初学者的C++:掌握15个关键概念
发表时间: 2019-03-24 09:40
模块始终是是一个很重要的概念,硬件如此,软件也是如此。物以类聚,类型因为其属性、行为的相同与不同。
让我们把世界看成是一个由对象(object)所组成的大环境。对象是什么?白一点说,「东西」是也!任何实际的物体你都可以说它是对象。为了描述对象,我们应该先把对象的属性描述出来。好,给「对象的属性」一个比较学术的名词,就是「类别」(class)。
对象的属性有两大成员,一是属性,一是行为。在对象导向的术语中,前者常被称为property(Java 语言则称之为field),后者常被称为method。另有一对比较像程序设计领域的术语,名为member variable(或data member)和member function。
一般而言,成员变量通常由成员函数处理之。
如果我以CSquare 代表「四方形」这种类别,四方形有color,四方形可以display。好,color 就是一种成员变量,display 就是一种成员函数:
CSquare square; // 声明square 是一个四方形。square.color = RED; // 设定成员变量。RED 代表一个颜色值。square.display(); // 调用成员函数。
下面是C++ 语言对于CSquare 的描述:
class CSquare // 常常我们以C 作为类别名称的开头{private: int m_color; // 通常我们以m_ 作为成员变量的名称开头public: void display() { ... } void setcolor(int color) { m_color = color; }};成员变量可以只在类别内被处理,也可以开放到外界处理。以资料封装的目的而言,自然是前者较为妥当,但有时候也不得不开放。为此,C++ 提供了private、public 和protected 三种修饰词。一般而言成员变量尽量声明为private,成员函数则通常声明为public。上例的m_color 既然声明为private,我们势必得准备一个成员函数setcolor,供外界设定颜色用。把资料声明为private,不允许外界随意存取,只能透过特定的接口来操作(可以在构造函数中初始化),这就是对象导向的封装(encapsulation)特性。
其它语言欲完成封装性质,并不太难。以C 为例,在结构(struct)之中放置数据,以及处理这些数据的函数的指针(function pointer),就可得到某种程度的封装精神。
C++ 神秘而特有的性质其实在于继承。
矩形是形,椭圆形是形,三角形也是形。苍蝇是昆虫,蜜蜂是昆虫,蚂蚁也是昆虫。是的,人类习惯把相同的性质抽取出来,成立一个基础类别(base class),再从中衍化出派生类别(derived class)。所以,关于形状,我们就有了这样的类别层次:
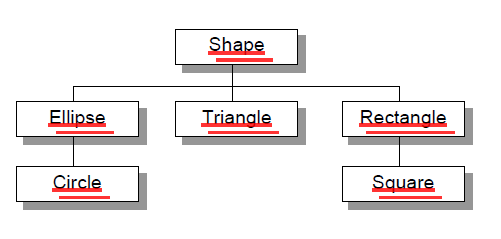
注意:派生类别与基础类别的关系是“Is Kind Of” 的关系。也就是说,
Circle「是一种」Ellipse,Ellipse「是一种」Shape;
Square「是一种」Rectangle,Rectangle「是一种」Shape。
所有类别都由CShape 衍生下来,所以它们都自然而然继承了CShape 的成员,包括变量和函数。(如MFC中控件类的派生就体现得很充分)
成员函数的参数表中都隐含了一个(类名*)this的指针,指向对象自身。
成员函数的定义:
class CShape{ ...public: void setcolor(int color) { m_color = color; }};被编译器整治过后,其实是:
class CShape{ ...public: void setcolor(int color, (CShape*)this) { this->m_color = color; }};如果基础类别和派生类别都定义了「相同名称、相同参数的完全相同的成员函数」,那么透过对象指针调用成员函数时,到底调用到哪一个函数,必须视该指针的原始型别而定,而不是视指针实际所指之对象的型别而定。
如果基类是虚拟(virtual)函数,派生类有重写,当基类指针指向不同的成员函数时,相同的调用代码,会调用不同的重写函数,这就是类型派生的多态功能。
虚拟函数是C++语言的Polymorphism 性质以及动态绑定的关键。
我们以相同的单一指令却唤起了不同的函数,这种性质称为Polymorphism,意思是"the ability to assume many forms"(多态)。编译器无法在编译时期判断到底是调用哪一个函数,必须在执行时期才能评估之,这称为后期绑定late binding 或动态绑定dynamic binding。至于C 函数或C++ 的non-virtual 函数,在编译时期就转换为一个固定地址的调用了,这称为前期绑定early binding 或静态绑定static binding。
MFC 有两个十分十分重要的虚拟函数:与document 有关的Serialize 函数和与view 有关的OnDraw 函数。你应该在自己的CMyDoc 和CMyView 中改写这两个虚拟函数。
纯虚拟函数不需定义其实际动作,它的存在只是为了在衍生类别中被重新定义,只是为了提供一个多态接口。
