51风控系统的秘密武器:PostgreSQL
发表时间: 2018-08-17 11:14
【IT168 专稿】本文根据张泽鹏老师在2018年5月12日【第九届中国数据库技术大会】现场演讲内容整理而成。
讲师简介:

张泽鹏,51信用卡架构师。前道富信息科技(浙江)有限公司技术专家,参与多个金融相关的系统开发,后自主创业。2015年加入51信用卡管家担任架构师,负责风控、信审、数据支持等互金相关系统的设计与开发。从2012年开始使用PostgreSQL,拥有多年PG相关的开发和实践经验。
摘要
51信用卡管家作为互联网金融领域的独角兽企业,在风险控制上积累了多年经验。PostgreSQL丰富的特性给风控的分析与开发工作带来极大的便利,并支撑了51实时的风控业务。本文将介绍PostgreSQL在51风控系统中的应用,并结合4个场景介绍实践经验,以及各自方案的演进过程。
正文:
风控业务概述
风控,顾名思义,就是风险控制。风控业务人员需要在诸多样本里挑出有风险的样本,并把它们排除掉。就像漫画中展示的一样:找出那个不一样的家伙!

所以,风控工作很像在玩“大家来找茬”游戏:把左边的图看成是正样本,右边的图看成是负样本,负样本会尽可能伪装得与正样本很像。风控业务人员利用他们的火眼金睛,提炼出特征与规则,辨别正负样本。

以此图为例,风控业务人员可能会注意到“狐狸耳朵数量”这个特征,并提出“正常狐狸有两只耳朵”的规则。未来再遇到狐狸图像,就能用这条规则来快速辨别真伪。
类比到金融风控领域,风控业务人员也会提出类似的规则。例如:符合以下条件的申请予以通过,否则拒绝:
男性客户:年龄在22到55岁之间;
女性客户:年龄在18到65岁之间。
风控系统概述
有了风控规则,就可以线下联系申贷客户收集信息,并人工判断是否符合规则。但纯人工的方式效率低下、容易出错,随着业务规模的增长,显然需要一套自动化的风控系统来代替人工方式。如果说风控规则决定了能不能做互金这个生意,那风控系统就决定了生意能做多大!
为实现上述风控规则,需要获得客户的“年龄”与“性别”两个特征变量;而“年龄”能由“出生年份”计算得出;“出生年份”与“性别”又能从“身份证号”中获得。这意味着,只要提供一个“身份证号”作为输入,就能依次获得“出生年份”、“性别”,进而得到“年龄”,最后得到风控规则的结果。
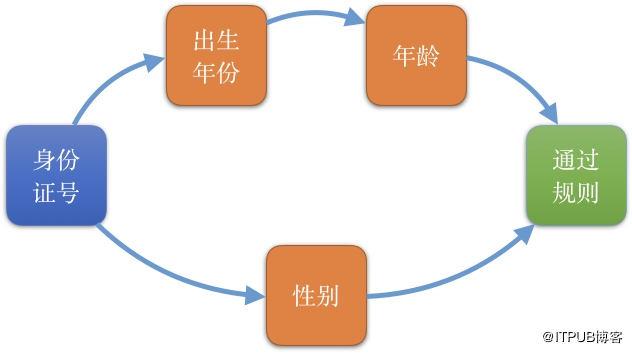
举个例子,有一个身份证号:330106199011110119(此为虚拟身份证号,仅供本文示例用途);按照18位身份证号的规则,首先提取第7到10位的出生年份“1990”;接着提取倒数第二位“1”,是一个奇数,说明性别是男性;然后,与今年的年份“2018”相差,得出年龄是2018-1990=28岁;最后,确认年龄28岁在男性客户的区间范围内,即最终结果是“通过”!
