掌握OpenAI:一步步教程指南
发表时间: 2018-12-12 20:14

在本教程中,我将解释如何从头开始创建OpenAI环境并在其上训练代理。
我还将解释如何创建模拟器以开发环境。本教程分为以下部分:问题陈述,模拟器,Gym环境和训练。
目标是创建一个人工智能代理来控制整个航道中船舶的导航。
如今,在诸如通道和港口的限制水域中的导航基本上基于关于诸如给定位置中的风和水流的环境条件的先导知识。

假设人类仍在犯错误,有时会损失数十亿美元,而人工智能是一种可能的替代方案,可以应用于导航,以减少事故数量。
为了创建一个人工智能代理来控制船只,我们需要一个环境,在这个环境中,人工智能代理可以执行导航体验,并通过自己的错误学习如何正确地导航整个通道。此外,由于我们不能使用真实的船只来训练AI代理,最好的替代方法是使用模拟真实船只动态行为的模拟器。为此,我们可以使用现有的商业软件,但在本教程中,我们将创建自己的船舶模拟器。
为此,采用了一些假设,例如:船是刚体,在船上唯一的外力是水阻力(无风,无水流),而推进力和方向舵控制力是用来控制船的方向和速度。控制船舶动力学的完整方程是复杂的。在这里,我们将使用一个非常简单的3DOF模型:
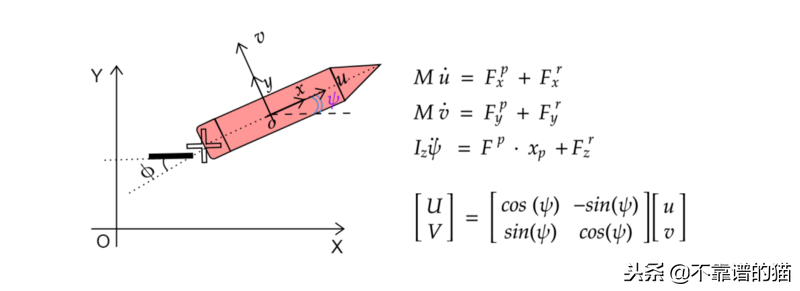
在该图中,u是船舶相对于固定在船舶CG上的框架的纵向速度,v是牵伸速度,dψ/ dt是相对于固定参考的角速度,ψ是船舶的迎角。相对于固定框架OXY测量。速度U,V(fixed frame)通过2x2旋转矩阵链接到u,v。Φ是舵角测量,如图所示。
阻力和推进力的公式超出了本教程的范围,但总的来说阻力与船的运动相反,与船的速度成比例。舵和推进力量成正比的参数Al(−1,1)和Ap[0,1]。这些参数与舵角和推进力成正比(Al和Ap为可控参数),这样:
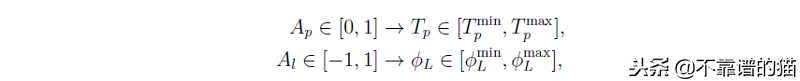
现在我们有模型微分方程,我们可以使用积分器来构建我们的模拟器。让我们写下我们的模拟器。
第1步:模拟器方程。写上面的方程式隔离加速度项我们有:
def simulate_scipy(self, t, global_states): local_states = self._global_to_local(global_states) return self._local_ds_global_ds(global_states[2], self.simulate(local_states)) def simulate(self, local_states): """ :param local_states: Space state :return df_local_states """ x1 = local_states[0] # u x2 = local_states[1] # v x3 = local_states[2] # theta (not used) x4 = local_states[3] # du x5 = local_states[4] # dv x6 = local_states[5] # dtheta Frx, Fry, Frz = self.compute_rest_forces(local_states) # Propulsion model Fpx, Fpy, Fpz = self.compute_prop_forces(local_states) # Derivative function fx1 = x4 fx2 = x5 fx3 = x6 # main model simple fx4 = (Frx + Fpx) / (self.M) fx5 = (Fry + Fpy) / (self.M) fx6 = (Frz + Fpz) / (self.Iz) fx = np.array([fx1, fx2, fx3, fx4, fx5, fx6]) return fx
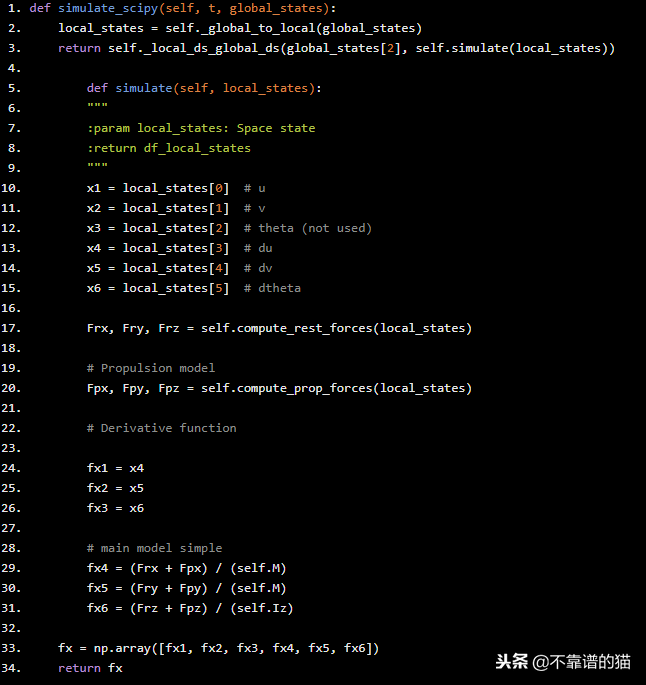
在前6行中我们只定义了从x1到x6的变量名,beta和alpha是用于控制方向舵和推进控制的控制常数,在我们计算阻力之后最后我们将导数项fx1,fx2 ...,fx6隔离开来。这样:

