字节跳动如何应对超大规模流式任务运维挑战?VLDB 2023数据库顶级会议论文深度解析!
发表时间: 2023-09-04 11:16
本文解读了新加坡国立大学马天白教授团队、字节跳动基础架构-计算-流式计算团队联合发表在国际数据库与数据管理顶级会议 VLDB 2023 上的论文“StreamOps: Cloud-Native Runtime Management for Streaming Services in ByteDance”,介绍字节跳动内部基于数万 Flink 流式任务管理实践所提炼出的一个流式任务运行时管控解决方案,有效解决流式作业运行期间因流量和运行环境变化而暴露的各类运行时需要人工介入治理的问题,推动 NoOps 化核心能力。它支持管理超大规模的流式作业,提供包括自动扩缩容、慢节点自动迁移和延迟/故障智能诊断等能力,同时能插件化拓展功能。StreamOps 在字节跳动内部得到了大规模验证,日常节省 15% 计算资源,每天有效迁移慢节点约 1000 次,减少 75% 的人工 Oncall,大幅降低了超大规模场景下流式任务的维护成本。
论文链接:https://www.vldb.org/pvldb/vol16/p3501-mao.pdf
引言
近年来,流计算被广泛应用于大规模的实时数据处理和决策中。字节跳动选用了 Flink 作为流式计算处理引擎,每天有数万个 Flink 作业运行在内部集群上,峰值流量高达每秒 90 亿条数据。由于流式作业通常会运行几天甚至更长的时间,它们的工作负载和运行环境往往会随着时间而变化。字节内部的流式作业高峰期和低谷期的流量差异平均有 4-5 倍,并时刻面临着底层资源挤占、机型差异等问题。这样的变化会带来各种运行时问题,例如数据积压和各种故障,导致需要频繁的人工介入或者预留过量的资源造成浪费。随着流计算的规模快速增长,亟需一套运行时管控系统来自动化地的解决这些运行时问题。然而,在字节跳动这样的场景下设计一个流式作业运行时管控服务是具有挑战性的:这个服务需要具有足够的可伸缩性来统一管理集群层面的所有流式作业并使用有效的管控策略来解决不同的运行时问题,还需要具有良好的可扩展性来为新的运行时问题制定新的管控策略。