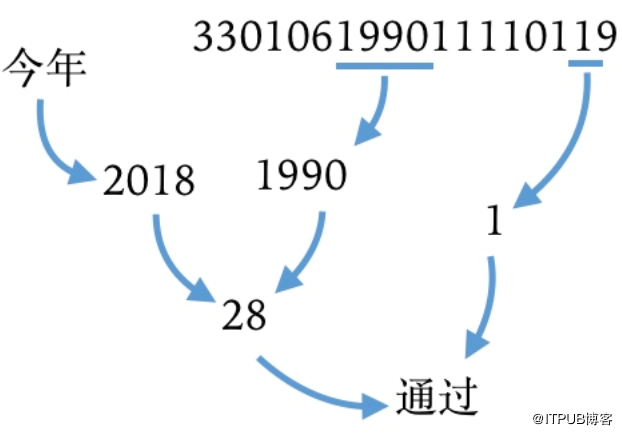
这就是风控系统的工作模式:不停地用一些变量算出另一些变量,直至获得最终的结果。日常办公软件中,电子表格(如Excel)正是一款符合该工作模式的软件:使用公式,单元格可引用另一个单元格内的数据,当被引用的单元格数据发生变化时,公式的计算结果会自动更新。
正如前文所言,一些业务刚起步的互金公司,不值得开发一套自主的风控系统,就可以用Excel来完成风控工作。将上述规则映射到Excel中,对应下图中的5行记录。除第一行的身份证号,其他值都直接或间接由身份证号衍生而来。
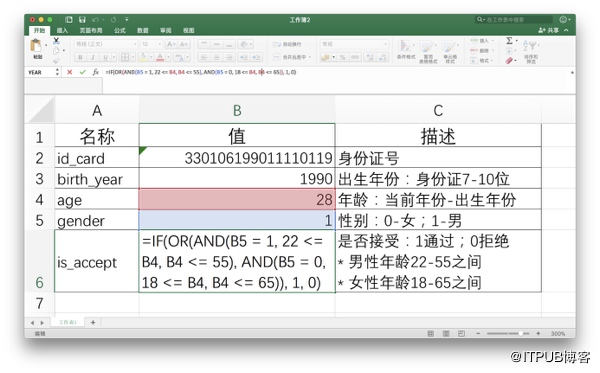
上图中最后一个特征变量的公式用到了IF、OR与AND三个函数,并且依赖了B4和B5两个单元格。Excel默认已提供了丰富的函数,但某些复杂运算逻辑——例如求熵——并未提供,但Excel支持用VBA自定义函数。
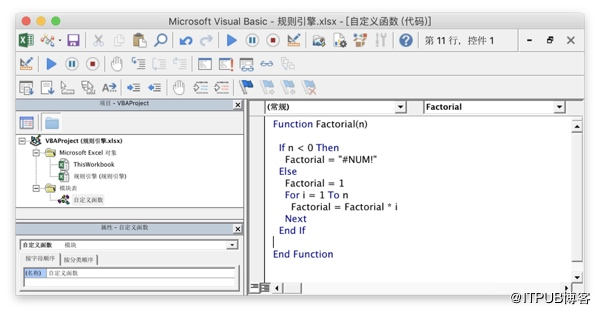
下图中定义了一个计算阶乘的函数,无需重启就能直接在公式中使用。虽说Excel不太招DBA们待见,处于鄙视链的底端,但扩展性和易用性方面窃以为能碾压不少主流的“真正”数据库。
从功能上来讲,51的风控系统和Excel是一样的,都提供了存储能力与计算能力。下图展示了51风控系统的组成模块:其中维度等价于Excel文件;快照等价于Excel的工作表(Sheet);而Excel里的单元格(Cell)在风控的系统中称做变量,并按照所属的业务意义细分为“清洗变量”、“特征变量”、“模型变量”、“规则变量”;变量之间也有依赖关系,任务调度模块提供了类似Excel中联动修改单元格值的功能。
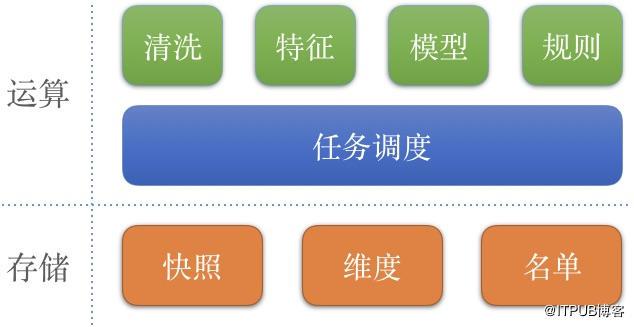
综上所述,只要提供必要的输入,风控系统就会像多米诺骨牌一样,一个接着一个,联动地运算起来!
