除了使用EXPLAIN,还有哪些方法可以分析MySQL索引?
发表时间: 2020-08-18 14:56

作者 | adrninistrat0r
责编 | 夕颜
出品 | CSDN(ID:CSDNnews)

对于非数据库开发人员而言,难以对MySQL源码进行分析或调试,接近一个黑盒,但MySQL提供了一些命令及系统状态变量,可对索引及其他内容进行分析。掌握这些方法后,可以尽量深入地了解MySQL的一些实现细节。

通过以下方法,可以获得MySQL索引相关的数据,便于分析与理解索引相关的问题。
参考
https://dev.mysql.com/doc/refman/5.6/en/slow-query-log.html 。
慢查询日志中包含的SQL语句,其执行时间超过long_query_time(系统参数)秒,并且至少检查min_examined_row_limit(系统参数)行。
获取初始锁的时间不包含在执行时间中。mysqld(MySQL服务器)在SQL语句执行且释放所有锁之后,将一条语句写入慢查询日志中,因此日志顺序可能与执行顺序不同。
long_query_time系统参数的最小值为0,默认值为10(秒)。将慢查询日志记录到文件时,写入的时间包括微秒部分。将慢查询日志记录到表,仅写入整数时间,微秒部分将被忽略。
默认情况下,慢查询日志是禁用的。slow_query_log系统参数可以设置慢查询日志是否启用,参数值为0或OFF表示禁用,1或ON表示启用。
slow_query_log_file系统参数用于设置日志文件名称,默认值为“[主机名]-slow.log”。MySQL服务器会在data目录中创建文件,除非通过绝对路径名指定了其他目录。
log_output系统参数用于设置通用查询日志与慢查询日志的输出位置。其值为一个或多个逗号分隔的单词组成的列表,可选值为TABLE,FILE及NONE。
当指定TABLE时,表示将日志记录到名为mysql的系统数据库的general_log与slow_log表中;
当指定FILE时,表示将日志记录到文件中;
NONE表示禁用日志。
不使用索引对行进行查找的查询,需要在启用
log_queries_not_using_indexes系统变量后,才会在写入慢查询日志时被包含进去。该系统默认为关闭。
查询缓存处理的查询不会被MySQL服务器记录。
为了通过慢查询日志记录查询语句的准确耗时,需要将慢查询日志保存至文件,log_output系统参数需要设置为FILE。
慢查询日志文件中,每条语句生成的记录都有一行以#开头的数据,并包含以下字段(所有字段在一行中显示):
Query_time
语句执行时间,单位为秒;
Lock_time
获取锁的时间,单位为秒;
Rows_sent
发送给客户端的行数;
Rows_examined
MySQL服务器层检查的行数(不包含存储引擎内部的处理)。
慢查询日志文件中的每个语句之前都有一个SET语句,该SET语句包括一个时间戳,代表该慢查询语句的记录时间。
为了开启慢查询日志,需要修改MySQL服务器使用的配置文件的“[mysqld]”节点对应的系统参数,修改配置文件并重启MySQL服务器程序后生效。(通过“set GLOBAL 系统变量=xxx”命令修改慢查询日志相关参数时,未生效。)
系统参数设置如下所示:
slow_query_log = 1long_query_time = 0min_examined_row_limit = 1
设置“slow_query_log = 1”,以开启慢查询日志。
设置“long_query_time = 0”,将每次的查询语句都记录至慢查询日志文件中。
设置“min_examined_row_limit = 1”,可以使explain语句不出现在慢查询日志中,因为explain语句的Rows_examined为0。
slow_query_log = 1long_query_time = 0
慢查询日志文件默认生成在安装目录的data目录中。
使用可视化数据库管理工具连接MySQL时,可能会定时发送请求,也会生成在慢查询日志文件中。
慢查询日志内容示例如下:
# Time: 200311 19:25:39# User@Host: test[test] @ localhost [127.0.0.1]# Thread_id: 3 Schema: testdb QC_hit: NoQuery_time: 0.015360 Lock_time: 0.001452 Rows_sent: 5222 Rows_examined: 5222use testdb;SET timestamp=1583925939;select id,cust_info from test_table_log where cust_info='1881';
经测试,以上Query_time时间仅包含MySQL服务器执行查询操作的耗时,不包含客户端展示数据的耗时。