针对上述挑战,本文提出了一个基于云原生构建的流式任务运行时管控系统 StreamOps,可以有效地降低大规模场景下用户流式任务的维护成本。StreamOps 被设计为独立于流式作业运行的一个轻量级可伸缩的管控系统以统一管理大规模的流式作业。它抽象了一层管控策略编程范式来支持快速构建新的管控策略,并根据字节内部的长期实践经验,支持了流式任务的自动扩缩容、慢节点自动迁移,以及延迟/故障智能诊断三个核心管控策略。本文介绍了我们在设计 StreamOps 中所做的设计决策和相关经验,并在内部生产环境中进行实验验证了 StreamOps 的效果。
SteamOps 介绍
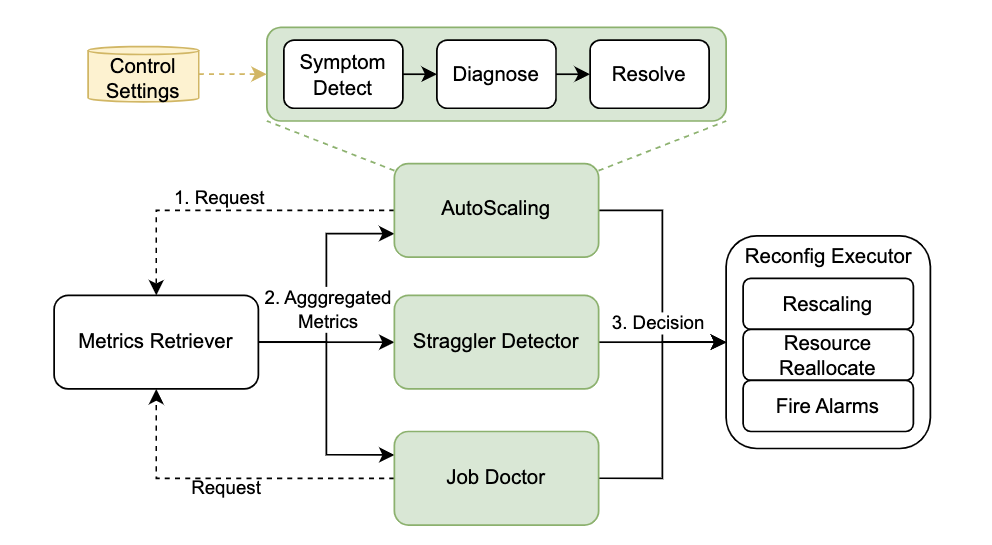
上图展示了 StreamOps 的总体架构和工作流程。其主要包括 3 个组件:
控制平面服务 (Control Plane Service) :可水平拓展的无状态服务来管理集群级别的流式作业,独立于流式作业部署以解耦控制平面和流式计算引擎获得更好的灵活性和拓展性。
全局存储(Global Storage):存储管控策略决策所需的作业指标、日志等数据,和控制平面服务本身的状态数据。
运行时管控触发器(Runtime Management Trigger):每一个流式作业都会配套一个运行时管控触发器来向控制平面服务发送请求触发管控操作。请求可以定期触发,也可以在满足某个特定条件时触发,或者手动触发。
总体的工作流程为:
单个流式作业根据触发策略向控制平面服务触发管控操作。
控制平面服务收到请求后从全局存储拉取作业指标和管控策略本身的状态等数据,供管控策略决策。
管控策略做出决策后,会对流式作业运行时发起配置更改或者向用户发出报警提醒处理。
