OpenAI Five 实战体验:技术强大却存在致命缺陷!
发表时间: 2019-04-24 09:54
在 4 月 14 日,OpenAI Five 代表人工智能拿下了与人类的竞争史上又一个里程碑:以 2 比 0 的绝对优势击败了 Dota 2 TI8 冠军 OG 战队。其中甚至以碾压之势拿下第二盘,仅用 22 分钟就“打卡下班”。比赛 4 天后,OpenAI 宣布将开放为期 3 天的 Arena 竞技场模式,邀请所有 Dota 2 玩家挑战OpenAI Five。
这场“人机大战”的竞技场于北京时间 4 月 22 日正式落幕。AI 在 Dota 2 竞技场上获得的最终成绩为 7215 : 42,胜率高达 99.4%,足以看出 OG 的败北并不是偶然事件。

图 | OpenAI Five 的战绩(来源:OpenAI Arena)
相比较 8 个多月前 TI8 上的表现,我们能明显看到 AI 的进步。比赛中有很多亮眼和极限操作,比如死血冰女果断开大反杀两人,家常便饭一样的吹风/BKB 躲先手,走走停停的暗影护符卡视野等等,顶级人类玩家都未必能保证 100% 做到。
除了惊讶于 AI 的进步速度,Dota 社区有很多声音认为 OG 只是“随便玩玩,没认真打”,而 OpenAI 随后推出的竞技场模式,就像是一封 AI 递给人类的战书,上书四个大字:You Can You Up。
笔者作为 Dota 老玩家,必然不能错过这千载难逢的机会,但由于找不到足够的人手对抗 AI,只能自己带 4 个 AI 娱乐一下。在连输两局之后基本摸清了 AI 队友的脾气(从不听话)和制裁 AI 的套路(隐身等于无敌),通过疯狂带线和毒瘤发育连赢三场“膀胱局”(指游戏时间特别长的对局),总算是勉强保住了 5000 分的尊严。

(来源:OpenAI)
竞技场有两种模式,一种是五名人类玩家组队对抗 AI,另一种是人类 + AI 的合作模式。
目前竞技场已经关闭,OpenAI 还未放出详细的比赛录像和结果解析,不过根据排行榜数据和社区反馈,我们可以挖掘出很多关于 OpenAI Five 的特征。
值得注意的是,AI 的 99% 胜率看似恐怖,其实里面有很多“水分”,比如组队娱乐的玩家。最有分析价值的还是人类获胜的比赛。
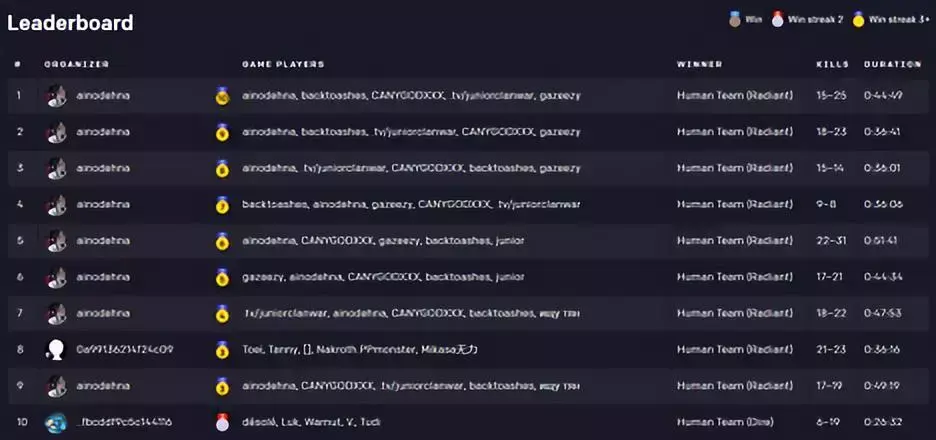
图 | 竞技场排行榜前十(来源:OpenAI Arena)
排行榜显示,在人类获胜的 42 场比赛中,有一些来自于天梯大神队伍,还有一些知名 Dota 2 主播的队伍,比如 Twitch 平台的 Waga,也有中国玩家熟悉的 OB 五人组和 Zard/天使焦/Fade/战术大师 Rubick 等人。
在这些队伍中,有一支队长是“ainodehna”的队伍一枝独秀,取得了对抗 AI 的十连胜。相比之下,排名第二的队伍仅有三连胜。
Steam 和 DotaBuff 的资料显示,队伍成员应该来自于俄罗斯或独联体地区,其中的 ainodehna 和 junior 单排天梯分都在 7000 以上,获得了冠绝一世奖章,欧服排名分别是 294 和 227。而且他们还有电竞选手资料,很可能曾经加入过职业或准职业队伍。