快照数据
快照,故名思义,是数据在某个时间点的备份。快照功能是风控系统的基础,在任何时刻发生了变量计算,系统都会将相应的输入参数、中间变量、最终结果保存成快照。这些快照数据有三类作用:
1. 历史证据:对业务而言,无论何时访问一笔订单相关的数据都是相同的,数据不会随时间变化而变化;对开发而言,方便线上问题的定位和排查。
2. 缓存数据:风控数据后续还会在信审、催收等系统多次用于展示,快照数据既是证据又是缓存,避免每次查询时多次计算。
3. 建模分析:积累的快照数据后续能用于分析与建模,供机器学习等算法使用。
数据结构
上述例子的5个变量,转换成JSON格式后,数据结构如下:
{
"id_card": "330106199011110119",
"birth_year": 1990,
"age": 28,
"gender": 1,
"is_accept": 1
}
如前文所述,变量会根据其业务意义分类。例如按照“输入变量”、“中间特征变量”、“输出规则变量”分成三类,数据结构就变成如下更复杂的嵌套结构:
{
"inputs": {
"id_card": "330106199011110119"
},
"features": {
"birth_year": 1990,
"age": 28,
"gender": 1
},
"rules": {
"is_accept": 1
}
}
在真实业务场景中,数据结构往往会更复杂、嵌套更深。例如再从身份证号中解析出省市区信息,数据结构会变成三层嵌套结构:
{
"inputs": {
"id_card": "330106199011110119"
},
"features": {
"birth_year": 1990,
"age": 28,
"gender": 1,
"address": {
"province": "浙江省",
"city": "杭州市",
"district": "西湖区"
}
},
"rules": {
"is_accept": 1
}
}
存储方案一:MongoDB
保存这类复杂的嵌套JSON数据,用MongoDB这种文档型数据库是最方便的。所以第一版的快照系统底层存储采用MongoDB——JSON进JSON出。MongoDB对开发者很友好,但业务人员大多来自传统银行,他们更熟悉SAS与SQL,MongoDB之于他们而言,和保存成JSON文件没区别,都很难开展统计与分析工作。
存储方案二:MySQL
为协助业务快速前进,第二版的快照系统,将底层存储方案换成了业务人员更熟悉的关系型数据库——MySQL。并制定了以下规范,用于将嵌套的JSON数据,保存到一系列二维表中:
如果值为基础类型(数值或字符串),则代表“字段”类型
如果值为复合类型(对象或数组),则代表“表”类型
第一层必须为“表”类型。
每一张表必须有一个唯一主键“id”。
嵌套的“表”,必须有一个外键字段指向上一层表的“id”。
例如,前文的JSON数据映射成以下表结构:
inputs:表
id:字段,主键
id_card:字段
features
id:字段,主键
birth_year:字段
age:字段
gender:字段
address:表
id:字段,主键
feature_id:字段,外键,指向features.id
province:字段
city:字段
district:字段
rules:表
is_accept:字段