控制平面服务
StreamOps 采用了策略-机制分离的设计原理,将整体的管控流程分成两大部分:管控策略和管控机制。管控策略专注于负责模型决策,实现被抽象发现-诊断-解决三步走的通用编程范式进行定义。管控机制负责和外部系统交互,执行指标获取和根据决策执行管控变更的操作,通用的指标获取和管控变更机制被封装起来可以复用。通过以上措施,可以低成本地拓展实现一个新的管控策略。
3.1 管控策略
上图展示了管控策略决策的总体流程,管控策略首先从指标采集器中获取流式作业运行时的指标和配置信息,然后遵从发现、诊断、解决三步走的步骤根据获取到指标和配置信息进行决策,最后交由流式作业配置变更器进行执行,常见的执行机制包括扩缩容、节点迁移或者只是发送报警让用户手动处理。
3.2 管控机制
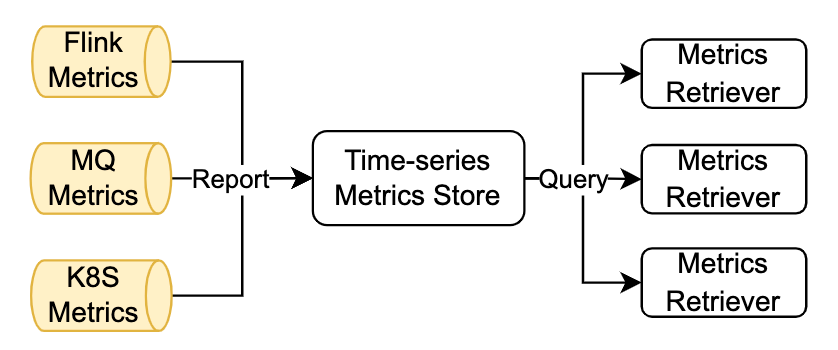
1.指标采集
流式作业管控常用的指标信息除了计算引擎自身的指标外还有 MQ 侧的数据源相关指标和 K8s 侧的资源相关指标,字节跳动内部将三类指标都通过中心时序数据库缓存起来。StreamOps 对接了内部的时序数据库系统,管控策略就可以根据需要对不同种类的指标进行丰富的查询操作。
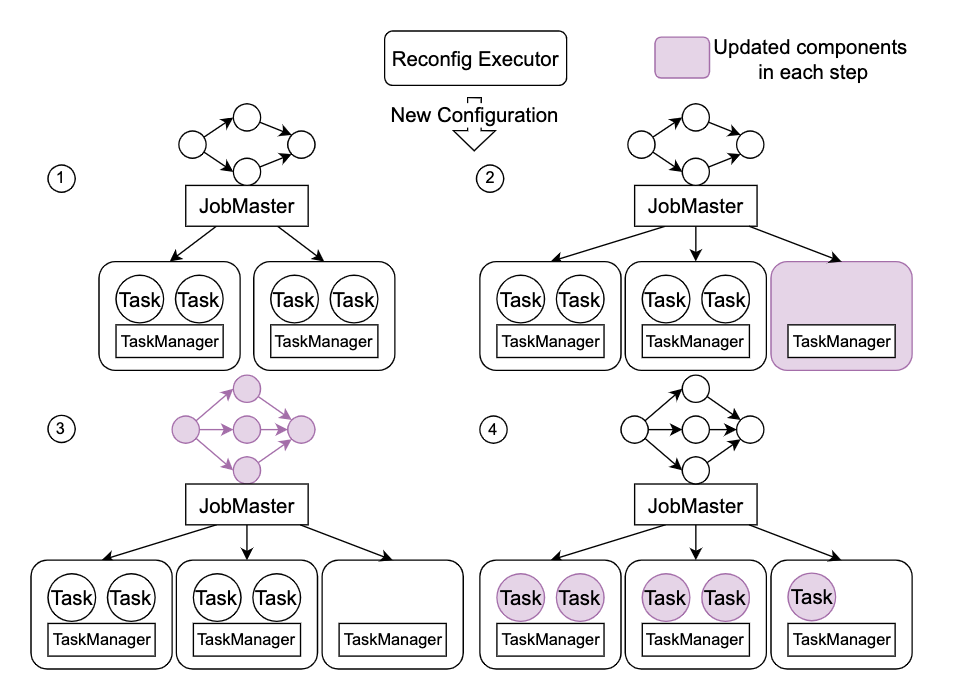
2.流式作业运行时配置变更
对作业的配置变更可以通过重启完成,但是这对用户影响较大。在变更上我们首先通过 API 实现作业热更新完成加速,此外我们分析发现这类操作中有不少优化空间,首先是涉及资源变更的操作很大一部分时间花费在资源申请上,对于小状态作业最高可达 70%,实现了一套资源预申请机制并接入 StreamOps。对于大状态任务,绝大部份时间花费在状态恢复上,我们针对 RocksDB 优化了 DB 合并与裁剪机制,整体状态恢复时间提速10 倍。经过我们整体优化,总体断流时间由完全重启所需的分钟级降低到秒级,用户几乎无感。
