AI 真的消亡了吗?不,AIGC 为我们带来了新的期待 | 氪记 2022
发表时间: 2023-01-05 08:32
作者 | 刘雨洁、王与桐
编辑 | 石亚琼
2022 年的热门词汇有什么?AIGC 当之无愧位列其中,甚至将名列前茅。
从 5 月的 Disco Diffusion 和 DALLE2 引起的 AI 作画潮流,到 11 月的 chatGPT 在一周内完成了百万用户注册,期间海内外出现了无数个 AIGC 的产品和创业公司,共同掀起了 AI 创作的热潮。
不得不说,在整个 AIGC 浪潮中,美国一直主导着技术,并将其开源;中国的产品和技术更多在跟随美国的步伐。其实,AIGC 的概念也来自于中国本土——在美国,更常见的说法是Generative AI,即生成式AI。
其实,AIGC 是 Generative AI 的子集。因此在本文中,我们将用 GA 来统称这一年的生成式 AI 的进展。
AI 领域还有一个名词叫做 AGI(通用人工智能),可以被理解为一个强人工智能的终极目标,其目的是系统性地解决方案,执行人类能够完成的“任何”任务。而想要实现 AGI,生成式 AI 是不可或缺的一步。或者说,当下人类最有可能接近创造 AGI 的方式,就是将一个个碎片化的生成式 AI 能力,集成在一个智能平台上,来模拟 AI 的智力和高度适应性。
AGI 早在几十年前的科幻作品中就已经有了很多不同的展现形式,其共同的特点是有着强大的自然语言理解(NLU)能力,这就是今天掀起生成式 AI 风浪的主要技术。
其实,AIGC 也好,生成式 AI 也好,虽然是在今2022年获得关注,但并不是2022年才出现的。
底层技术已经默默突破了几年,之所以生成式 AI 会在2022年出现在更多普罗大众面前,归根结底是背后的技术再上了一步台阶,可以向公众发布以供广泛使用。
以大语言模型(large language models,以下简称“LLM”)为基础的 text-to-X(文本到任意)技术再在2022年有了突破性进展,分别在 text- to-image(文本到图片)、AI-generated-text(AI 生成文字)、text-to-video(文本到视频)、generative code(生成式代码)等领域出现了值得全球关注的应用。
技术在2022年取得突破性进展,并将其开源,将 AI 结果产出的时间大大缩短,产出精度更强。比如 OpenAI 所用的 GPT 技术,其 GPT1 在 2017 年就已经出现,现在 chatGPT 所采用的 GPT3.5 则是在2022年出现。
尽管从 2014 年 AlphaGO 战胜柯洁开始,人类对于 AI 就抱有最大的希望,此后不停出现“AI 元年”的说法,但过去几年,AI 的应用和底层技术都没有实现更大的突破,这又让大家对于 AI 心灰意冷。
到 2022 年,AI 成为生产工具,带来了商业化价值,或许才终将迎来“AI 元年”。

生成式AI 2022大事年表,36氪制图
在 GPT-3 发布的两年内,风投资本对 AIGC 的投资增长了四倍,在 2022 年更是达到了 21 亿美元。
正如前文所说,GA 底层技术的突破,创造出了更多细分赛道,比如 Disco Diffuison 和 Stable Diffusion 正在加快艺术创作的速度,copy.ai 和 Jasper 在通过 AI 完成文案写作,Mutable.ai 和 Github Co-pilot 以 AI Coding 的方式提高编程效率。
细分赛道越多,意味着想象空间越大。而一级市场最擅长为想象空间买单。
当然,其中一部分取得融资的公司采用的的确是时下最先锋的 GA 模型,比如种子轮获得 1.01 亿美元的 StabilityAI,但很多获得融资的公司,也不过是用以往的 AI 模型蹭上了热度而已。这加大了投资人和机构的判断难度,自然会导致一级市场在短期内,比如 2023 年的混乱。

来源:PitchBook
之所以使用最新模型的 GA 创业公司比例不高,除了一部分公司想要“走捷径”直接偷换概念外,大模型的训练,原本就是烧钱、砸人还不一定有成效的事情。以2022年先后推出 AI Art 赛道明星项目 DALLE2 和对话式 AI 爆款的 chatGPT 的母公司 openAI 来说,其大模型 GPT1 从 2017 年就开始训练,直到 GPT3 出现才逐渐变得易用、好用。而 chatGPT 之所以风靡全球,是因为其背后是比 GPT3 更高级的 GPT3.5。
根据公开资料,GPT-3 训练的仅是硬件和电力成本高达 1200 万美元(约 7500 万人民币),GPT3.5 只高不少。
如此高额的投入、大量的迭代时间,显然并不是初创公司能够完成的。