图 | 队伍中单 junior 的 DotaBuff 资料(来源:DotaBuff)
即便如此,想要获得十连胜也绝对不是一件容易的事。哪怕是两支水平相近的人类队伍对战,也很少有这样的连胜,他们所用的技巧因此引发了热议。
由于这些比赛会在 Twitch 上直播,也会有人将人类胜利的视频放到 YouTube 上,所以很快就有热心网友在 Reddit 论坛上整理出了“如何打败 AI”的帖子。
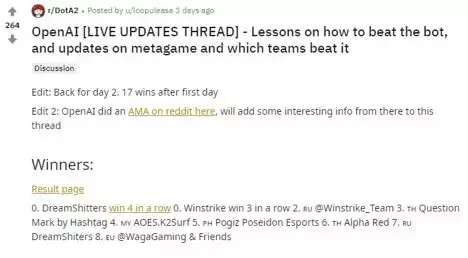
图 | 网友总结如何打败 AI 的帖子(来源:Reddit)
最开始的 1000 局比赛里,人类队伍只赢了 3 局。但随着时间的推移,OpenAI 的弱点逐渐暴露。就像所有游戏的 AI 一样,如果你足够强,击败 AI 总有套路可寻。
AI 的 5V5 团战和遭遇战都很强,但却不擅长应对带线和分推战术,不擅长插眼和反眼,对信使的保护也很糟糕。它们在逆风局的时候大多窝在家里「打麻将」,不爱主动出击,甚至还会顶着偷塔保护强拆兵营和基地,直到自己的高地建筑几乎被拆光了才回家。
最致命的是,AI 非常不擅长应对隐身单位,隐身等于无敌。

图 | 面对 AI,隐身等于无敌
于是就有了三辅助牵扯 AI 五人,两大哥隐刀 BKB 拆家这样的骚套路。还有网友表示,隐刺出了辉耀之后可以一直灼烧 AI 英雄,可是 AI 看不见隐刺,也不知道自己掉血的原因是辉耀隐刺在附近——人类玩家可以瞬间理解这种情况。
由此我们能够看出,获得了上千场胜利的 AI 似乎并未“学会”如何打 Dota,很多常识人类通过十几局游戏就能快速掌握,但却是AI学不明白的技巧。
AI 的强大是建立在灵活走位、反应迅速、无缝衔接技能和精准控制血量之上的“变态”微操作,它能够依靠这些打赢遭遇战和团战,但是面对人类故意设下的圈套或者隐身单位,它仍然缺乏合理的推理能力。

图 | 人类强拆兵营,AI 却只顾中路打架
换言之,在已经大规模减少复杂度的游戏中,AI 仍然难以透过复杂的表面看到本质,比如 AI 自己控制的英雄在不断掉血,周围却没有看到敌方英雄(表面),为什么会这样(本质)?下一步该怎么办?
打个比方,OpenAI Five 就像一个严重偏科的学生,有的科目能得 120 分,有的却只能得 20 分。获得连胜的队伍正是扬长避短,利用明显的“木桶效应”不断制裁 AI,颇有几分田忌赛马的感觉。
OpenAI 自己也认为,大规模的竞技场测试会回答一个重要的研究问题:OpenAI Five 在多大程度上可以被人类找到漏洞,进而被反复击败。

我们可以将这一问题扩大到整个深度学习领域,甚至是通用人工智能技术(AGI)。
简单来说,AGI 就是和人类智能水平相似的 AI 系统,能够进行感知、推理、学习、决策、行动和交流等任务,不必局限于某个应用领域,可以创造灵活的通用解决方案,能在很多领域替代人类。
按照 OpenAI 的愿景,今天陪人类玩游戏的 AI 系统,明天很可能拓展到自动化和机器人领域,有望成为AGI 的雏形。
OpenAI 本指望通过竞技场为 AI 积累通用经验,但如今可能会面临一个数据较少的严峻考验:人类只赢了 42 场,这对于动辄分析数万场训练数据的 AI 来说,实在是九牛一毛,它真的可以从中学到什么吗?

