Redis原理揭秘:干货分享!
发表时间: 2018-10-17 00:08
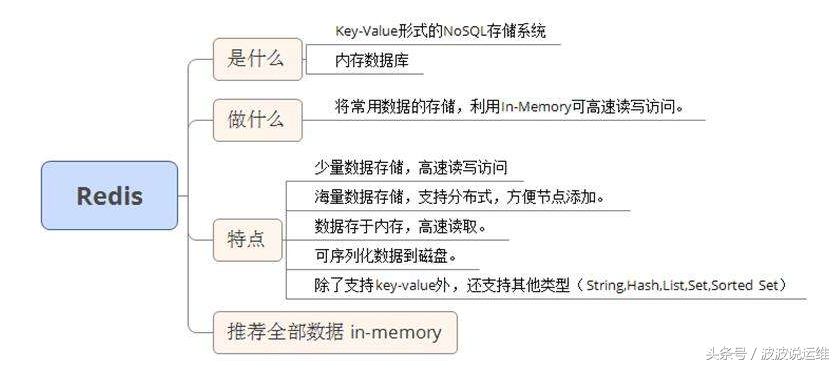
总结一下redis的原理,适合大家以后装逼!
单点TPS达到8万/秒,QPS达到10万/秒。
string、list、set、map(hash)、stored-set
1、能表达3种类型:字符串、整数和浮点数。根据场景相互间自动转型,并且根据需要选取底层的承载方式
2、value内部以int、sds作为结构存储。int存放整型数据,sds存放字节/字符串和浮点型数据
1、list类型的value对象内部以linkedlist或ziplist承载。当list的元素个数和单个元素的长度较小时,redis会采用ziplist实现以减少内存占用,否则采用linkedlist结构
2、linkedlist内部实现是双向链表。在list中定义了头尾元素指针和列表的长度,是的pop/push操作、llen操作的复杂度为O(1)。由于是链表,lindex类的操作复杂度仍然是O(N)
3、ziplist的内部结构
所有内容被放置在连续的内存中。其中zlbytes表示ziplist的总长度,zltail指向最末元素,zllen表示元素个数,entry表示元素自身内容,zlend作为ziplist定界符
rpush、rpop、llen,复杂度为O(1);lpush/pop操作由于涉及全列表元素的移动,复杂度为O(N)
1、map又叫hash。map内部的key和value不能再嵌套map了,只能是string类型:整形、浮点型和字符串
2、map主要由hashtable和ziplist两种承载方式实现,对于数据量较小的map,采用ziplist实现
3、hashtable内部结构
主要分为三层,自底向上分别是dictEntry、dictht、dict
dictEntry:管理一个key-value对,同时保留同一个桶中相邻元素的指针,一次维护哈希桶的内部连
dictht:维护哈希表的所有桶链
dict:当dictht需要扩容/缩容时,用于管理dictht的迁移
redis是单线程处理请求,迁移和访问的请求在相同线程内进行,所以不会存在并发性问题
4、ziplist内部结构
和list的ziplist实现类似。不同的是,map对应的ziplist的entry个数总是2的整数倍,奇数存放key,偶数存放value
1、set以intset或hashtable来存储。hashtable中的value永远为null,当set中只包含整数型的元素时,则采用intset
2、intset的内部结构
2.1、核心元素是一个字节数组,从小到大有序存放着set的元素
2.2、由于元素有序排列,所以set的获取操作采用二分查找方式实现,复杂度O(log(N))。进行插入时,首先通过二分查找得到本次插入的位置,再对元素进行扩容,再将预计插入位置之后的所有元素向右移动一个位置,最后插入元素,插入复杂度为O(N)。删除类似
1、类似map是一个key-value对,但是有序的。value是一个浮点数,称为score,内部是按照score从小到大排序
2、内部结构以ziplist或skiplist+hashtable来实现
1、将本次事务涉及的所有key注册为观察模式
2、执行只读操作
3、根据只读操作的结果组装写操作命令并发送到服务器端入队
4、发送原子化的批量执行命令EXEC试图执行连接的请求队列中的命令
5、如果前面注册为观察模式的key中有一个货多个,在EXEC之前被修改过,则EXEC将直接失败,拒绝执行;否则顺序执行请求队列中的所有请求
6、redis没有原生的悲观锁或者快照实现,但可通过乐观锁绕过。一旦两次读到的操作不一样,watch机制触发,拒绝了后续的EXEC执行
redis主要提供了两种持久化机制:RDB和AOF;
1、RDB
默认开启,会按照配置的指定时间将内存中的数据快照到磁盘中,创建一个dump.rdb文件,redis启动时再恢复到内存中。