如果你期望衍生类别重新定义一个成员函数,那么你应该在基础类别中把此函数设为virtual。
既然抽象类别中的虚拟函数不打算被调用,我们就不应该定义它,应该把它设为纯虚拟函数(在函数声明之后加上"=0" 即可)。
我们可以说,拥有纯虚拟函数者为抽象类别(abstract Class),以别于所谓的具象类别(concrete class)。
抽象类别不能产生出对象实体,但是我们可以拥有指向抽象类别之指针,以便于操作抽象类别的各个衍生类别。
虚拟函数衍生下去仍为虚拟函数,而且可以省略virtual 关键词。
假设你有一个类别,专门用来处理存款帐户,它至少应该要有存户的姓名、地址、存款额、利率等成员变量:
class SavingAccount{private: char m_name[40]; // 存戶姓名 char m_addr[60]; // 存戶地址 double m_total; // 存款額 double m_rate; // 利率 ...};这家行库采用浮动利率,每个帐户的利息都是根据当天的挂牌利率来计算。这时候m_rate 就不适合成为每个帐户对象中的一笔资料,否则每天一开市,光把所有帐户内容叫出来,修改m_rate 的值,就花掉不少时间。m_rate 应该独立在各对象之外,成为类别独一无二的资料。怎么做?在m_rate 前面加上static 修饰词即可:
static double m_rate; // 利率
static成员变量不属于对象的一部份,而是类别的一部份,所以程序可以在还没有诞生任何对象的时候就处理此种成员变量。但首先你必须初始化它。不要把static成员变量的初始化动作安排在类别的构造式中,因为构造式可能一再被调用,而变量的初值却只应该设定一次。也不要把初始化动作安排在头文件中,因为它可能会被包含许多地方,因此也就可能被执行许多次。你应该在实现文件中且类别以外的任何位置设定其初值。例如在main之中,或全域函数中,或任何函数之外:
double SavingAccount::m_rate=0.0075;//设立static成员变量的初值
void main(){...}这么做可曾考虑到m_rate是个private资料?没关系,设定static成员变量初值时,不受任何存取权限的束缚。请注意,static成员变量的型别也出现在初值设定句中,因为这是一个初值设定动作,不是一个数量指定(assignment)动作。事实上,static成员变量是在这时候(而不是在类别声明中)才定义出来的。
只要access level 允许,任何函数(包括全域函数或成员函数,static 或non-static)都可以存取static 成员变量。但如果你希望在产生任何object 之前就存取其class 的private static 成员变量,则必须设计一个static 成员函数(例如以下的setRate):
class SavingAccount{public:static void setRate(double newRate) { m_rate = newRate; }}由于static 成员函数不需要借助任何对象,就可以被调用执行,所以编译器不会为它暗加一个this 指针。也因为如此,static 成员函数无法处理类别之中的non-static 成员变量。成员函数之所以能够以单一一份函数码处理各个对象的资料而不紊乱,完全靠的是this 指针的指示。
C++ 的new 运算子和C 的malloc 函数都是为了配置内存,但前者比之后者的优点是,new 不但配置对象所需的内存空间时,同时会引发构造式的执行。
所谓构造式(constructor),就是对象诞生后第一个执行(并且是自动执行)的函数,它的函数名称必定要与类别名称相同。
相对于构造式,自然就有个析构式(destructor),也就是在对象行将毁灭但未毁灭之前一刻,最后执行(并且是自动执行)的函数,它的函数名称必定要与类别名称相同,再在最前面加一个~ 符号。如果在构造式中有动态内存申请,而在析构式中定义了动态内存释放,这样就可以避免内存泄漏。
一个有着阶层架构的类别群组,当衍生类别的对象诞生之时,构造式的执行是由最基础类别(most based)至最尾端衍生类别(most derived);当对象要毁灭之前,析构式的执行则是反其道而行。
对于全域对象,程序一开始,其构造式就先被执行(比程序进入点更早);程序即将结束前其析构式被执行。MFC 程序就有这样一个全域对象,通常以application object 称呼之。
对于局部对象(保存在栈上),当对象诞生时,其构造式被执行;当程序流程将离开该对象的存活范围(以至于对象将毁灭),其析构式被执行。
对于静态(static)对象(保存在全局\静态内存区),当对象诞生时其构造式被执行;当程序将结束时(此对象因而将遭致毁灭)其析构式才被执行,但比全域对象的析构式早一步执行。
对于以new 方式产生出来的区域对象(保存在堆上),当对象诞生时其构造式被执行。析构式则在对象被delete 时执行。
程序要加载到内存才可以执行,程序和其处理的数据在内存中分区存放,数据区内存进一步分为全局\静态区(在程序存续期自其申请开始不释放、其后代码均可见,也可控制在其它文件是否可见)、栈区(存放局部变量,局部域中存续和可访问,离开该域后其内存空间自动释放,也就是该块内存是可重复利用的)、堆区(在运行时视需求数量申请、可用完后手动释放,因为此时编译器也帮不上忙,谁也不知你想将这块内存用到什么时候,需要在何时释放)。
