Redis性能卓越,你了解多少?
发表时间: 2022-11-07 14:09
curd 的工程师的梗,大多数程序员都是业务的开发,大量业务有没有让你心乱如麻,有时学些底层的知识感觉也是蛮不错的。

Redis是基于内存运行的高性能 K-V 数据库,官方提供的测试报告是单机可以支持约10w/s的QPS。redis 性能为什么这么好,你不完全知道。
磁盘调用栈图
内存操作
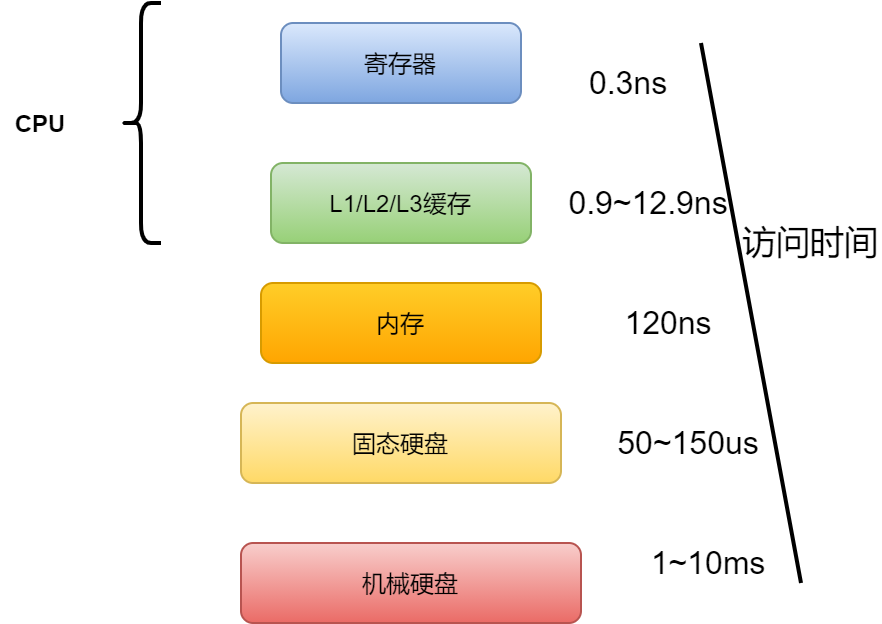
众所周知,内存的访问速度是远远大于硬盘访问速度的。我们来做个对比,拿数据库(硬盘)和 redis (内存)对比,一个操作对应磁盘,一个操作对应内存。他们两个的的访问速度差了一个数量级。
可能大家对数量级没有什么该概念。那可是整整 1000 倍啊!现在大家知道了吧。
1、简单动态字符串 SDS 是对 C 语言字符数组的封装,类似 GO 语言中的切片,也是对应底层数组的封装,在其中增加一些额外的参数,方便加速字符串操作。
字符串长度处理

这个图是字符串在 C 语言中的存储方式,想要获取 「Redis」的长度,需要从头开始遍历,直到遇到 '这个图是字符串在 C 语言中的存储方式,想要获取 「Redis」的长度,需要从头开始遍历,直到遇到 '\0' 为止。' 为止。
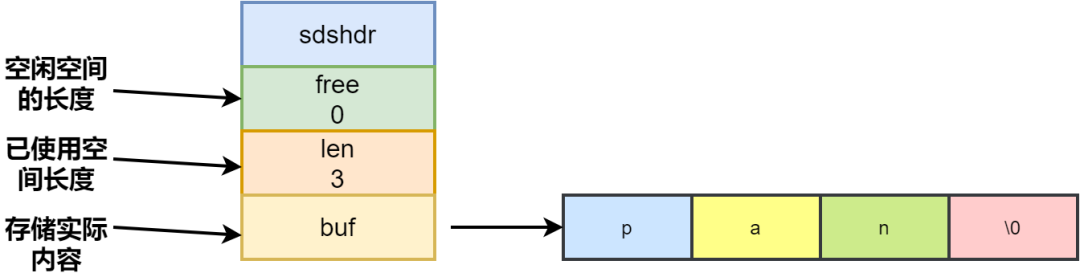
Redis 中用一个 len 字段记录当前字符串的长度。想要获取长度只需要获取 len 字段即可。前者遍历的时间复杂度为 O(n),Redis 中 O(1) 就能拿到,速度明显提升。
内存重新分配
C 语言中涉及到修改字符串的时候会重新分配内存。修改地越频繁,内存分配也就越频繁。而内存分配是会消耗性能的,那么性能下降在所难免。
而 Redis 中会涉及到字符串频繁的修改操作,这种内存分配方式显然就不适合了。于是 SDS 实现了两种优化策略:
空间预分配
对 SDS 修改及空间扩充时,除了分配所必须的空间外,还会额外分配未使用的空间。GO语言中的切片也会分配预留空间,防止空间频繁分配。
具体分配规则是这样的:SDS 修改后,len 长度小于 1M,那么将会额外分配与 len 相同长度的未使用空间。如果修改后长度大于 1M,那么将分配1M的使用空间。
惰性空间释放
当然,有空间分配对应的就有空间释放。
