OpenAI发布GPT-4o mini大模型,与中国竞品对比揭秘
发表时间: 2024-08-02 22:55
美国时间 7 月18 日,OpenAI 正式发布了多模态小模型 GPT-4o mini,在海内外引起了广泛关注。
此前,OpenAI 凭借 GPT-3 开拓了 AI 模型的“暴力美学”时代,同时也以训练超大参数规模的模型能力建立起 AGI 同赛道的护城河。但在其推出 GPT-4o 的“Mini”版本之后,OpenAI 似乎走向了原有优势的反方向,开始卷“小模型”,而值得注意的是:
在 Mini 这条路上,欧洲与中国的大模型团队已经率先研究了大半年。
从 2023 年上半年智谱 AI 发布对话小模型 ChatGLM-6B,10 月 Mistral 发布 7B 模型,到 2024 年 2 月面壁智能团队祭出 2.4B 的 MiniCPM,紧接着是多模态小模型 8B MiniCPM-Llama3-V 2.5,还有商汤的 1.8B SenseChat Lite、上海人工智能实验室 OpenGV Lab 团队的 Intern-VL 系列……
基于通用大模型开发小模型或端侧模型的路线,此前已在国内发酵大半年。如今,OpenAI 等世界级头部 AI 企业的入局,更表明端侧模型、“智能小模型”是大势所趋。
GPT-4o 发布后,AI 技术大牛 Andrej Karpathy 也在推特上发表了自己对“小模型”的看法:

在 Andrej Karpathy 看来,未来将会出现参数规模小、但思考能力强的小模型;小模型才是 AI “大模型”的最终目标。
Andrej Karpathy 指出,现在的 AI 模型之所以“大”,是因为目前模型的训练仍比较粗放;换言之,即训练不高效——面壁智能团队在 3 月与 AI 科技评论的交谈中就已表达相似观点。
如何让小模型更智能?Andrej 认为关键点在于模型的知识,即训练数据。目前来看,无论是 OpenAI、还是面壁智能等团队,他们的路线都是先将模型“做大”、然后再将模型“做小”,原因在 Andrej 看来,是因为“小模型需要依托大模型来重构理想的合成数据”,直到大模型中的高质量数据被耗尽。
除数据考虑外,面壁团队还告诉 AI 科技评论,从 2023 年下半年开始,他们通过建立一套“用大模型训练小模型”的沙盒实验机制,是为了验证他们所理解的“Scaling Law”,即模型参数规模随着时间推移递减、但智能水平不断上升的“面壁定律”——大模型的智能密度每 8 个月翻一倍。
如果模型能在越小的规模上实现更高的智能,那么模型的训练与推理成本都将大幅下降。但据 AI 科技评论了解,该方向对算法与数据工程的挑战也十分巨大,中间的技术门槛并不低。
随着成本下降,英伟达的 GPU 需求量也将受到影响。有业内人士向 AI 科技评论评价,“对英伟达来说,相比 GPT-4o 或 GPT-4o mini,年底的 GPT-5 才是一个关键节点。”
同时,从商业上来看,GPT-4o mini 作为一个性价比极高的云端模型,对国内外云端 API 市场也将造成冲击,大规模的云端模型更难赚钱;相反,端侧模型将成为新的市场“显学”。
GPT-4o mini 能力揭秘
作为 GPT-4o 更小参数的简化版本,此次 GPT-4o mini 的发布意味着 OpenAI 正式“进军”多模态小模型。据官网介绍,目前,在API层面,GPT-4o mini支持128k、16k输入tokens(图像和文本),未来还将支持视频和音频的输入和输出。