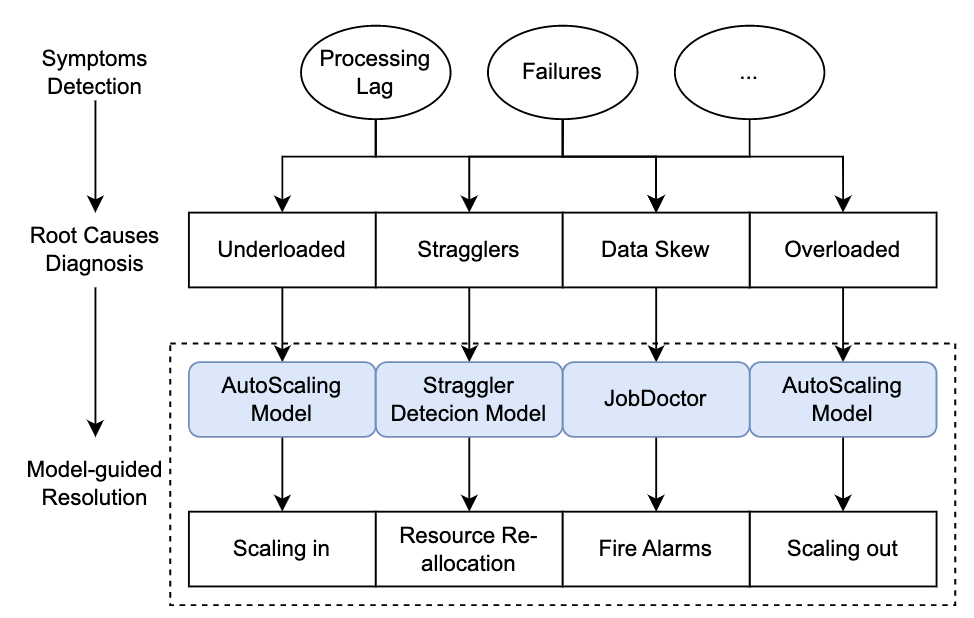
核心管控策略实现
StreamOps 核心管控策略的目标是:1、保障作业处理跟上入流的数据速率,解决消息积压和运行时异常问题;2、提升集群资源使用率降低成本。在字节的生产实践中,发现消息积压主要有两种原因导致:总体资源不足和负载不均衡,其中负载不均衡又可以细分为由运行效率慢问题的机器(慢节点)导致和数据倾斜导致。运行时异常则原因多样,并且很多时候无法从计算引擎内部解决。因此,StreamOps 实现了如上图所示的三个核心管控策略:
自动扩缩容:解决作业总体资源配置不足/过剩的问题。
慢节点自动迁移:解决由运行效率慢问题的机器导致的消息积压。
智能诊断:针对数据倾斜、运行时异常这些往往无法从计算引擎内部解决的问题,提供诊断和建议。
4.1 自动扩缩容
我们在 DS2[1] 模型的基础上拓展实现了适用于字节的自动扩缩容模型,其总体决策流程如上。模型综合考虑了作业的消息积压与算子负载情况判断是否需要进行扩缩容操作,对于缩容会额外考虑过去一段时间的工作负载情况,排除了严重数据倾斜、作业运行故障等异常情况避免错误的决策。在处理过程中搭配作业热更新、RocksDB DB 合并与裁剪加速等机制可以实现接近零停机的快速恢复。
4.2 慢节点自动迁移
针对因少数机器运行环境导致的慢节点问题,检测模型通过算法可以排除常规情况,在作业拓扑中筛选出具有很高机器聚合性的异常慢节点,对其进行迁移恢复。在处理过程中搭配节点拉黑和资源预申请等优化手段更加快速稳定。
4.3 智能诊断
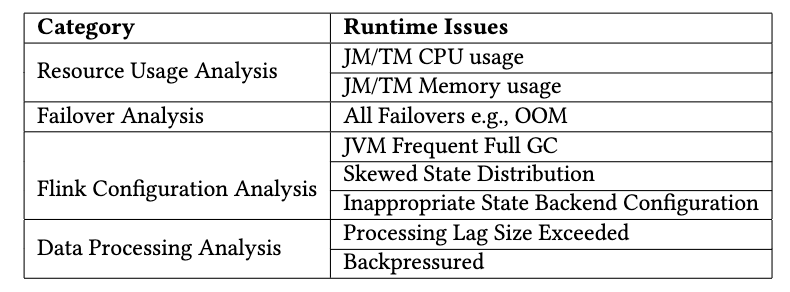
同时 StreamOps 实现了一套智能诊断(Job Doctor)系统,并提供了可视化平台供用户和运维人员分析使用。其内部主要涵盖了如下四种等类型的诊断规则:资源使用情况分析与建议、运行异常收集分析与建议、Flink 配置分析与建议、处理瓶颈情况分析与建议。用户可以进行自主检测,系统也会定期巡检,向用户发送警告并提供相应的处理建议。