这就决定了,初创公司只能依靠开源的模型,进行在具体应用侧的创新。可是这样一来,壁垒变低,对于客户和用户来说,选项也变多了,那么应用创新的商业价值就会变低。技术价值和商业价值都不够的情况下,一级市场自然不会买单。
其实在 2022 年,就已经出现了此类现象,在国内在 AI Art 领域出现了不少用户量大的创业项目,但是融资情况并不容乐观。
2023 年或许会延续 2022 年的创投趋势:创业项目层出不穷,但是一级市场只买单有技术壁垒和商业前景的个别项目;当然,总体数量会比前些年更多。

GAmapping,来源 Leonis Capital 风险投资基金
Disco Diffusion 是在2022年 2 月初开始流行的一个 AI 图像生成程序,可以根据描述场景的关键词渲染出对应的图像,可以在 Google Drive 直接运行,也可以部署到本地运行。
但在那时,人们尚未意识到,Disco Diffusion 的出现,是 2022 年一整年 AI Art 狂热潮的开始。
图为国内最大的平面设计师社区 UISDC 上首次出现关于 Disco Diffusion 的科普文章
上图为国内最大的平面设计师社区 UISDC 上首次出现关于 Disco Diffusion 的科普文章,设计师是对图像创作工具最敏感的群体之一,彼时大多数 C 端用户还并不知道这一“黑科技”的存在,即使知道,也会因为它复杂的调试环境失去参与测试的欲望。
但之后,随着更多 AI Art 模型和工具的成熟,门槛越来越低,越来越多 C 端用户开始了解并使用相关的工具。
AI Art在2022年以来的热度,是因为一种呈现为文字转图像(text-to-image)特性的崭新交互方式,正在向大众宣告 AI Art 正在进入一个“民主化”的时代。使用文字描述,或者基于画面意象和故事,或者基于艺术家风格、构图、色彩、透视方法等专业名词,就能在数十秒内生成完整的绘画作品,这让艺术创作成为了一件像跑步一样的事:人人都会跑步,只不过是专业的人跑得更快。
还原到底层技术方面,则是一场 Diffusion 对 GAN 的彻底革新。
传统 AI Art 的的技术原理是生成对抗网络(GAN)或 VAE 等,目前,GAN 作为上一代 AI Art 工具与平台最主流的图像生成模型,在模型训练方面已经有了很大的突破,但在实际应用的过程中仍然拥有严重的结构性问题。
随着热度升温,可能会取而代之的是 Diffusion。Denoising Diffusion Models(去躁扩散模型)作为一种基于分数的生成模型,是一种非常强大的新型生成模型。其工作原理就是通过反复地向训练数据添加高斯噪声来破坏训练数据,然后通过反转添加噪声的过程来学习如何取回数据。Diffusion 还提供大量样本多样性和学习数据分布的准确模式覆盖,这意味着 Diffusion 适用于具有大量不同和复杂数据的学习模型,从而解决了 GAN 的问题。Diffusion 缓慢改变输入数据将数据映射到噪声的正向变换,通过学习的、参数化的反向过程来完成数据生成。该过程从随机噪声开始,一次一步地进行清理。

图源网络
Diffusion 对图像生成效果的提升十分显著,数字生成的痕迹也得到了有效削弱,用户自己可选执行步数,步数越多图像越精细的特点也激起了更多的“硬核”需求。

Diffusion 对图像生成步骤
这也就是为什么 AI Art 工具其实从很早之前就有了,但此前的图像效果经常会有“太假”或者不够完整等种种问题,甚至不如直接用 Photoshop 做一些风格化处理,因此这些作品也就失去了如今 Diffusion 时代作为艺术品的收藏与分享价值。
通过指数级爆发的帖子和作品展示,以 Disco Diffusion、Stable Diffusion、DALL-E2、MidJourney 这些算法和工具为代表的生成器,已经成为了 AI 生成向 C 端落地、以及更广阔的元宇宙世界的先发力量。
DALLE2 可以从自然语言的描述中创建逼真的图像和艺术,上线于 2022 年 4 月 6 日,由 OpenAI 开发。
OpenAI 在四月份推出了 DALL-E 2,DALLE2 可以从自然语言的描述中创建逼真的图像和艺术,超过 150 万用户测试了这个模型,2022年 9 月,公司将它推向了市场。
微软为 OpenAI 提供资金,以换取其作品的独家商业版权,并将该模式整合到 Azure AI-as-a-service 平台中。
作为解决了 DiscoDifusion 的技术痛点的追随者,Stability AI 也加大了赌注,于 8 月 22 日上线。并推出了开源的扩散模型(Stable Diffusion)。
StabilityAI 是一家创立于 2019 年的人工智能初创公司,总部位于伦敦,致力于构建以 AI 为技术载体的解决方案。