但是,OpenAI 并未透露此次新模型的参数量大小。
数据显示,GPT-4o mini 在文本智能和多模态推理方面的学术基准测试中超越了 GPT-3.5 Turbo 和其他小模型,并且支持的语言范围与 GPT-4o 相同。此外, GPT-3.5 Turbo 相比,其长上下文性能也有所提高。
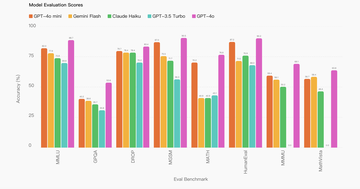
与 GPT-4 相比,GPT-4o mini 在聊天偏好上表现优于 GPT-4 ,并在大规模多任务语言理解(MMLU)测试中获得了82%的得分。公开资料介绍,MMLU 是一项包含 57 个学科大约 16000 道多项选择题的考试,得分越高的大模型在各种领域中理解和使用语言的能力越强。
从 OpenAI 提供的数据来看,GPT-4o mini 的得分为82%,Google 的 Gemini Flash得分为77.9%,Anthropic 的Claude Haiku 得分为73.8%,GPT-4o mini 能力更强:
在实现性能优化的同时,价格也更便宜。
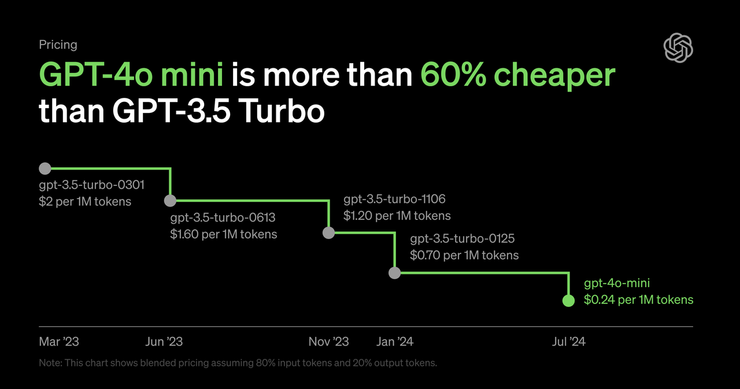
OpenAI 表示,GPT-4o mini 的成本为每百万输入标记(token)15 美分,每百万输出标记 60 美分,比 GPT-3.5 Turbo 便宜超过 60%。即日起正式向免费版、Plus 版和团队版的 ChatGPT 用户开放,企业用户则从下周开始可使用。
OpenAI 也想在小模型市场“分一杯羹”。
此前,无法承担 OpenAI 模型昂贵费用的开发者往往会选择更便宜的替代,如 Gemini 1.5 Flash 及 Claude 3 Haiku,这或许也是此次 OpenAI 推出小模型的主要原因——为开发者提供更为轻量且廉价的工具,以创建其无法负担的大模型(如 GPT-4)的应用程序和工具。
对于此次 GPT-4o mini 的推出,社交平台上外国网友们似乎存在不少不买账的声音,部分网友催促 OpenAI 发布 GPT-4o 完整版,「No one wants a cheaper 3.5. We want a better 4o.」(没有人想要更便宜的3.5,我们想要更好的4o),还有网友显然对于 GPT-4.5 以及 GPT-5 的热情更盛。
但也有国产大模型团队指出,GPT-4o mini 是相对 GPT-4o 的“Mini”版本,具体参数量不详,因此如商汤、面壁智能、上海人工智能实验室等团队难以与其比拼。
OpenAI 退出中国市场后,对国内模型团队的影响有限。一位端侧模型从业者告诉 AI 科技评论,OpenAI 在 Mini 模型上的这一举动,或许是为了响应硅谷智能硬件兴起的浪潮,同时对苹果 AI 在端侧能力上的需求作出反应。
从今年上半年开始,苹果 AI 团队相继发布其在手机端侧上运用的 AI 成果,如 Ferret-UI、OpenELM、MM1 等等,对模型落到端侧起了开头。相当于,苹果已经在手机 AI 端出了开卷考试,接下来各家模型厂商与手机厂商都要思考如何答题。
国产小模型不输 OpenAI
而根据以往成果发布,国产大模型团队在文本小模型、乃至多模态小模型上的能力也表现卓然:
今年 4 月,商汤发布了1.8B(18亿)参数规模的 SenseChat-Lite版本,作为端侧模型,交互体验对标GPT-4,当时性能已实现同等尺度性能最优。
后来,在 WAIC 期间,商汤又再次进行端侧模型的更新,较 4 月推出的版本首包耗时降低 40%,速度更快。
上海人工智能实验室 OpenGV Lab 的 InternVL 也是中国多模态小模型的系列典范。从 InternVL-Chat-V1.5 到书生万象 Intern VL 2.0,OpenGV Lab 团队开源了从多模态模型系列,参数规模从 1B 到 76B 不等,其中小模型最高 8B、最小 1B,均可单卡部署。据 AI 科技评论了解,其 1B 版本的参数规模实际只有 938 M。
值得注意的是,OpenGV Lab InternVL 系列的 26B 自开源以来一直是 Hugging Face 上的当红炸子鸡,以开源不过两周的 InternVL 2.0 为例,其 26B 在 Hugging Face 上的下载量已超过 6000 次。
同样在 Mini 模型上发力的国产代表团队还有面壁智能。他们在小模型上的成果包含基座模型与多模态模型,在 Hugging Face 上的下载量已经近 95 万次,Github 上获得超过 1 万星标,这一端侧模型系列不仅是开源社区口碑之作,甚至一度火到全网热搜第一。
今年 2 月,面壁端侧模型“小钢炮”发布,具备 GPT-3 同等性能但参数仅为24亿的 MiniCPM-2.4B ,把知识密度提高了大概 86 倍 (如下图所示):
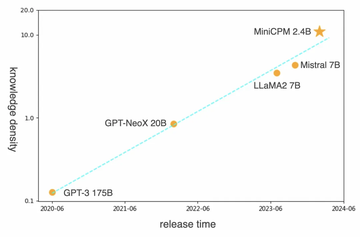
而后其又相继在 4 、5月发布了2.0和2.5 版本。在 2.5 版本上,面壁 MiniCPM 以 1% 的参数规模,形成了可以跟GPT-4V 和 Gemini Pro 多模态能力对标的性能,模型参数只有 8B 大小,能够放到终端上。
今年7月,面壁新发布的MiniCPM-S 1.2B 知识密度达到同规模稠密模型 MiniCPM 1.2B 的 2.57 倍,Mistral-7B 的 12.1 倍(如下图所示):
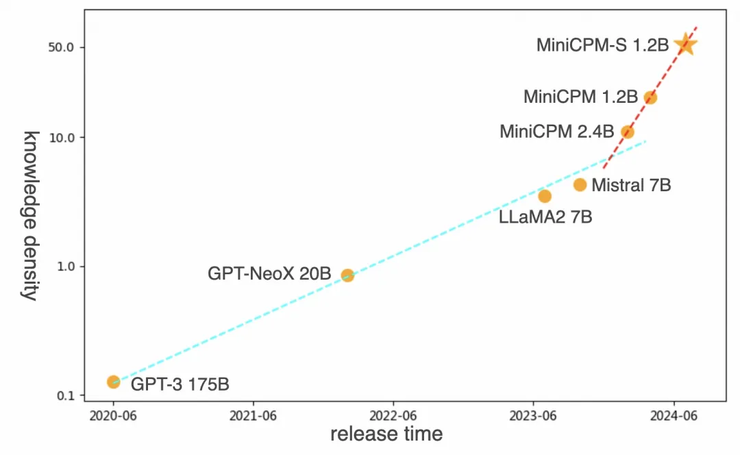
在面壁看来,他们做小模型的目标是“模型变小的同时、效果还能变好”。
当前,面壁有两条产品线,一条是基座大模型,另一条是给大模型做小模型,在小模型上验证大模型的技术极限。这两条产品线,其实是一条路,就是面壁通往 AGI 的道路,大模型与小模型难以分开。一方面,要提升模型的效率,让每个参数发挥更好的效果;另一方面,能在应用支持的成本下做出最好的模型。
而对于大模型,大众的认知普遍存在偏差,实际上,参数规模大不代表模型的能力强。
以马斯克的 Grok 为例,Grok 的参数规模为 3140 亿,行内对它的评价其实不太好,有技术人员去测过,说 Grok 的效果大概比 Mistral 的 8*7B MoE 稍微好一点。那么大参数的模型实现这么小的效果,其实是失败的。
在2021 年到 2022 年期间,国内最早做大模型的那批团队扎堆卷模型参数量,阿里甚至将模型卷到了 10 万亿参数规模(非稠密模型)。
但当时大家对“大模型能做什么”是不清楚的,只是认为“大模型就是参数要大”,在用户价值上,也并未达到后来 ChatGPT 的体验。ChatGPT 发布后,大家才意识到“提升模型效果”才是大模型训练的正确方向。