实验结果
5.1 控制平面总体效果
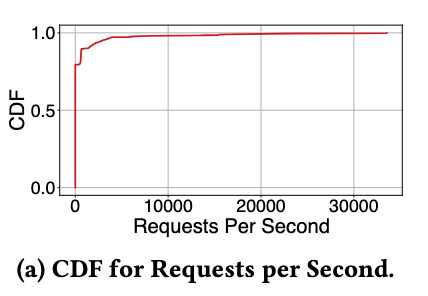
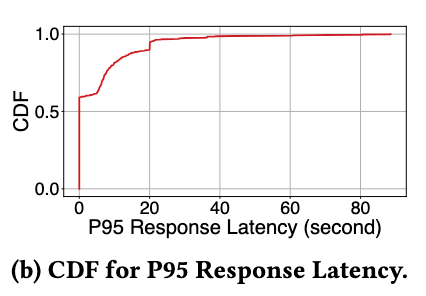
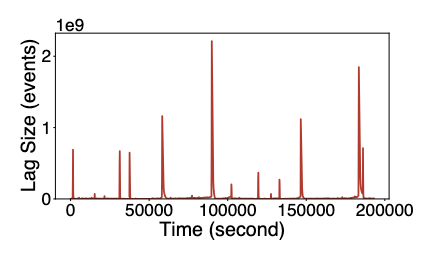
首先展示 StreamOps 对集群层面的作业大规模运行式管控能力的评估。我们在生产环境中部署了一个有 50 个节点组成的 StreamOps 集群进行压测,每个节点配置了 16 核 CPU 和 32 GB 内存。从下图可以看到 StreamOps 可以在最多每秒 33k 个请求的情况下达到 P95 60s 以内的响应时间,说明了系统具备很好的伸缩性。
5.2 自动扩缩容效果
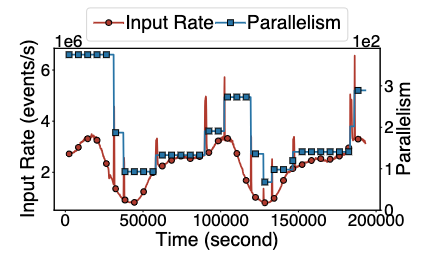
这里展示了自动扩缩容在一个大流量生产作业上的执行效果:图 a 展示了作业并行度随着作业入流速率变化的情况,图 b 展示了期间消息积压的变化。可以看到 StreamOps 可以有效的根据作业入流速率扩缩容,并且可以节约至少 60% 的 CPU 资源。当然也可以看到扩缩容本身会造成消息的暂时堆积,所以各作业可以更细粒度地调参来权衡扩缩容的开销和自动扩缩容的灵敏度。
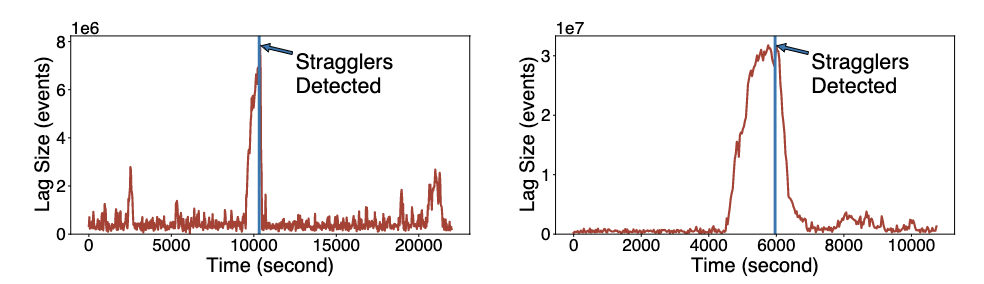
5.3 慢节点自动迁移效果
下图展示了字节内部两个有代表性的生产作业受慢节点影响导致消息积压的案例,StreamOps 可以准确识别并自动迁移慢节点,有效解决因慢节点导致的消息积压问题。
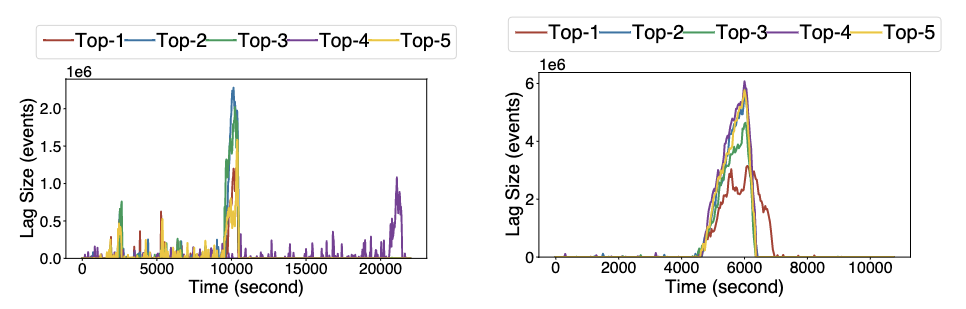
下图进一步展示了上述两个作业 top-5 积压的 Partition 和对应的积压量,可见 80% 以上的消息积压集中在 top-5 Partition 中,说明了消费这些 Partition 的节点运行在慢节点上,StreamOps 准确识别了这些慢节点并且迁移后确实积压得到了解决。