Stable Diffusion 是时下最先锋、也是最流行的 AI 绘画机器学习模型,由 StabilityAI 开发,Web 演示版本搭载于 AI 开源社区 Huggingface。Stable Diffusion 的预训练模型是一个文本至图像的 AI 模型。根据文本提示,Stable Diffusion 能够生成逼真的 512x512 像素的图像以描述提示中的场景。
在模型权重公开发布之前,它的代码已经发布,模型权重也有限发布给了研究社区。在最新的版本中,任何用户都可以在消费者级别的硬件中下载并运行 Stable Diffusion。除了文本至图像的生成,该模型还支持图像至图像的风格转换以及图像质量提升。在发布该版本的同时,Stable AI 还发布了 beta 版本的 API 以及模型的 Web UI,名为 DreamStudio。
Stable Diffusion 基于名为潜在扩散模型(latent diffusion models,LDMs)的图像生成技术。与其他的流行的图像合成方法不同,如生成对抗网络(generative adversarial networks,GANs)和 DALL-E 使用的自动回归技术,LDMs 通过在一个潜在表示空间中迭代“去噪”数据来生成图像,然后将表示结果解码为完整的图像。
LDM 是由 Ludwig Maximilian University of Munich 的机器视觉与学习(Machine Vision and Learning)研究组开发的,并在最近的 IEEE / CVF 计算机视觉和模式识别会议(Computer Vision and Pattern Recognition Conference)上发表的一篇论文中进行了阐述。在2022年早些时候,InfoQ 曾经报道过 Google 的 Imagen 模型,它是另一个基于扩散的图像生成 AI。
Stable Diffusion 模型支持多种操作。与 DALL-E 类似,它能够根据所需图像的文本描述,生成符合匹配该描述的高质量图像。它还可以根据一个简单的草图再加上所需图像的文本描述,生成一个看起来更逼真的图像。
Meta AI 也发布了名为 Make-A-Scene 的模型,具有类似的图像至图像的功能。
10 月 18 日,在上线不足两月的时间里,StabilityAI 获得由在 Coatue 和 Lightspeed Venture Partners 领投的 1.01 亿美元融资,投后估值超过 10 亿美元。
上线两个月就成为独角兽,足以见得市场对于 StabilityAI 以及 AI 作画的认可。这也引发了一级市场对于 AI 作画的强关注。
同样在 10 月,微软开始将由 DALLE2 提供支持的生成人工智能技术,集成到其 Bing 搜索引擎、Edge 浏览器和新的
MicrosoftDesignerforOffice。
2022 年的商业化进展:欲速则不达
由于 AI Art 在受到越来越多关注的同时,开发门槛越来越低,全球范围内 AI Art 的创业公司和产品也在 10 月、11 月密集出现。
在 11 月初打开 Product Hunt(一个发现新产品的平台,开发者可以提交自己的产品,网站会依据大众的投票数量产生每日榜单),会发现每天都有新的 AI 作画产品上线,并且这些 AI 作画产品,都在每天榜单的前几名。

2022 年 11 月 3 号,Product Hunt 榜单第一名就是 AI 作画产品

2022 年 11 月 2 号,Product Hunt 第二名是需要付费的 AI 作画产品
其中,Avatar AI 推出 10 天以来,销售额已经突破 10 万美元(销量为 2943,平均售价 33 美元)。
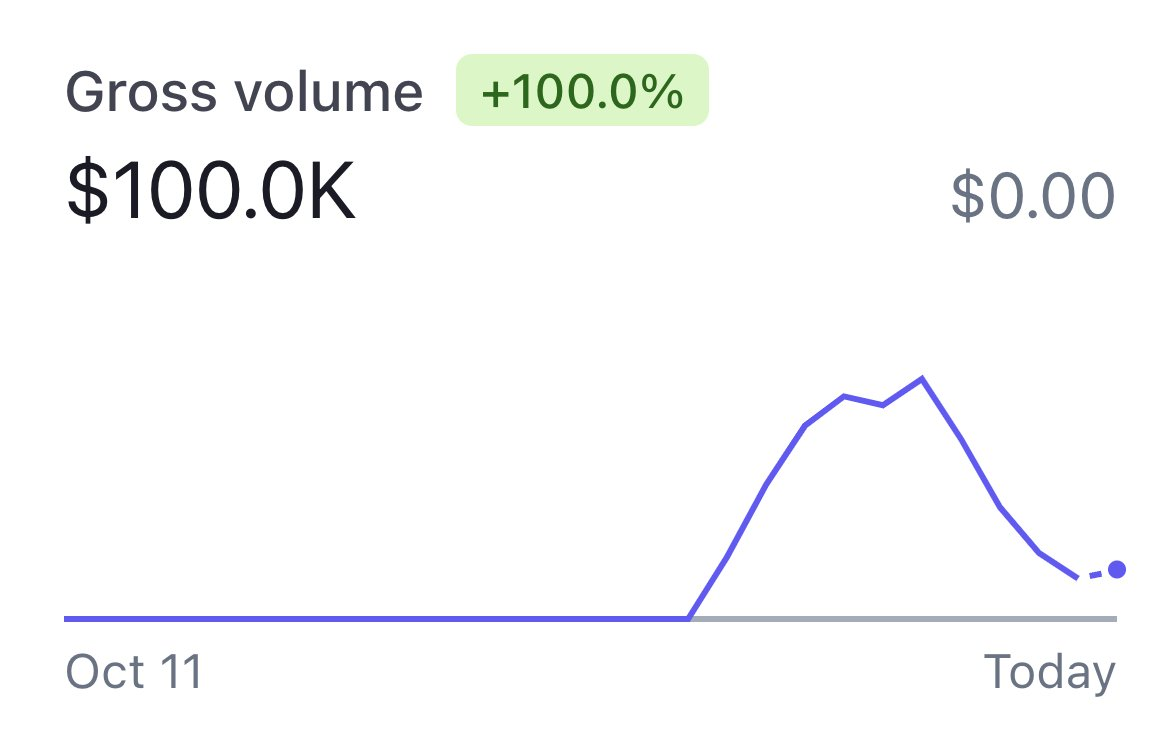
Avatar AI 销售额
不仅美国如此,在中国也是这样,盗梦师、无界、皮卡智能、TIAMAT 等也在 10~11 月里受到了广泛关注,盗梦师小程序甚至达到了日增 5 万用户的规模。
层出不穷的 AI 作画产品背后,是全球从业者和 C 端群众对于新技术的好奇和热捧。从 Google Trends 和百度指数上,在 10 月 AI 作画搜索指数的暴涨,就可见一斑。
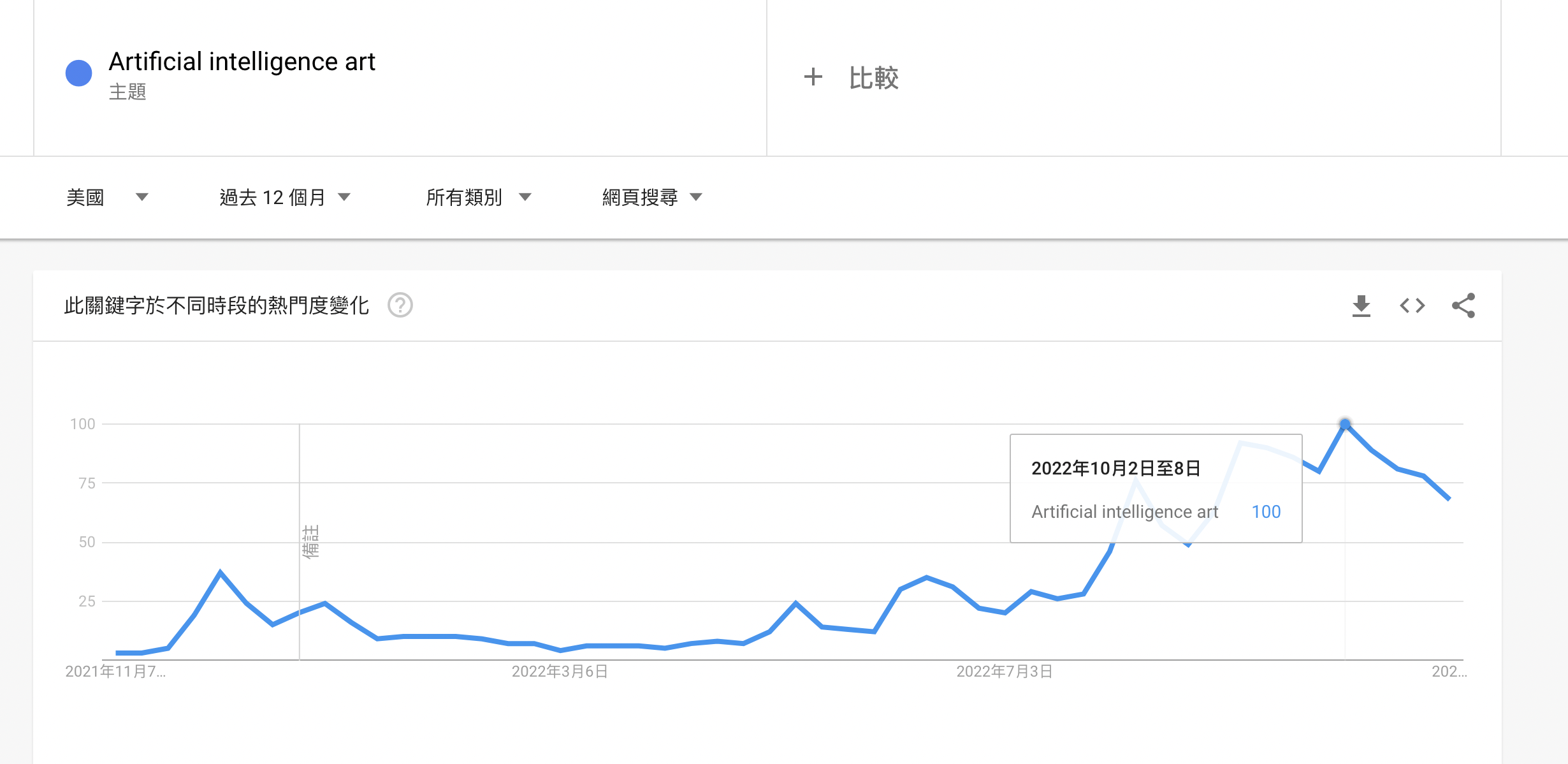
Google Trends 美国区“AI Art”热度
AI Art,火烧得太快、来得太突然,法规完善、生态体系、用户认知等等一个赛道长期发展所要具备的要素,在 AI 作画赛道都稍显空白,这或许会带来商业化短期的混乱。
一类玩家,以 Avatar AI 这类产品为例,30 美元打包一沓头像,固然能赚到快钱,但是如何在不伤害猎奇心理消费者的情况下保持长期商业价值是 Avatar AI 不得不考虑的问题。
另一类玩家,不以收费为前提,仅是提供工具免费给用户使用,那么在早期获得病毒式增长后,又该如何获得收入维持后续发展?
