Golang调度模型深度解析
发表时间: 2020-03-16 10:16
1 goroutine
在java/c++中我们要实现并发编程的时候,我们通常需要自己维护一个线程池,并且需要自己去包装一个又一个的任务,同时需要自己去调度线程执行任务并维护上下文切换,这一切通常会耗费程序员大量的心智。那么能不能有一种机制,程序员只需要定义很多个任务,让系统去帮助我们把这些任务分配到CPU上实现并发执行呢?
Go语言中的 goroutine 就是这样一种机制, goroutine 的概念类似于线程,但 goroutine 是由Go的运行时(runtime)调度和管理的。Go程序会智能地将 goroutine 中的任务合理地分配给每个CPU。Go语言之所以被称为现代化的编程语言,就是因为它在语言层面已经内置了调度和上下文切换的机制。
在Go语言编程中你不需要去自己写进程、线程、协程,你的技能包里只有一个技能– goroutine ,当你需要让某个任务并发执行的时候,你只需要把这个任务包装成一个函数,开启一个 goroutine 去执行这个函数就可以了,就是这么简单粗暴。
并发(Concurrency)
指在同一时刻只能有一条指令执行,但多个进程指令被快速的轮换执行,使得在宏观上具有多个进程同时执行的效果,但在微观上并不是同时执行的(宏观上是同时的,微观仍是顺序执行),只是把时间分成若干段,使多个进程快速交替的执行。
并行(Parallel )
指在同一时刻,有多条指令在多个处理器上同时执行。所以无论从微观还是从宏观来看,二者都是一起执行的。
进程(Process)
进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。每个进程都有自己的独立内存空间,不同进程通过进程间通信来通信。由于进程比较重量,占据独立的内存,所以上下文进程间的切换开销(栈、寄存器、虚拟内存、文件句柄等)比较大,但相对比较稳定安全。 进程就是一个程序运行时候的所需要的基本资源单位(也可以说是程序运行的一个实体)。
线程(Thread)
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。线程模型一般分三种(N:1,1:1,M:N),由用户级线程和 OS 线程的不同对应关系决定。
协程(Coroutine)
协程是一种 用户态的轻量级线程 ,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
GPM 是Go语言运行时(runtime)层面的实现,是go语言自己实现的一套调度系统。区别于操作系统调度OS线程。
GPM(machine)P 与 M 一般也是一一对应的。他们关系是:: P 管理着一组 G 挂载在 M 上运行。当一个 G 长久阻塞在一个 M 上时,runtime会新建一个 M ,阻塞 G 所在的 P 会把其他的 G 挂载在新建的 M 上。当旧的 G 阻塞完成或者认为其已经死掉时 回收旧的 M 。
P 的个数是通过 runtime.GOMAXPROCS 设定(最大256),Go1.5版本之后默认为物理线程数。 在并发量大的时候会增加一些 P 和 M ,但不会太多,切换太频繁的话得不偿失。
