 调用
服务器端缓存是提高 API 调用的性能和反应性的常用方法,但它是一个非常广泛的主题,有很多可能的实现。
在像我们所描述的分布式环境中,使用 redis 来存储缓存的值可能是使所有节点表现相同的最佳方法。
缓存需要考虑的最困难的方面是失效。 快速而简陋的解决方案只考虑时间,因此缓存中的值在固定的 TTL 之后刷新,缺点是不得不等待下一次刷新以查看响应中的更新。
如果你有更多的时间,最好在应用程序级别实现失效,在 DB 上值更改时手动刷新 redis 缓存上的记录。
我们在本文中介绍了一些有关扩展和性能的一些主题。 文中提供的建议可以作为指导,可以根据你的项目的特定需求进行定制。
英文原文:
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号