还有一类玩家,或许并没有明确的商业化目标,其出发点或许只是热爱,但部分 AI Art 产品已经伤害了艺术家的版权,正在全球范围内引起相关讨论。
而目前的混乱,或许是由于这个原本技术突破困难、应该有较高门槛的行业,因为开源,而变得低门槛,投机者几乎能以零成本去“追逐风口”。作为长期具有 ToC 价值的领域,开源一定程度上“放纵”了 AI Art 在商品层面的混乱。
未来,AI Art 想要获得更长久的商业发展,需要在 C 端用户有足够的认知的同时,玩家探索 toB 的商业价值。
2022年 6 月,Google 的一名工程师声称 LaMDA 可能有自己的感觉,可能“还隐藏着一个感知的心灵”。这让 LaMDA 一度陷入争议。
LaMDA 在 2021 年 I/O 大会上首次亮相,是 Google“迄今为止最先进的对话式人工智能”,即与2022年 12 月红遍全球的 ChatGPT 有着相同的语言模型技术和原生应用场景。2022 年 5 月 11 日,Google 在 2022 年 I/O 大会上公布了 LaMDA2。作为 Google 一直在研究的最先进的大数据模型之一,与 GPT-3 不同的是,LaMDA 没有被配置为执行任何特定任务,LaMDA 是“对话训练”,本质上是一个以聊天机器人为导向的 LLMs。
在引起了不少社会上的讨论后,Google 回应到:LaMDA 和公司近几年的大型 AI 项目一样,都经过了多次严格的 AI 道德方面的审核,对其内容、质量、系统安全性等进行了多方面的考量。
2022年早些时候,Google 也专门发表了一篇论文,公开了 LaMDA 开发过程当中的合规细节。其中提到,“在 AI 群体内,对于具备感知的 AI/通用 AI 的长期可能性,确实有一些研究。然而在今天把对话模型来拟人化,这样做是没有意义的,因为这些模型是没有知觉的。不过,这些系统能够基于数以百万计的句子来模仿交流的方式,并且在任何有趣的话题上都能够扯出有意思的内容。”
在 ChatGPT 赶在 2023 年到来之前意料之外地迅速爆发之后,LaMDA 只能以其竞争对手的形式在市场上被动出现。正如在另一个 AI 赛道内,Google 强大的 AI Art 模型 DreamBooth,也是几乎在 Stability AI 获得融资成为独角兽的前夕,才以一个定制化编码功能更强大的标准曝光在公众视野之下。同样,从技术上来说,LaMDA 被认为拥有“对抗 ChatGPT 所需的一切”。
在一些投资人与用户高呼 ChatGPT 能够“杀死传统搜索引擎”之后,另一群人寄托在 LaMDA 身上的希望,情节变得更加跌宕起伏。
Google 和 OpenAI 都是全球久负盛名的 AI 梦工厂,区别是前者成为科技巨头已久,且在垄断用户搜索查询流量的同时,也主导了多个 AI 生成赛道的诞生和迭代。而后者则在2022年连续推出了 DALLE2 和 ChatGPT 两个现象级生成式 AI 工具,未来几年内有望做出最庞大的 AI 生成平台。
因此,LaMDA 和 ChatGPT 的竞争更有可能是生态级别的。抛开前文所讨论的人工智能恐怖谷、科技伦理学等问题,从长期来看,作为“巨头之子”,LaMDA 的机会很可能集中在以下几点:
首先,“打败 Google 的,只可能是 Google”。就像社交帝国腾讯用微信“打败”了 QQ 一样,Google 几十年来在搜索引擎领域的绝对话语权,使其在对话式 AI 在搜索领域的应用上,也具有不可撼动的优势。
目前,Google 在搜索引擎中使用 Featured Snippets(精选片段)为用户的问题引用答案,这是其商业化手段之一,也是广受用户诟病的一点。
相比来说,ChatGPT 之所以被列入“杀死 Google 搜索”的候补名单,是因为其擅长为更复杂、更完整的问题生成答案,同时不会像 Google 一样试图将用户引导到其他页面,提供了更清爽的用户体验。但极致的用户体验有些时候也会成为商业化的阻碍,由于对话式 AI 中的“竞价广告”可能要比 Google 的 SEO 要隐蔽得多,且不直接显示数据引用来源的 AI 表面上无需对搜索结果负责,因此潜在威胁也是可想而知的。
前两天,全球最大产品发现社区 ProductHunt 上已经出现了导购项目,专门收集 ChatGPT 回答的“某一分类下最好的品牌”。如果对话式 AI 未来更加泛滥地应用于品牌营销,或者商家发明出一套规则能让自己的品牌名更多地被 AI 模型抓取,它的内容可信度会不会成为昙花一现呢?如果坚持“真实”和“专业”,又怎样实现在搜索领域的变现?
在这个问题上,LaMDA 和 ChatGPT 面对的商业化难题是一样的,但毫无疑问作为搜索巨头的 Google,会有更完善的解决方案。
其二,MUM(Multitask Unified Model,多任务统一模型)、PaLM(路径语言模型)等其他 Google 自研 AI 模型的支持和集成。ChatGPT 之所以现在看起来更像是一个工具或者“写邮件神器”,是因为技术和模型已经是时下最先进的了,服务和体验却仍然是单点维度的,距离生态利器还有很长的路要走。
而在这一点上,Google 已经有所考虑。比如,除了 LaMDA 之外,Google 还强调了 MUM 的重要性。多模式模型允许人们“跨不同类型的信息进行提问”,也就是说,将图片、音频、视频等媒介形式结合文字来提问。