通过以下所述的方法,可以获取SQL语句执行时,读取的索引次数及方法,但不会显示读取了哪个索引。
参考
https://dev.mysql.com/doc/refman/5.6/en/show-status.html 。
SHOW STATUS语句提供服务器状态信息。该语句不需要任何特权,只要能连接到服务器即可。
SHOW STATUS语句用法如下所示:
SHOW [GLOBAL | SESSION] STATUS [LIKE 'pattern' | WHERE expr]
SHOW STATUS语句接受可选的作用域修饰符,可为GLOBAL或SESSION:
当指定作用域为GLOBAL时,SHOW STATUS显示全局的状态值。全局状态变量可以表示服务器本身某些方面的状态,或者表示MySQL所有连接的汇总状态。如果某个变量没有全局值,则显示会话值;
当指定作用域为SESSION时,SHOW STATUS显示当前连接的状态变量值。如果某个变量没有会话值,则显示全局值。LOCAL是SESSION的代名词;
如果没有指定作用域,默认使用SESSION。
每次调用SHOW STATUS语句都会使用一个内部临时表,并增加全局Created_tmp_tables值。
SHOW STATUS语句支持LIKE子句,仅显示变量名称与指定模式匹配的行。
参考
https://dev.mysql.com/doc/refman/5.6/en/server-status-variables.html 。
与读取索引次数相关的服务器状态变量以“HANDLER_READ”开头,如下所示:
Handler_read_first
索引中第一个条目的读取索引次数。如果该数值很高,则表明服务器正在执行很多全索引扫描(例如,SELECT col1 FROM foo,假设col1列存在索引);
Handler_read_key
基于索引键读取行的请求数(即通过索引读取行的数量)。如果该数值很高,则表明表的索引很合适查询;
Handler_read_last
读取索引中最后一个键的请求数。使用ORDER BY时,服务器将发出一个first-key请求(对应Handler_read_first),然后发出多个next-key(对应Handler_read_next)请求;使用ORDER BY DESC时,服务器将发出一个last-key(对应Handler_read_last)请求,然后发出多个previous-key(对应Handler_read_prev)请求;
Handler_read_next
按索引键顺序读取下一行的请求数。当对索引列使用范围约束进行查询,或进行索引扫描时,该数值会增加;
Handler_read_prev
按索引键顺序读取上一行的请求数。这种读取方法主要用于优化ORDER BY … DESC;
Handler_read_rnd
基于固定位置读取行的请求数。当执行很多需要对结果进行排序的查询时,该数值会很高。可能有很多查询需要MySQL扫描整个表,或者联接未正确使用索引键;
Handler_read_rnd_next
读取数据文件下一行的请求数(即通过全表扫描读取行的数量)。当进行大量全表扫描时,该数值会变高。通常这表明表未正确建立索引,或者编写的查询未利用索引。
当需要获取当前会话的SQL语句读取索引次数,可以执行SHOW STATUS查看以“HANDLER_READ”开头的服务器状态变量(以下执行命令中的HANDLER_READ大小写不限):
SHOW STATUS LIKE 'HANDLER_READ%';
若需要使以上数值重置,可以重新连接MySQL服务器(创建新的会话),或重启MySQL服务器程序。
在以下示例中,test_table_log表的create_time字段存在单列索引,id列为主键。
执行以下语句时,需要读取索引中第一个记录,Handler_read_first值加1。
select * from test_table_log order by create_time limit 1;
执行以下语句时,需要读取索引中的最后一个记录,Handler_read_last值加1。
select * from test_table_log order by create_time desc limit 1;
执行以下语句时,需要基于索引读取行,Handler_read_key值加1。
select * from test_table_log where create_time = '2020/3/10 12:23:38' limit 1;