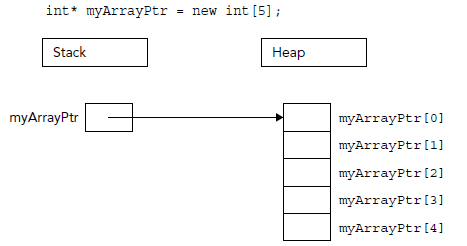
二维数组的动态内存分配要复杂一点:
以下代码不会通过编译:
char** board = new char[i][j]; // BUG! Doesn't compile
此代码不编译,因为基于堆的数组的工作方式与基于堆栈的数组不同。它们的内存布局不是连续的,因此为基于堆栈的多维数组分配足够的内存是不正确的。相反,您可以从为基于堆的数组的第一个下标维度分配一个连续数组开始。该数组的每个元素实际上是指向另一个数组的指针,该数组存储第二个下标维度的元素。动态分配的二乘二板的布局如下所示。This code doesn’t compile because heap-based arrays don’t work like stack-based arrays. Their memory layout isn’t contiguous, so allocating enough memory for a stack-based multi-dimensional array is incorrect. Instead, you can start by allocating a single contiguous array for the first subscript dimension of a heap-based array. Each element of that array is actually a pointer to another array that stores the elements for the second subscript dimension. This layout for a two-by-two dynamically allocated board is shown as belows.
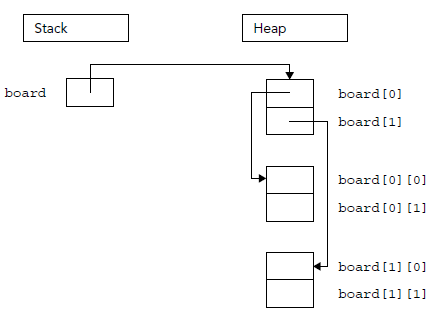
可以像基于堆的一维数组一样分配第一个维度数组,但必须显式分配各个子数组。以下函数为二维数组正确分配内存:
You can allocate the first-dimension array just like a single-dimensional heap-based array, but the individual subarrays must be explicitly allocated. The following function properly allocates memory for a two-dimensional array:
char** allocateCharacterBoard(size_t xDimension, size_t yDimension){char** myArray = new char*[xDimension]; // Allocate first dimensionfor (size_t i = 0; i < xDimension; i++) {myArray[i] = new char[yDimension]; // Allocate ith subarray}return myArray;}同样,当您希望释放与基于多维堆的数组关联的内存时,数组delete[]语法不会代表您清除子数组。释放数组的代码应该镜像分配数组的代码,如下函数所示:
Similarly, when you want to release the memory associated with a multi-dimensional heap-based array, the array delete[] syntax will not clean up the subarrays on your behalf. Your code to release an array should mirror the code to allocate it, as in the following function:
void releaseCharacterBoard(char** myArray, size_t xDimension){for (size_t i = 0; i < xDimension; i++) {delete [] myArray[i]; // Delete ith subarray}delete [] myArray; // Delete first dimension}对象中的动态内存分配带来了新的挑战:您需要实现一个析构函数、复制构造函数、复制分配运算符、移动构造函数和移动分配运算符,这些操作可以正确地复制、移动和释放内存。
Dynamic memory allocation in objects presents new challenges: you need to implement a destructor, copy constructor, copy assignment operator, move constructor, and move assignment operator, which properly copy, move, and free your memory.
