计算机科学新视角:Python数据结构与算法分析
发表时间: 2019-09-03 18:06

自从第一台利用转接线和开关来传递计算指令的电子计算机诞生以来,人们对编程的认识历经了多次变化。与社会生活的其他许多方面一样,计算机技术的变革为计算机科学家提供了越来越多的工具和平台去施展他们的才能。高效的处理器、高速网络以及大容量内存等一系列新技术,要求计算机科学家掌握更多复杂的知识。然而,在这一系列快速的变革之中,仍有一些基本原则始终保持不变。
计算机科学被认为是一门利用计算机来解决问题的学科。
你肯定在学习解决问题的基本方法上投入过大量的时间,并且相信自己拥有根据问题描述构建解决方案的能力。你肯定也体会到了编写计算机程序的困难之处。大型难题及其解决方案的复杂性往往会掩盖问题解决过程的核心思想。
本文会复习计算机科学以及数据结构与算法的研究必须符合的框架,尤其是学习这些内容的原因以及为什么说理解它们有助于更好地解决问题。
要定义计算机科学,通常十分困难,这也许是因为其中的“计算机”一词。你可能已经意识到,计算机科学并不仅是研究计算机本身。尽管计算机在这一学科中是非常重要的工具,但也仅仅只是工具而已。
计算机科学的研究对象是问题、解决问题的过程,以及通过该过程得到的解决方案。给定一个问题,计算机科学家的目标是开发一个能够逐步解决该问题的算法。算法是具有有限步骤的过程,依照这个过程便能解决问题。因此,算法就是解决方案。
可以认为计算机科学就是研究算法的学科。但是必须注意,某些问题并没有解决方案。对于学习计算机科学的人来说,认清这一事实非常重要。结合上述两类问题,可以将计算机科学更完善地定义为:研究问题及其解决方案,以及研究目前无解的问题的学科。
在描述问题及其解决方案时,经常用到“可计算”一词。若存在能够解决某个问题的算法,那么该问题便是可计算的。因此,计算机科学也可以被定义为:研究可计算以及不可计算的问题,即研究算法的存在性以及不存在性。在上述任意一种定义中,“计算机”一词都没有出现。解决方案本身是独立于计算机的。
在研究问题解决过程的同时,计算机科学也研究抽象。抽象思维使得我们能分别从逻辑视角和物理视角来看待问题及其解决方案。举一个常见的例子。
试想你每天开车去上学或上班。作为车的使用者,你在驾驶时会与它有一系列的交互:坐进车里,插入钥匙,启动发动机,换挡,刹车,加速以及操作方向盘。从抽象的角度来看,这是从逻辑视角来看待这辆车,你在使用由汽车设计者提供的功能来将自己从某个地方运送到另一个地方。这些功能有时候也被称作接口。
另一方面,修车工看待车辆的角度与司机截然不同。他不仅需要知道如何驾驶,而且更需要知道实现汽车功能的所有细节:发动机如何工作,变速器如何换挡,如何控制温度,等等。这就是所谓的物理视角,即看到表面之下的实现细节。
使用计算机也是如此。大多数人用计算机来写文档、收发邮件、浏览网页、听音乐、存储图像以及打游戏,但他们并不需要了解这些功能的实现细节。大家都是从逻辑视角或者使用者的角度来看待计算机。计算机科学家、程序员、技术支持人员以及系统管理员则从另一个角度来看待计算机。他们必须知道操作系统的原理、网络协议的配置,以及如何编写各种脚本来控制计算机。他们必须能够控制用户不需要了解的底层细节。
上面两个例子的共同点在于,抽象的用户(或称客户)只需要知道接口是如何工作的,而并不需要知道实现细节。这些接口是用户用于与底层复杂的实现进行交互的方式。下面是抽象的另一个例子,来看看Python 的math 模块。一旦导入这一模块,便可以进行如下的计算。
>>> import math>>> math.sqrt(16)4.0>>>
这是一个过程抽象的例子。我们并不需要知道平方根究竟是如何计算出来的,而只需要知道计算平方根的函数名是什么以及如何使用它。只要正确地导入模块,便可以认为这个函数会返回正确的结果。由于其他人已经实现了平方根问题的解决方案,因此我们只需要知道如何使用该函数即可。这有时候也被称为过程的“黑盒”视角。我们仅需要描述接口:函数名、所需参数,以及返回值。所有的计算细节都被隐藏了起来,如图1 所示。
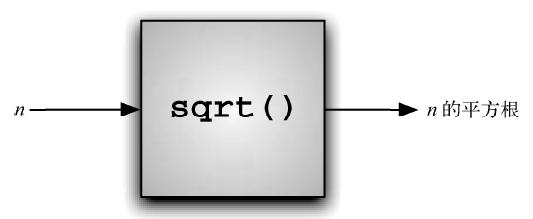
图1 过程抽象
编程是指通过编程语言将算法编码以使其能被计算机执行的过程。尽管有众多的编程语言和不同类型的计算机,但是首先得有一个解决问题的算法。如果没有算法,就不会有程序。
计算机科学的研究对象并不是编程。但是,编程是计算机科学家所做工作的一个重要组成部分。通常,编程就是为解决方案创造表达方式。因此,编程语言对算法的表达以及创造程序的过程是这一学科的基础。
通过定义表达问题实例所需的数据,以及得到预期结果所需的计算步骤,算法描述出了问题的解决方案。编程语言必须提供一种标记方式,用于表达过程和数据。为此,编程语言提供了众多的控制语句和数据类型。
控制语句使算法步骤能够以一种方便且明确的方式表达出来。算法至少需要能够进行顺序执行、决策分支、循环迭代的控制语句。只要一种编程语言能够提供这些基本的控制语句,它就能够被用于描述算法。
计算机中的所有数据实例均由二进制字符串来表达。为了赋予这些数据实际的意义,必须要有数据类型。数据类型能够帮助我们解读二进制数据的含义,从而使我们能从待解决问题的角度来看待数据。这些內建的底层数据类型(又称原生数据类型)提供了算法开发的基本单元。
举例来说,大部分编程语言都为整数提供了相应的数据类型。根据整数(如23、654 以及–19)的常见定义,计算机内存中的二进制字符串可以被理解成整数。除此以外,数据类型也描述了该类数据能参与的所有运算。对于整数来说,就有加减乘除等常见运算。并且,对于数值类型的数据,以上运算均成立。
我们经常遇到的困难是,问题及其解决方案都过于复杂。尽管由编程语言提供的简单的控制语句和数据类型能够表达复杂的解决方案,但它们在解决问题的过程中仍然存在不足。因此,我们需要想办法控制复杂度以利于找到解决方案。
为了控制问题及其求解过程的复杂度,计算机科学家利用抽象来帮助自己专注于全局,从而避免迷失在众多细节中。通过对问题进行建模,可以更高效地解决问题。模型可以帮助计算机科学家更一致地描述算法要用到的数据。
如前所述,过程抽象将功能的实现细节隐藏起来,从而使用户能从更高的视角来看待功能。数据抽象的基本思想与此类似。抽象数据类型(有时简称为ADT)从逻辑上描述了如何看待数据及其对应运算而无须考虑具体实现。这意味着我们仅需要关心数据代表了什么,而可以忽略它们的构建方式。通过这样的抽象,我们对数据进行了一层封装,其基本思想是封装具体的实现细节,使它们对用户不可见,这被称为信息隐藏。
图2 展示了抽象数据类型及其原理。用户通过利用抽象数据类型提供的操作来与接口交互。抽象数据类型是与用户交互的外壳。真正的实现则隐藏在内部。用户并不需要关心各种实现细节。
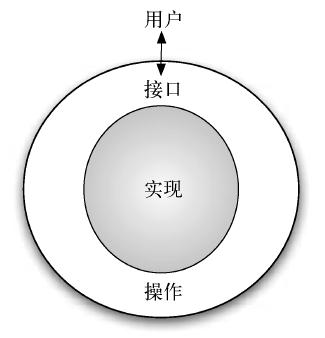
图2 抽象数据类型
抽象数据类型的实现常被称为数据结构,这需要我们通过编程语言的语法结构和原生数据类型从物理视角看待数据。正如之前讨论的,分成这两种不同的视角有助于为问题定义复杂的数据模型,而无须考虑模型的实现细节。这便提供了一个独立于实现的数据视角。由于实现抽象数据类型通常会有很多种方法,因此独立于实现的数据视角使程序员能够改变实现细节而不影响用户与数据的实际交互。用户能够始终专注于解决问题。
计算机科学家通过经验来学习:观察他人如何解决问题,然后亲自解决问题。接触各种问题解决技巧并学习不同算法的设计方法,有助于解决新的问题。通过学习一系列不同的算法,可以举一反三,从而在遇到类似的问题时,能够快速加以解决。
各种算法之间往往差异巨大。回想前文提到的平方根的例子,完全可能有多种方法来实现计算平方根的函数。算法一可能使用了较少的资源,算法二返回结果所需的时间可能是算法一的10 倍。我们需要某种方式来比较这两种算法。尽管这两种算法都能得到结果,但是其中一种可能比另一种“更好”——更高效、更快,或者使用的内存更少。随着对算法的进一步学习,你会掌握比较不同算法的分析技巧。这些技巧只依赖于算法本身的特性,而不依赖于程序或者实现算法的计算机的特性。
最坏的情况是遇到难以解决的问题,即没有算法能够在合理的时间内解决该问题。因此,至关重要的一点是,要能区分有解的问题、无解的问题,以及虽然有解但是需要过多的资源和时间来求解的问题。
在选择算法时,经常会有所权衡。除了有解决问题的能力之外,计算机科学家也需要知晓如何评估一个解决方案。总之,问题通常有很多解决方案,如何找到一个解决方案并且确定其为优秀的方案,是需要反复练习、熟能生巧的。
下面我们将复习Python,并且为前面提到的思想提供更详细的例子。如果你刚开始学习Python或者觉得自己需要更多的信息,建议你查看《Python数据结构与算法分析(第2版)》结尾列出的Python 资源。
Python 是一门现代、易学、面向对象的编程语言。它拥有强大的內建数据类型以及简单易用的控制语句。由于Python 是一门解释型语言,因此只需要查看和描述交互式会话就能进行学习。
你应该记得,解释器会显示提示符>>>,然后计算你提供的Python 语句。例如,以下代码显示了提示符、print 函数、结果,以及下一个提示符。
>>> print("Algorithms and Data Structures")>>> Algorithms and Data Structures>>>一、数据
前面提到,Python 支持面向对象编程范式。这意味着Python 认为数据是问题解决过程中的关键点。在Python 以及其他所有面向对象编程语言中,类都是对数据的构成(状态)以及数据能做什么(行为)的描述。由于类的使用者只能看到数据项的状态和行为,因此类与抽象数据类型是相似的。在面向对象编程范式中,数据项被称作对象。一个对象就是类的一个实例。
1. 内建原子数据类型
我们首先复习原子数据类型。Python 有两大內建数据类实现了整数类型和浮点数类型,相应的Python 类就是int 和float。标准的数学运算符,即+、-、*、/以及**(幂),可以和能够改变运算优先级的括号一起使用。其他非常有用的运算符包括取余(取模)运算符%,以及整除运算符//。注意,当两个整数相除时,其结果是一个浮点数,而整除运算符截去小数部分,只返回商的整数部分。
>>> 2+3*414>>> (2+3)*420>>> 2**101024>>> 6/32.0>>> 7/32.3333333333333335>>> 7//32>>> 7%31>>> 3/60.5>>> 3//60>>> 3%63>>> 2**1001267650600228229401496703205376>>>
Python 通过bool 类实现对表达真值非常有用的布尔数据类型。布尔对象可能的状态值是True 或者False,布尔运算符有and、or 以及not。
>>> TrueTrue>>> FalseFalse>>> False or TrueTrue>>> not (False or True)False>>> True and TrueTrue
布尔对象也被用作相等(==)、大于(>)等比较运算符的计算结果。此外,结合使用关系运算符与逻辑运算符可以表达复杂的逻辑问题。表1-1 展示了关系运算符和逻辑运算符。