Google 提供的一个搜索示例:用户给自己的登山靴拍了张照片,问“我可以穿这个登富士山吗?”MUM 则能够通过理解图像等内容和查询背后的意图进行判断,并推荐装备列表和博客文章。
目前,Google 已经将 MUM 技术添加到了 Google Lens,后者为 Google 推出的一款支持图片对象检索的现实搜索应用。
总体来说,在 LaMDA 始终位于技术前列的情况下,至少在搜索和对话式领域,Google 将比一切竞争对手都更接近产品化和商业化。
其实,AI 自然对话的能力基于对人类说话口吻的模仿,本就是为了让信息和计算从根本上更易于被人们访问和使用,这种软性提效与工业硬件升级等硬性提效的最大区别,就是它与人类的行为和语言体系是一种寄生关系。换句话说,不具备商业能力的 AI 模型代表着长期投入能力差,缺少时效性价值,从而损害“搜索”的核心价值。
早在2022年 5 月份,Google CEO Sundar Pichai 就重申了对话式自然语言处理的最大价值是“数字民主化”。至少在研发转产品的目标上,LaMDA 比2022年大多数生成式 AI 工具都要明确,那就是让 Google 搜索未来能够像人类一样回答问题。
“仓促行事对于搜索领域来说似乎并不明智,因为世界需要始终如一的正确。”
11 月 30 日,人工智能实验室 OpenAI 发布了自研的聊天机器人——ChatGPT,它比其他任何可供公众互动的聊天机器人都要先进,在聊天外,可以当成搜索引擎、论文生成器、代码生成器、翻译等多个实用角色,成为人类的生活工作助手。
其价值被广泛认可,上线 5 天后,注册人数突破百万,而到达这个数字,推特用了两年。
因为 ChatGPT 的火爆,OpenAI 在大语言训练模型领域的积累也逐渐被看到——ChatGPT采用最新的GPT3.5模型,模型中首次采用 RLHF(从人类反馈中强化学习)方式。
OpenAI 最初于 2017 年提出的 GPT1,其采取的是生成式预训练 Transform 模型(一种采用自注意力机制的深度学习模型)。GPT1 的方法包含预训练和微调两个阶段,预训练遵循的是语言模型的目标,微调过程遵循的是文本生成任务的目的。2020 年的 GPT3,训练参数是 GPT-2 的 10 倍以上,给 GPT 训练读过文字和句子后可接续问题的能力,同时包含了更为广泛的主题。
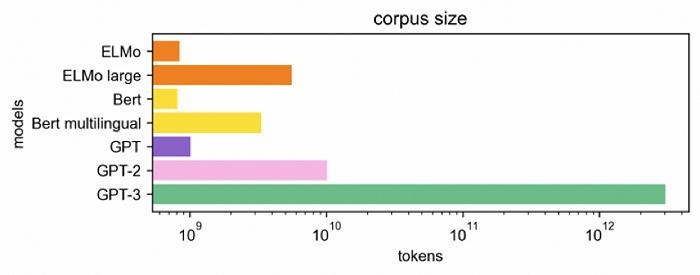
图源:Medium GPT 系列模型的数据集训练规模
现在的 ChatGPT 则是由效果比 GPT3 更强大的 GPT-3.5 系列模型提供支持,这些模型使用微软 Azure AI 超级计算基础设施上的文本和代码数据进行训练。
具体来说,ChatGPT 在一个开源数据集上进行训练,训练参数也是前代 GPT3 的 10 倍以上,还多引入了两项功能:人工标注数据和强化学习,相当于拿回了被 GPT3 去掉的微调步骤,实现了在与人类互动时从反馈中强化学习。

ChatGPT 自己回答与前代 GPT3 的能力区别
尽管目前 ChatGPT 还存在很多语言模型中常见的局限性和不准确问题,但毋庸置疑的是,其在语言识别、判断和交互层面存在巨大优势。
2022年 11 月,全球独角兽 Notion 发布了 Notion AI 的 Alpha 版本,这也是知识管理工具与生成式 AI 工具的进一步结合。
从功能上来说,Notion AI 与 ChatGPT、Jasper 等工具类似,都是根植于 LLM 在2022年的技术爆发,服务于 text-to-text 应用下的重复性或创造性写作。而从应用环境来看,Notion AI 的创新性在于,它完全融合于 Notion 文档内部,这也就意味着人工智能协作又少了一步“冷启动”的时间。
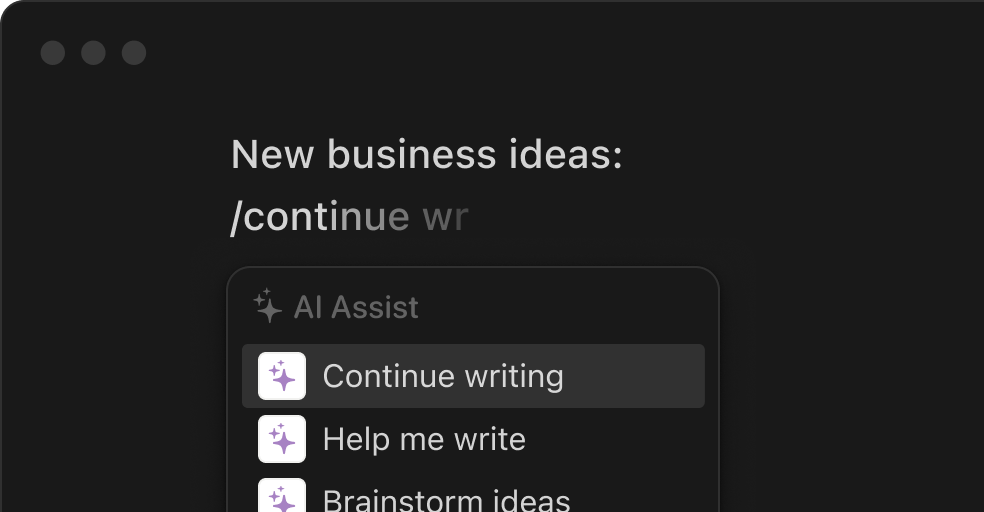
图片来自 Notion AI 官网
图片来自 Notion AI 官网,可以看出,Notion 用户在文档中输入“/”(也是 Notion 区块式笔记的基础基础逻辑)即可调用不同功能的 Notion AI,包括 Continue writing(续写)、Help me write(text-to-text 生成内容)、Brainstorm ideas(列出 bullet points)等。在功能定位上,Notion 将 AI 列为了写作助手的角色,比起 ChatGPT 更加接近 Grammarly。
其实,无论是 ChatGPT 还是 Notion AI,目前为止都还没有办法直接生成一篇原创且可发表的内容,但它们能够很好地帮助用户“跳过初稿阶段”,直接进入对文字的改进和完善阶段。与此同时,所有 LLM 的应用工具都在迅速改进,使得语义理解能够从句子到段落,再到逻辑关系更加复杂的语境,从而更好地理解和编写各种文本。
Notion AI 的机会有三点:
第一,Notion 的平台特性能够与 LLM 的技术特性更好地融合。众所周知,目前的生成式 AI 最需要的就是更多更详细的语境。在我们使用 ChatGPT 的时候,得到的文字内容经常会以“由于没有更详细的数据支持,我只能尝试理解需求”之类的声明作为开头。