SDS 缩短时,并不会回收多余的内存空间,而是使用 free 字段将多出来的空间记录下来。如果后续有变更操作,直接使用 free 中记录的空间,减少了内存的分配。
二进制安全
你已经知道了 Redis 可以存储各种数据类型,那么二进制数据肯定也不例外。但二进制数据并不是规则的字符串格式,可能会包含一些特殊的字符,比如 '你已经知道了 Redis 可以存储各种数据类型,那么二进制数据肯定也不例外。但二进制数据并不是规则的字符串格式,可能会包含一些特殊的字符,比如 '\0' 等。' 等。
前面我们提到过,C 中字符串遇到 '前面我们提到过,C 中字符串遇到 '\0' 会结束,那 '\0' 之后的数据就读取不上了。但在 SDS 中,是根据 len 长度来判断字符串结束的。' 会结束,那 '前面我们提到过,C 中字符串遇到 '\0' 会结束,那 '\0' 之后的数据就读取不上了。但在 SDS 中,是根据 len 长度来判断字符串结束的。' 之后的数据就读取不上了。但在 SDS 中,是根据 len 长度来判断字符串结束的。
2、双端链表
列表 List 更多是被当作队列或栈来使用的。队列和栈的特性一个先进先出,一个先进后出。双端链表很好的支持了这些特性。
前后节点
链表里每个节点都带有两个指针,prev 指向前节点,next 指向后节点。这样在时间复杂度为 O(1) 内就能获取到前后节点。
头尾节点
你可能注意到了,头节点里有 head 和 tail 两个参数,分别指向头节点和尾节点。这样的设计能够对双端节点的处理时间复杂度降至 O(1) ,对于队列和栈来说再适合不过。同时链表迭代时从两端都可以进行。
链表长度
头节点里同时还有一个参数 len,和上边提到的 SDS 里类似,这里是用来记录链表长度的。因此获取链表长度时不用再遍历整个链表,直接拿到 len 值就可以了,这个时间复杂度是 O(1)。不用每次遍历获取长度。
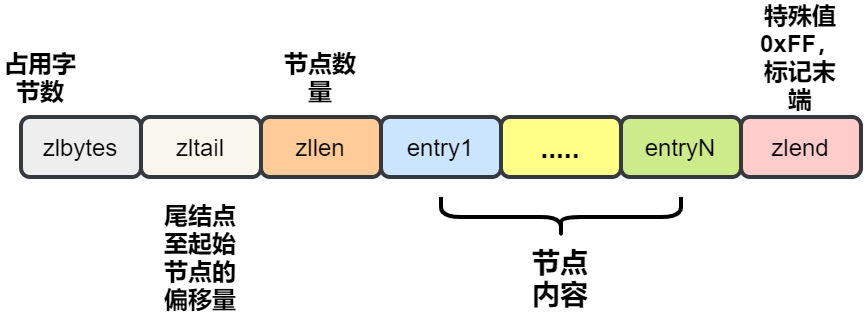
3、压缩列表
双端链表我们已经熟悉了。不知道你有没有注意到一个问题:如果在一个链表节点中存储一个小数据,比如一个字节。那么对应的就要保存头节点,前后指针等额外的数据。
这样就浪费了空间,同时由于反复申请与释放也容易导致内存碎片化。这样内存的使用效率就太低了。
于是,压缩列表上场了!