执行以下语句时,需要基于索引读取行,Handler_read_key值加1;并需要根据索引读取后续9行,Handler_read_next值增加9。
select * from test_table_log where create_time = '2020/3/10 12:23:38' limit 10;
执行以下语句时,共查询到4条记录需要基于索引读取行,Handler_read_key值加1;并需要根据索引读取后续行,Handler_read_next值增加4。
select * from test_table_log where id >= 'testtime1583814037num1' and id <= 'testtime1583814037num1000'
执行以下语句时,需要读取索引中第一个记录,Handler_read_first值加1;并需要根据索引读取后续9行,Handler_read_next值增加9。
select * from test_table_log order by create_time limit 10;
执行以下语句时,需要读取索引中的最后一个记录,Handler_read_last值加1;并需要根据索引读取之前的9行,Handler_read_prev值增加9。
select * from test_table_log order by create_time desc limit 10;
执行以下语句时,需要通过全表扫描读取数据文件中的行,数量为110,Handler_read_rnd_next值增加110。
select * from test_table_log limit 100,10;
执行以下语句时,需要通过全表扫描读取数据文件中的行,Handler_read_rnd_next值增加超过110;并需要对查询到的10条记录进行排序,Handler_read_rnd值增加10。
select a.* from(select * from test_table_log limit 100,10) as a order by a.create_time;
参考
https://dev.mysql.com/doc/refman/5.6/en/status-table.html 。
INFORMATION_SCHEMA.GLOBAL_STATUS与
INFORMATION_SCHEMA.SESSION_STATUS表与“SHOW GLOBAL STATUS”及“SHOW SESSION STATUS”命令显示对应的信息。查询示例如下:
select * from INFORMATION_SCHEMA.SESSION_STATUSwhere VARIABLE_NAME like 'HANDLER_READ%' and VARIABLE_VALUE <> '0'order by cast(VARIABLE_VALUE as UNSIGNED INTEGER) desc;
当从上述表查询数据获取SQL语句读取索引次数时,会导致Handler_read_rnd_next变量值增大;当使用排序时,还会导致Handler_read_rnd变量值增大。因此需要获取SQL语句读取索引次数时,不通过上述数据库表查询。
InnoDB缓冲池中索引页与记录数,可以反映MySQL在执行SQL语句时,将指定表的索引读取到缓冲池中的索引页及记录数量。
若需要重置InnoDB缓冲池相关数据,需要重启MySQL服务器程序(未找到其他方法清空InnoDB缓冲池)。
参考
https://dev.mysql.com/doc/refman/5.6/en/innodb-information-schema-buffer-pool-tables.html 。
InnoDB INFORMATION_SCHEMA缓冲池表提供了缓冲池状态信息,以及有关InnoDB缓冲池页面的元数据。
InnoDB INFORMATION_SCHEMA缓冲池表中包含INNODB_BUFFER_PAGE,该表保存InnoDB缓冲池中每个页的信息。
查询INNODB_BUFFER_PAGE或INNODB_BUFFER_PAGE_LRU表可能会影响性能,应避免在生产环境查询。
参考
https://dev.mysql.com/doc/refman/5.6/en/innodb-buffer-page-table.html 。
INNODB_BUFFER_PAGE表中包含以下关注的字段:
POOL_ID
缓冲池ID。是用于区分多个缓冲池实例的标识符。
SPACE
表空间ID。
PAGE_NUMBER
页编号(page number)。
PAGE_TYPE
页的类型。例如“INDEX”代表B+树节点,“BLOB”代表未压缩的BLOB页等。
TABLE_NAME
页所属的表名。该列仅适用于PAGE_TYPE值为INDEX的页。