而作为一个综合了笔记、项目管理等用户个人知识内容的 Workspace(工作区),Notion 为每位用户存储了大量逻辑结构和关联性更强的文本内容,比 ChatGPT 等聊天式 AI 更容易获取大量的上下文语境素材,从而实现更精准的需求理解和对于用户语言风格的模仿等。
第二,Notion AI 符合生成式 AI 目前最重要的两个竞争条件。尽管 Notion 计划“缓慢而谨慎”地推出他们的 AI 工具,但由于 AI 并不是一项一劳永逸的技术,其核心竞争壁垒来自于数据质变、用户需求理解和模型的完善性,因此用户量和在时间上占先,对于生成式 AI 来说是非常重要的两点。
作为数字协作领域的独角兽,用户量和 C 端口碑是 Notion 一直以来引以为傲的亮点。从入局时间来看,ChatGPT 在 11 月底引发了 AI 写作的全球热潮,Notion AI 与之基本同期,没有错过时间红利。
第三,存在于知识库内部的 AI 工具有更多呈现形式。从应用场景来看,以聊天机器人形式出现的 ChatGPT 似乎更像是一个用来展现技术能力的 demo,它还在寻找广泛的领域场景和合作商。与之相比,Notion 在协作领域的巨大影响力,则已经为 Notion AI 注脚好了未来的可能性。在一个巨大的知识管理工作区内部,AI 除了辅助写作的用途,还能集成搜索、连接日历与任务管理、回答用户的问题并粘贴知识库中的信息等。
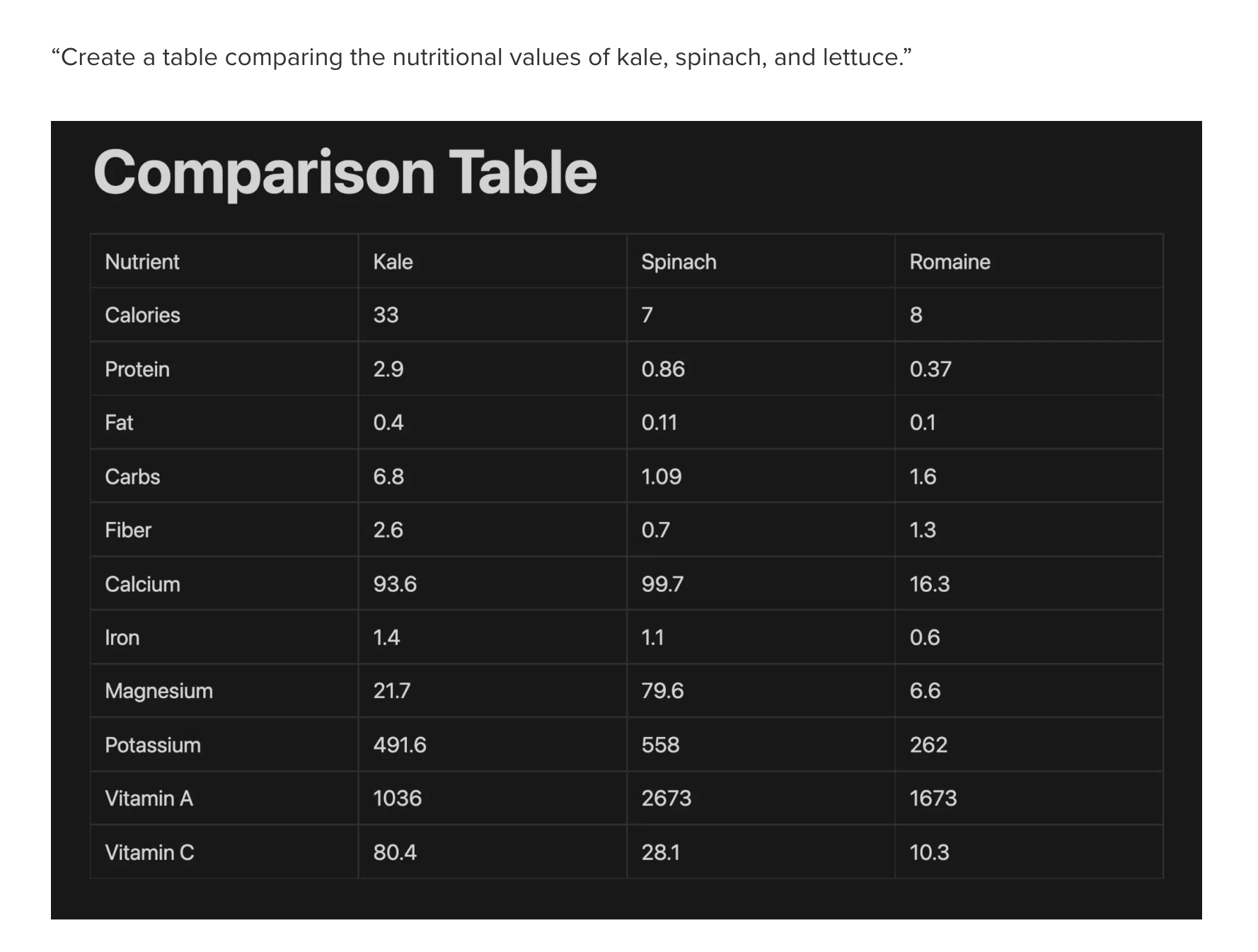
用 Notion AI 生成表格
综上,刚刚被“交到用户手中”就立刻引发了热议的 Notion AI,也让我们重新想起了 AGI 的概念。其实,Notion 本身能够从一众产品精度做得越来越“卷”的笔记应用中取得不可忽视的地位,并建立最庞大的第三方模版市场和社区,就是基于其一体化文本协作的理念和高度集成性。
虽然文本到图像的生成式 AI 是2022年 AI 领域的最大新闻之一,但“文本到视频”无疑将会接班成为 2023 年的新技术焦点。目前,在 AI 视频领域,捕捉远程依赖关系等决定性的技术仍具有挑战性,但 AI 视频在2022年年底已经实现了对于部分短视频的覆盖。2023年,也许“我们将无法区分视频是由人还是 AI 生成的。”
此外,2022年以来,生成式 AI 在影音技术方面的应用,也越来越详细地描述着元宇宙将如何出现。虽然在 C 端没有出现像 Stable Diffusion 和 ChatGPT 一样现象级的工具,且各 AI Art 厂家围绕 text-to-video 所做的布局,常常被看作是 text-to-image 的形态拓展,但在各类短视频、长视频占据用户大量时间的互联网环境下,AI 视频工具的商业化路径也要比前者清晰得多,比如应用在营销等领域。
虽然制作最好的视频总是需要创造力和人性化的触觉,但人工智能软件可以用来减少处理所占用的大量时间。
也因此,不少 Video AI 赛道的公司在2022年获得一级市场的关注。
2 月,以色列 AI 技术研发商 Hour One 宣布完成 2000 万美元 A 轮融资,该公司计划利用这笔资金扩大其自助服务平台 Reals,允许企业在几分钟内从文本中自动创建以人为主导的视频。
10 月,Descript 宣布完成了由 OpenAI 领投的新一轮融资,估值达到了 5.5 亿美金。Descript 是一家音频转录编辑器,会将音频转录下来的文字放到 Word 文档中,然后编辑人员或音频制作人可以像修文档一样剪辑音频。
12 月,图片和视频 AI 编辑软件提供商 runway 完成 5000 万美元 C 轮融资,投后估值达到 5 亿美元。
同样在 12 月,家视频搜索和分析云基础设施提供商 Twelve Labs 宣布获 1200 万美元种子轮追加融资,该公司推出一套云原生 API,可与该公司的人工智能视频搜索工具集成,使开发人员能够对海量视频进行搜索。
不过,抛去对于技术层在2023年能够实现爆发的乐观预期,如果基于文本的视频生成模型仍然需要 1-2 年才能达到以假乱真的效果,那么此类模型也许需要 2-3 年才能在商业应用和企服领域真正发挥作用。在此之前,这些模型可能适用于对保真度和可控性要求较低的场景,如 C 端用户在娱乐创作平台上的猎奇式创作。
当今世界,毫无疑问不仅仅由物理世界组成,由代码组成的互联网世界已经成为人类赖以生存的世界之一,这从中美等各个国家互联网公司位列前沿的市值可见一斑。
因此,AI 编写代码也被倾注了最大的期望。
AI 对工业的“妄图染指”,开启了 AI 在良莠不齐的生产环境中漫长的应用过程,而这也是 AI 回报周期过长的原因之一。由于人类只能从已经存在的历史中去提炼参照系,在被称为“信息革命”、“数字革命”的新世纪洪流中,代码一直以来所对应的就是像蒸汽、电力一样的工业生产力新单位。
不过,与以往不同,开发在科技世界的构建中比以往的工人取得了更高的地位和经济话语权。随着数字经济的发展,编程人才逐渐被细化到各行各业、各个技术体系中去,从价值层级来分,他们的工作也可以被拆分为创造和解决需求两个部分。