第2步:积分器。作为模拟积分器,我们使用scipy库的5-order Runge-Kutta积分器。
from scipy.integrate import RK45
我们定义了一个函数,它使用scipy RK45对一个有趣的函数进行积分,这个函数的起点是y0。从t0到t_bound进行积分,得到相对公差rtol和绝对公差atol。
def scipy_runge_kutta(self, fun, y0, t0=0, t_bound=10): return RK45(fun, t0, y0, t_bound, rtol=self.time_span/self.number_iterations, atol=1e-4)

因为我们使用全局引用(OXY)来定位船舶,使用局部引用(oxyz)来积分方程,所以我们定义了一个“mask”函数来在积分器中使用。该函数将函数模拟输出的微分向量基本转换为全局引用。
def simulate_scipy(self, t, global_states): local_states = self._global_to_local(global_states) return self._local_ds_global_ds(global_states[2], self.simulate(local_states))

Step3:step函数
对于每个step,我们通过方向舵angle_level和旋转水平(rot_level)来控制推进力传递的推力。
def step(self, angle_level, rot_level): self.current_action = np.array([angle_level, rot_level]) while not (self.integrator.status == 'finished'): self.integrator.step() self.last_global_state = self.integrator.y self.last_local_state = self._global_to_local(self.last_global_state) self.integrator = self.scipy_runge_kutta(self.simulate_scipy, self.get_state(), t0=self.integrator.t, t_bound=self.integrator.t+self.time_span) return self.last_global_state

在第一行中我们存储当前动作向量,在第二行中我们使用RK45 self.integrator.step()进行积分,直到它达到最终时间跨度。最后通过 self.integrator对self.last_global_state, self.last_local_state和积分区间进行了更新。。最后,我们返回全局状态self.last_global_state。
Step4:reset函数。reset函数用于在每次新迭代(例如初始位置和速度)下设置模拟的初始条件。它使用全局变量并更新self.last_global_state,self.last_local_state。
def reset_start_pos(self, global_vector): x0, y0, theta0, vx0, vy0, theta_dot0 = global_vector[0], global_vector[1], global_vector[2], global_vector[3], global_vector[4], global_vector[5] self.last_global_state = np.array([x0, y0, theta0, vx0, vy0, theta_dot0]) self.last_local_state = self._global_to_local(self.last_global_state) self.current_action = np.zeros(2) self.integrator = self.scipy_runge_kutta(self.simulate_scipy, self.get_state(), t_bound=self.time_span)