函数调用做了两件事情:用对应的实参初始化函数的形参(创建变量并赋值),并将控制权转移给被调用函数。主调函数的执行被挂起,被调函数开始执行。函数的运行以形参的(隐式)定义和初始化开始。
函数的按值传递或引用、指针传递,区别在于是否在函数体内改变参数的情形下;
在C++中,值传递是指将要传递的值作为一个副本传递。值传递过程中,被调函数的形参作为被调函数的局部变量处理,在内存的堆栈中开辟空间以存放由主调函数放进来的实参的值,从而成为了实参的一个副本。值传递的特点是被调函数对形参的任何操作都是作为局部变量进行,不会更改主调函数的实参变量的值。
引用传递传递的是引用对象的内存地址。在地址传递过程中,被调函数的形参也作为局部变量在堆栈中开辟了内存空间,但是这时存放的是由主调函数放进来的实参变量的地址。被调函数对形参的任何操作都被处理成间接寻址,即通过堆栈中存放的地址访问主调函数中的实参变量。所以,被调函数对形参做的任何操作都会影响主调函数中的实参变量。
值传递是因为变量之间没有关联。而引用或指针传递是因为引用只是变量的别名,而指针是指向某个变量,所以变量之间有关系,这样在修改函数参数时,没有关联的就没有影响,而有关联的就有影响。
Using (const) References to Avoid Copies
利用 const 引用避免复制
在向函数传递大型对象时,需要使用引用形参,这是引用形参适用的另一种情况。虽然复制实参对于内置数据类型的对象或者规模较小的类类型对象来说没有什么问题,但是对于大部分的类类型或者大型数组,它的效率(通常)太低了;某些类类型是无法复制的。使用引用形参,函数可以直接访问实参对象,而无须复制它。
The other circumstance in which reference parameters are useful is when passing a large object to a function. Although copying an argument is okay for objects of built-in data types and for objects of class types that are small in size, it is (often) too inefficient for objects of most class types or large arrays. Some class types cannot be copied. By using a reference parameter, the function can access the object directly without copying it.
编写一个比较两个 string 对象长度的函数作为例子。这个函数需要访问每个 string 对象的 size,但不必修改这些对象。由于 string 对象可能相当长,所以我们希望避免复制操作。使用 const 引用就可避免复制:
// compare the length of two strings bool isShorter(const string &s1, const string &s2) { return s1.size() < s2.size(); }其每一个形参都是 const string 类型的引用。因为形参是引用,所以不复制实参。又因为形参是 const 引用,所以 isShorter 函数不能使用该引用来修改实参。
private和protected的成员不能在类的外部访问。
private除了不能被外部访问以外,还不能被继承,而protected是可以被继承的。私有除了其本身的成员方法以外,不能被外部访问,派生类亦是如此,但可以通过成员函数来访问,但函数访问是有成本的,一个变通的方法就是,将这一类数据成员声明为protected,这样,派生类就可以访问这一类成员了。
友元是对类的访问控制或封装性的一种突破或破坏。
一个类的友元可以是一个外部函数,也可以是一个类。它们虽然不是该类的成员,但却能直接访问该类的任何成员,这显然提高了访问效率,但带来的问题是,这在一定程序上违背了数据封装原则。
class ca { friend funa(); friend cb::mfun(); friend class cc; };友元机制允许一个类将对其非公有成员的访问权授予指定的函数或类。友元的声明以关键字 friend 开始。它只能出现在类定义的内部。友元声明可以出现在类中的任何地方:友元不是授予友元关系的那个类的成员,所以它们不受声明出现部分的访问控制影响。
所谓有元类就是两个有缘的类。其中一个类A将另一个类B声明为友元,则类B的成员函数能够访问A的所有成员,无论这些成员是公有的还是私有的。友元其实是对于访问控制的一种有限突破。想私有,但想让特定(朋友)的类能够访问。
声明友元的方法为:
class A{friend class B;……}将整个类设置为友元,极大地破坏了类的封装性。在C++中,还可以单独地将某个函数或某个类的某个成员函数声明为友元:
class A{friend 返回值类型 函数名()参数表; //友元函数friend 返回值类型 B::成员函数名()参数表; //友元成员函数}C++是一种强类型语言,它要求程序中每一个对象的类型在编译阶段就能确定。一方面,这可以在很大程度上保证程序不会出现因类型问题而导致的错误。但另一方面,这种对类型的强力约束也限制了编码的灵活性,并且有可能导致编码效率的低下。泛型编程技术的引入使得两方面得到 了很好的平衡。包括函数模板与类模板。
函数模板可以用来创建一个通用的函数,以支持多种不同的形参,避免重载函数的函数体重复设计。它的最大特点是把函数使用的数据类型作为参数。
一个类模板(也称为类属类或类生成类)允许用户为类定义一种模式,使得类中的某些数据成员、默认成员函数的参数、某些成员函数的返回值,能够取任意类型(包括系统预定义的和用户自定义的)。
如果一个类中数据成员的数据类型不能确定,或者是某个成员函数的参数或返回值的类型不能确定,就必须将此类声明为模板,它的存在不是代表一个具体的、实际的类,而是代表着一类类。
类模板的使用实际上是将类模板实例化成一个具体的类,它的格式为:类名<实际的类型>.