>>> 5 == 10False>>> 10 > 5True>>> (5 >= 1) and (5 <= 10)True
标识符在编程语言中被用作名字。Python 中的标识符以字母或者下划线(_)开头,区分大小写,可以是任意长度。需要记住的一点是,采用能表达含义的名字是良好的编程习惯,这使程序代码更易阅读和理解。
当一个名字第一次出现在赋值语句的左边部分时,会创建对应的Python 变量。赋值语句将名字与值关联起来。变量存的是指向数据的引用,而不是数据本身。来看看下面的代码。
>>> theSum = 0>>> theSum0>>> theSum = theSum + 1>>> theSum1>>> theSum = True>>> theSumTrue
赋值语句theSum = 0 会创建变量theSum,并且令其保存指向数据对象0 的引用(如图3 所示)。Python 会先计算赋值运算符右边的表达式,然后将指向该结果数据对象的引用赋给左边的变量名。在本例中,由于theSum 当前指向的数据是整数类型,因此该变量类型为整型。如果数据的类型发生改变(如图4 所示),正如上面的代码给theSum 赋值True,那么变量的类型也会变成布尔类型。赋值语句改变了变量的引用,这体现了Python 的动态特性。同样的变量可以指向许多不同类型的数据。

图3 变量指向数据对象的引用
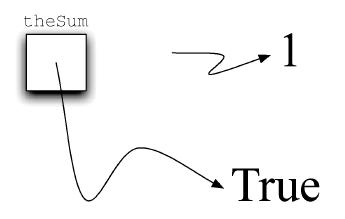
图4 赋值语句改变变量的引用
2. 内建集合数据类型
除了数值类和布尔类,Python 还有众多强大的內建集合类。列表、字符串以及元组是概念上非常相似的有序集合,但是只有理解它们的差别,才能正确运用。集(set)和字典是无序集合。
列表是零个或多个指向Python 数据对象的引用的有序集合,通过在方括号内以逗号分隔的一系列值来表达。空列表就是[]。列表是异构的,这意味着其指向的数据对象不需要都是同一个类,并且这一集合可以被赋值给一个变量。下面的代码段展示了列表含有多个不同的Python 数据对象。
>>> [1,3,True,6.5][1, 3, True, 6.5]>>> myList = [1,3,True,6.5]>>> myList[1, 3, True, 6.5]
注意,当Python 计算一个列表时,这个列表自己会被返回。然而,为了记住该列表以便后续处理,其引用需要被赋给一个变量。
由于列表是有序的,因此它支持一系列可应用于任意Python 序列的运算,如表1-2 所示。

需要注意的是,列表和序列的下标从0 开始。myList[1:3]会返回一个包含下标从1 到2的元素列表(并没有包含下标为3 的元素)。
如果需要快速初始化列表,可以通过重复运算来实现,如下所示。
>>> myList = [0] * 6>>> myList[0, 0, 0, 0, 0, 0]
非常重要的一点是,重复运算返回的结果是序列中指向数据对象的引用的重复。下面的例子可以很好地说明这一点。
>>> myList = [1,2,3,4]>>> A = [myList]*3>>> A[[1, 2, 3, 4], [1, 2, 3, 4], [1, 2, 3, 4]]>>> myList[2] = 45>>> A[[1, 2, 45, 4], [1, 2, 45, 4], [1, 2, 45, 4]]>>>
变量A 包含3 个指向myList 的引用。myList 中的一个元素发生改变,A 中的3 处都随即改变。
列表支持一些用于构建数据结构的方法,如表1-3 所示。后面的例子展示了用法。