图 | OpenAI 每天的训练量相当于玩 180 年 Dota 游戏
假设 OpenAI Five 想要变成 AGI 的雏形,那么它的学习能力就应该媲美人类。
人类有什么样的学习能力呢?从竞技场的例子可以看出,AI 一开始连赢了 500 场,但一支人类顶尖队伍在尝试 2 次之后就获得了胜利,之后还获得了连胜。
随着人类不断挖掘 AI 的弱点,只用了 1 天就摸清了 AI 的套路,做到了可以稳定击败 AI,最后取得十连胜(这支队伍在竞技场结束之后还在直播打 OpenAI,继续保持了连胜记录)。
也就是说,人类整体只用了几百场游戏、顶尖个体甚至只用了 2 场游戏,就“学会了”如何反复击败训练了 4.5 万年的 AI,两者的学习效率差距显而易见。
当然,在比赛的过程中,OpenAI 自身是锁定的,不会学习,也不会改变,给了人类找到套路的机会。但这并不能改变它需要的训练数据远超人类的事实。
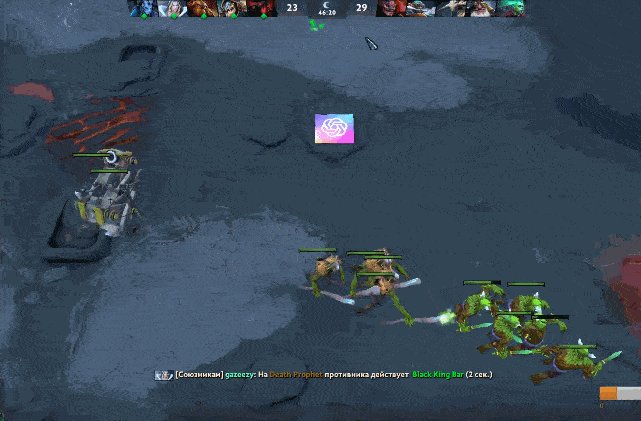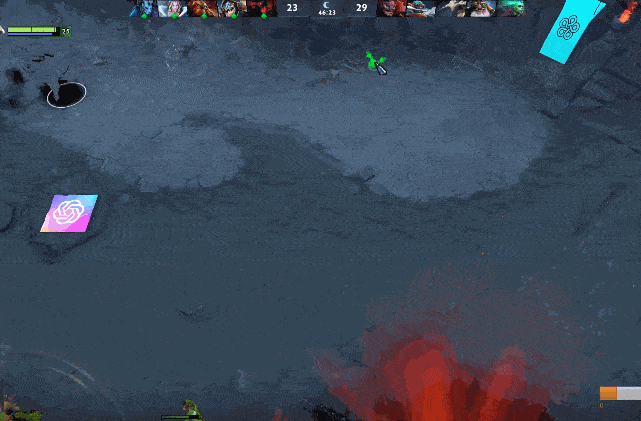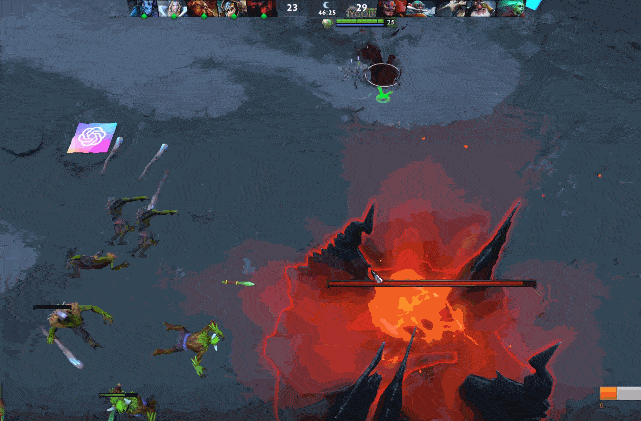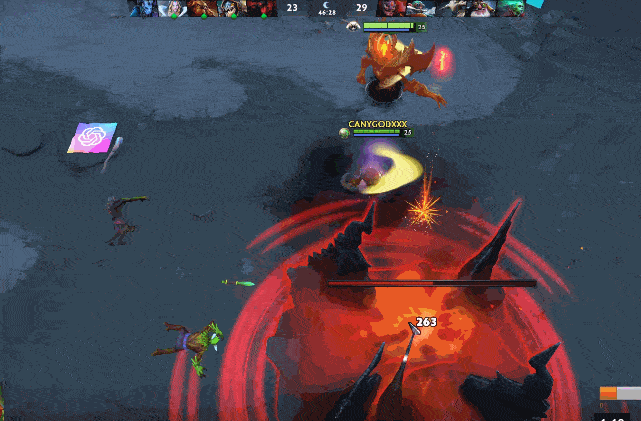
图 | 双大哥隐刀 BKB 拆家
现代机器学习领域最热门的莫过于深度学习(AlphaGo)和强化学习(OpenAI Five)等人工神经网络。当 AI 系统一次次在围棋、电子游戏、图像识别、自然语言处理等多个应用领域追上、甚至超越人类后,很多人都在使用这些技术探索可以应用于多个领域的 AGI 的可能性。
但是,这些技术都依赖于海量数据和计算资源,比如训练 AI 识别医疗影像,进行中英翻译或听懂你说的话,均需要数十万份训练数据才能训练出表现出色的模型。但它们也只能在特定场景下才能使用。因此,相对于被称之为“强人工智能”的 AGI,这类 AI 系统普遍被称为“弱”或“窄人工智能”(Narrow AI)。
如果想再更进一步,进军 AGI,首先要攻克的就是在冷门应用场景下,训练数据稀少的问题。