最终的代码可以在这里查看(
https://github.com/jmpf2018/SimpleShipAI/blob/master/simulator_simple.py)。
一旦我们拥有我们的模拟器,我们现在可以创建一个Gym环境来训练代理。
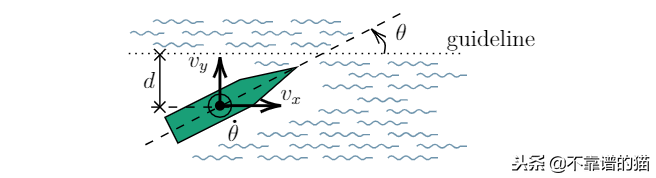
3.1状态
状态是代理可以“看到”全局的环境变量。代理使用变量在环境中定位自己,并决定采取什么动作来完成建议的任务,定义如下:
使用方向舵控制在给定的恒定推进动作下沿通道执行定义的线性导航路径。
选择在任务中应用RL的状态如下:
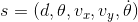
其中d为船舶质心到guideline的距离;θ是船舶纵轴与guideline之间的夹角;vx是船舶在其质心处(在guideline方向上)的水平速度;vy是船舶质心的垂直速度(垂直于guideline);dθ/ dt是这艘船的角速度。
3.2奖励
奖励函数负责惩罚代理,如果他不遵守guideline,并且如果他能够保持guideline,则将奖励他。定义的奖励函数是:
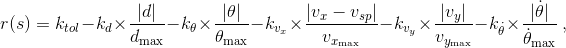
其中:

3.3动作
该action是用于控制船舶操纵运动的输入参数。使船可控的力是方向舵和推进力。动作具有矢量形式Av = [Al,Ap],其中A1是无量纲方向舵命令,Ap是无量纲推进命令,使Al在[-1,1],Ap在[0,1]。
3.4Python编码
现在我们已经定义了环境的主要方面,我们可以写下Python代码。
首先,我们定义船舶的极限边界和我们可观察的空间状态(特征)的“盒子”类型,我们还定义了初始条件框。
self.observation_space = spaces.Box(low=np.array([0, -np.pi / 2, 0, -4, -0.2]), high=np.array([150, np.pi / 2, 4.0, 4.0, 0.2]))self.init_space = spaces.Box(low=np.array([0, -np.pi / 15, 1.0, 0.2, -0.01]), high=np.array([30, np.pi / 15, 1.5, 0.3, 0.01]))self.ship_data = None