redis会单独创建fork()一个子进程,将当前父进程的数据库数据复制到子进程的内存中,然后由子进程写入到临时文件中,持久化的过程结束了,再用这个临时文件替换上次的快照文件,然后子进程退出,内存释放。
需要注意的是,每次快照持久化都会将主进程的数据库数据复制一遍,导致内存开销加倍,若此时内存不足,则会阻塞服务器运行,直到复制结束释放内存;都会将内存数据完整写入磁盘一次,所以如果数据量大的话,而且写操作频繁,必然会引起大量的磁盘I/O操作,严重影响性能,并且最后一次持久化后的数据可能会丢失;
2、AOF
以日志的形式记录每个写操作(读操作不记录),只需追加文件但不可以改写文件,redis启动时会根据日志从头到尾全部执行一遍以完成数据的恢复工作。包括flushDB也会执行。
主要有两种方式触发:有写操作就写、每秒定时写(也会丢数据)。
因为AOF采用追加的方式,所以文件会越来越大,针对这个问题,新增了重写机制,就是当日志文件大到一定程度的时候,会fork出一条新进程来遍历进程内存中的数据,每条记录对应一条set语句,写到临时文件中,然后再替换到旧的日志文件(类似rdb的操作方式)。默认触发是当aof文件大小是上次重写后大小的一倍且文件大于64M时触发;
3、当两种方式同时开启时,数据恢复redis会优先选择AOF恢复。一般情况下,只要使用默认开启的RDB即可,因为相对于AOF,RDB便于进行数据库备份,并且恢复数据集的速度也要快很多。
4、开启持久化缓存机制,对性能会有一定的影响,特别是当设置的内存满了的时候,更是下降到几百reqs/s。所以如果只是用来做缓存的话,可以关掉持久化。
redis集群(redis cluster)
1、redis3以后,节点之间提供了完整的sharding(分片)、replication(主备感知能力)、failover(故障转移)的特性
2、配置一致性:每个节点(Node)内部都保存了集群的配置信息,存储在clusterState中,通过引入自增的epoch变量来使得集群配置在各个节点间保持一致
3、sharding数据分片
将所有数据划分为16384个分片(slot),每个节点会对应一部分slot,每个key都会根据分布算法映射到16384个slot中的一个,分布算法为slotId=crc16(key)%16384
当一个client访问的key不在对应节点的slots中,redis会返回给client一个moved命令,告知其正确的路由信息从而重新发起请求。client会根据每次请求来缓存本地的路由缓存信息,以便下次请求直接能够路由到正确的节点
分片迁移:分片迁移的触发和过程控制由外部系统完成,redis只提供迁移过程中需要的原语支持。主要包含两种:一种是节点迁移状态设置,即迁移钱标记源、目标节点;另一种是key迁移的原子化命令
4、failover故障转移
故障发现:节点间两两通过TCP保持连接,周期性进行PING、PONG交互,若对方的PONG相应超时未收到,则将其置为PFAIL状态,并传播给其他节点
故障确认:当集群中有一半以上的节点对某一个PFAIL状态进行了确认,则将起改为FAIL状态,确认其故障
slave选举:当有一个master挂掉了,则其slave重新竞选出一个新的master。主要根据各个slave最后一次同步master信息的时间,越新表示slave的数据越新,竞选的优先级越高,就更有可能选中。竞选成功之后将消息传播给其他节点。
5、集群不可用的情况:
集群中任意master挂掉,且当前master没有slave。
集群中超过半数以上master挂掉。
上面很多内容毫无意义,平时不会怎么用到,也记不住,但是却是大家需要了解的...
说句实在,还是值得收藏的!
后期会分享更多运维DBA和devops内容,感兴趣的朋友可以关注下!

声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号