并查集:数据结构与算法(九)的深度解析
发表时间: 2023-01-12 22:48
并查集是一种树型的数据结构 ,并查集可以高效地进行如下操作:

并查集也是一种树型结构,但这棵树跟我们之前讲的二叉树、红黑树、B树等都不一样,这种树的要求比较简单:
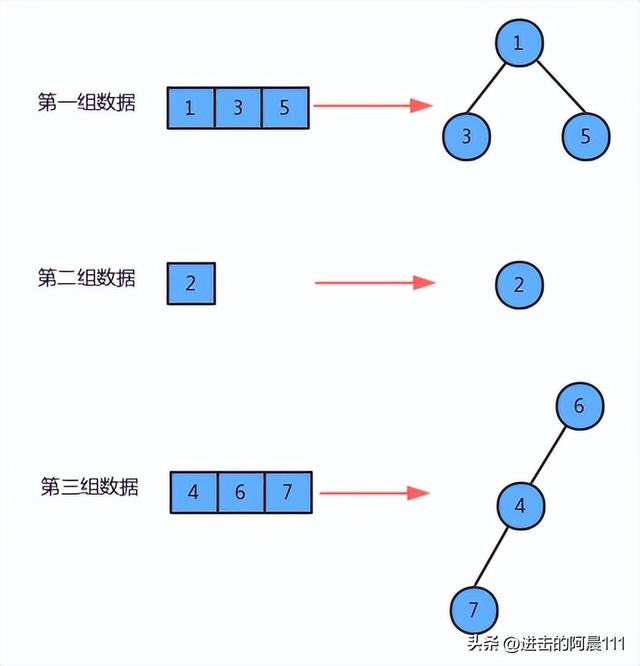
类名 | UnionFind |
构造方法 | UnionFind(int n):初始化并查集,以整数标识(0, n-1)个结点 |
成员方法 | public int count():获取当前并查集中的数据有多少个分组 public boolean connected(int p, int q):判断并查集中元素p和元素q是否在同一分组中 public int find(int p):元素p所在分组的标识符 public void union(int p, int q):把p元素所在分组和q元素所在分组合并 |
成员变量 | private int[] eleAndGroup:记录结点元素和该元素所在分组的标识 private int count:记录并查集中数据的分组个数 |