将JSON拍平成二维表之后,业务人员又能愉快地使用SQL查询并分析数据了,但却给开发带来一些负担。被MongoDB惯坏之后,工程师们希望新方案能保留MongoDB直接存取JSON的能力:只要把JSON丢进来,希望系统就能自动一层一层去保存;只要给一个ID,希望系统能自动查询相关表,并将结构组织成JSON再返回。
为此,我们开发了一个中间件——ActiveMap——对JDBC做了一层简单的封装:它能自动获得数据库的元信息——例如表名、字段名、外键依赖等——根据这些元信息,与JSON做自动映射,以实现JSON的自动拆箱和自动装箱。
存储方案三:PostgreSQL
方案二上线后只几个月,业务爆发式增长,很快遇到了新问题:因为风控业务的特殊性,需要频繁地新增特征变量,即频繁地添加字段。但快照数据积累很快,几个月下来平均每张表有过亿的数据量,往这些大表里新增字段或新增索引,即使业务不停工也要折腾很久。于是,在开发快照系统的第三个版本时,再次调整了底层存储,换成PostgreSQL。PostgreSQL拥有了两个强大的特性:
1. 创建索引时用concurrently,就能并发地创建索引,不会取得任何能阻止该表上并发插入、更新或者删除的锁。
2. 添加新的列,如果不指定默认值,就只修改元数据,能瞬间完成。
有了这两个特性,后续新增特征变量就不用大费周章了。
存储方案四:PostgreSQL+JSONB
方案三上线后运行了近一年,直到某天流量爆发,平均一分钟能收到8000多笔申请,此时的数据结构已经复杂到有5、6层嵌套结构,涉及十几张表的写入,最宽的表有超过400个字段,每笔申请会瞬间产生约20万条快照记录,即每分钟保存约16亿条记录。据DBA观察,当时TPS已经突破5万大关。虽然应用层有重试机制,能保证所有任务最终都能正常完成,但数据库已经不可用。
经过重新评估,最终用PostgreSQL自带的JSONB类型代替多表结构。这仿佛回到方案一:用MongoDB存JSON。其实,在快照系统不断升级的这两年里,51的大数据平台也同样在进步,并搭建了内部的离线数仓,线上数据会T+1同步到离线Hive仓库,同时解析JSON数据,展开成二维表。
业务人员不再直连线上业务库,也就不关心线上库的存储形式。改造后的系统,存储效率提升了10多倍,已经能满足目前线上的业务量。
我们从中学到:架构师在做技术选型时,都是戴着脚镣跳舞,得因地制宜,得结合环境的约束,才能给出当下最适合的方案。在方案一就采用MongoDB属于太过激进:仅考虑线上输出风控这一个环节,MongoDB是合适的方案;但全局考虑上下游系统的协作,以及各方的学习成本,MongoDB就不见得是最佳选择了。
维度数据
维度是快照数据依附的主体,即这些数据属于“谁”。大多数金融业务系统基本只和一个维度的数据打交道。例如,信审系统只处理订单相关的数据,清算系统只处理标的相关的数据。但风控系统会贯穿整个金融业务生命周期,例如下单前风控系统要提供用户的授信额度和信用评级,这类数据属于用户维度;下单后订单号是唯一表示,维度变成订单维度;募资时维度又变成标的维度。
这些系统在各自处理过程中,都会从风控系统查询一些风险相关的数据,所以风控系统更像是一个横向的切面服务,而不是垂直的服务。
不同维度的数据需要相互隔离、不能覆盖,最简单的做法是给每个维度的快照数据创建独立的表。例如上述例子中,有inputs、features、rules三类快照数据,假设只有订单维度(orders)和用户维护(users),排列组合就产生了3*2=6张表。后续,无论是新增一个维度还是新增一个快照,都需要创建一批表,所以这种方式会引起组合爆炸!