面壁认为,“小”模型的精髓在于高效,将每个参数发挥到最大作用——这才是大模型研究的正确方向。不然未来如果达到 AGI,但 AGI 比人还贵,那就没意义了。
GPT-4o mini 的发布意味着能用更少的推理算力消耗实现更强更高效的模型,这也恰恰验证了面壁提出的大模型时代的摩尔定律——模型的知识密度不断提升,其中,知识密度=模型能力 / 推理算力消耗。
小模型的“新”挑战
从年初开始,小模型的声量开始增大。小模型崛起后,无疑带来了几个行业变化:
首先,计算成本更低的 AI 模型落到终端硬件产品上的门槛更低,端侧模型兴起。在此浪潮中,模型层厂商如面壁智能、手机厂商如苹果华米OV 等也纷纷入局,端侧模型的创业也迎来更多玩家。
端侧模型虽然是“小”模型,但其智能水平也离不开一个基础的大模型,同时需要具备丰富的训练数据与完善的数据工程系统,才能做可控的训练。因此,端侧模型往往要与具体的行业与特定领域相结合。
与此同时,端侧模型需要结合模型、硬件与计算。据了解,当前主流芯片厂商在端侧 AI 芯片上的供给成本仍没打下来。一位业者告诉 AI 科技评论,某知名芯片厂商的报价是 300 美金一台设备,折算下来超过 2000 元人民币,现阶段能支撑起如此高昂的计算成本的硬件设备只有汽车、医疗等高端行业。
其次,小模型的开源社区形成后,有业者也认为,这将使“大模型的研究进入高校科研者的舒适区”。“过去大模型因为算力成本高昂,只有工业者能支撑得起,但当小模型的成本降下来后,越来越多高校科研人员也能参与这一方向的研究。”
这意味着,小模型团队的研发压力也在加大,竞争或许会变得更加激烈。
此外,也有从业者指出,OpenAI 发布 GPT-4o mini 是近日来大模型价格战的缩影。OpenAI 将云端 API 的价格打下来后,其他海内外的云端大模型厂商在 C 端应用上的压力会更大,“模应一体”的发展路径或许会迎来新的变局。
端侧大模型兴起后,端侧设备自己提供智能化的底座并且负担推理成本,且个人数据隐私有保障,一系列的应用公司借助终端设备厂商提供的智能化底座来做应用。对于用到千亿参数模型的应用,将最终也陷入推理成本的拼杀。
李大海猜测,GPT-4o mini 会是一个宽 MOE 的模型、而非一个端侧模型。“(GPT-4o mini)作为一个性价比很高的云端模型,一方面对云端 API 市场应该会造成冲击,一方面降低大模型落地产业成本,让我们对大规模行业应用的兴起抱有更强信心。”
言归正传。OpenAI 此次发布 GPT-4o mini,顶级公司的入场再一次验证了小模型的研究风向与必然趋势。在这一方向上,中国的大模型研究团队如面壁智能、上海人工智能实验室等均领先半年左右提出自己的解决,国产大模型从跟随到引领,也反应了国产大模型技术的日新月异。
“GPT-4o mini 主打的是更快,大小相对 GPT-4o 来说更加 mini。但由于 GPT-4o 参数不详,因此 GPT-4o mini 是否为端侧小模型、是否能单卡部署,仍然存疑。”一位业内人士向 AI 科技评论评价。
所以,对待国产大模型的技术成果,我们或许应该多一份“民族自信”。雷峰网雷峰网
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号