它是经过特殊编码,专门为了提升内存使用效率设计的。所有的操作都是通过指针与解码出来的偏移量进行的。
并且压缩列表的内存是连续分配的,遍历的速度很快。
4、字典
Redis 作为 K-V 型数据库,所有的键值都是用字典来存储的。
字典又称为哈希表,这点没什么可说的。哈希表的特性大家都很清楚,能够在 O(1) 时间复杂度内取出和插入关联的值。
5、跳跃表
作为 Redis 中特有的数据结构-跳跃表,其在链表的基础上增加了多级索引来提升查找效率。
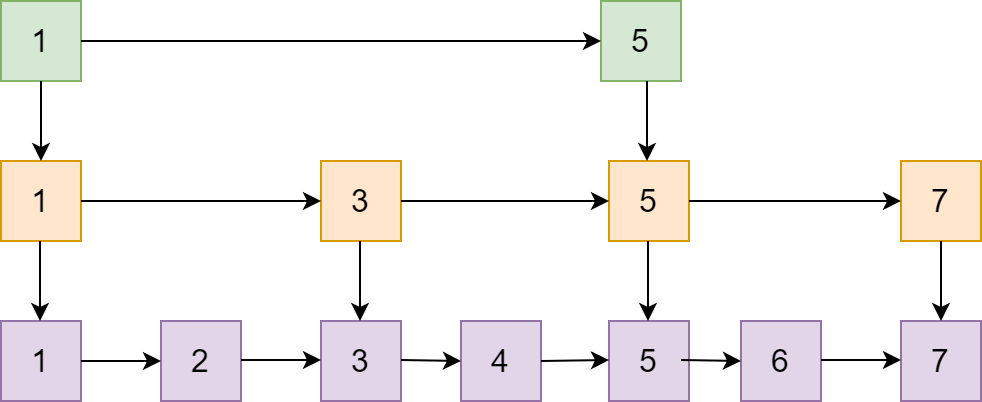
这是跳跃表的简单原理图,每一层都有一条有序的链表,最底层的链表包含了所有的元素。这样跳跃表就可以支持在 O(logN) 的时间复杂度里查找到对应的节点。
下面这张是跳表真实的存储结构,和其它数据结构一样,都在头节点里记录了相应的信息,减少了一些不必要的系统开销。

单线程指的是 Redis 键值对读写指令的执行是单线程。
Redis 的单线程指的是 Redis 的网络 IO (6.x 版本后网络 IO 使用多线程)以及键值对指令读写是由一个线程来执行的。
单线程有什么好处?