桥接模式
设计模式中的桥接模式可以解决这种多对多组合的问题,它将抽象部分与它的实现部分分离,使两者能独立地变化。借鉴这个思路,将“维度”与“快照”抽象成两个独立的部分,通过继承各自独立变化。如下图所示:
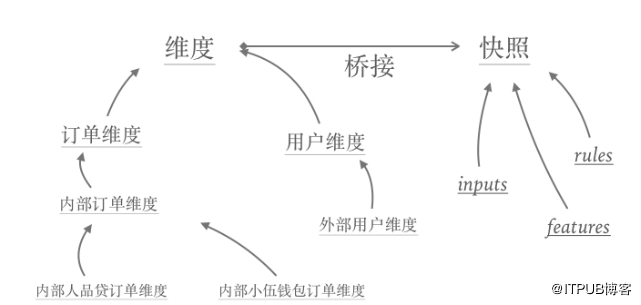
虽然桥接模式可以解决组合爆炸的问题,但它毕竟属于面向对象领域,需要将诸如“继承”等面向对象的语义转换成“join”等关系型范式的语义,才能用来解决上述关系型数据库中的问题。
例如,互金领域的订单都会包含申贷金额和期数,但结合更具体的场景,如面向个人的产品订单,需要保存申贷个人的身份证号等,而面向商家的产品订单,则需要提供营业执照等信息。用面向对象的语言设计时,通常会先定义一个抽象的订单基类,再定义个人订单与商家订单两个子类;在关系型数据库中设计时,通常会定义一个订单表,只包含公共的字段,再定义个人订单表和商家订单表,分别保存各自的扩展字段,并都包含一个外键指向订单表的订单主键。在维护旧系统的过程中,如果你经常能看到类似XXX_EXT结尾的扩展信息表,基本都属于这种模式。但这种模式读写都很麻烦:读的时候,需join多张表,继承的层次越深,join的表越多;写的时候,需做好多表插入的事务控制。
继承表
看起来在关系型数据库中实现桥接模式并不容易。翻看PostgreSQL官方文档、第一章、第一节:《What is PostgreSQL?》,第一句话说:PostgreSQL是一个对象-关系型数据库管理系统!它不可思议地内置了面向对象的继承功能:
子表继承父表的字段
父表可查询子表数据
通过约束排除无关表:constraint_exclusion
与父表共享一个序列
它完美地融合了面向对象和关系型两种范式,用inherits关键字继承父表,就像Java中用extends关键字继承父类一样简单。举个例子:有两张子表children1和children2分别继承了parents父表,并各自声明了约束。
create table parents (id serial primary key, type int, name text);
create table children1 (primary key (id), check (type = 1)) inherits (parents);
create table children2 (primary key (id), check (type = 2)) inherits (parents);
select * from parents where type = 1;
当执行第4条type=1查询时,只会扫描parents表和children1表,并不会扫描children2表。维度数据库正是利用该特性,实现了桥接模式,几乎没给开发工程师增加工作量。
名单数据
名单数据通常是指黑名单和白名单,一般都是随着业务发展不断积累,在风控中属于最简单直接的拦防方法。
方案一:资源文件
51风控项目刚起步时,只有一份几十万条记录的身份证黑名单,保存成txt文件才几MB。所以,第一期直接把名单打包进项目中:
1. 名单作为资源文件打包进Java项目中。
2. 系统启动时将数据加载到内存,生成HashSet。
3. 查询时,检查key是否在集合中即可。
方案二:Redis
方案一简单、粗暴、有效,但上线后其他项目也想使用这份黑名单,如果在每个项目中都拷贝一份,未来往黑名单中新增记录就变得很困难。于是升级成方案二:利用Redis集群来维护名单数据,并提供查询服务。使用依旧很简单,性能也很好。
方案二持续了很久,直到遇到一项新需求:提供模糊查询功能。例如,名单库中有“330106199011110119”这条记录,当使用“3301061990111*****”这类带掩码key来查询时,希望返回“true”。
这个需求用Redis的SCAN也可以实现,不过SCAN毕竟还是要扫一遍所有的KEYS;另一种方法是插入明文的时候,同时插入相应的掩码,即掩码也保存在名单库中,就能用掩码查询了。这两种方法,都需要计算明文对应的掩码,只不过前者在查询时计算,后者在插入时计算。对于名单库这种一次插入多次查询的场景,后者会更适合。
方案三:PostgreSQL+Groovy
为了添加时生成掩码,当时总共评估了三套方案:
1. 增强Redis:用lua或C语言改造Redis,提供一个自定义的命令(如MASK_SET)代替SET命令,自动添加掩码key。