近年来,随着科技门槛一再降级,每当有 CRM、无代码等看似“反程序员价值”的产品出现,人们就会热议“程序员的工作很快就要被替代了”。2022年跟随 LLM 掀起水花的 AI Coding 也是同理。
在过去,这种“不再被需要”也许只是一种乌托邦式的幻想或自嘲,大多数人都明白,更多的数字生产力被解放,就会有更多的创造导向型领域出现人才缺口。可直到2022年,飘荡在全球互联网上空的裁员危机,似乎是在倒逼着这一口号重新回到了从业者的焦虑范围内。
AI Coding 则正是在这种情况下开始小规模地应用于业界。
2022年 2 月,DeepMind 推出了 AlphaCode,这是一款用 12 种编程语言对 8600 万个程序进行预训练的 Transformer,并针对编码竞赛的内容进行了微调。
通过推理,它产生了一百万种可能的解决方案,并过滤掉了不佳的解决方案。通过这种方式,它在 10 次编程竞赛中击败了一半以上的参赛者。
6 月,GitHub 开放了 Copilot 的访问权限,这是一个能够实时提供代码建议的自动完成系统。虽然学生和经过验证的开源开发者可以免费访问,但用户需要支付订阅费。
11 月,“万能助手”chatGPT 出现,不少用户开始尝试用 chatGPT 编写代码。像简单的 shell 脚本,makefile 等,ChatGPT 确实能处理,但更复杂的编程需求,chatGPT 会给出错误答案。开发者可以把 AI 生成的代码拿来进行修改,以节省时间。
但同时,AI coding 的隐患也在随着技术门槛降低而攀升。
The Register 的一份报告显示,斯坦福大学计算机科学家发现,与完全靠自己做事的程序员相比,使用 Github Copilot 等人工智能编码工具的程序员创建的代码安全性较低。
除了已经暴露出的版权问题、安全隐患之外,AI 编程还有很多已知或未知的痛点,比如提高了人才筛选难度,
比起 AI Art、AI 写作等领域,AI 编程主要有如下三个特点:
1. 其应用环境往往不是 C 端用户的猎奇心理和“科技民主化”的目的,而是用于实际的工作项目中,准确性要求更高,对版权等商业信息更敏感;
2. 编写结果可能会涉及到复杂的函数,无法像 AI Art 一样让任何人都能够以肉眼判断,有较大的应用和试错成本;
3. 编程本身可以说是一个比较庞大复杂的母领域,而是多个语言领域的泛概念,因此所针对的领域、需求和实现难度也不同。
这些特点决定了 AI Coding 在短期内会更多地用于科技巨头的内部构建,并且由于代码是这些公司的主要商业资产,其内部孵化或投资的项目,可能并不会被竞争对手所接受。虽然目前以 DeepMind 为代表的头部服务商呼声很高,但 AI Coding 本质来说也并不是一件具有技术壁垒的事,大公司各筑城池的局面不难想象。
此外,由于 AI Coding 和无码化趋势的现阶段目的,同样都是为企业的 IT 部门解放生产力,其对于大多数业务类型的公司来说,降本增效的空间也难免会被进行对比。AI Coding 虽然是自动生成代码,但其商业逻辑也是主要服务于程序员,目前还很难做到离开“人脑”工作。就像 AI Art 在热潮退去之后,也会逐渐成为艺术家等专业人员的灵感工具一样。
但其降本矛盾在于,如果是 freelancer 或独立开发者,AI Coding 工具毫无疑问能够帮助他们提高效率,但大多数程序员作为企业员工,可能自身并不会愿意被“人工智能”间接降薪。但从长期来看,随着数字经济下的编程基础教育进一步完善,各类开发工程师的分工也趋于细化,届时 AI Coding 将大有可为。只不过,这一点希冀很难惠及到即将到来的 2023 年。
相比来说,无码化工具的出现则是为了解构程序员的价值和工作属性。毕竟在程序员普遍“高薪”的情况下,在同一个业务需求下,把程序员换成业务运营人员,至少在人力方面就已经做到了降本。
不过,好消息是,2022 年的最后一个季度,AlphaCode 等 AI 编码工具似乎遭受了前所未有的业界争议。在科技和创投界,法律、商业、社会道德对于新生事物的争议通常代表着希望,虽然 AI 编码在2023年也不可能直接代替那些“螺丝钉型”码农,但大面积的智能优化代码服务,可能会成为另一个企业服务的热点。
没有一家巨头缺席 LLM,更加说明了 LLM 进入较为成熟的阶段。
11 月 15 日,Meta 公司发布大型语言模型 Galactica,并宣称它“可以总结学术论文,解决数学问题,生成维基百科文章,编写科学代码,标记分子和蛋白质,以及更多功能。”
但上线仅 3 天,该模型就在巨大争议中撤回。它虽然能生成一些貌似通顺的学术文本,但文本中的信息是完全错误的——貌似合理的化学方程,描述的是实际上并不会发生的化学反应;格式合规的引文参考的是子虚乌有的文献;甚而种族主义、性别歧视的观点,也能通过模型生成的文本而被包装成 " 科学研究 "。
Google 于去年推出“LaMDA”(对话应用程序语言模型)。LaMDA 是 Google 一直在研究的最先进的 LLMs 之一,与 GPT-3 不同的是,它没有被配置为执行任何特定任务,LaMDA 是“对话训练”。
它本质上是一个以聊天机器人为导向的 LLMs,2022年 6 月,Google 的一名工程师声称 LaMDA 可能有自己的感觉,可能“还隐藏着一个感知的心灵”。这让 LaMDA 一度陷入争议。