INDEX_NAME
页所属的索引名。可以是聚簇索引或二级索引的名称。该列仅适用于PAGE_TYPE值为INDEX的页。
NUMBER_RECORDS
页的记录的数量。
2.3.3. 从INNODB_BUFFER_PAGE表获取InnoDB缓冲池中索引页与记录数
从INNODB_BUFFER_PAGE表中可获取InnoDB缓冲池中索引页与记录数,table_name字段的形式为“`[数据库名]`.`[表名]`”。
查询的示例语句如下,page_num为指定表的指定索引在InnoDB缓冲池中的页的总数,record_num为指定表的指定索引在InnoDB缓冲池中记录的总数:
select TABLE_NAME,INDEX_NAME,count(*) as page_num,sum(NUMBER_RECORDS) as record_numfrom INFORMATION_SCHEMA.INNODB_BUFFER_PAGEwhere table_name = '`testdb`.`test_table_log`'group by TABLE_NAME,INDEX_NAMEorder by page_num desc;
查询结果如下所示:
InnoDB对索引页的操作包括读取、创建及写入等。
若需要重置上述数据,需要重启MySQL服务器程序。
参考
https://dev.mysql.com/doc/refman/5.6/en/server-status-variables.html 。
MySQL服务器状态中,包含以下与InnoDB索引页操作次数相关的状态:
Innodb_buffer_pool_pages_data
InnoDB缓冲池中包含数据的页数。该数量包含脏页与非脏页。
Innodb_pages_created
对InnoDB表操作创建的页数。
Innodb_pages_read
对InnoDB表操作,从InnoDB缓冲池读取的页数。
Innodb_pages_written
对InnoDB表操作导致被写的页数。
使用SHOW STATUS获取InnoDB索引页操作次数时,可执行以下语句:
SHOW STATUS LIKE 'Innodb_pages_%';SHOW STATUS LIKE 'Innodb_buffer_pool_pages_data';
参考
https://dev.mysql.com/doc/refman/5.6/en/innodb-buffer-pool-stats-table.html 。
INFORMATION_SCHEMA.INNODB_BUFFER_POOL_STATS表提供了许多与“SHOW ENGINE INNODB STATUS”输出相同的缓冲池信息。
上述表包含以下关注的列:
DATABASE_PAGES
InnoDB缓冲池中包含数据的页数。该数量包含脏页与非脏页。
与“SHOW STATUS”输出中的
Innodb_buffer_pool_pages_data相同。
NUMBER_PAGES_READ
读取的页数。
与“SHOW STATUS”输出中的Innodb_pages_read相同。
NUMBER_PAGES_CREATED
创建的页数。
与“SHOW STATUS”输出中的Innodb_pages_created相同。
NUMBER_PAGES_WRITTEN
写入的页数。
与“SHOW STATUS”输出中的Innodb_pages_written相同。
从上述表获取InnoDB索引页操作次数示例语句如下(查询操作不会导致以上参数变化):
select DATABASE_PAGES, NUMBER_PAGES_READ, NUMBER_PAGES_CREATED, NUMBER_PAGES_WRITTEN from INFORMATION_SCHEMA.INNODB_BUFFER_POOL_STATS;
2.4.3. 使用SHOW ENGINE STATUS获取InnoDB索引页操作次数(不使用)
参考
https://dev.mysql.com/doc/refman/5.6/en/show-engine.html 。
“SHOW ENGINE”显示指定存储引擎的操作信息。执行时需要“PROCESS”权限。
“SHOW ENGINE INNODB STATUS”显示来自标准InnoDB监控器的有关InnoDB存储引擎状态的大量信息。
以上输出信息全部包含在Status字段中,无法进行过滤,不方便单独查看Pages read, created, written等参数。
参考
https://dev.mysql.com/doc/refman/5.6/en/index-page-merge-threshold.html ,频繁发生页分裂可能对性能产生影响。
2.5.1.