2. 部分取代Redis:新开一个Java工程,提供单个添加、批量添加等接口,取代直接写Redis,但最终明文和掩码的key依旧保存在Redis中,读操作直接访问Redis。
3. 抛弃Redis:新开一个Java工程,同时提供读写名单的接口,完全屏蔽甚至抛弃Redis。
方案一对于应用层而言非常优雅,改动量最小,但后续添加新的掩码规则时都要去修改并重新部署自定义命令,在当时的人才储备下实施成本较高;
方案二让应用层接入成本升高,需同时接入Redis和服务接口,还需同时考虑两者的可用性与降级策略等;综合考虑之后,最终选择方案三,实施和迁移的成本都还能接受。
考虑到掩码规则在未来一小段时间内会频繁地增删改,为避免每次修改规则都重新发布,所以不能将规则硬编码,而是用Groovy脚本作为规则配置到数据库中,这些脚本称作生成器(Generator),它们接收一个JSON作为入参,检查参数是否拥有相关字段,如果有则返回相应的掩码,否则返回空。
此外,每新增一个Generator时,都需要全量计算明文Key相应的掩码Key;删除明文Key时,也需要关联删除相应的掩码Key。因此,还要保存Generator与Key的映射关系。原计划新工程只是封装Redis,但关联查询并非Redis所擅长,在经过一系列性能对比之后,最终决定用PostgreSQL取代Redis,设计方案如下:
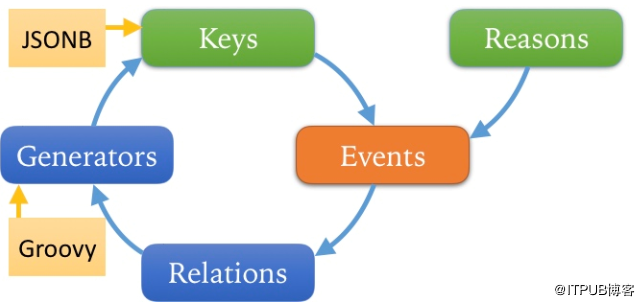
所有明文和掩码保存在Keys表中。
Keys的数据类型采用JSONB,因为不同名单Key的类型与字段数目都有可能不同。例如有些名单是手机号码、有些是姓名+身份证号、有些是用户ID。
被加入名单的原因存入reasons表。
两者通过事件(Events)相关联。
生成器保存在Generators中。
生成器生成的掩码Key通过Relations与Events关联。
方案四:PostgreSQL+UDF
方案三能满足模糊查询的需求,也在生产中运用了一段时间,但整个方案相当“凑活”,使用过程中遇到不少麻烦:
每次新增Groovy Generator时,需全量计算所有明文Keys。但因为待计算的量比较大,无法一次性快速计算完,不得不分批计算,于是又额外需要任务管理与调度功能,导致系统愈加复杂。
无法用PostgreSQL自带的COPY命令来批量导入Keys,因为掩码Key依赖应用层用Groovy生成,只能调用应用端的接口逐个计算。
批量导入时会占用应用层大量资源,导致正常查询请求不能得到及时响应。
因为数据库之上架了一层应用层,整体链路变长,性能变差。
这些麻烦归根到底,原因是数据与计算不在同一体系内,数据不得不在持久层和应用层之间来回传递;同时,因为应用层作为统一出口,诸如批量导入数据这些原本数据库已经支持的功能,又不得不在应用层再实现一遍,还实现的更加蹩脚。是否有可能通过增强现有的持久层体系,而不是额外引入一层新的应用层?这样既能充分利用持久层的现有功能,又能避免数据传输和调度的额外工作,也避免重复造轮子。
前文提到,Redis通过模块功能支持自定义功能,Excel通过VBA也能轻松自定义函数。PostgreSQL中,通过UDF(User Defined Function),允许用C、SQL、PLPGSQL、Python等几乎所有主流编程语言,动态添加自定义函数。例如,用SQL实现计算身份证号后5位掩码的函数:
create function id_card_mask(jsonb) returns text as $$
select substring(->>'id_card', 1, 13) || '*****'
$$ language sql immutable;
有了计算掩码的函数,再绑定一个触发器(Trigger)——插入明文数据后自动再插入相应的掩码数据。但转念一想,掩码真正的用途是用来查询,例如:
select * from keys where id_card_mask(context) = '3301061990111*****';
之所以一直考虑提前计算好并保存掩码结果,是避免每次查询时都反复计算。PostgreSQL提供了另一个特性——表达式索引——既能避免重复计算,又能节约空间。索引通常都创建在真实的列上,而表达式索引允许给函数的计算结果创建索引:
create index on keys (id_card_mask(context));
