在DNA上直接运行SQL操作,PostgreSQL已验证成功
发表时间: 2019-07-24 17:48
法国通信系统工程师学校与研究中心(Eurecom)数据科学系助理教授 Appuswamy 和伦敦帝国理工学院 SCALE 实验室负责人 Heinis 等人近期发表了一篇关于在 DBMS 存储层操作 DNA 的论文《OligoArchive: Using DNA in the DBMS storage hierarchy》。
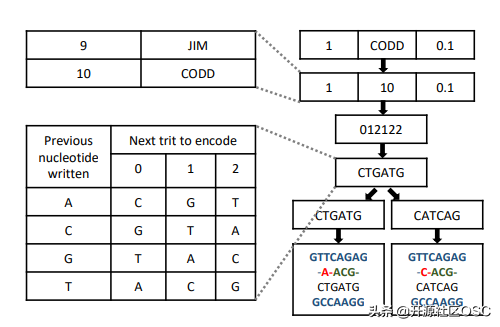
论文研究了在数据库存储层次结构中集成 DNA 的问题。更具体地,其提出了以下两个问题:
为了回答这两个问题,该研究引入了一个叫 OligoArchive 的架构,这是一种使用基于 DNA 的存储系统作为关系数据库归档层的架构。
DNA 的存储系统简单讲也就是指基于 ATCG 这些碱基所组成的一套存储信息的方案,类比 0/1 二进制,这种存储系统具有四进制。用 DNA 作为存储介质,优势是容量大与存储时间长,有数据指出 1 克 DNA 能够存储大约 2 拍字节,相当于大约 300 万张 CD;同时用 DNA 存储数据保存时间可能长达数千年;此外与硬盘、磁带等存储介质不同,DNA 不需要经常维护,而且在读取方式上,DNA 存储不涉及兼容性问题。
天然存在的 DNA 是有两条核苷酸链的双螺旋结构,而用于数据存储的 DNA 是单链核苷酸序列,又叫寡核苷酸(oligo),它是使用每次一个核苷酸来组装 DNA 的化学过程合成的。
OligoArchive 架构通过将基于磁带的归档层替换为基于 DNA 的归档层来改变 DBMS 存储层次结构,论文具体介绍了数据库引擎和 DNA 存储设备之间的分工,以及 DNA 存储设备应在 OligoArchive 中使用的接口。
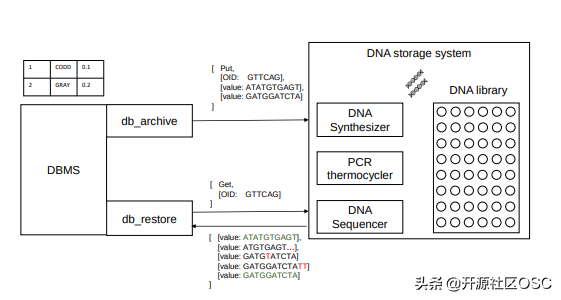
数据库与 DNA 存储分工是这样的:数据库系统执行关系数据和寡核苷酸序列之间的转换。在 put 操作期间,DNA 存储系统合成 DNA 链并将它们存储在库中;在 get 操作期间,对 DNA 链进行测序并将读数返回。

研究人员通过为 PostgreSQL 构建归档和恢复工具(pg_oligo_dump 与 pg_oligo_restore)证明 OligoArchive 可以在实践中实现,这些工具执行模式识别编码和解码 DNA 上的关系数据,并使用这些工具将 12KB TPC-H 数据库归档到 DNA,进行体外计算,并将其恢复。
论文中的实验表明,使用合成 DNA 存档和恢复数据不仅可行,而且还可以利用数据库知识经验优化 DNA 编码和解码过程,甚至直接在 DNA 上执行 SQL 操作。
具体内容查看论文:
http://cidrdb.org/cidr2019/papers/p98-appuswamy-cidr19.pdf
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号