Redis知识全解析,你掌握了多少?
发表时间: 2020-06-09 22:00

来源:数据分析与开发
本文约2806字,建议阅读8分钟。
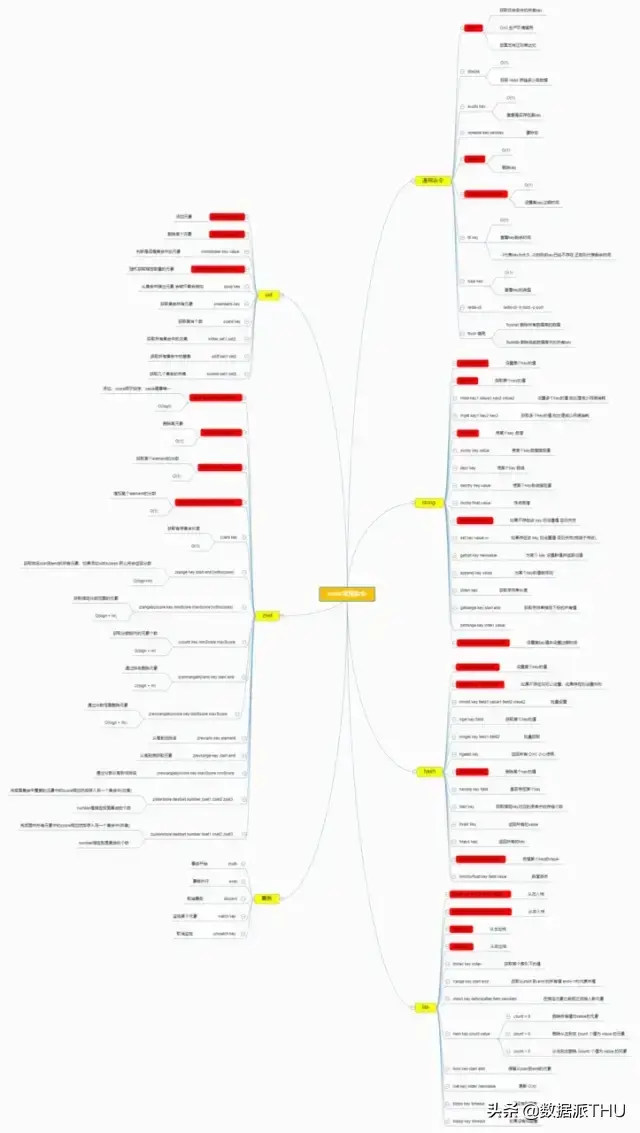
本文介绍Redis的通用命令及其五种基本数据类型等,希望对读者能有帮助。
Redis 是 开源,内存 中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。它支持多种类型的数据结构,如 字符串strings, 散列 hashes, 列表 lists, 集合 sets, 有序集合 sorted sets 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。
Redis 还内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
嗯,没错这就是 redis 中文官方网站上面的介绍,简洁明了。
我们知道 redis 是一种非关系型数据库 NoSQL 。而为什么出现 NoSQL?NoSQL 又是什么呢?
在一个网站访问量不大的时候,我们使用一个数据库就足以应对流量请求。
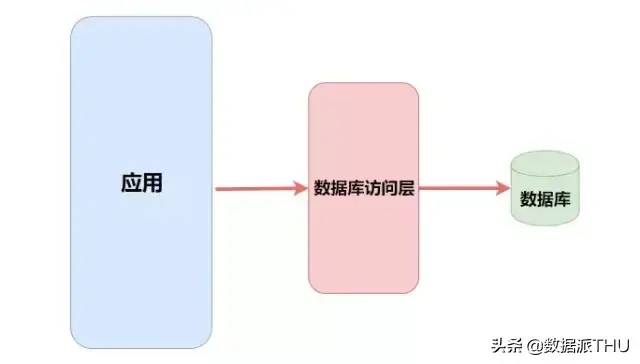
随着访问量的上升,一个数据库已经不能满足我们的需求了。为了更高的性能,我们在中间加上了一个缓存层并且将数据库做了集群、结构优化和读写分离。
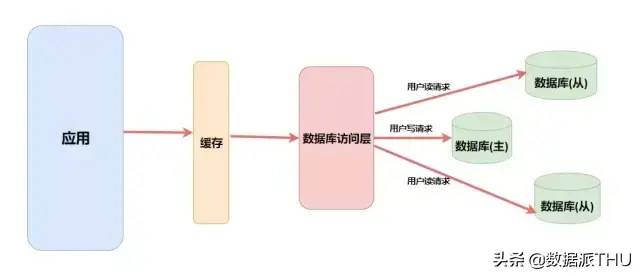
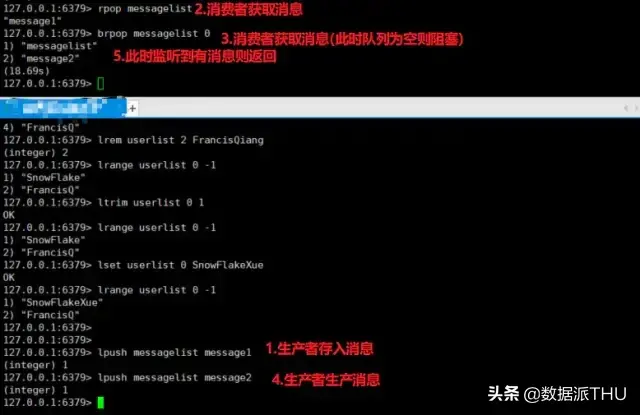
而这里的缓存就是 NoSQL,当然做缓存也只是 NoSQL 的一种功能,就像 Redis 并不仅仅有缓存这一种功能。比如它还能实现 简单的消息队列,解决Session共享,计数器,排行榜,好友关系处理 等等功能,可见 Redis 是一个非常强大工具,让我们来学习它吧!
首先我们抛开数据类型来讲关于 Redis 的通用命令。
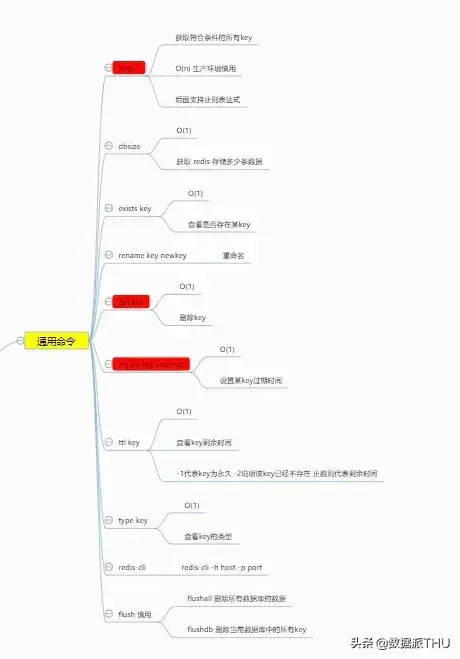
Redis 是一种 key value 存储的缓存数据库,所有的数据都有一个自己唯一的key。
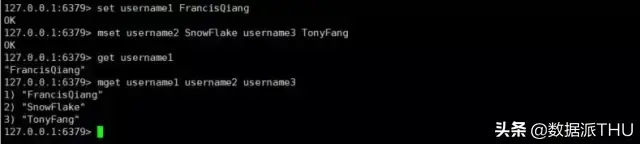
这里为了方便演示,我使用了字符串相关的设置命令