当查询条件中出现了与表达式索引中完全一致的表达式时,PostgreSQL会直接使用索引中的计算结果,并不会执行该表达式。所以,即使函数执行非常耗时,也能高效地查询!利用UDF和表达式索引,可以完全抛弃应用层,甚至连Generators和Relations这两张表也可丢弃,整体方案得到极大简化。
来看一下优化前后的对比:优化前,磁盘空间占用接近10G,优化后只用了2G;TPS,即单位时间生成新Key的速度,优化前在应用端用Groovy脚本计算并保存,TPS约2500,优化后突破了12000。效果是非常惊人!最重要的是,可以直接用COPY等命令批量导入名单,索引能自动生成,也无需担心有遗漏。

任务调度
任务调度,正如前文所述,处理任务之间的依赖关系,就像解决Excel中单元格相互引用。举个例子:有A、B、C、D四个任务
D依赖B
D依赖C
C依赖A
B依赖A
任务调度的工作就是管理任务间的依赖关系,按照有效的顺序依次执行任务。在上例中,调度系统会首先执行A、接着同时执行B和C、最后执行D。如下图所示,任务的依赖关系是有向无环图,用拓扑排序就能得到正确的执行顺序,其思想是每次取出“出度”为0的节点,这些节点不依赖其他节点,处于可执行状态。

方案一:多表join
每个任务创建一张与之对应的任务队列表
每张任务表有一个status状态字段,可取值:
submitted:待处理
completed:已完成
依赖某个任务,就join相应的任务队列表
以上述4个任务为例,需创建queue_a、queue_b、queue_c、queue_d四张任务队列表。结构如下:
create table queue_x (
id bigint primary key,
status text not null default 'submitted'
);
假设4张表中都插入一个id为1的任务,并且状态都是submitted。根据前文的依赖关系,可以算出每个任务依赖的队列状态。比如任务A,不依赖其他任务,只要队列queue_a中有一条状态为submitted状态的任务就能马上执行;任务B和C都依赖了任务A,除了各自的队列queue_b和queue_c有一条状态为submitted的任务,还需要queue_a中有一条id相同且状态为completed的任务;任务D,则需要queue_d有状态为submitted,queue_b与queue_c状态为completed。任务调度系统会根据以上依赖关系,自动生成SQL查询语句:
select queue_a.id from queue_a where queue_a.status = 'submitted';
select queue_b.id from queue_b inner join queue_a on queue_b.id = queue_a.id where queue_b.status = 'submitted' and queue_a.status = 'completed';
select queue_c.id from queue_c inner join queue_a on queue_c.id = queue_a.id where queue_c.status = 'submitted' and queue_a.status = 'completed';
select queue_d.id from queue_d inner join queue_b on queue_d.id = queue_b.id inner join queue_c on queue_d.id = queue_c.id where queue_d.status = 'submitted' and queue_b.status = 'completed' and queue_c.status = 'completed';
1. 第一轮:queue_a的状态变成了completed;其他队列不变。
2. 第二轮:queue_b和queue_c的状态变成completed;queue_a和queue_d状态保持不变。
3. 第三轮:queue_d的状态变成completed;所有队列状态都变成completed。
PostgreSQL还提供了一个特性——条件索引——可以优化查询性能:
create index on queue_x (id) where status = 'submitted';
条件索引只给符合条件的记录创建索引,所以索引占用的空间就非常小。因为任务实时在调度,正常情况下处于待处理的任务并不多,所以检索速度会非常快!