一种基本数据类型定义了其数值范围,需要的内存空间大小,可以实现的操作(操作符)。在编程语言中,操作符与函数都是实现对一个特定数组集的操作。例如+号,int可以实现算术上的加法。类类型做为一种自定义复合数据类型,也要实现与基本数据数据相似的定义,例如字符串类型(string类型,已在C++通过string类实现),两个字符串的连接,如果将字符串定义为数组,在C语言中可以通过函数实现,如通过strcat()实现两个字符数组的连接。如果是string类,则可以通过成员函数operator+()来实现两个字符串对象的连接,这种写法在编程语言中叫操作符重载。
通过操作符重载,可以重定义大多数操作符,使它们用于类类型对象。明智地使用操作符重载可以使类类型的使用像内置类型一样直观。标准库为容器类定义了几个重载操作符。这些容器类定义了下标操作符以访问数据元素,定义了 * 和 -> 对容器迭代器解引用。这些标准库的类型具有相同的操作符,使用它们就像使用内置数组和指针一样。允许程序使用表达式而不是命名函数,可以使编写和阅读程序容易得多。
重载操作符是具有特殊名称的函数:保留字 operator 后接需定义的操作符号。像任意其他函数一样,重载操作符具有返回类型和形参表。
Sales_item operator+(const Sales_item&, const Sales_item&);
声明了加号操作符,可用于将两个 Sales_item 对象“相加”并获得一个 Sales_item 对象的副本。
重载操作符必须具有一个类类型操作数。
操作符的优先级、结合性或操作数目不能改变。
不再具备短路求值特性。
大多数重载操作符可以定义为普通非成员函数或类的成员函数。操作符定义为非成员函数时,通常必须将它们设置为所操作类的友元。
操作符其实就是一个函数,操作符有一元操作符、二元操作符、三元操作符,就如果一个函数名加一个参数、或二个相同类型参数、或三个相同类型参数;所以操作会可以重载,用于对象的操作,阅读起来更直观。
如以下是一个complex类成员函数:
complex add(const complex &c1, const complex &c2) { complex temp(c1.real + c2.real, c1.imag + c2.imag); return temp; }其类似的功能可以用操作符重载来实现:
complex operator+(const complex& c1, const complex& c2) { complex temp(c1.real + c2.real, c1.imag + c2.imag); return temp; }c1+c2会被编译器理解为:
::operator+(c1,c2)
STL的从广义上讲分为三类:algorithm(算法)、container(容器)和iterator(迭代器),容器和算法通过迭代器可以进行无缝地连接。几乎所有的代码都采用了模板类和模板函数的方式,这相比于传统的由函数和类组成的库来说提供了更好的代码重用机会。
STL中的迭代器是模板类,从某种程序上说,它们是泛型指针。这些模板类让程序员能够对STL容器进行操作。注意,操作也可以是以模板函数的方式提供的STL算法,迭代器是一座桥梁,让这些模板函数能够以一致而无缝的方式处理容器,而容器是模板类。
泛化、泛化、再泛化:
12.1 类型的泛化:模板技术让容器不局限于具体类型;
12.2 迭代器的泛化:迭代器是指针的泛化,如vector可以用指针实现迭代器,list可以通过类实现迭代器。迭代器的使用除了声明有所区别以外,其它方面基本一致,如:
vector::iterator pr;//list::iterator pr;for(pr=ins.begin(); pr != ins.end(); pr++){cout<<*pr<<endl}12.3 算法的泛化:因为迭代器的泛化,可以让算法独立于具体的容器。也就是说,算法能够独立于具体的容器、独立于具体的类型。