>>> myList[1024, 3, True, 6.5]>>> myList.append(False)>>> myList[1024, 3, True, 6.5, False]>>> myList.insert(2,4.5)>>> myList[1024, 3, 4.5, True, 6.5, False]>>> myList.pop()False>>> myList[1024, 3, 4.5, True, 6.5]>>> myList.pop(1)3>>> myList[1024, 4.5, True, 6.5]>>> myList.pop(2)True>>> myList[1024, 4.5, 6.5]>>> myList.sort()>>> myList[4.5, 6.5, 1024]>>> myList.reverse()>>> myList[1024, 6.5, 4.5]>>> myList.count(6.5)1>>> myList.index(4.5)2>>> myList.remove(6.5)>>> myList[1024, 4.5]>>> del myList[0]>>> myList[4.5]
你会发现,像pop 这样的方法在返回值的同时也会修改列表的内容,reverse 等方法则仅修改列表而不返回任何值。pop 默认返回并删除列表的最后一个元素,但是也可以用来返回并删除特定的元素。这些方法默认下标从0 开始。你也会注意到那个熟悉的句点符号,它被用来调用某个对象的方法。myList.append(False)可以读作“请求myList 调用其append 方法并将False 这一值传给它”。就连整数这类简单的数据对象都能通过这种方式调用方法。
>>> (54).__add__(21)75>>>
在上面的代码中,我们请求整数对象54 执行其add 方法(该方法在Python 中被称为__add__),并且将21 作为要加的值传给它。其结果是两数之和,即75。我们通常会将其写作54+21。稍后会更多地讨论这些方法。
range 是一个常见的Python 函数,我们常把它与列表放在一起讨论。range 会生成一个代表值序列的范围对象。使用list 函数,能够以列表形式看到范围对象的值。下面的代码展示了这一点。
>>> range(10)range(0, 10)>>> list(range(10))[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]>>> range(5,10)range(5, 10)>>> list(range(5,10))[5, 6, 7, 8, 9]>>> list(range(5,10,2))[5, 7, 9]>>> list(range(10,1,-1))[10, 9, 8, 7, 6, 5, 4, 3, 2]>>>
范围对象表示整数序列。默认情况下,它从0 开始。如果提供更多的参数,它可以在特定的点开始和结束,并且跳过中间的值。在第一个例子中,range(10)从0 开始并且一直到9 为止(不包含10);在第二个例子中,range(5,10)从5 开始并且到9 为止(不包含10);range(5,10,2)的结果类似,但是元素的间隔变成了2(10 还是没有包含在其中)。
字符串是零个或多个字母、数字和其他符号的有序集合。这些字母、数字和其他符号被称为字符。常量字符串值通过引号(单引号或者双引号均可)与标识符进行区分。
>>> "David"'David'>>> myName = "David">>> myName[3]'i'>>> myName*2'DavidDavid'>>> len(myName)5>>>
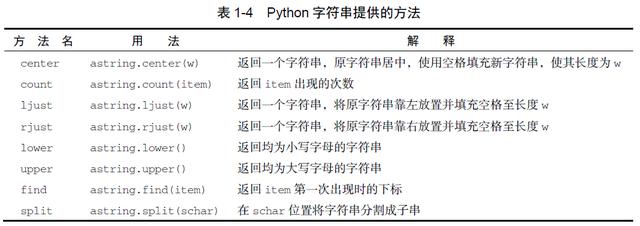
由于字符串是序列,因此之前提到的所有序列运算符都能用于字符串。此外,字符串还有一些特有的方法,表1-4 列举了其中一些。
>>> myName'David'>>> myName.upper()'DAVID'>>> myName.center(10)' David '>>> myName.find('v')2>>> myName.split('v')['Da', 'id']split 在处理数据的时候非常有用。split 接受一个字符串,并且返回一个由分隔字符作为分割点的字符串列表。在本例中,v 就是分割点。如果没有提供分隔字符,那么split 方法将会寻找如制表符、换行符和空格等空白字符。
列表和字符串的主要区别在于,列表能够被修改,字符串则不能。列表的这一特性被称为可修改性。列表具有可修改性,字符串则不具有。例如,可以通过使用下标和赋值操作来修改列表中的一个元素,但是字符串不允许这一改动。
>>> myList[1, 3, True, 6.5]>>> myList[0]=2**10>>> myList[1024, 3, True, 6.5]>>>>>> myName'David'>>> myName[0]='X'Traceback (most recent call last):File "<pyshell#84>", line 1, in -toplevelmyName[0]='X'TypeError: object doesn't support item assignment>>>
由于都是异构数据序列,因此元组与列表非常相似。它们的区别在于,元组和字符串一样是不可修改的。元组通常写成由括号包含并且以逗号分隔的一系列值。与序列一样,元组允许之前描述的任一操作。
>>> myTuple = (2,True,4.96)>>> myTuple(2, True, 4.96)>>> len(myTuple)3>>> myTuple[0]2>>> myTuple * 3(2, True, 4.96, 2, True, 4.96, 2, True, 4.96)>>> myTuple[0:2](2, True)>>>
然而,如果尝试改变元组中的一个元素,就会遇到错误。请注意,错误消息指明了问题的出处及原因。
>>> myTuple[1]=FalseTraceback (most recent call last):File "<pyshell#137>", line 1, in -toplevelmyTuple[1]=FalseTypeError: object doesn't support item assignment>>>
集(set)是由零个或多个不可修改的Python 数据对象组成的无序集合。集不允许重复元素,并且写成由花括号包含、以逗号分隔的一系列值。空集由set()来表示。集是异构的,并且可以通过下面的方法赋给变量。
>>> {3, 6, "cat", 4.5, False}{False, 4.5, 3, 6, 'cat'}>>> mySet = {3, 6, "cat", 4.5, False}>>> mySet{False, 4.5, 3, 6, 'cat'}>>>尽管集是无序的,但它还是支持之前提到的一些运算,如表1-5 所示。
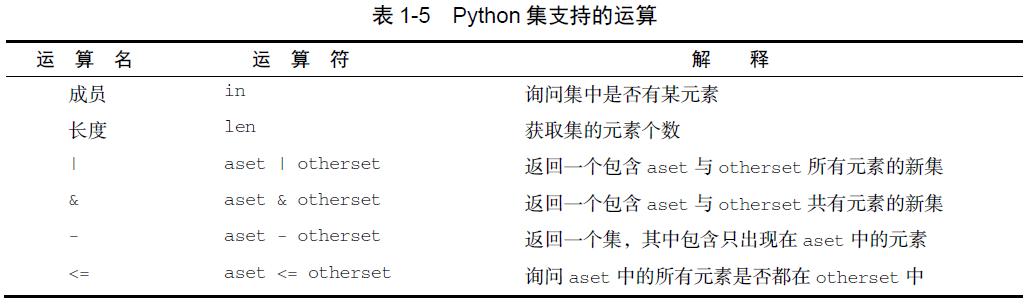
>>> mySet{False, 4.5, 3, 6, 'cat'}>>> len(mySet)5>>> False in mySetTrue>>> "dog" in mySetFalse>>>集支持一系列方法,如表1-6 所示。在数学中运用过集合概念的人应该对它们非常熟悉。注意,union、intersection、issubset 和difference 都有可用的运算符。
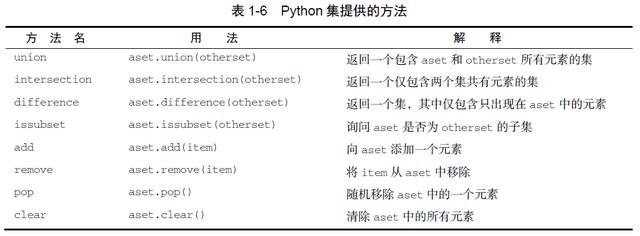