方案二:数组倒排
方案一原理简单,在任何关系型数据库中都能实现。但随着依赖数量急剧膨胀,出现超过40张表join的场景,性能急剧下降,高峰期最长耗时700多毫秒。经过研究,对方案做出了改进,用到PostgreSQL另外两个特性——数据类型和倒排索引:
用两个数组字段取代原来任务队列表
submits int[]
completes int[]
数组字段创建GIN倒排索引
新方案极大简化了表结构,不再需要一堆任务队列表,只需要一张queues表:
create table queues (
id bigint primary key,
submits int[],
completes int[]
);
不仅表结构简化,连查询语句也极大的简化:
select id from queues where submits @> '{A}';
select id from queues where submits @> '{B}' and completes @> '{A}';
select id from queues where submits @> '{C}' and completes @> '{A}';
select id from queues where submits @> '{D}' and completes @> '{B,C}';
其中@>是包含运算符,意思是左边的数组包含了右边数组中所有的元素。
1. 初始状态:submits的值是{A,B,C,D},completes的值是{}。
第一轮:A从submits移到completes,submits的值变成{B,C,D},completes的值是{A}。
2. 第二轮:B和C从submits移到completes,submits的值变成{D},completes的值是{A,B,C}。
3. 第三轮:D从submits移到completes,submits的值变成{},completes的值是{A,B,C,D}。
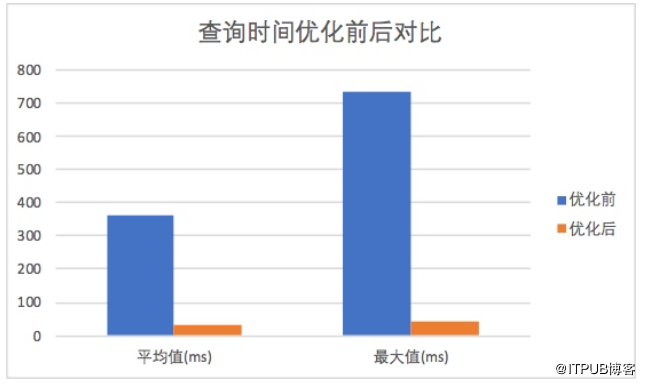
优化前,40张表join的方法,平均耗时在350ms左右,最大耗时会超过700ms;优化后,平均耗时在35ms以下,业务高峰期的最大耗时也只有45ms。下降了一个数量级!
总结
前文总共用到了PostgreSQL数据库的9个特性:
1. 瞬间添加无默认值新列
2. JSONB类型
3. 数组类型
4. 继承表
5. UDF
6. 并发创建索引
7. 表达式索引
8. 条件索引
9. 倒排索引
这9个特性分别解决了风控系统中遇到的各种问题,就像是武侠中的绝世武功——独孤九剑:遇刀破刀、遇剑破剑!PostgreSQL的特性远不止这9个,诸如并行查询、空间索引等都未涉及。
PostgreSQL不仅仅是一个提供了SQL接口的关系型数据库,更是一个类似Hadoop、拥有存储能力和运算能力的开发平台!希望本文能抛砖引玉,掌握更多PostgreSQL的特性,为开发赋能!
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号