之后我们定义一个函数将模拟器空间状态转换为环境空间状态。请注意,我们将vy速度与θ角度和距离d进行镜像,以便AI更容易学习(减小空间状态尺寸)。
def convert_state(self, state): """ This method generated the features used to build the reward function :param state: Global state of the ship """ ship_point = Point((state[0], state[1])) side = np.sign(state[1] - self.point_a[1]) d = ship_point.distance(self.guideline) # meters theta = side*state[2] # radians vx = state[3] # m/s vy = side*state[4] # m/s thetadot = side * state[5] # graus/min obs = np.array([d, theta, vx, vy, thetadot]) return obs
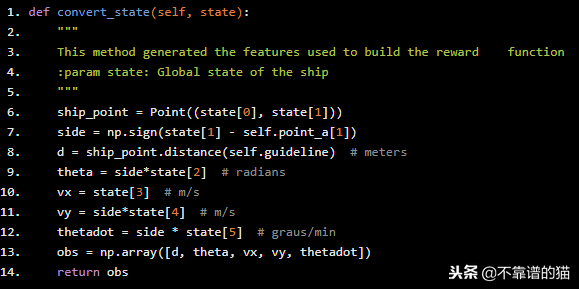
比我们定义一个函数来计算之前定义的奖励
d, theta, vx, vy, thetadot = obs[0], obs[1]*180/np.pi, obs[2], obs[3], obs[4]*180/np.piif not self.observation_space.contains(obs): return -1000else: return 1-8*np.abs(theta/90)-np.abs(thetadot/20)-5*np.abs(d)/150- np.abs(vy/4)-np.abs(vx-2)/2
我们还必须定义step函数。代理在导航时使用此函数,在每个step中,代理选择一个动作并在10秒内(在我们的积分器中)运行模拟并一次又一次地执行,直到它到达通道末端或直到它到达通道边缘。
def step(self, action): side = np.sign(self.last_pos[1]) angle_action = action[0]*side rot_action = 0.2 state_prime = self.simulator.step(angle_level=angle_action, rot_level=rot_action) # convert simulator states into obervable states obs = self.convert_state(state_prime) # print('Observed state: ', obs) dn = self.end(state_prime=state_prime, obs=obs) rew = self.calculate_reward(obs=obs) self.last_pos = [state_prime[0], state_prime[1], state_prime[2]] self.last_action = np.array([angle_action, rot_action]) info = dict() return obs, rew, dn, info
因为我们反映了状态,所以我们也必须反映出方向舵动作。在本教程中,我们将创建一个网络来仅控制方向舵动作并保持旋转角度不变(rot_action = 0.2)。
我们还使用库 turtle创建了一个查看器,您可以在这里查看代码。它用于显示学习过程或训练后的表现。在函数render中调用查看器。
def render(self, mode='human'): if self.viewer is None: self.viewer = Viewer() self.viewer.plot_boundary(self.borders) self.viewer.plot_guidance_line(self.point_a, self.point_b) img_x_pos = self.last_pos[0] - self.point_b[0] * (self.last_pos[0] // self.point_b[0]) if self.last_pos[0]//self.point_b[0] > self.number_loop: self.viewer.end_episode() self.viewer.plot_position(img_x_pos, self.last_pos[1], self.last_pos[2], 20 * self.last_action[0]) self.viewer.restart_plot() self.number_loop += 1 else: self.viewer.plot_position(img_x_pos, self.last_pos[1], self.last_pos[2], 20 * self.last_action[0])
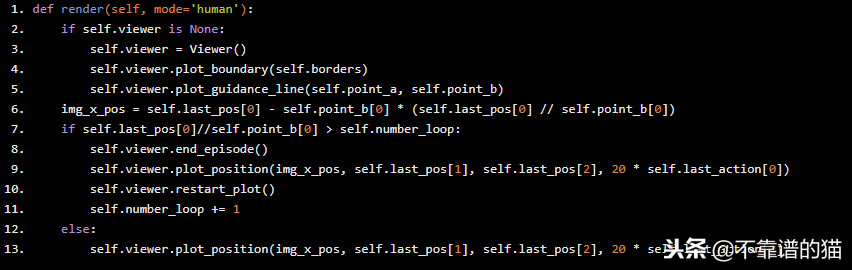
最后,我们定义了设置init space-state和reset函数,它们在每次新迭代的开始使用。
def set_init_space(self, low, high): self.init_space = spaces.Box(low=np.array(low), high=np.array(high))def reset(self): init = list(map(float, self.init_space.sample())) init_states = np.array([self.start_pos[0], init[0], init[1], init[2] * np.cos(init[1]), init[2] * np.sin(init[1]), 0]) self.simulator.reset_start_pos(init_states) self.last_pos = np.array([self.start_pos[0], init[0], init[1]]) print('Reseting position') state = self.simulator.get_state() if self.viewer is not None: self.viewer.end_episode() return self.convert_state(state)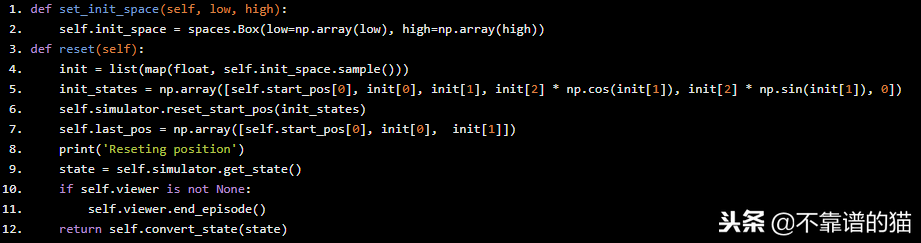
完整的代码可以在这里找到(
https://github.com/jmpf2018/SimpleShipAI)。
为了训练我们的代理,我们正在使用Keras-rl project.的DDPG代理。
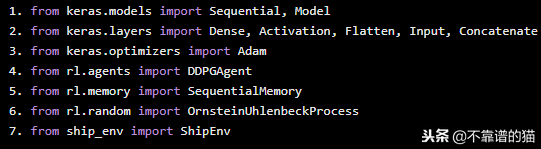
我们比导入所有使用的方法来构建我们的神经网络。
from keras.models import Sequential, Modelfrom keras.layers import Dense, Activation, Flatten, Input, Concatenatefrom keras.optimizers import Adamfrom rl.agents import DDPGAgentfrom rl.memory import SequentialMemoryfrom rl.random import OrnsteinUhlenbeckProcessfrom ship_env import ShipEnv
使用的神经网络具有以下结构(actor-critic structure):