由于 LaMDA 仍处于封闭测试阶段,只有少数用户可以使用,因此关于它的性能几乎没有披露。但是 LaMDA 只有 1370 亿个参数,与前面讨论的 GPT-3 的 1750 亿个参数相差甚远。虽然用于训练 LLMs 的数据量并不是其性能和准确性的唯一驱动因素,特别是考虑到 GPT-3 和 LaMDA 是为不同的功能而创建的,但两者中参数数量的差异确实引起了人们对 LaMDA 是否是 ChatGPT 或广义上的 GPT-3 的有力竞争者的更大审查。
LaMDA 证明了 Google 在 LLM 竞赛中并没有完全出局。
2021 年 10 月,微软和英伟达正式推出由 DeepSpeed 和 Megatron 驱动的 Megatron-Turing 自然语言生成模型(MT-NLG),声称有 5300 亿参数,在当时宣传这是训练的最大最强的解码语言模型。不过在2022年并没有取得更新的进展。
微软在生成式 AI 方面始终参与度不低。2022年大火的 chatGPT,其背后模型 GPT3.5 就是在微软 Azure AI 超算基础设施(由英伟达 V100GPU 组成的高带宽集群)上进行训练,同时微软在考虑对 OpenAI 进行新一轮投资。

图源网络
国内,互联网大厂也走在大模型训练的前沿,各大厂在超大规模 AI 模型训练的爆发主要集中在 2021 年,国内超大模型研发虽然比国外公司晚,但是发展却异常的迅速。在2022年,也有一些进展。
百度文心大模型已经形成“模型层+工具与平台层+产品与社区层”的整体布局,于2022年全新发布 11 个大模型,包括 5 个基础大模型、1 个任务大模型、5 个行业大模型;全面升级文心大模型开发套件、文心 API;新发布和升级基于文心大模型的 2 大产品,AI 作画产品“文心一格”和产业级搜索系统“文心百中”。
去年,阿里达摩院先后发布多个版本的多模态及语言大模型,在超大模型、低碳训练技术、平台化服务、落地应用等方面实现突破。其中使用 512 卡 V100 GPU 实现全球最大规模 10 万亿参数多模态大模型 M6,同等参数规模能耗仅为此前业界标杆的 1%,极大降低大模型训练门槛。2022年 9 月,阿里巴巴 fault 最新「通义」大模型系列,其打造了国内首个 AI 统一底座,并构建了通用与专业模型协同的层次化人工智能体系。
近年来,大型语言模型的参数数量保持着指数增长势头。据预测,OpenAI 开发中的最新大型语言模型 GPT-4 将包含约 100 万亿的参数,与人脑的突触在同一数量级。由此,出现了一个新的人工智能口号:" 规模就是一切 "。
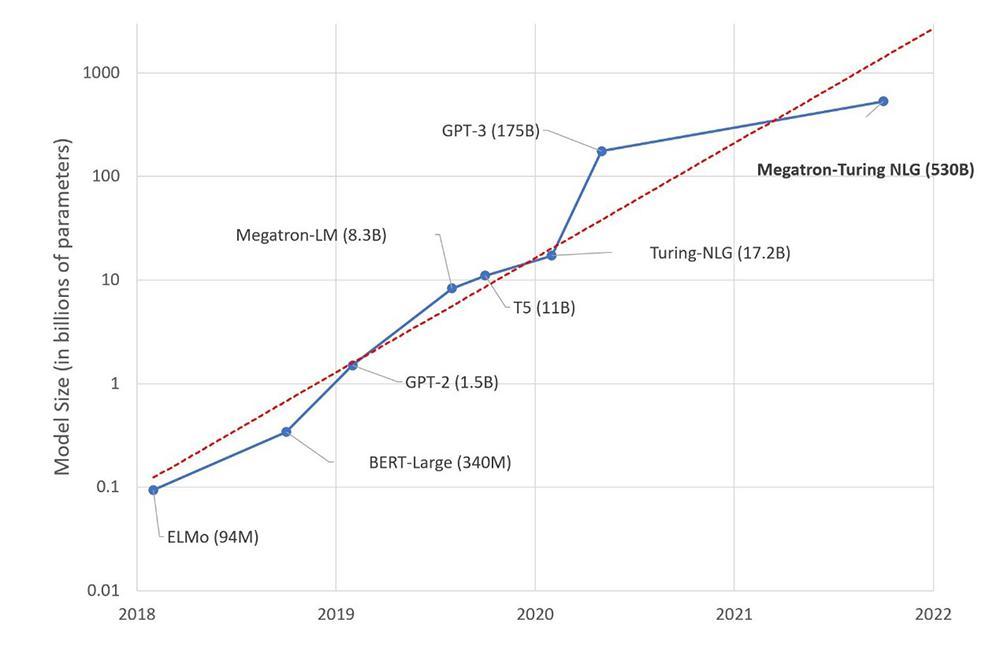
大数据模型花销
在生成式 AI 技术取得突破性进展、应用井喷式出现、用户与其距离越来越近的 2022,我们不得不关心,GA 到底是未来 AI 进入人类生活的开始,还是如此前一样昙花一现。
目前,不少人对生成式 AI 的质疑主要在以下几点:
1、现在 AI 的生成内容大多数还达不到直接商用的标准,仍然需要大量的模型微调,以及人的行业经验的辅助、补充、加工。
2、AI 生成控制方式相对普通人来说,还有一定门槛。
3、AI 的生成结果在版权方面存在模糊性。
4、行业过热,会导致不成熟的 AI 激增,良莠不齐的应用和鱼龙混杂的市场很可能会让 C 端用户和企业客户失去判断信心,同时带来数据安全隐患。
但以上问题只能限制生成式 AI 无法在短期内成为普惠的技术,并不代表生成式 AI 没有价值。其评判标准应该是,AI 技术能否变现,能否带来商业价值,使其成为一个成熟的产业。
在技术方面,2023 年,更好的基础模型值得期待,比如能够以更高效或更紧凑的方式表示复杂数据的稀疏模型。它可以更快计算且需要更少的内存来储存,从而带来成本上的进一步普惠化。除此之外,更精准的数据收集能力也意味着在审核、消除偏见信息等方面投入更大的努力。
在2022年,技术开源尽管带来了一些不必要的混乱,但毋庸置疑,这也让更多原本没有能力的开发者加入了战场,加快了生成式 AI 的商业化步伐。
在目前最大的、每天更新的 AI 应用目录 FUTUREPEDIA 网站里可以发现,目前最受关注的 AI 应用多是文本生成和图片生成相关的应用。这和2022年的风口趋势一致。
36氪截图于2022年12月底
但同时我们也注意到,在文本和图像之外,最受关注的 AI 应用,是市场营销工具。如果说文本、图像应用是普适的、不对 toBtoC 进行区分的应用方向,那么市场营销是商业价值更加明确的 toB 方向。
FUTUREPEDIA 营销方面的应用
或许我们可以判断,生成式 AI 接下来一年的商业化进展,将有三条路:
一,成为用户量足够大的 C 端工具,如 Google,依靠流量赚钱;
二,成为足够好用的细分工具,如 Adobe,靠特定人群的固定需求赚钱;
三,成为特定赛道的企业服务软件,比如服务营销、开发等需求量极大的赛道。
无论是哪条路,在2022年都已有雏形和早期沉淀。
时间不对
是不是商业化应用没有突破更准确些?
这个点文章没有证明
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号