程序整体与模块都可以按输入、处理、输出去构建(硬件也是如此)。对于console程序,可以用stdio.h中提供的函数去实现输入、输出,对于GUI函数自然可以通过GUI去实现输入、输出。对于函数而言,其整体也可以区分输入、处理、输出部分,其输入、输出体现在函数返回回值、参数中。
C++语言本身是不提供输入输出操作的,它的输入/输出(input/output)由标准库提供。标准库定义了一组类型,支持对文件和控制窗口等设备的读写(I\O)。还定义了其他一些类型,使string 对象能够像文件一样操作,从而使编程者无须I\O 就能实现数据与字符之间的转换。这些I\O 类型都定义了如何读写内置数据类型的值。此外,类的设计者还可以很方便地使用I\O 标准库设施读写自定义类的对象。类类型通常使用I\O 标准库为内置类型定义的操作符和规则来进行读写。
标准库的输入输出功能就涉及了流的使用。C++的输入输出流是指由若干字节组成的字节序列,这些字节中的数据按顺序从一个对象传送到另一个对象。流实际上是程序中输入或者输出设备的一种抽象表示,它表示了信息从源端到目的端的运动。在输入操作时, 字节流从输入设备(如键盘、磁盘)流向内存;在输出操作时,字节流从内存流向输出设备(例如屏幕、打印机、磁盘等)。流中的内容可以是ASCII 字符、二进制形式的数据、图形图像、数字音频视频或其他形式的信息。
实际上,在内存中为每个数据流开辟一个内存缓冲区,是用来存放流中的数据。流是与内存缓冲区相对应的,或者可以说,缓冲区中的数据就是流。
在编程语言中,函数是一个很重要的概念,其身影无处不在。在面向过程的编程方式中,函数更是程序的基本构建模块,在面向对象的编程方式中,函数演变为类或对象的成员(当然也可以使用与类无关的函数)。
函数由函数头和函数体组成。函数头包括域属性(如external、static或类域)、返回值类型、函数名、及参数。域属性包括其在多文件编程中的可见范围,是否是属于某一个类的成员?返回值类型是指函数返回的值的具体数据类型(可以理解为函数输出的一部分)。函数名是函数保存在内存代码区的首地址,用于函数的调用及函数指针的右值。参数可以理解为函数的输入、输出(如果是引用或指针作为参数,可以理解为是一个种输出,因为其操作或更新的数据是引用或指针的地址值所指向的内存单元)。在CC++中,函数体位于{}中,函数体是函数功能的具体实现。
如果用一台手机来理解函数概念,手机裸露在外的操作界面就像是函数头,外壳内的组件就像是函数体中,外壳就像是{}。
函数的开发者和使用者可以站在不同的角度去理解函数的构造,函数的开发者需要负责函数头作为界面(interface)的友好性及稳定性,以及保证实现(implement)函数功能的函数体的空间和时间效率。而函数的使用者可以不关心函数功能的具体实现(当然了解其具体实现能更好地加深对函数的理解),也就是不心关心函数体的具体内容,只需关心函数使用的具体细节,也就是函数体的内容。
函数的内部观点:关心函数的定义,1 采用什么计算方法;2 采用什么实现结构;3 实际参数如何使用;4 怎样得到所需要的返回值;
函数的外部观点:关心函数的使用,1 实现了什么功能;2 名字是什么;3 要求几个参数,各参数的意义和作用;4 返回什么值;
黑盒视角只是在你使用函数或库时。
就如同一台手机,手机开发者要负责手机从外部操作到内部零部件的全部,而手机购买者(使用者)则只需关心怎样使用即可。
函数头提供给函数使用者一个认识与使用的操作界面,函数签名是函数头的一部分(不包括函数返回类型)。函数签名就像一个人的签名,都叫李明,就因为笔迹不同而可以理解为不同的签名,在程序语言中,即使函数名相同,但因为为参数数量或类型不同,编译器也可以识别为不同的函数签名。在类类型的继承关系中,派生类成员函数可以重写基类包括类型数量和类型、名字相同的成员函数,因为层次关系的隶属及类类型的域解析(类类型限定),编译器也可以做出隶属关系不同的解析。
函数就是一个功能部件,其头部定义了它的接口,描述了函数的名字及其对参数的要求。使用者只需要考虑函数的功能是否满足实际需要,还要保证调用式符合函数头部的要求,并不需要知道函数实现的任何具体细节。