>>> mySet{False, 4.5, 3, 6, 'cat'}>>> yourSet = {99,3,100}>>> mySet.union(yourSet){False, 4.5, 3, 100, 6, 'cat', 99}>>> mySet | yourSet{False, 4.5, 3, 100, 6, 'cat', 99}>>> mySet.intersection(yourSet){3}>>> mySet & yourSet{3}>>> mySet.difference(yourSet){False, 4.5, 6, 'cat'}>>> mySet - yourSet{False, 4.5, 6, 'cat'}>>> {3,100}.issubset(yourSet)True>>> {3,100}<=yourSetTrue>>> mySet.add("house")>>> mySet{False, 4.5, 3, 6, 'house', 'cat'}>>> mySet.remove(4.5)>>> mySet{False, 3, 6, 'house', 'cat'}>>> mySet.pop()False>>> mySet{3, 6, 'house', 'cat'}>>> mySet.clear()>>> mySetset()>>>最后要介绍的Python 集合是字典。字典是无序结构,由相关的元素对构成,其中每对元素都由一个键和一个值组成。这种键–值对通常写成键:值的形式。字典由花括号包含的一系列以逗号分隔的键–值对表达,如下所示。
>>> capitals = {'Iowa':'DesMoines','Wisconsin':'Madison'}>>> capitals{'Wisconsin':'Madison', 'Iowa':'DesMoines'}>>>可以通过键访问其对应的值,也可以向字典添加新的键–值对。访问字典的语法与访问序列的语法十分相似,只不过是使用键来访问,而不是下标。添加新值也类似。
>>> capitals['Iowa']'DesMoines'>>> capitals['Utah']='SaltLakeCity'>>> capitals{'Utah':'SaltLakeCity', 'Wisconsin':'Madison', 'Iowa':'DesMoines'}>>> capitals['California']='Sacramento'>>> capitals{'Utah':'SaltLakeCity', 'Wisconsin':'Madison', 'Iowa':'DesMoines','California':'Sacramento'}>>> len(capitals)4>>>需要谨记,字典并不是根据键来进行有序维护的。第一个添加的键–值对('Utah':'Salt-LakeCity')被放在了字典的第一位,第二个添加的键–值对('California':'Sacramento')则被放在了最后。键的位置是由散列来决定的,第5 章会详细介绍散列。以上示例也说明,len函数对字典的功能与对其他集合的功能相同。
字典既有运算符,又有方法。表1-7 和表1-8 分别展示了它们。keys、values 和items 方法均会返回包含相应值的对象。可以使用list 函数将字典转换成列表。在表1-8 中可以看到,get 方法有两种版本。如果键没有出现在字典中,get 会返回None。然而,第二个可选参数可以返回特定值。
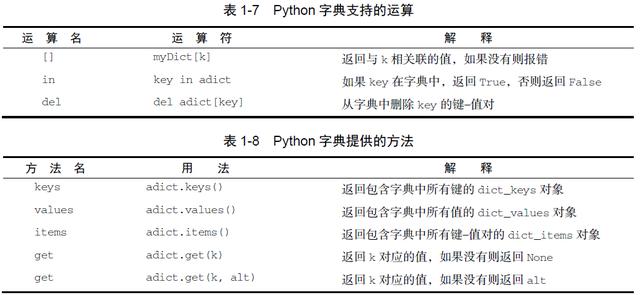
>>> phoneext={'david':1410, 'brad':1137}>>> phoneext{'brad':1137, 'david':1410}>>> phoneext.keys()dict_keys(['brad', 'david'])>>> list(phoneext.keys())['brad', 'david']>>> phoneext.values()dict_values([1137, 1410])>>> list(phoneext.values())[1137, 1410]>>> phoneext.items()dict_items([('brad', 1137), ('david', 1410)])>>> list(phoneext.items())[('brad', 1137), ('david', 1410)]>>> phoneext.get("kent")>>> phoneext.get("kent", "NO ENTRY")'NO ENTRY'>>>二、输入与输出
程序经常需要与用户进行交互,以获得数据或者提供某种结果。目前的大多数程序使用对话框作为要求用户提供某种输入的方式。尽管Python 确实有方法来创建这样的对话框,但是可以利用更简单的函数。Python 提供了一个函数,它使得我们可以要求用户输入数据并且返回一个字符串的引用。这个函数就是input。
input 函数接受一个字符串作为参数。由于该字符串包含有用的文本来提示用户输入,因此它经常被称为提示字符串。举例来说,可以像下面这样调用input。
aName = input('Please enter your name: ')
不论用户在提示字符串后面输入什么内容,都会被存储在aName 变量中。使用input 函数,可以非常简便地写出程序,让用户输入数据,然后再对这些数据进行进一步处理。例如,在下面的两条语句中,第一条要求用户输入姓名,第二条则打印出对输入字符串进行一些简单处理后的结果。
aName = input("Please enter your name ")print("Your name in all capitals is ",aName.upper(),"and has length", len(aName))需要注意的是,input 函数返回的值是一个字符串,它包含用户在提示字符串后面输入的所有字符。如果需要将这个字符串转换成其他类型,必须明确地提供类型转换。在下面的语句中,用户输入的字符串被转换成了浮点数,以便于后续的算术处理。
sradius = input("Please enter the radius of the circle ")radius = float(sradius)diameter = 2 * radius格式化字符串
print 函数为输出Python 程序的值提供了一种非常简便的方法。它接受零个或者多个参数,并且将单个空格作为默认分隔符来显示结果。通过设置sep 这一实际参数可以改变分隔符。此外,每一次打印都默认以换行符结尾。这一行为可以通过设置实际参数end 来更改。下面是一些例子。
>>> print("Hello")Hello>>> print("Hello","World")Hello World>>> print("Hello","World", sep="***")Hello***World>>> print("Hello","World", end="***")Hello World***>>>更多地控制程序的输出格式经常十分有用。幸运的是,Python 提供了另一种叫作格式化字符串的方式。格式化字符串是一个模板,其中包含保持不变的单词或空格,以及之后插入的变量的占位符。例如,下面的语句包含is 和years old.,但是名字和年龄会根据运行时变量的值而发生改变。
print(aName, "is", age, "years old.")
使用格式化字符串,可以将上面的语句重写成下面的语句。
print("%s is %d years old." % (aName, age))这个简单的例子展示了一个新的字符串表达式。%是字符串运算符,被称作格式化运算符。表达式的左边部分是模板(也叫格式化字符串),右边部分则是一系列用于格式化字符串的值。
需要注意的是,右边的值的个数与格式化字符串中%的个数一致。这些值将依次从左到右地被换入格式化字符串。
让我们更进一步地观察这个格式化表达式的左右两部分。格式化字符串可以包含一个或者多个转换声明。转换字符告诉格式化运算符,什么类型的值会被插入到字符串中的相应位置。在上面的例子中,%s 声明了一个字符串,%d 则声明了一个整数。其他可能的类型声明还包括i、u、f、e、g、c 和%。表1-9 总结了所有的类型声明。