单从线程调度讲,Go语言相比起其他语言的优势在于OS线程是由OS内核来调度的, goroutine 则是由Go运行时(runtime)自己的调度器调度的,这个调度器使用一个称为m:n调度的技术(复用/调度m个goroutine到n个OS线程)。 其一大特点是goroutine的调度是在用户态下完成的, 不涉及内核态与用户态之间的频繁切换,包括内存的分配与释放,都是在用户态维护着一块大的内存池, 不直接调用系统的malloc函数(除非内存池需要改变),成本比调度OS线程低很多。 另一方面充分利用了多核的硬件资源,近似的把若干goroutine均分在物理线程上, 再加上本身goroutine的超轻量,以上种种保证了go调度方面的性能。
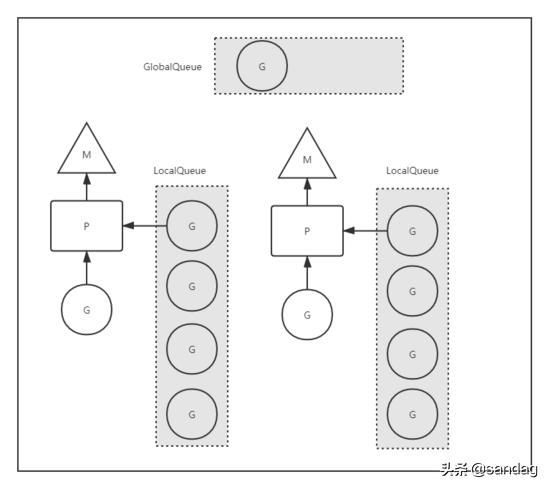
groutine调度
本地队列(LocalQueue)
LQ本地是相对 P 而言的本地,每个 P 维护一个本地队列;与 P 绑定的 M 中如若生成新的 G ,一般情况下会放到 P 的本地队列;当本地队列满了的时候,才会截取本地队列中 “一半” 的元素放入全局队列中。
全局队列(GlobalQueue)
GQ承载本地队列“溢出”的 G 。为了保证调度公平性,调度过程中有 1/61 的几率优先检查全局队列,否则本地队列一直满载的情况下,全局队列中的 G 将永远无法被调度到。
综上,整个调度流程就是:
n = min(len(GQ)/GOMAXPROCS + 1, len(GQ/2))只要找到了 G , 就会立马丢给 M 执行。当然上述任何执行逻辑如果没有 running 的 M 参与,都是无法真正被执行的,这包括调度逻辑本身。
一言蔽之,调度的本质就是 P 将 G 合理的分配给某个 M 的过程。
假设调度中全局和本地队列均为空, M 此时没有任何任务可以处理,那么你会选择让 M 进入阻塞状态还是选择让 CPU 空转等待 G 的驾临?
Go 的设计者们倾向于高性能的并发表现,选择了后者。为了避免过多浪费 CPU 资源,自旋的线程数不会超过 GOMAXPROCS ,这是因为一个 P 在同一个时刻只能绑定一个 M , P 的数量不会超过 GOMAXPROCS,自然被绑定的 M 的数量也不会超过。对于未被绑定的“游离态”的 M ,会进入休眠阻塞态。
M 如果因为 G 发起了系统调用进入了阻塞态会怎样?
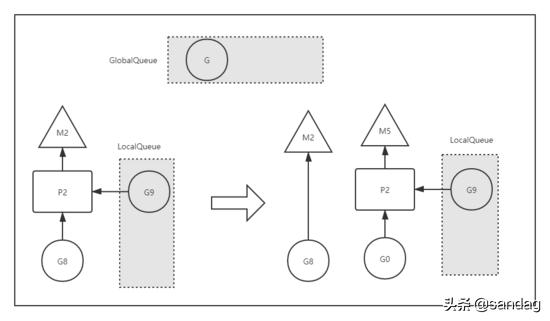
groutine调度--G阻塞.png
如图,如果 G8 发起了阻塞系统调用(例如阻塞 IO 操作),使得对应的 M2 进入了阻塞态。此时如果没有任何的处理,Go Scheduler 就会在这段阻塞的时间内,白白缺失了一个 OS 线程单元。
Go 设计者的解决方案是,一旦 G8 发起 Syscall 使得 M2 进入阻塞态,此时的 P2 会立即与 M2 解绑,保留 M2 与 G8 的关系,继而与新的 OS 线程 M5 绑定,继续下一轮的调度。那么虽然 M2 进入了阻塞态,但宏观来看,并没有缺失任何处理单元, P2 依然正常工作。
G8 失去了 P2 ,意味着失去了执行机会, M2 被唤醒以后第一件事就是要窃取一个上下文(Processor),还给 G8 执行机会。然而现实是 M2 不一定能够找到 P 绑定,不过找不到也没关系, M2 会将 G8 丢到全局队列中,等待调度。
这样一来 G8 会被其他的 M 调度到,重新获得执行机会,继续执行阻塞返回之后的逻辑。
Go 并发调度的优势在哪呢?
原生支持;调度算法更加科学,更具备普适性;另外,简洁的语法掩盖了底层细节,这让开发者轻松实现高性能并发编程,成为可能。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号