多线程的弊端
从网络 IO 来说,redis 的 网络 IO 接收事件,确实是一个很需要去提升的点 因为所有客户端对 redis 的操作 最终都会由 redis 的网络模块接受 ,所以对于 redis 来说 提升网络 IO 的利用率很有必要。
redis在4.0版本的时候就已经引入了多线程来做一些异步操作,此举主要针对那些非常耗时的命令,通过将这些命令的执行异步化,避免阻塞单线程的事件循环(增加了一些的非阻塞命令如 UNLINK、FLUSHALL ASYNC、FLUSHDB ASYNC)。
redis v6.0版本的时候引入了多线程IO,只是用来处理网络数据的读写和协议的解析,而执行命令依旧是单线程。
Redis 采用 I/O 多路复用技术,并发处理连接。采用了 epoll + 自己实现的简单的事件框架。
epoll 中的读、写、关闭、连接都转化成了事件,然后利用 epoll 的多路复用特性,绝不在 IO 上浪费一点时间。
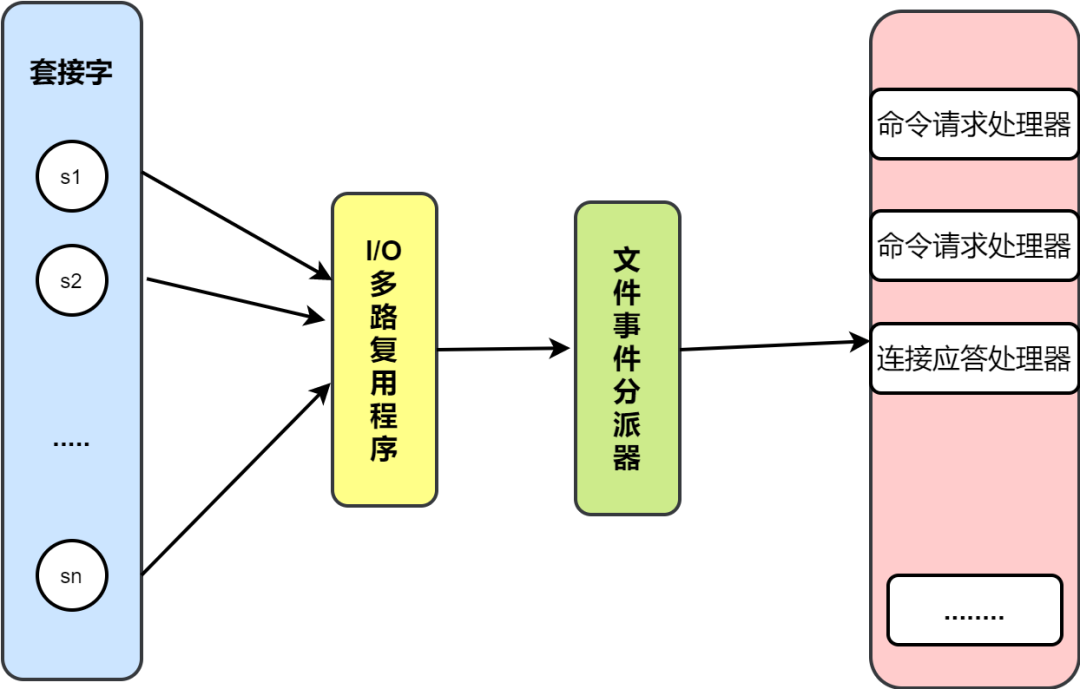
Redis 线程不会阻塞在某一个特定的监听或已连接套接字上,也就是说,不会阻塞在某一个特定的客户端请求处理上。正因为此,Redis 可以同时和多个客户端连接并处理请求,从而提升并发性。
对于每一种数据类型来说,底层的支持可能是多种数据结构,什么时候使用哪种数据结构,这就涉及到了编码转化的问题。
那我们就来看看,不同的数据类型是如何进行编码转化的:
String:存储数字的话,采用int类型的编码,如果是非数字的话,采用 raw 编码。
List:字符串长度及元素个数小于一定范围使用 ziplist 编码,任意条件不满足,则转化为 linkedlist 编码。
Hash:hash 对象保存的键值对内的键和值字符串长度小于一定值及键值对。
Set:保存元素为整数及元素个数小于一定范围使用 intset 编码,任意条件不满足,则使用 hashtable 编码。
Zset:zset 对象中保存的元素个数小于及成员长度小于一定值使用 ziplist 编码,任意条件不满足,则使用 skiplist 编码。
Redis 6.0中的多线程,也只是针对处理网络请求过程采用了多线程,而数据的读写命令,仍然是单线程处理的。
期待后期版本 redis 数据的读写命令使用多线程,大家认为这是否合适?
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号