可以在%和格式化字符之间加入一个格式化修改符。格式化修改符可以根据给定的宽度对值进行左对齐或者右对齐,也可以通过小数点之后的一些数字来指定宽度。表1-10 解释了这些格式化修改符。

格式化运算符的右边是将被插入格式化字符串的一些值。这个集合可以是元组或者字典。如果这个集合是元组,那么值就根据位置次序被插入。也就是说,元组中的第一个元素对应于格式化字符串中的第一个格式化字符。如果这个集合是字典,那么值就根据它们对应的键被插入,并且所有的格式化字符必须使用(name)修改符来指定键名。
>>> price = 24>>> item = "banana">>> print("The %s costs %d cents" % (item,price))The banana costs 24 cents>>> print("The %+10s costs %5.2f cents" % (item,price))The banana costs 24.00 cents>>> print("The %+10s costs %10.2f cents" % (item,price))The banana costs 24.00 cents>>> itemdict = {"item":"banana","cost":24}>>> print("The %(item)s costs %(cost)7.1f cents" % itemdict)The banana costs 24.0 cents>>>除了格式化字符串可以使用格式化字符和修改符之外,Python 的字符串还包含了一个format 方法。该方法可以与新的Formatter 类结合起来使用,从而实现复杂字符串的格式化。可以在Python 参考手册中找到更多关于这些特性的内容。
三、控制结构
正如前文所述,算法需要两个重要的控制结构:迭代和分支。Python 通过多种方式支持这两种控制结构。程序员可以根据需要选择最有效的结构。
对于迭代,Python 提供了标准的while 语句以及非常强大的for 语句。while 语句会在给定条件为真时重复执行一段代码,如下所示。
>>> counter = 1>>> while counter <= 5:... print("Hello, world")... counter = counter + 1...Hello, worldHello, worldHello, worldHello, worldHello, world这段代码将“Hello, world”打印了5 遍。Python 会在每次重复执行前计算while 语句中的条件表达式。由于Python 本身要求强制缩进,因此可以非常容易地看清楚while 语句的结构。
while 语句是非常普遍的迭代结构,我们在很多不同的算法中都会用到它。在很多情况下,迭代过程由复合条件来控制。
while counter <= 10 and not done:
在这个例子中,迭代语句只有在上面两个条件都满足的情况下才会被执行。变量counter的值需要小于或等于10,并且变量done 的值需要为False(not False 就是True),因此Trueand True 的最后结果才是True。
while 语句在众多情况下都非常有用,另一个迭代结构for 语句则可以很好地和Python 的各种集合结合在一起使用。for 语句可以用于遍历一个序列集合的每个成员,如下所示。
>>> for item in [1,3,6,2,5]:... print(item)...13625
for 语句将列表[1,3,6,2,5]中的每一个值依次赋给变量item。然后,迭代语句就会被执行。这种做法对任意的序列集合(列表、元组以及字符串)都有效。
for 语句的一个常见用法是在一定的值范围内进行有限次数的迭代。下面的语句会执行print 函数5 次。range 函数会返回一个包含序列0、1、2、3、4 的范围对象,然后每个值都会被赋给变量item。接着,Python 会计算该值的平方并且打印结果。
>>> for item in range(5):... print(item**2)...014916>>>
for 语句的另一个非常有用的使用场景是处理字符串中的每一个字符。下面的代码段遍历一个字符串列表,并且将每一个字符串中的每一个字符都添加到结果列表中。最终的结果就是一个包含所有字符串的所有字符的列表。
>>> wordlist = ['cat','dog','rabbit']>>> letterlist = []>>> for aword in wordlist:... for aletter in aword:... letterlist.append(aletter)...>>> letterlist['c', 'a', 't', 'd', 'o', 'g', 'r', 'a', 'b', 'b', 'i', 't']>>>
分支语句允许程序员进行询问,然后根据结果,采取不同的行动。绝大多数的编程语言都提供两种有用的分支结构:ifelse 和if。以下是使用ifelse 语句的一个简单的二元分支示例。
if n < 0:print("Sorry, value is negative")else:print(math.sqrt(n))在这个例子中,Python 会检查n 所指向的对象是否小于0。如果是,就会打印一条消息,说明它是负值;如果不是,就会执行else 分支来计算它的平方根。
和其他所有控制结构一样,分支结构支持嵌套,一个问题的结果能帮助决定是否需要继续问下一个问题。例如,假设score 是指向计算机科学考试分数的变量。
if score >= 90:print('A')else:if score >= 80:print('B')elseif score >= 70:print('C')else:if score >= 60:print('D')else:print('F')这一代码段通过打印字母等级来对变量score 进行分类。如果分数大于或等于90,这一语句会打印A;如果小于90(else),会接着问下一个问题。如果分数大于或等于80,因为小于90,所以它一定介于80 和89 之间,那么语句就会打印B。可以发现,Python 的缩进模式帮助我们在不需要额外语法元素的情况下有效地关联对应的if 和else。
另一种表达嵌套分支的语法是使用elif 关键字。将else 和下一个if 结合起来,可以减少额外的嵌套层次。注意,最后的else 仍然是必需的,它用来在所有分支条件都不满足的情况下提供默认分支。
if score >= 90:print('A')elif score >= 80:print('B')elif score >= 70:print('C')elif score >= 60:print('D')else:print('F')Python 也有单路分支结构,即if 语句。如果条件为真,就会执行相应的代码。如果条件为假,程序会跳过if 语句,执行下面的语句。例如,下面的代码段会首先检查变量n 的值是否为负。如果值为负,那么就取它的绝对值,再计算它的平方根。
if n < 0:n = abs(n)print(math.sqrt(n))
列表可以通过使用迭代结构和分支结构来创建。这种方式被称为列表解析式。通过列表解析式,可以根据一些处理和分支标准轻松创建列表。举例来说,如果想创建一个包含前10 个完全平方数的列表,可以使用以下的for 语句。
>>> sqlist = []>>> for x in range(1,11):sqlist.append(x*x)>>> sqlist[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]>>>
使用列表解析式,只需一行代码即可创建完成。
>>> sqlist = [x*x for x in range(1,11)]>>> sqlist[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]>>>
变量x 会依次取由for 语句指定的1 到10 为值。之后,计算x*x 的值并将结果添加到正在构建的列表中。列表解析式也允许添加一个分支语句来控制添加到列表中的元素,如下所示。
>>> sqlist = [x*x for x in range(1,11) if x%2 != 0]>>> sqlist[1, 9, 25, 49, 81]>>>
这一列表解析式构建的列表只包含1 到10 中奇数的平方数。任意支持迭代的序列都可用于列表解析式。
>>>[ch.upper() for ch in 'comprehension' if ch not in 'aeiou']['C', 'M', 'P', 'R', 'H', 'N', 'S', 'N']>>>
四、异常处理
在编写程序时通常会遇到两种错误。第一种是语法错误,也就是说,程序员在编写语句或者表达式时出错。例如,在写for 语句时忘记加冒号。
>>> for i in range(10)SyntaxError: invalid syntax (<pyshell#61>, line 1)
在这个例子中,Python 解释器发现,由于语句不符合Python 语法规范,因此它无法执行这条指令。初学者经常会犯语法错误。
第二种是逻辑错误,即程序能执行完成但返回了错误的结果。这可能是由于算法本身有错,或者程序员没有正确地实现算法。有时,逻辑错误会导致诸如除以0、越界访问列表等非常严重的情况。这些逻辑错误会导致运行时错误,进而导致程序终止运行。通常,这些运行时错误被称为异常。
许多初级程序员简单地把异常等同于引起程序终止的严重运行时错误。然而,大多数编程语言都提供了让程序员能够处理这些错误的方法。此外,程序员也可以在检测到程序执行有问题的情况下自己创建异常。
当异常发生时,我们称程序“抛出”异常。可以用try 语句来“处理”被抛出的异常。例如,以下代码段要求用户输入一个整数,然后从数学库中调用平方根函数。如果用户输入了一个大于或等于0 的值,那么其平方根就会被打印出来。但是,如果用户输入了一个负数,平方根函数就会报告ValueError 异常。
>>> anumber = int(input("Please enter an integer "))Please enter an integer -23>>> print(math.sqrt(anumber))Traceback (most recent call last):File "<pyshell#102>", line 1, in <module>print(math.sqrt(anumber))ValueError: math domain error>>>可以在try 语句块中调用print 函数来处理这个异常。对应的except 语句块“捕捉”到这个异常,并且为用户打印一条提示消息。
>>> try:print(math.sqrt(anumber))except:print("Bad Value for square root")print("Using absolute value instead")print(math.sqrt(abs(anumber)))Bad Value for square rootUsing absolute value instead4.79583152331>>>except 会捕捉到sqrt 抛出的异常并打印提示消息,然后会使用对应数字的绝对值来保证sqrt 的参数非负。这意味着程序并不会终止,而是继续执行后续语句。
程序员也可以使用raise 语句来触发运行时异常。例如,可以先检查值是否为负,并在值为负时抛出异常,而不是给sqrt 函数提供负数。下面的代码段显示了创建新的RuntimeError异常的结果。注意,程序仍然会终止,但是导致其终止的异常是由我们自己手动创建的。
>>> if anumber < 0:... raise RuntimeError("You can't use a negative number")... else:... print(math.sqrt(anumber))...Traceback (most recent call last):File "<stdin>", line 2, in <module>RuntimeError: You can't use a negative number>>>除了RuntimeError 以外,还可以抛出很多不同类型的异常。请查看Python 参考手册,了解完整的异常类型以及如何自己创建异常。
五、定义函数
之前的过程抽象例子调用了Python 数学模块中的sqrt 函数来计算平方根。通常来说,可以通过定义函数来隐藏任何计算的细节。函数的定义需要一个函数名、一系列参数以及一个函数体。
函数也可以显式地返回一个值。例如,下面定义的简单函数会返回传入值的平方。
>>> def square(n):... return n**2...>>> square(3)9>>> square(square(3))81>>>
这个函数定义包含函数名square 以及一个括号包含的形式参数列表。在这个函数中,n 是唯一的形式参数,这意味着square 只需要一份数据就能完成任务。计算n**2 并返回结果的细节被隐藏起来。如果要调用square 函数,可以为其提供一个实际参数值(在本例中是3),并要求Python 环境计算。注意,square 函数的返回值可以作为参数传递给另一个函数调用。
通过运用著名的牛顿迭代法,可以自己实现平方根函数。用于近似求解平方根的牛顿迭代法使用迭代计算的方法来求解正确的结果。
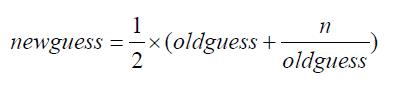
以上公式接受一个值n,并且通过在每一次迭代中将newguess 赋值给oldguess 来反复猜测平方根。初次猜测的平方根是n/2。代码清单1-1 展示了该函数的定义,它接受值n 并且返回20 轮迭代之后的n 的平方根。牛顿迭代法的细节都被隐藏在函数定义之中,用户不需要知道任何实现细节就可以调用该函数来求解平方根。代码清单1-1 同时也展示了#的用法。任何跟在#之后一行内的字符都是注释。Python 解释器不会执行这些注释。