INFORMATION_SCHEMA.INNODB_METRICS表
参考
https://dev.mysql.com/doc/refman/5.6/en/innodb-metrics-table.html 。
INFORMATION_SCHEMA.INNODB_METRICS表提供了InnoDB的各种性能信息。
每个监控器代表InnoDB源代码中用于收集计数器(counter)信息的位置。每个计数器可被启动、停止及重置。
默认情况下,收集的数据比较少。为了启动、停止及重置计算器,需要对系统变量innodb_monitor_enable、innodb_monitor_disable、innodb_monitor_reset或innodb_monitor_reset_all进行设置。
INFORMATION_SCHEMA.INNODB_METRICS表包含以下关注的列:
NAME
计数器的唯一名称;
COUNT
计数器启用后的计数值;
STATUS
enabled代表计数器在执行,disabled代表已停止;
COMMENT
计数器描述。
在查询
INFORMATION_SCHEMA.INNODB_METRICS表时,需要有PROCESS权限。
在
INFORMATION_SCHEMA.INNODB_METRICS表中,存在NAME为“index_page_splits”,COMMENT为“Number of index page splits”的记录,即索引页分裂次数对应的计数器,COUNT列为索引页分裂次数。
select count from INFORMATION_SCHEMA.INNODB_METRICS where name='index_page_splits';
参考
https://dev.mysql.com/doc/refman/5.6/en/innodb-information-schema-metrics-table.html 。
全局变量innodb_monitor_enable、innodb_monitor_disable可分别用于启用、禁用记数器。命令如下所示:
SET GLOBAL innodb_monitor_enable = index_page_splits;
SET GLOBAL innodb_monitor_disable = index_page_splits;
innodb_monitor_enable变量还可以MySQL配置文件的[mysqld]节点进行配置,可使用半角逗号对多项进行分隔。innodb_monitor_disable不支持在MySQL配置文件配置。
经验证,对以上系统变量进行设置时,需要有SUPER权限(root用户)。
参考
https://dev.mysql.com/doc/refman/5.6/en/explain-output.html 。
EXPLAIN语句提供有关MySQL如何执行语句的信息。EXPLAIN适用于SELECT,DELETE,INSERT,REPLACE和UPDATE语句。
EXPLAIN为SELECT语句中使用的每个表返回一行信息。输出中的表的顺序,与MySQL在处理语句时读取表的顺序一致。
EXPLAIN输出的列及含义如下所示:
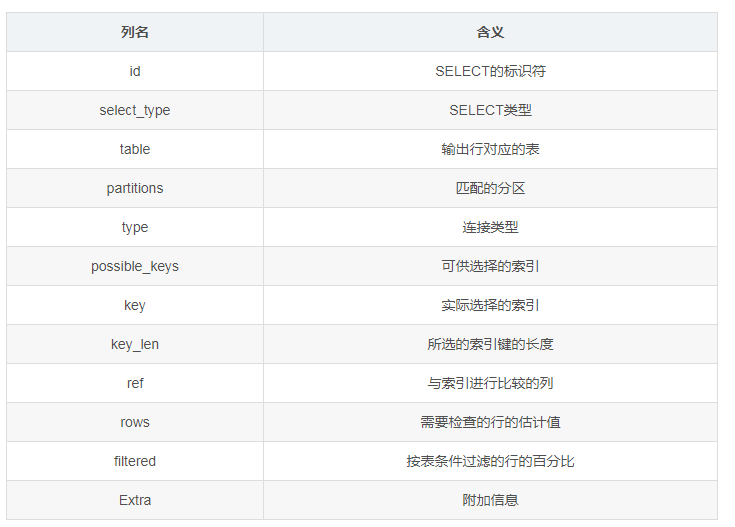
id列为SELECT的标识符,其值为查询中SELECT的顺序号。
即id列反映了SELECT在执行时的顺序(从小到大)。
select_type列为SELECT的类型,select_type值及含义如下所示:
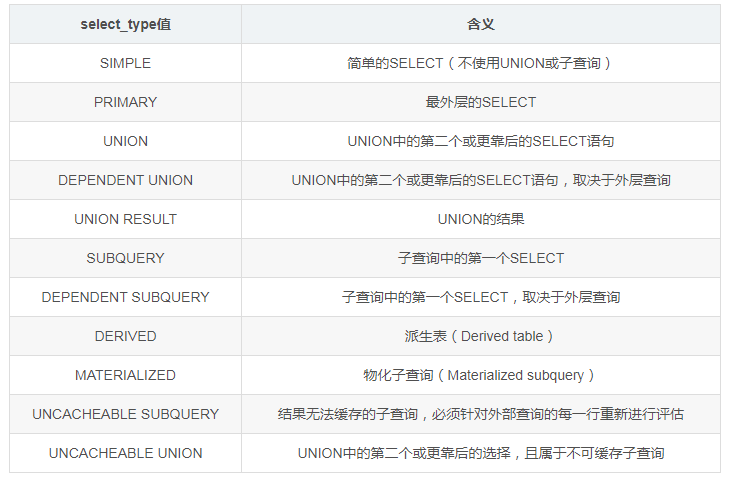
DEPENDENT通常表示使用了相关子查询(correlated subquery)。
type列为连接类型,描述了表的连接方式。不同的连接类型如下所示:
system
表只有一行(系统表)。system是const连接类型的特例。
const
查询的开头读取的表,最多只有一行匹配。因为只有一行,优化器的其余部分可以将此行中对应列的值视为常量。
const连接类型对应的表查询非常快,因为它们只读取一次。