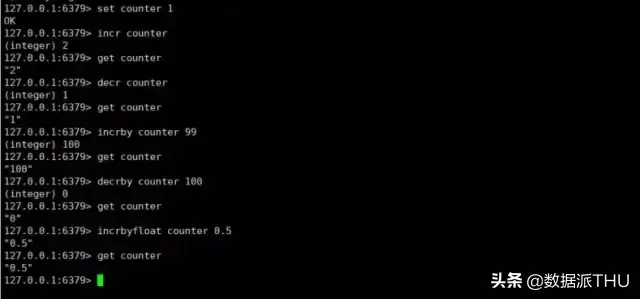
Redis 中很多数据都是用来作为缓存数据的,而作为缓存就需要有过期时间,在 Redis 中提供了很强大的过期时间设置功能。

在上面我说到了很多 Redis 作为缓存能实现的其他功能,比如计数器,排行榜,好友关系等,这些实现的依据就是靠着 Redis 的数据结构。在整个 Redis 中一共有五种基本的数据结构(还有些高级数据结构以后会讲),他们分别是 字符串strings, 散列 hashes, 列表 lists, 集合 sets, 有序集合 sorted sets。在绝大部分编程语言中都有 String 字符串类型,对于作为数据库的 Redis 也是必不可少的。