实现这个的Python代码结构如下:
# Next, we build a very simple model.actor = Sequential()actor.add(Flatten(input_shape=(1,) + env.observation_space.shape))actor.add(Dense(400))actor.add(Activation('relu'))actor.add(Dense(300))actor.add(Activation('relu'))actor.add(Dense(nb_actions))actor.add(Activation('softsign'))print(actor.summary())action_input = Input(shape=(nb_actions,), name='action_input')observation_input = Input(shape=(1,) + env.observation_space.shape, name='observation_input')flattened_observation = Flatten()(observation_input)x = Concatenate()([action_input, flattened_observation])x = Dense(400)(x)x = Activation('relu')(x)x = Dense(300)(x)x = Activation('relu')(x)x = Dense(1)(x)x = Activation('linear')(x)critic = Model(inputs=[action_input, observation_input], outputs=x)print(critic.summary())# Finally, we configure and compile our agent. You can use every built-in Keras optimizer and# even the metrics!memory = SequentialMemory(limit=2000, window_length=1)random_process = OrnsteinUhlenbeckProcess(size=nb_actions, theta=0.6, mu=0, sigma=0.3)agent = DDPGAgent(nb_actions=nb_actions, actor=actor, critic=critic, critic_action_input=action_input, memory=memory, nb_steps_warmup_critic=2000, nb_steps_warmup_actor=10000, random_process=random_process, gamma=.99, target_model_update=1e-3)agent.compile(Adam(lr=0.001, clipnorm=1.), metrics=['mae'])
最后,我们使用300.000次迭代训练我们的代理,在训练之后我们得到神经网络的权重和训练历史:
hist = agent.fit(env, nb_steps=300000, visualize=False, verbose=2, nb_max_episode_steps=1000) # train our agent and store training in histfilename = '300kit_rn4_maior2_mem20k_target01_theta3_batch32_adam2'# we save the history of learning, it can further be used to plot reward evolutionwith open('_experiments/history_ddpg__redetorcs'+filename+'.pickle', 'wb') as handle: pickle.dump(hist.history, handle, protocol=pickle.HIGHEST_PROTOCOL)#After training is done, we save the final weights.agent.save_weights('h5f_files/ddpg_{}_weights.h5f'.format('600kit_rn4_maior2_mem20k_target01_theta3_batch32_adam2_action_lim_1'), overwrite=True)最后,经过训练,我们得到以下结果:代理已经学会了如何控制方向舵以及如何在中途保持通道。
更详细的船模型,还包括由AI代理控制的推进动作。可以在此处找到项目存储库。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号