5.4 智能诊断效果
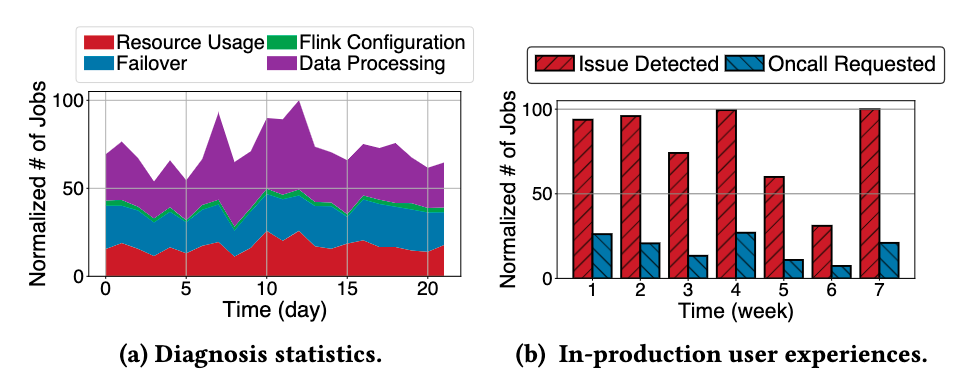
图 a 中展示了一段时间内每天使用 StreamOps 成功诊断出的各大类运行时问题的数量,图 b 展示了一周内每天成功诊断出的问题数和使用诊断后继续进入人工 Oncall 处理的对比。之前当遇到运行时问题时,用户通常会直接拉起人工 Oncall,可以看到接入智能诊断有效降低了人工 Oncall 的数量。
总结
本文提出了一个基于云原生构建的流式任务运行时管控系统 StreamOps。作者通过将其实现为一个独立在流式作业外部的独立无状态服务,使得其可以高效地统一管理大规模的流式作业。提出将总体管控流程拆分为策略和与外部系统交互的通用机制两部分并将策略部分抽象为发现-诊断-解决三步走的通用编程范式进行定义,使其可以低成本快速实现新的管控策略。实现了自动扩缩容、慢节点自动迁移和延迟/故障智能诊断三大类管控策略解决了生产实践中消息积压、运行时故障和资源浪费的痛点,并在字节跳动内部的生产环境验证了其高效性和有效性。
作者简介:
陈张昊,字节跳动基础架构工程师。流式计算专家,Apache Flink Contributor。伊利诺伊大学香槟分校硕士,毕业后一直从事流计算相关研发工作。
张一凡,字节跳动基础架构工程师。流式计算专家,杭州电子科技大学硕士,曾就职网易,目前在字节跳动专职于流式计算系统和服务研发工作。
引用
[1]https://www.usenix.org/conference/osdi18/presentation/kalavri
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12











 鲁公网安备37020202000738号
鲁公网安备37020202000738号