其实我们可以理解 hash 为 小型 Redis ,Redis 在底层实现上和 Java 中的 HashMap 差不多,都是使用 数组 + 链表 的二维结构实现的。
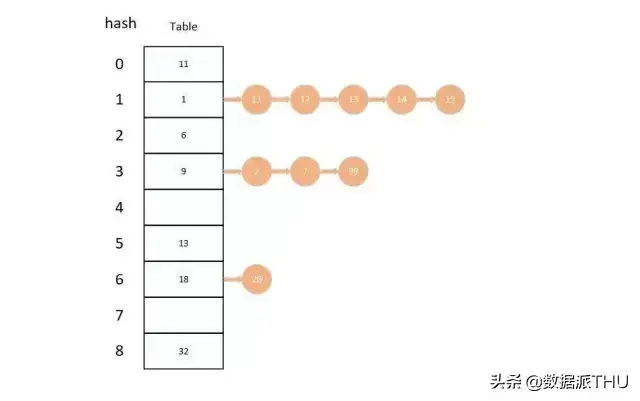
不同的是,在 Redis 中字典的值只能是字符串,而且他们 rehash 的方式不一样,在 Redis 中使用的是 渐进式rehash 。
在 rehash 的时候会保留新旧两个 hash 字典,在数据迁移的时候会将旧字典中的内容一点一点迁移到新字典中,查询的同时会查询两个 hash 字典,等数据全部迁移完成才会将新字典代替就字典。
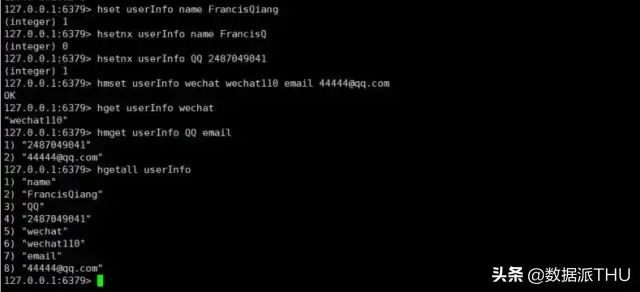
下面我们来看一下关于 hash 的基本操作。


Redis 中的列表相当于 Java 中的 LinkedList(双向链表) ,也就是底层是通过 链表 来实现的,所以对于 list 来说 插入删除操作很快,但 索引定位非常慢。

Redis 提供了许多对于 list 的操作,如出,入等操作,你可以充分利用它们来实现一个 栈 或者 队列。

下面我们来看一下关于 list 的基本操作。
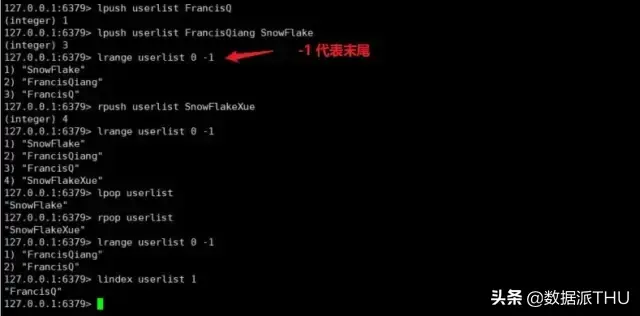
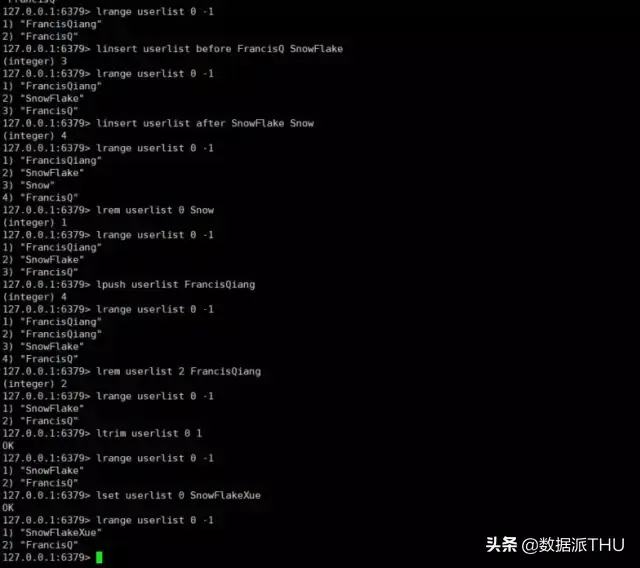
总结来说我们可以使用 左入又出或者右入左出 来实现队列,左入左出或者右入右出 来实现栈。
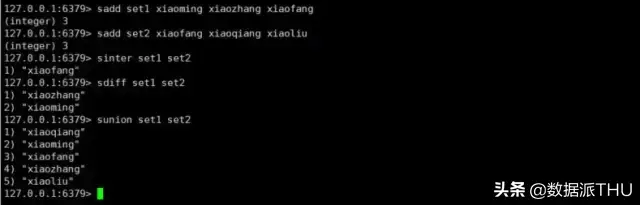
Redis 中的 set 相当于 Java 中的 HashSet(无序集合),其中里面的元素不可以重复,我们可以利用它实现一些去重的功能。我们还有对几个集合进行取交集,取并集等操作,这些操作就可以获取不同用户之间的共同好友,共同爱好等等。