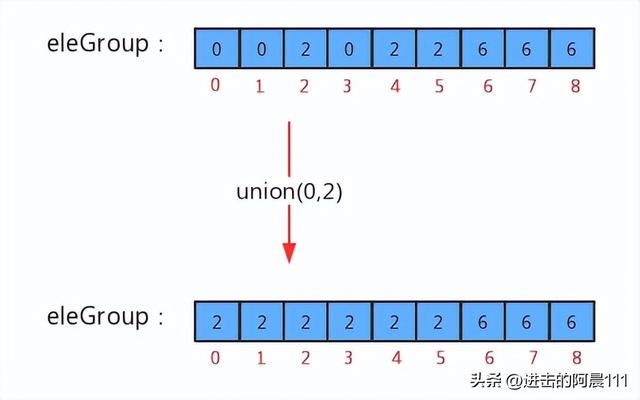
public class UnionFind { /** * 记录结点元素和该元素所在分组的标识 */ private final int[] eleAndGroup; /** * 记录并查集中数据的分组个数 */ private int count; public UnionFind(int n) { // 初始化分组的数量,默认情况下,有n个分组 count = n; // 初始化eleAndGroup数组 eleAndGroup = new int[n]; // 初始化eleAndGroup中的元素及其所在的组的标识符,让eleAndGroup数组的索引作为并查集的每个节点的元素,并且让每个索引处的值就是该索引(该元素所在的组的标识符) for (int i = 0; i < eleAndGroup.length; i++) { eleAndGroup[i] = i; } } /** * 获取当前并查集中的数据有多少个分组 */ public int count() { return count; } /** * 判断并查集中元素p和元素q是否在同一分组中 */ public boolean connected(int p, int q) { return find(p) == find(q); } /** * 元素p所在分组的标识符 */ public int find(int p) { return eleAndGroup[p]; } /** * 把p元素所在分组和q元素所在分组合并 */ public void union(int p, int q) { // 判断p和q是否在同一分组,直接结束方法 if (connected(p, q)) { return; } // 找到p所在分组的标识符 var pGroup = find(p); // 找到q所在分组的标识符 var qGroup = find(q); // 合并组:将p元素所在组的所有的元素的组标识符修改为q元素所在组的标识符 for (int i = 0; i < eleAndGroup.length; i++) { if (pGroup == eleAndGroup[i]) { eleAndGroup[i] = qGroup; } } count--; }}测试代码
class UnionFindTest { @Test void testUnionFind() { var uf = new UnionFind(5); assertEquals(5, uf.count()); // 合并0和1 uf.union(0, 1); assertTrue(uf.connected(0, 1)); assertEquals(4, uf.count()); // 合并1和2 uf.union(1, 2); assertTrue(uf.connected(1, 2)); assertTrue(uf.connected(0, 2)); assertEquals(3, uf.count()); // 合并0和2,因为已经在同一分组,所以分组数不会减少 uf.union(0, 2); assertEquals(3, uf.count()); }}如果我们并查集存储的每一个整数表示的是一个大型计算机网络中的计算机,则我们就可以通过 connected(int p, int q) 来检测,该网络中的某两台计算机之间是否连通?
如果连通,则他们之间可以通信,如果不连通,则不能通信,此时我们又可以调用 union(int p, int q) 使得p和q之间连通,这样两台计算机之间就可以通信了。
一般像计算机这样网络型的数据,我们要求网络中的每两个数据之间都是相连通的,也就是说,我们需要调用很多次 union 方法,使得网络中所有数据相连。
其实我们很容易可以得出,如果要让网络中的数据都相连,则我们至少要调用 N-1 次 union方法才可以,但由于我们的 union 方法中使用 for 循环遍历了所有的元素,所以很明显,我们之前实现的合并算法的时间复杂度是 O(N^2)。
如果要解决大规模问题,它是不合适的,所以我们需要对算法进行优化。
为了提升 union 算法的性能,我们需要重新设计 find 方法和 union 方法的实现,此时我们先需要对我们的之前数据结构中的 eleAndGourp 数组的含义进行重新设定:

类名 | UnionFindTree |
构造方法 | UnionFindTree(int n):初始化并查集,以整数标识 (0, n-1) 个结点 |
成员方法 | public int count():获取当前并查集中的数据有多少个分组 public boolean connected(int p, int q):判断并查集中元素p和元素q是否在同一分组中 public int find(int p):元素p所在分组的标识符 public void union(int p, int q):把p元素所在分组和q元素所在分组合并 |
成员变量 | private int[] eleAndGroup:记录结点元素和该元素的父结点 private int count:记录并查集中数据的分组个数 |