>>> squareroot(9)3.0>>> squareroot(4563)67.549981495186216>>>
六、Python 面向对象编程:定义类
前文说过,Python 是一门面向对象的编程语言。到目前为止,我们已经使用了一些內建的类来展示数据和控制结构的例子。面向对象编程语言最强大的一项特性是允许程序员(问题求解者)创建全新的类来对求解问题所需的数据进行建模。
我们之前使用了抽象数据类型来对数据对象的状态及行为进行逻辑描述。通过构建能实现抽象数据类型的类,可以利用抽象过程,同时为真正在程序中运用抽象提供必要的细节。每当需要实现抽象数据类型时,就可以创建新类。
1. Fraction 类
要展示如何实现用户定义的类,一个常用的例子是构建实现抽象数据类型Fraction 的类。我们已经看到,Python 提供了很多数值类。但是在有些时候,需要创建“看上去很像”分数的数据对象。
像3/5这样的分数由两部分组成。上面的值称作分子,可以是任意整数。下面的值称作分母,可以是任意大于0 的整数(负的分数带有负的分子)。尽管可以用浮点数来近似表示分数,但我们在此希望能精确表示分数的值。
Fraction 对象的表现应与其他数值类型一样。我们可以针对分数进行加、减、乘、除等运算,也能够使用标准的斜线形式来显示分数,比如3/5。此外,所有的分数方法都应该返回结果的最简形式。这样一来,不论进行何种运算,最后的结果都是最简分数。
在Python 中定义新类的做法是,提供一个类名以及一整套与函数定义语法类似的方法定义。以下是一个方法定义框架。
class Fraction:# 方法定义
所有类都应该首先提供构造方法。构造方法定义了数据对象的创建方式。要创建一个Fraction 对象,需要提供分子和分母两部分数据。在Python 中,构造方法总是命名为__init__(即在init 的前后分别有两个下划线),如代码清单1-2 所示。

注意,形式参数列表包含3 项。self 是一个总是指向对象本身的特殊参数,它必须是第一个形式参数。然而,在调用方法时,从来不需要提供相应的实际参数。如前所述,分数需要分子与分母两部分状态数据。构造方法中的self.num 定义了Fraction 对象有一个叫作num 的内部数据对象作为其状态的一部分。同理,self.den 定义了分母。这两个实际参数的值在初始时赋给了状态,使得新创建的Fraction 对象能够知道其初始值。
要创建Fraction 类的实例,必须调用构造方法。使用类名并且传入状态的实际值就能完成调用(注意,不要直接调用__init__)。
myfraction = Fraction(3,5)
以上代码创建了一个对象,名为myfraction,值为3/5。图5 展示了这个对象。
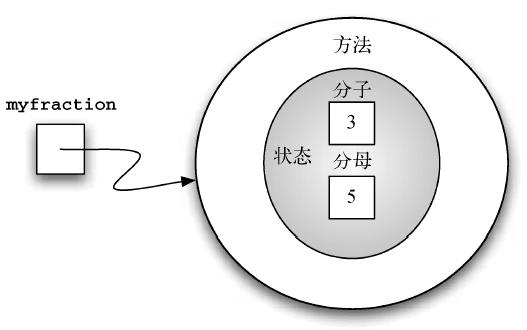
图5 Fraction 类的一个实例
接下来实现这一抽象数据类型所需要的行为。考虑一下,如果试图打印Fraction 对象,会发生什么呢?
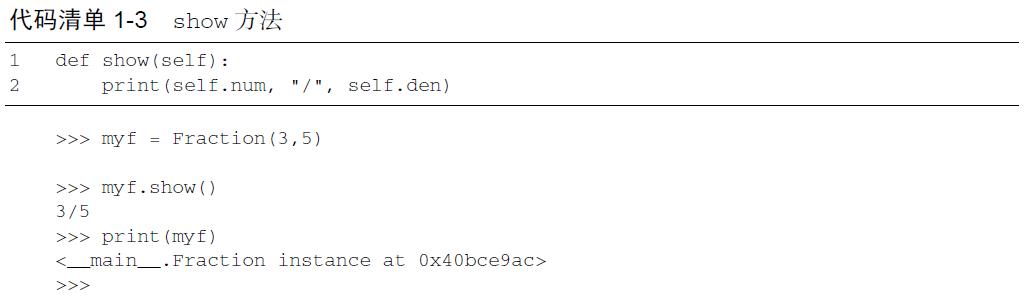
>>> myf = Fraction(3,5)>>> print(myf)<__main__.Fraction instance at 0x409b1acc>
Fraction 对象myf 并不知道如何响应打印请求。print 函数要求对象将自己转换成一个可以被写到输出端的字符串。myf 唯一能做的就是显示存储在变量中的实际引用(地址本身)。这不是我们想要的结果。
有两种办法可以解决这个问题。一种是定义一个show 方法,使得Fraction 对象能够将自己作为字符串来打印。代码清单1-3 展示了该方法的实现细节。如果像之前那样创建一个Fraction 对象,可以要求它显示自己(或者说,用合适的格式将自己打印出来)。不幸的是,这种方法并不通用。为了能正确打印,我们需要告诉Fraction 类如何将自己转换成字符串。要完成任务,这是print 函数所必需的。
Python 的所有类都提供了一套标准方法,但是可能没有正常工作。其中之一就是将对象转换成字符串的方法__str__。这个方法的默认实现是像我们之前所见的那样返回实例的地址字符串。我们需要做的是为这个方法提供一个“更好”的实现,即重写默认实现,或者说重新定义该方法的行为。
为了达到这一目标,仅需定义一个名为__str__的方法,并且提供新的实现,如代码清单1-4 所示。除了特殊参数self 之外,该方法定义不需要其他信息。新的方法通过将两部分内部状态数据转换成字符串并在它们之间插入字符/来将分数对象转换成字符串。一旦要求Fraction 对象转换成字符串,就会返回结果。注意该方法的各种用法。

>>> myf = Fraction(3,5)>>> print(myf)3/5>>> print("I ate", myf, "of the pizza")I ate 3/5 of the pizza>>> myf.__str__()'3/5'>>> str(myf)'3/5'>>>可以重写Fraction 类中的很多其他方法,其中最重要的一些是基本的数学运算。我们想创建两个Fraction 对象,然后将它们相加。目前,如果试图将两个分数相加,会得到下面的结果。
>>> f1 = Fraction(1,4)>>> f2 = Fraction(1,2)>>> f1+f2Traceback (most recent call last):File "<pyshell#173>", line 1, in -toplevelf1+f2TypeError: unsupported operand type(s) for +:'instance' and 'instance'>>>
如果仔细研究这个错误,会发现加号+无法处理Fraction 的操作数。
可以通过重写Fraction 类的__add__方法来修正这个错误。该方法需要两个参数。第一个仍然是self,第二个代表了表达式中的另一个操作数。
f1.__add__(f2)
以上代码会要求Fraction 对象f1 将Fraction 对象f2 加到自己的值上。可以将其写成标准表达式:f1 + f2。
两个分数需要有相同的分母才能相加。确保分母相同最简单的方法是使用两个分母的乘积作为分母。
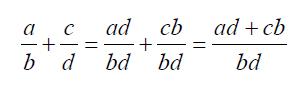
代码清单1-5 展示了具体实现。__add__方法返回一个包含分子和分母的新Fraction 对象。可以利用这一方法来编写标准的分数数学表达式,将加法结果赋给变量,并且打印结果。值得注意的是,第3 行中的\称作续行符。当一条Python 语句被分成多行时,需要用到续行符。

>>> f1 = Fraction(1, 4)>>> f2 = Fraction(1, 2)>>> f3 = f1 + f2>>> print(f3)6/8>>>
虽然这一方法能够与我们预想的一样执行加法运算,但是还有一处可以改进。1/4+1/2 的确等于6/8,但它并不是最简分数。最好的表达应该是3/4。为了保证结果总是最简分数,需要一个知道如何化简分数的辅助方法。该方法需要寻找分子和分母的最大公因数(greatest common divisor,GCD),然后将分子和分母分别除以最大公因数,最后的结果就是最简分数。
要寻找最大公因数,最著名的方法就是欧几里得算法,第8 章将详细讨论。欧几里得算法指出,对于整数m 和n,如果m 能被n 整除,那么它们的最大公因数就是n。然而,如果m 不能被n 整除,那么结果是n 与m 除以n 的余数的最大公因数。代码清单1-6 提供了一个迭代实现。注意,这种实现只有在分母为正的时候才有效。对于Fraction 类,这是可以接受的,因为之前已经定义过,负的分数带有负的分子,其分母为正。

现在可以利用这个函数来化简分数。为了将一个分数转化成最简形式,需要将分子和分母都除以它们的最大公因数。对于分数6/8,最大公因数是2。因此,将分子和分母都除以2,便得到3/4。代码清单1-7 展示了实现细节。