下面我们就来看一下关于 set 的一些基本操作。
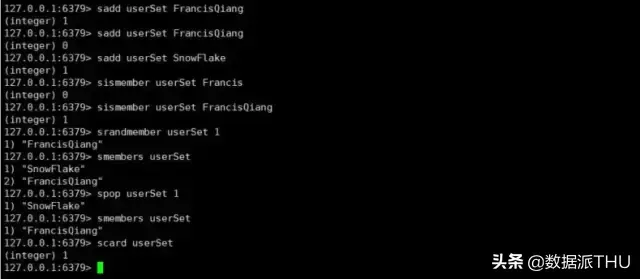
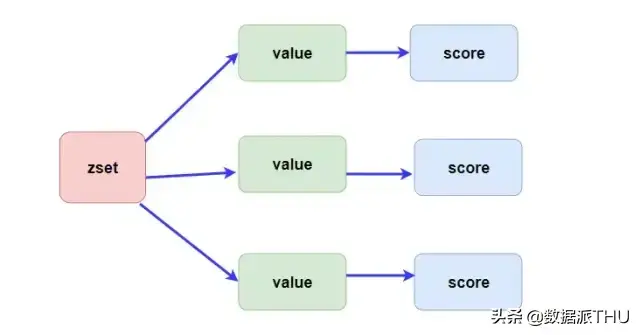
Redis 中的 zset 是一个 有序集合,通过它可以实现很多有意思的功能,比如学生成绩排行榜,视频播放量排行榜等等。
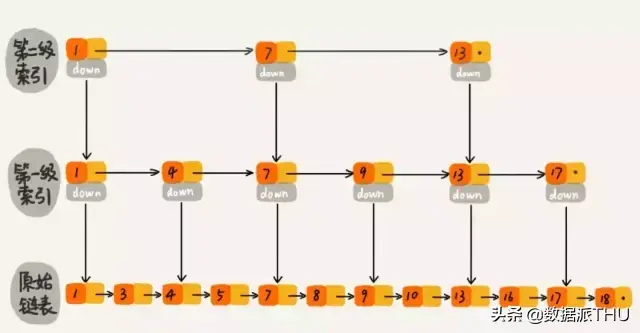
zset 中是使用 跳表 来实现的,我们知道只有数组这种连续的空间才能使用二分查找进行快速的定位,而链表是不可以的。跳表帮助链表查找的时候节省了很多时间(使用跳的方式来遍历索引来进行有序插入),如果不了解跳表的同学可以补习一下。
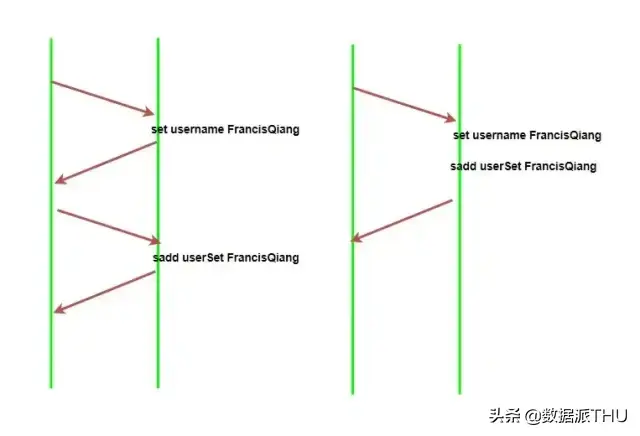
在某些场景下我们在一次操作中可能需要执行多个命令,而如果我们只是一个命令一个命令去执行则会浪费很多网络消耗时间,如果将命令一次性传输到 Redis 中去再执行,则会减少很多开销时间。
但是需要注意的是 pipeline 中的命令并不是原子性执行的,也就是说管道中的命令到达 Redis 服务器的时候可能会被其他的命令穿插。
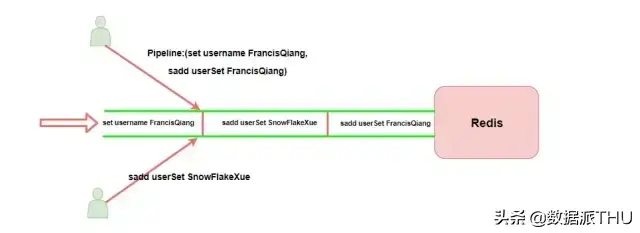
关系型数据库具有 ACID 特性,Redis 能保证A(原子性)和I(隔离性),D(持久性)看是否有配置 RDB或者 AOF 持久化操作,但无法保证一致性,因为 Redis 事务不支持回滚。
我们可以简单理解为 Redis 中的事务只是比 Pipeline 多了个原子性操作,也就是不会被其他命令给分割,如上图。


大图:
https://user-gold-cdn.xitu.io/2019/11/8/16e49e23acdfe101
好了,这就是这篇文章全部的内容了,对于 Redis 你还有多少遗忘的或者没学习到的呢?
—完—
想要获得更多数据科学领域相关动态,诚邀关注清华-青岛数据科学研究院官方微信公众平台“ 数据派THU ”。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号