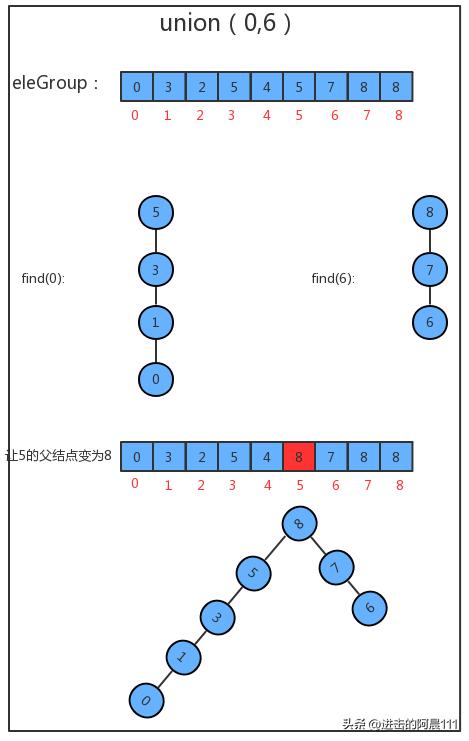
public class UnionFindTree { /** * 记录结点元素和该元素的父结点 */ private final int[] eleAndGroup; /** * 记录并查集中数据的分组个数 */ private int count; public UnionFindTree(int n) { // 初始化分组的数量,默认情况下,有n个分组 count = n; // 初始化eleAndGroup数组 eleAndGroup = new int[n]; // 初始化eleAndGroup中的元素及其所在的组的标识符,让eleAndGroup数组的索引作为并查集的每个节点的元素,并且让每个索引处的值就是该索引(该元素所在的组的标识符) for (int i = 0; i < eleAndGroup.length; i++) { eleAndGroup[i] = i; } } /** * 获取当前并查集中的数据有多少个分组 */ public int count() { return count; } /** * 判断并查集中元素p和元素q是否在同一分组中 */ public boolean connected(int p, int q) { return find(p) == find(q); } /** * 元素p所在分组的标识符 */ public int find(int p) { while (true) { if (p == eleAndGroup[p]) { return p; } p = eleAndGroup[p]; } } /** * 把p元素所在分组和q元素所在分组合并 */ public void union(int p, int q) { // 找到p元素和q元素所在组对应的树的根节点 int pRoot = find(p); int qRoot = find(q); if (pRoot == qRoot) { return; } // 让p所在树的根节点的父节点为q所在树的根节点 eleAndGroup[pRoot] = qRoot; count--; }}测试代码
class UnionFindTreeTest { @Test void testUnionFindTree() { var ufTree = new UnionFindTree(5); assertEquals(5, ufTree.count()); // 合并0和1 ufTree.union(0, 1); assertTrue(ufTree.connected(0, 1)); assertEquals(4, ufTree.count()); // 合并1和2 ufTree.union(1, 2); assertTrue(ufTree.connected(1, 2)); assertTrue(ufTree.connected(0, 2)); assertEquals(3, ufTree.count()); // 合并0和2,因为已经在同一分组,所以分组数不会减少 ufTree.union(0, 2); assertEquals(3, ufTree.count()); }}我们优化后的算法 union,如果要把并查集中所有的数据连通,仍然至少要调用 N-1 次union方法,但是,我们发现 union 方法中已经没有了 for 循环,所以 union 算法的时间复杂度由O(N^2) 变为了 O(N)。
但是这个算法仍然有问题,因为我们之前不仅修改了 union 算法,还修改了 find 算法。
我们修改前的 find 算法的时间复杂度在任何情况下都为 O(1),但修改后的 find 算法在最坏情况下是 O(N):

在 union 方法中调用了 find 方法,所以在最坏情况下 union 算法的时间复杂度仍然为 O(N^2)。
UnionFindTree中最坏情况下 union 算法的时间复杂度为 O(N^2),其最主要的问题在于最坏情况下,树的深度和数组的大小一样,如果我们能够通过一些算法让合并时,生成的树的深度尽可能的小,就可以优化 find 方法。
之前我们在 union 算法中,合并树的时候将任意的一棵树连接到了另外一棵树,这种合并方法是比较暴力的。
如果我们把并查集中每一棵树的大小记录下来,然后在每次合并树的时候,把较小的树连接到较大的树上,就可以减小树的深度。