在程序开发的实践中人们逐渐认识到,仅有计算层面的抽象机制和抽象定义还不够,还需要考虑数据层面的抽象。能围绕一类数据建立程序组件,将该类数据的具体表示和相关操作的实现包装成一个整体,也是组织复杂程序的一种有效技术,可以用于开发出各种有用的程序模块。要把这种围绕着一类数据对象构造的模块做成数据抽象,同样需要区分模块的接口和实现。模块接口提供使用它提供的功能所需的所有信息,但不涉及具体实现细节。另一方面,模块实现者则要通过模块内部的一套数据定义和函数(过程)定义,实现模块接口的所有功能,从形式上和实际效果上满足模块接口的要求。
代码重构:寻找可以使用重构(refactoring,重新组织程序,以改善接口(函数名称与形参),提高代码重用)来改善程序的机会。例如,如果发现程序中几处地方有相似的代码,可以考虑将它们抽取出来做一个合适的通用函数。
程序开发首先要考虑的是要选择合适的开发工具,选择合适的开发语言、框架、库。
C++中的include关键字用来进行文件包含,这些文件就存在于不同的库(library)中(开发的程序与库的链接可以是静态链接,也可以是动态链接)。
静态链接库就是把(lib)文件中用到的函数代码直接链接进目标程序,程序运行的时候不再需要其他库文件。
动态链接则是把调用的函数所在文件模块(DLL)和调用函数在文件中的位置等信息链接进目标程序,程序运行的时候再从DLL中寻找相应函数代码,因此需要相应的DLL文件的支持。顾名思义,动态链接是在运行时通过连接器(linker)来加载启动代码,从而加载所需要的库,对每一个库的调用都要通过一个跳台(jump table)指向该库,唯一的开销是间接引用。动态链接还需要验证jump table符号链接(symbols linkage),动态loader需要检查共享库,加载入内存并且附加在程序内存段。
静态链接库与动态链接库都是共享代码的方式。
开发的一个重要原则就是复用代码,包括自己的代码,牛人写的解决一些一般问题的代码(也就是库),所以说库包括自己或自己公司开发的库,或第三方提供的库。(内存的栈概念也是内存空间重用思想的一种体现)
GUI程序开发,包括UI开发与内部业务开发,相应的库也有UI库、实现一些数据结构与算法的函数库或类库。
不同类别的程序或模板所需要框架代码都有一定的相似性,这方面的代码也可以通过实现一般化来实现代码重用,这也就是框架,如VC提供的application wizard(sdi、mdi、dialog)、class Wizard(控件类、一般类、变量关连、成员函数、消息响应函数等)就能按流程实现程序的一些框架代码。
开发语言提供原料、库提供组件、框架帮助搭建一个架子、开发人员需要做的就是装配、装修等个性化与业务问题的解决。
开发工具IDE不但提供开发语言的编辑器、编译器、连接器、调试器,还提供语言的函数库与类库,开发框架。
可考虑组合的语言、工具或技术如:Java、C\C++、Python、HTML5、Javascript、.net(Windows API、MFC、WPF、XAML)、QT、STL、WTL、DirectUI、大数据应用大数据(Hadoop MapReduce、HBase、spark、redis、Kafka),当然也要考虑平台及跨平台的需求,PC端、移动端、web应用(前端、后端)、嵌入开发、工控领域、大数据应用等不同的领域需要考虑不同的组合。
API就是应用程序接口,是由系统提供的一些函数,比如你想创建一个文件,就要调用CreateFile,这个CreateFile就是一个API。任何一个操作系统都会提供API的,比如DOS也提供API,不过它是通过Int 21h中断提供的就是了。
SDK是指一些公司针对某一项技术为软件开发人员制作的一套辅助开发或者减少开发周期的工具。一般专指Windows系统提供的相关的头文件和LIB文件。有时候很多人将不用MFC等相关类库,而只用API进行开发的方式也叫做SDK开发,从这一点来说,API和SDK似乎是通用的。
MFC是MS对API的一个封装,也就是一个C++类库,当然MFC比一般类库庞大,所以有人称之为应用程序框架。但其本质还是一个类库
-End-
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号