(来源:Pixabay)
目前已有类似的努力,比如“仅需”数千个数据就能生效的生成模型(Generative Models)、数据需求进一步降低至数百的迁移学习(Transfer Learning),可以从零开始的单样本学习(one-shot learning)和自我对战 (Self-Play),这都是近几年的新兴概念。
生成模型的基础思想为“训练算法来生成自己的训练数据”,通过生成一个能够抽取出基类数据的模型,根据少量的训练数据,凭空“想”出大量的训练数据。对于图像来说,迄今最成功的生成模型是生成对抗网络(GAN)。正如生成对抗网络的发明人 Ian Goodfellow 所说的,生成模型给机器带来了“想象力”。
但是,有些应用场景连训练生成模型的数据都凑不够。因此,由人类儿童学习方式启发的迁移学习诞生了。
迁移学习是深度学习领域为了解决其海量数据需求而开发的一种手段。其基础在于先用一个有着大量训练数据的场景训练模型。完成训练后,该模型的特征将适用于所有跟这个应用场景相关或类似的具体场景。
换句话说,这个模型“学会”的特征可以被“迁移”到另外一个应用场景。比如用具有 1400 万张照片的 ImageNet 去训练一个图像识别模型(通用特征),然后再训练这个模型去具体地识别医疗成像中的肿瘤(具体应用)。
但迁移学习的基础也限制了它的应用场景:如果一个任务的所有相关任务都缺少数据(比如打 Dota 2),就无法训练迁移学习所需的“通用模型”(生成模型因此也不适用)。这也是将深度学习扩散到新的(少数据)应用领域时所面临的最大挑战。
在计算机视觉任务领域,为了减少对训练数据的依赖,研究人员正在努力研发单样本学习。单样本,指的是借助元学习(Meta Learning)技术的支持,只用展示一张图片或者一段演示,就可以让 AI 认识某个物品,学会某种技能,从而具备一种“触类旁通”的能力。
而在其他从零开始的应用场景中,AI 可以根据规则在自我对战中进行学习,这也正是 OpenAI Five 和 DeepMind 的 AlphaGo Zero 所使用的技术。自我对战最大的优势在于可以“从零开始”,在大量的对战中进行优化,用大量的计算力和训练时间来掌握一个技能。
无论哪种方法,我们都能看出类似的趋势:减少数据需求。但是,从 OpenAI Five 竞技场的表现来看,虽然现有的技术手段能够有效地减少对数据的依赖,却依然无法有效地提高模型训练的速度。
所幸,提升学习速度也是当下机器学习领域的一个大热门。可以预见的是,从 AI 到 AGI,将是一个漫长的发展历程,而只借助少量数据就能迅速学习新技能的能力,将是发展过程中的最大难题之一。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号