将主键或唯一索引的所有部分与常量值进行比较时会使用const连接类型。
在以下示例中,tbl_name表可以作为const连接类型使用:
SELECT * FROM tbl_name WHERE primary_key=1;
SELECT * FROM tbl_name WHERE primary_key_part1=1 AND primary_key_part2=2;
eq_ref
对于先前的表的每种行组合,从eq_ref连接类型对应的表中读取一行。除了system和const连接类型外,eq_ref是最好的联接类型。当连接使用索引的所有部分并且索引是主键或非空唯一索引时,将使用eq_ref连接类型。
eq_ref可用于使用=运算符进行比较的索引列。比较值可以是常量,也可以是使用在此表之前读取的表中列的表达式。
在以下示例中,MySQL可以使用eq_ref连接类型处理ref_table表:
SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;
ref
对于先前的表的每种行组合,从ref连接类型对应的表读取所有具有匹配索引值的行。
如果连接仅使用索引键的最左前缀或者索引键不是主键或唯一索引(即连接不能基于索引键值选择单行),则使用ref连接类型。
如果使用的键只匹配少量几行,则ref是一个好的连接类型。
ref连接类型可用于使用=或<=>运算符进行比较的索引列。
在以下示例中,MySQL可以使用ref连接类型处理ref_table表:
SELECT * FROM ref_table WHERE key_column=expr;
SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;
fulltext
使用全文索引执行连接。
ref_or_
ref_or_与ref类似,区别在于使用ref_or_时,MySQL对包含值的行进行了额外搜索。
ref_or_连接类型最常用于解决子查询。
在以下示例中,MySQL可以使用ref_or_连接类型处理ref_table表:
SELECT * FROM ref_table WHERE key_column=expr OR key_column IS ;
index_merge
index_merge连接类型表示使用了索引合并优化。在这种情况下,输出行中的key列包含使用的索引列表,key_len列包含所用索引的最长键部分列表。
unique_subquery
unique_subquery连接类型在某些使用IN的子查询的情况下替代eq_ref,如下所示:
value IN (SELECT primary_key FROM single_table WHERE some_expr)
unique_subquery只是一个索引查找函数,可以完全替代子查询以提高效率。
index_subquery
index_subquery连接类型与unique_subquery类似,它替代了IN子查询,支持子查询中的非唯一索引,如下所示:
value IN (SELECT key_column FROM single_table WHERE some_expr)
range
range连接类型表示仅检索给定范围内的行,使用索引选择行。
EXPLAIN输出行中的key列表示使用哪个索引。key_len列包含使用的最长的索引键部分。对于此连接类型,ref列为。
使用=,<>,>,> =,<,<=,IS ,<=>,BETWEEN,LIKE或IN运算符中的任何一个将索引键列与常量进行比较时,可以使用range类型。
index
index连接类型与ALL类型类似,区别在于index连接类型有对索引树进行扫描。有两种方式:
a. 如果查询的索引是覆盖索引,并且可满足所需表的所有数据,则仅扫描索引树。在这种情况下,Extra列显示“Using index”。仅扫描索引通常比ALL连接类型快,因为索引的大小通常小于表数据。
b. 对指定索引读取数据,进行全表扫描,以按索引顺序查找数据行。Extra列不会显示“Using index”。
当查询仅使用属于单个索引一部分的列时,MySQL可以使用此连接类型。