>>> f1 = Fraction(1,4)>>> f2 = Fraction(1,2)>>> f3 = f1 + f2>>> print(f3)3/4>>>
Fraction 对象现在有两个非常有用的方法,如图6 所示。为了允许两个分数互相比较,还需要添加一些方法。假设有两个Fraction 对象,f1 和f2。只有在它们是同一个对象的引用时,f1 == f2 才为True。这被称为浅相等,如图7 所示。在当前实现中,分子和分母相同的两个不同的对象是不相等的。
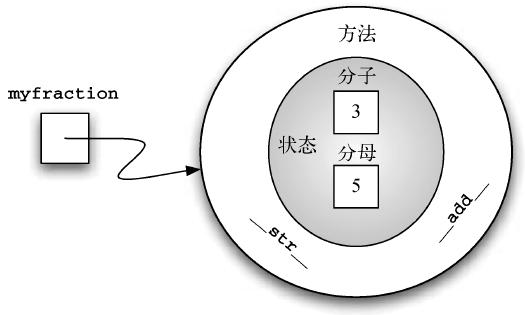
图6 包含两个方法的Fraction 实例
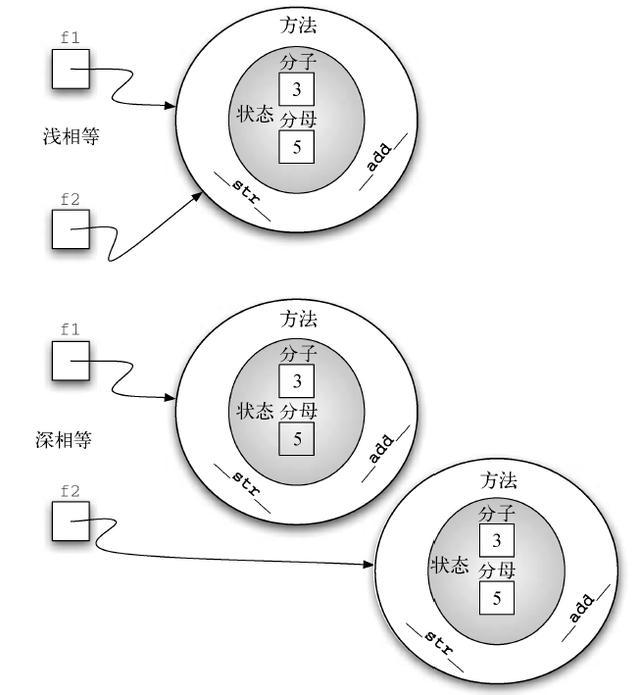
图7 浅相等与深相等
通过重写__eq__方法,可以建立深相等——根据值来判断相等,而不是根据引用。__eq__是又一个在任意类中都有的标准方法。它比较两个对象,并且在它们的值相等时返回True,否则返回False。
在Fraction 类中,可以通过统一两个分数的分母并比较分子来实现__eq__方法,如代码清单1-8 所示。需要注意的是,其他的关系运算符也可以被重写。例如,__le__方法提供判断小于等于的功能。

代码清单1-9 提供了到目前为止Fraction 类的完整实现。剩余的算术方法及关系方法留作练习。

2. 继承:逻辑门与电路
最后一节介绍面向对象编程的另一个重要方面。继承使一个类与另一个类相关联,就像人们相互联系一样。孩子从父母那里继承了特征。与之类似,Python 中的子类可以从父类继承特征数据和行为。父类也称为超类。
图8 展示了內建的Python 集合类以及它们的相互关系。我们将这样的关系结构称为继承层次结构。举例来说,列表是有序集合的子。因此,我们将列表称为子,有序集合称为父(或者分别称为子类列表和超类序列)。这种关系通常被称为IS-A 关系(IS-A意即列表是一个有序集合)。这意味着,列表从有序集合继承了重要的特征,也就是内部数据的顺序以及诸如拼接、重复和索引等方法。
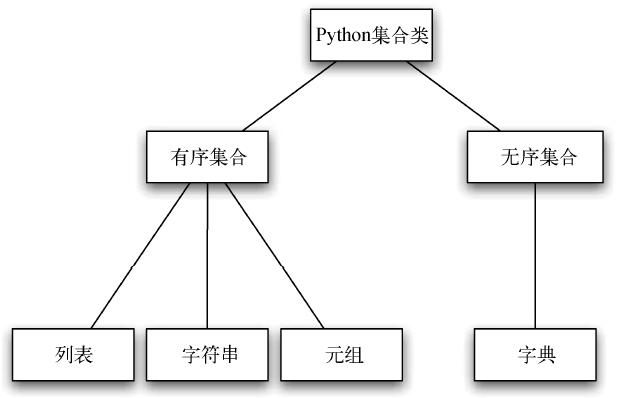
图8 Python 集合类的继承层次结构
列表、字符串和元组都是有序集合。它们都继承了共同的数据组织和操作。不过,根据数据是否同类以及集合是否可修改,它们彼此又有区别。子类从父类继承共同的特征,但是通过额外的特征彼此区分。
通过将类组织成继承层次结构,面向对象编程语言使以前编写的代码得以扩展到新的应用场景中。此外,这种结构有助于更好地理解各种关系,从而更高效地构建抽象表示。
为了进一步探索这个概念,我们来构建一个模拟程序,用于模拟数字电路。逻辑门是这个模拟程序的基本构造单元,它们代表其输入和输出之间的布尔代数关系。一般来说,逻辑门都有单一的输出。输出值取决于提供的输入值。
与门(AND gate)有两个输入,每一个都是0 或1(分别代表False 和True)。如果两个输入都是1,那么输出就是1;如果至少有一个输入是0,那么输出就是0。或门(OR gate)同样也有两个输入。当至少有一个输入为1 时,输出就为1;当两个输入都是0 时,输出是0。
非门(NOT gate)与其他两种逻辑门不同,它只有一个输入。输出刚好与输入相反。如果输入是0,输出就是1。反之,如果输入是1,输出就是0。图9 展示了每一种逻辑门的表示方法。
每一种都有一张真值表,用于展示输入与输出的对应关系。
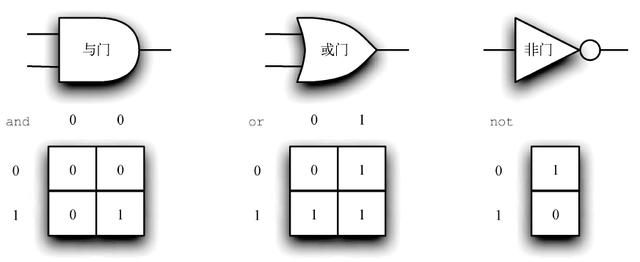
图9 3 种逻辑门
通过不同的模式将这些逻辑门组合起来并提供一系列输入值,可以构建具有逻辑功能的电路。图10 展示了一个包含两个与门、一个或门和一个非门的电路。两个与门的输出直接作为输入传给或门,然后其输出又输入给非门。如果在4 个输入处(每个与门有两个输入)提供一系列值,那么非门就会输出结果。图1-10 也展示了这一过程。
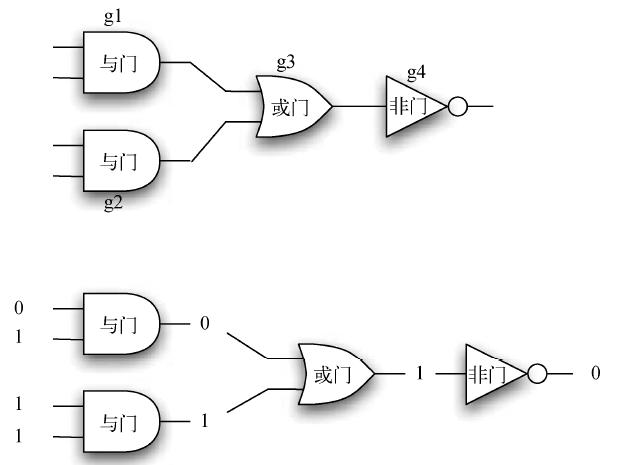
图10 电路示例
为了实现电路,首先需要构建逻辑门的表示。可以轻松地将逻辑门组织成类的继承层次结构,如图11 所示。顶部的LogicGate 类代表逻辑门的通用特性:逻辑门的标签和一个输出。下面一层子类将逻辑门分成两种:有一个输入的逻辑门和有两个输入的逻辑门。再往下,就是具体的逻辑门。
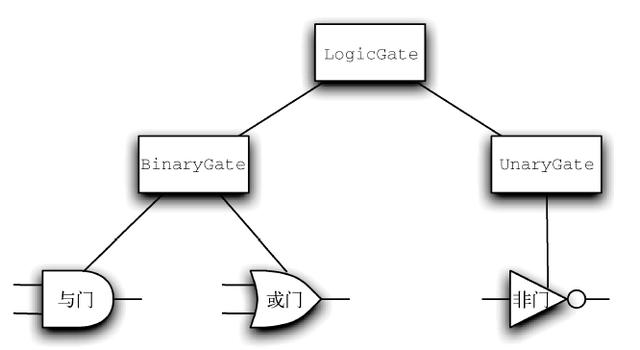
图11 逻辑门的继承层次结构
现在开始通过实现最通用的类LogicGate 来实现这些类。如前所述,每一个逻辑门都有一个用于识别的标签以及一个输出。此外,还需要一些方法,以便用户获取逻辑门的标签。
所有逻辑门还需要能够知道自己的输出值。这就要求逻辑门能够根据当前的输入值进行合理的逻辑运算。为了生成结果,逻辑门需要知道自己对应的逻辑运算是什么。这意味着需要调用一个方法来进行逻辑运算。代码清单1-10 展示了LogicGate 类的完整实现。

