Redis概述与入门
发表时间: 2020-07-29 21:23
本文主要从以下几个方面介绍Redis:
一、什么是Redis
二、Redis支持的五种数据类型
三、Redis应用场景
四、Redis特性
五、Redis的持久化
六、Redis的Demo
它是一种 NoSQL(not-only sql,泛指非关系型数据库)的数据库!!!!(三个月前面试某团时居然回答不出NoSQL数据库有哪些。。。。。。。)
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。它是一个key-value存储系统,支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。为了保证效率,数据都是缓存在内存中。另外,redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
1、String 是 Redis 最基本的类型,一个 Key 对应一个 Value。Value 不仅是 String,也可以是数字。
String 类型是二进制安全的,意思是 Redis 的 String 类型可以包含任何数据,比如 jpg 图片或者序列化的对象。String 类型的值最大能存储 512M。
2、Hash是一个键值(key-value)的集合。Redis 的 Hash 是一个 String 的 Key 和 Value 的映射表,Hash 特别适合存储对象。常用命令:hget,hset,hgetall 等。
3、List 列表是简单的字符串列表,按照插入顺序排序。可以添加一个元素到列表的头部(左边)或者尾部(右边) 常用命令:lpush、rpush、lpop、rpop、lrange(获取列表片段)等。
应用场景:List 应用场景非常多,也是 Redis 最重要的数据结构之一,比如 Twitter 的关注列表,粉丝列表都可以用 List 结构来实现。
数据结构:List 就是链表,可以用来当消息队列用。Redis 提供了 List 的 Push 和 Pop 操作,还提供了操作某一段的 API,可以直接查询或者删除某一段的元素。
实现方式:Redis List 的是实现是一个双向链表,既可以支持反向查找和遍历,更方便操作,不过带来了额外的内存开销。
4、Set 是 String 类型的无序集合。集合是通过 hashtable 实现的。Set 中的元素是没有顺序的,而且是没有重复的。常用命令:sdd、spop、smembers、sunion 等。
应用场景:Redis Set 对外提供的功能和 List 一样是一个列表,特殊之处在于 Set 是自动去重的,而且 Set 提供了判断某个成员是否在一个 Set 集合中。
5、Zset 和 Set 一样是 String 类型元素的集合,且不允许重复的元素。常用命令:zadd、zrange、zrem、zcard 等。
使用场景:Sorted Set 可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。
当你需要一个有序的并且不重复的集合列表,那么可以选择 Sorted Set 结构。
和 Set 相比,Sorted Set关联了一个 Double 类型权重的参数 Score,使得集合中的元素能够按照 Score 进行有序排列,Redis 正是通过分数来为集合中的成员进行从小到大的排序。
实现方式:Redis Sorted Set 的内部使用 HashMap 和跳跃表(skipList)来保证数据的存储和有序,HashMap 里放的是成员到 Score 的映射。
而跳跃表里存放的是所有的成员,排序依据是 HashMap 里存的 Score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
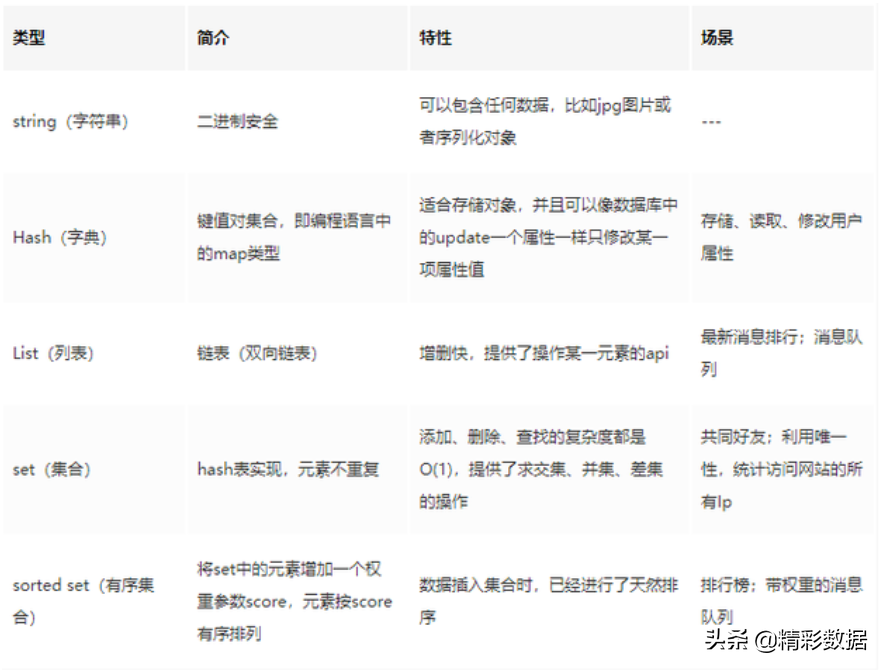
数据类型应用场景总结
1、 配合关系型数据库做高速缓存
高频次,热门访问的数据,降低数据库IO
分布式架构,做session共享
2、 由于其拥有持久化能力,利用其多样的数据结构存储特定的数据
最新N个数据 ------通过list实现按自然时间排序的数据
排行榜,TOP N ------利用zset(有序集合)
时效性的数据,比如手机验证码 -----Expire(过期)
计数器,秒杀 ------原子性,自增方法incr、decr
去除大量数据中的重复数据-----利用set集合
构建队列 -------利用list集合
发布订阅消息系统 ------pub/sub模式
PS:我是想在SparkStreaming和kafka进行直连时保存历史数据使用。因为SparkStreaming和kafka进行直连时只能对当前时间片段内的数据进行统计,当想使用历史数据就需要一个介质将历史数据进行保存,该历史数据访问次数多、要求时延短,就考虑在Redis中进行保存数据,毕竟是存储在内存中,相比较MySQL等要快的多。
redis提供两种持久化方式:RDB和AOF,即可以用两种策略将内存的数据保存在硬盘中,这样就保证了数据的可持久性。
RDB:快照形式是直接把内存中的数据保存到一个 dump 的文件中,定时保存策略。
AOF:把所有的对 Redis 的服务器进行修改的命令都存到一个文件里,命令的集合。
Redis 默认是快照 RDB 的持久化方式。
使用连接池连接Redis:
package xxximport java.utilimport redis.clients.jedis.{Jedis, JedisPool, JedisPoolConfig}object JedisConnectionPool{ val config = new JedisPoolConfig() //最大连接数, config.setMaxTotal(20) //最大空闲连接数, config.setMaxIdle(10) //当调用borrow Object方法时,是否进行有效性检查 --> config.setTestOnBorrow(true) //10000代表超时时间(10秒) val pool = new JedisPool(config, "192.168.247.8", 6379, 10000, "123") def getConnection():Jedis={ pool.getResource } // 初始时,Redis中只存有 xiao->5 def main(args: Array[String]): Unit = { val conn: Jedis = JedisConnectionPool.getConnection() val value: String = conn.get("xiao") println(value) conn.incrBy("xiao", 5) val updatedValue: String = conn.get("xiao") println(updatedValue) // 遍历所有的key val keys: util.Set[String] = conn.keys("*") import scala.collection.JavaConversions._ for(key<-keys){ print(key+": "+ conn.get(key)) } }}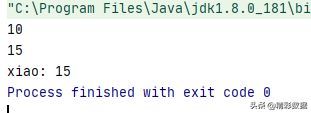
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号