ALL
对之前的表中的每个行组合进行全表扫描。
如果当前表是第一个没有标记为const的表,这通常是不好的,并且通常在所有其他情况下非常糟糕。
通常,可以通过添加索引来避免ALL连接类型,这些索引基于常量值或先前的表的列值,启用从该表的行检索。
possible_keys列表示MySQL可以选择用于查找此表的行的索引。请注意,此列于EXPLAIN输出中显示的表的顺序完全独立。
假如possible_keys列为,说明没有相关的索引。
key列表示MySQL实际决定使用的索引键。如果MySQL决定使用其中一个possible_keys索引来查找行,那么该索引将被显示在key列中。
如果key列为,说明MySQL未找到更有效执行查询的索引。
要强制MySQL使用或忽略possible_keys列中列出的索引,请在查询中使用FORCE INDEX,USE INDEX或IGNORE INDEX。
key_len列表示MySQL决定使用的索引键的长度。根据key_len的值可以确定MySQL实际使用了联合索引的多少部分。
由于索引键的存储格式,可以为的列比不允许为的列的索引键长度大1。
ref列显示了在key列中列出的,用于从表中查询行的索引,与哪些列或常量进行了比较。
如果ref列的值为func,说明使用的值是某些函数的结果。
rows列表示MySQL认为执行查询时必须检查的行数。
对于InnoDB表,该数字是估计值,可能并不总是准确的。
Extra列包含MySQL如何解决查询的额外信息。以下为Extra列的部分可能的值及说明:
Using filesort
出现该提示说明MySQL在进行排序时需要使用filesort,未使用索引进行排序。
Using index
从表中检索列信息时,仅使用索引树的信息,不需要进行额外的查找以读取实际行。
当仅查询属于单个索引的部分列时,可以使用此策略。
对于具有用户定义的聚簇索引的InnoDB表,即使Extra列中没有出现“Using index”,对应的索引也可能被使用。当type列为index且key列为主键时,对应以上情况。
Using index condition
出现该提示说明MySQL在查询时使用了索引条件下推。
Using sort_union(…), Using union(…), Using intersect(…)
以上显示了对应index_merge连接类型,即使用索引合并时,索引扫描合并时使用的特定算法。
Using temporary
为了解决该查询,MySQL需要创建一个临时表来保存结果。如果查询包含GROUP BY和ORDER BY子句,且列出了不同的列时,通常会发生这种情况。
Using where
WHERE子句用于限制与下一个表匹配的行,或发送到客户端的行。假如Extra列的值不是using where,且表的连接类型为ALL或index时,则说明查询语句存在一些问题,除非是特意为了获取或检查表中所有的行。
InnoDB读取索引页的时机,包括但不限于MySQL启动、执行EXPLAIN语句、执行查询/插入/更新操作等情况。
为了获取InnoDB读取索引页的次数,可参考前文,查询以“Innodb_pages_”开头的系统状态,或从
INFORMATION_SCHEMA.INNODB_BUFFER_POOL_STATS表查询。
当MySQL启动时,会读取对部分表的索引。此时还未执行任何语句,查看InnoDB读取索引页的次数大于0,查看InnoDB缓冲池中索引页与记录数大于0。
在执行EXPLAIN语句时,可能会读取相关表对应的索引页,若所需的索引页数据已被读取至缓冲池中,可能不会读取。对于上述情况,可查看InnoDB读取索引页的次数,执行EXPLAIN语句后次数会增加。
在执行插入/查询/更新/删除语句时,可能会读取相关表对应的索引页,若所需的索引页数据已被读取至缓冲池中,可能不会读取。
以上参考的资料如下:
https://dev.mysql.com/doc/refman/5.6/en/


声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号