只要我们保证每次合并,都能把小树合并到大树上,就能够压缩合并后新树的路径,这样就能提高 find 方法的效率。
为了完成这个需求,我们需要另外一个数组来记录存储每个根结点对应的树中元素的个数,并且需要一些代码调整数组中的值。
类名 | UnionFindTreeWeighted |
构造方法 | UnionFindTreeWeighted(int n):初始化并查集,以整数标识(0, n-1)个结点 |
成员方法 | public int count():获取当前并查集中的数据有多少个分组 public boolean connected(int p, int q):判断并查集中元素p和元素q是否在同一分组中 public int find(int p):元素p所在分组的标识符 public void union(int p, int q):把p元素所在分组和q元素所在分组合并 |
成员变量 | private int[] eleAndGroup:记录结点元素和该元素的父结点 private int[] sz:存储每个根结点对应的树中元素的个数 private int count:记录并查集中数据的分组个数 |
public class UnionFindTreeWeighted { /** * 记录结点元素和该元素的父结点 */ private final int[] eleAndGroup; /** * 存储每个根结点对应的树中元素的个数 */ private final int[] sz; /** * 记录并查集中数据的分组个数 */ private int count; public UnionFindTreeWeighted(int n) { // 初始化分组的数量,默认情况下,有n个分组 this.count = n; // 初始化eleAndGroup数组 this.eleAndGroup = new int[n]; // 初始化eleAndGroup中的元素及其所在的组的标识符,让eleAndGroup数组的索引作为并查集的每个节点的元素,并且让每个索引处的值就是该索引(该元素所在的组的标识符) for (int i = 0; i < eleAndGroup.length; i++) { this.eleAndGroup[i] = i; } this.sz = new int[n]; Arrays.fill(this.sz, 1); } /** * 获取当前并查集中的数据有多少个分组 */ public int count() { return count; } /** * 判断并查集中元素p和元素q是否在同一分组中 */ public boolean connected(int p, int q) { return find(p) == find(q); } /** * 元素p所在分组的标识符 */ public int find(int p) { while (true) { if (p == eleAndGroup[p]) { return p; } p = eleAndGroup[p]; } } /** * 把p元素所在分组和q元素所在分组合并 */ public void union(int p, int q) { // 找到p元素和q元素所在组对应的树的根节点 int pRoot = find(p); int qRoot = find(q); if (pRoot == qRoot) { return; } // 判断pRoot对应的树大,还是qRoot对应的树大,最终需要吧较小的树合并到较大的树中 if (sz[pRoot] < sz[qRoot]) { eleAndGroup[pRoot] = qRoot; sz[qRoot] += sz[pRoot]; } else { eleAndGroup[qRoot] = pRoot; sz[pRoot] += sz[qRoot]; } count--; }}测试代码
class UnionFindTreeWeightedTest { @Test void testUnionFindTreeWeighted() { var ufTreeWeighted = new UnionFindTree(5); assertEquals(5, ufTreeWeighted.count()); // 合并0和1 ufTreeWeighted.union(0, 1); assertTrue(ufTreeWeighted.connected(0, 1)); assertEquals(4, ufTreeWeighted.count()); // 合并1和2 ufTreeWeighted.union(1, 2); assertTrue(ufTreeWeighted.connected(1, 2)); assertTrue(ufTreeWeighted.connected(0, 2)); assertEquals(3, ufTreeWeighted.count()); // 合并0和2,因为已经在同一分组,所以分组数不会减少 ufTreeWeighted.union(0, 2); assertEquals(3, ufTreeWeighted.count()); }}某省调查城镇交通状况,得到现有城镇道路统计表,表中列出了每条道路直接连通的城镇。省政府“畅通工程”的目标是使全省任何两个城镇间都可以实现交通(但不一定有直接的道路相连,只要互相间接通过道路可达即可)。
问:最少还需要建设多少条道路?
新建一个 traffic_project.txt 文件,内容如下:
2070 16 93 85 112 126 104 8它就是诚征道路统计表,下面是对数据的解释:

总共有20个城市,目前已经修改好了7条道路,问:还需要修建多少条道路,才能让这20个城市之间全部相通?
@Slf4jclass UnionFindTreeWeightedTest { /** * 案例-畅通工程 */ @Test void trafficProject() throws IOException { var br = new BufferedReader(new InputStreamReader(UnionFindTreeWeightedTest.class.getClassLoader().getResourceAsStream("traffic_project.txt"))); // 读取第一行数据 var totalNumber = Integer.parseInt(br.readLine()); // 创建并查集 var uf = new UnionFindTreeWeighted(totalNumber); // 读取第二行数据 var roadNumber = Integer.parseInt(br.readLine()); for (int i = 0; i < roadNumber; i++) { var line = br.readLine(); var arr = line.split(" "); var p1 = Integer.parseInt(arr[0]); var p2 = Integer.parseInt(arr[1]); // 让2个城市相通 uf.union(p1, p2); } // 当前并查集剩余分组的数量 - 1,就是结果 var roads = uf.count() - 1; // 还需要12条道路才能畅通 LOGGER.info("还需要{}条道路才能畅通", roads); }}测试结果:还需要12条道路才能畅通,是符合题意的。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号