目前还不用实现performGateLogic 函数。原因在于,我们不知道每一种逻辑门将如何进行自己的逻辑运算。这些细节会交由继承层次结构中的每一个逻辑门来实现。这是一种在面向对象编程中非常强大的思想——我们创建了一个方法,而其代码还不存在。参数self 是指向实际调用方法的逻辑门对象的引用。任何添加到继承层次结构中的新逻辑门都仅需要实现之后会被调用的performGateLogic 函数。一旦实现完成,逻辑门就可以提供运算结果。扩展已有的继承层次结构并提供使用新类所需的特定函数,这种能力对于重用代码来说非常重要。
我们依据输入的个数来为逻辑门分类。与门和或门有两个输入,非门只有一个输入。BinaryGate 是LogicGate 的一个子类,并且有两个输入。UnaryGate 同样是LogicGate 的子类,但是仅有一个输入。在计算机电路设计中,这些输入被称作“引脚”(pin),我们在实现中也使用这一术语。
代码清单1-11 和代码清单1-12 实现了这两个类。两个类中的构造方法首先使用super 函数来调用其父类的构造方法。当创建BinaryGate 类的实例时,首先要初始化所有从LogicGate中继承来的数据项,在这里就是逻辑门的标签。接着,构造方法添加两个输入(pinA 和pinB)。
这是在构建类继承层次结构时常用的模式。子类的构造方法需要先调用父类的构造方法,然后再初始化自己独有的数据。


BinaryGate 类增添的唯一行为就是取得两个输入值。由于这些值来自于外部,因此通过一条输入语句来要求用户提供。UnaryGate 类也有类似的实现,不过它只有一个输入。
有了不同输入个数的逻辑门所对应的通用类之后,就可以为有独特行为的逻辑门构建类。例如,由于与门需要两个输入,因此AndGate 是BinaryGate 的子类。和之前一样,构造方法的第一行调用父类(BinaryGate)的构造方法,该构造方法又会调用它的父类(LogicGate)的构造方法。注意,由于继承了两个输入、一个输出和逻辑门标签,因此AndGate 类并没有添加任何新的数据。
AndGate 类唯一需要添加的是布尔运算行为。这就是提供performGateLogic 的地方。对于与门来说,performGateLogic 首先需要获取两个输入值,然后只有在它们都为1 时返回1。
代码清单1-13 展示了AndGate 类的完整实现。

可以创建一个实例来验证AndGate 类的行为。下面的代码展示了AndGate 对象g1,它有一个内部标签“G1”。当调用getOutput 方法时,该对象必须首先调用它的performGateLogic方法,这个方法会获取两个输入值。一旦取得输入值,就会显示正确的结果。
>>> g1 = AndGate("G1")>>> g1.getOutput()Enter Pin A input for gate G1-->1Enter Pin B input for gate G1-->00或门和非门都能以相同的方式来构建。OrGate 也是BinaryGate 的子类,NotGate 则会继承UnaryGate 类。由于计算逻辑不同,这两个类都需要提供自己的performGateLogic 函数。
要使用逻辑门,可以先构建这些类的实例,然后查询结果(这需要用户提供输入)。
>>> g2 = OrGate("G2")>>> g2.getOutput()Enter Pin A input for gate G2-->1Enter Pin B input for gate G2-->11>>> g2.getOutput()Enter Pin A input for gate G2-->0Enter Pin B input for gate G2-->00>>> g3 = NotGate("G3")>>> g3.getOutput()Enter Pin input for gate G3-->01有了基本的逻辑门之后,便可以开始构建电路。为此,需要将逻辑门连接在一起,前一个的输出是后一个的输入。为了做到这一点,我们要实现一个叫作Connector 的新类。
Connector 类并不在逻辑门的继承层次结构中。但是,它会使用该结构,从而使每一个连接器的两端都有一个逻辑门(如图12 所示)。这被称为HAS-A 关系(HAS-A 意即“有一个”),它在面向对象编程中非常重要。前文用IS-A 关系来描述子类与父类的关系,例如UnaryGate 是一个LogicGate。
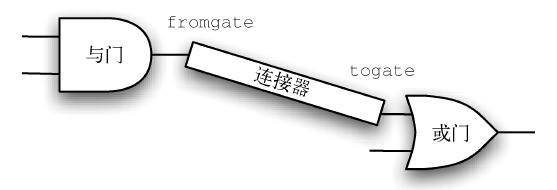
图12 连接器将一个逻辑门的输出与另一个逻辑门的输入连接起来
Connector 与LogicGate 是HAS-A 关系。这意味着连接器内部包含LogicGate 类的实例,但是不在继承层次结构中。在设计类时,区分IS-A 关系(需要继承)和HAS-A 关系(不需要继承)非常重要。
代码清单1-14 展示了Connector 类。每一个连接器对象都包含fromgate 和togate 两个逻辑门实例,数据值会从一个逻辑门的输出“流向”下一个逻辑门的输入。对setNextPin 的调用(实现如代码清单1-15 所示)对于建立连接来说非常重要。需要将这个方法添加到逻辑门类中,以使每一个togate 能够选择适当的输入。



在BinaryGate 类中,逻辑门有两个输入,但连接器必须只连接其中一个。如果两个都能连接,那么默认选择pinA。如果pinA 已经有了连接,就选择pinB。如果两个输入都已有连接,则无法连接逻辑门。
现在的输入来源有两个:外部以及上一个逻辑门的输出。这需要对方法getPinA 和getPinB进行修改(请参考代码清单1-16)。如果输入没有与任何逻辑门相连接(None),那就和之前一样要求用户输入。如果有了连接,就访问该连接并且获取fromgate 的输出值。这会触发fromgate 处理其逻辑。该过程会一直持续,直到获取所有输入并且最终的输出值成为正在查询的逻辑门的输入。在某种意义上,这个电路反向工作,以获得所需的输入,再计算最后的结果。

下面的代码段构造了图1-10 中的电路。
>>> g1 = AndGate("G1")>>> g2 = AndGate("G2")>>> g3 = OrGate("G3")>>> g4 = NotGate("G4")>>> c1 = Connector(g1, g3)>>> c2 = Connector(g2, g3)>>> c3 = Connector(g3, g4)两个与门(g1 和g2)的输出与或门(g3)的输入相连接,或门的输出又与非门(g4)的输入相连接。非门的输出就是整个电路的输出。
>>> g4.getOutput()Pin A input for gate G1-->0Pin B input for gate G1-->1Pin A input for gate G2-->1Pin B input for gate G2-->10>>>
——本书内容节选自《Python数据结构与算法分析(第2版)》

了解数据结构与算法是透彻理解计算机科学的前提。随着Python日益广泛的应用,Python程序员需要实现与传统的面向对象编程语言相似的数据结构与算法。
本书是用Python描述数据结构与算法的开山之作,汇聚了作者多年的实战经验,向读者透彻讲解在Python环境下,如何通过一系列存储机制高效地实现各类算法。通过本书,读者将深刻理解Python数据结构、递归、搜索、排序、树与图的应用,等等。
——
若把编写代码比作行军打仗,那么要想称霸沙场,不能仅靠手中的利刃,还需深谙兵法。Python是一把利刃,数据结构与算法则是兵法。只有熟读兵法,才能使利刃所向披靡。
本书作者在计算机科学领域深耕数十载,积累了丰富的实战经验。通过学习本书,你将掌握数据结构与算法的基本思想,从而有信心探索任何编程难题的解决方法。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号