第33讲:PostgreSQL技术大讲堂 - 并行查询管理
发表时间: 2023-11-09 17:03

PostgreSQL从小白到专家,是从入门逐渐能力提升的一个系列教程,内容包括对PG基础的认知、包括安装使用、包括角色权限、包括维护管理、、等内容,希望对热爱PG、学习PG的同学们有帮助,欢迎持续关注CUUG PG技术大讲堂。
第33讲:并行查询管理
第33讲:11月11日(周六)19:30-20:30,往期文档及视频,联系CUUG
内容 : 并行查询工作原理与机制、各种并行查询处理方式
并行查询概述
· 并行查询为什么会快?
现代的CPU型号有大量的内核,提供了并行执行更大的可扩性,并行查询不是因为并行读取,而是因为数据分散在许多CPU内核上进行处理。现代操作系统为PostgreSQL数据文件提供了良好的缓存。预读允许从存储中获取一个块,而不仅仅是PG守护进程请求的块。因此,查询性能不受磁盘IO的限制。
它消耗CPU周期:从表数据页逐个读取行,比较行值和WHERE条件。
并行查询工作原理与机制
· How does it work?
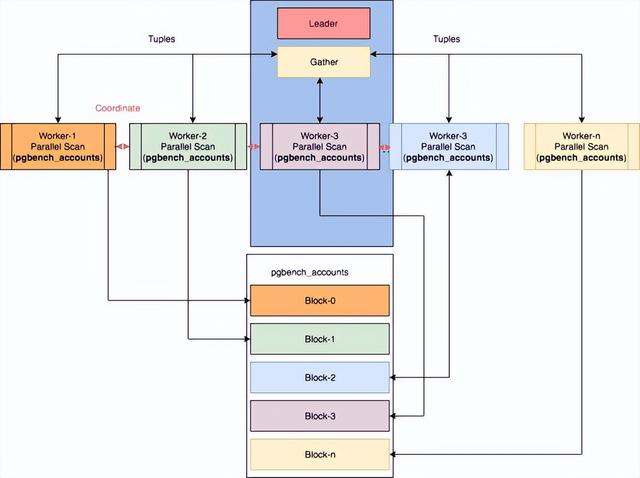
Processes:查询执行总是在“leader”进程中开始。一个leader执行所有非并行活动及其对并行处理的贡献。执行相同查询的其他进程称为“worker”进程。并行执行使用动态后台工作器基础结构(在9.4中添加)。由于PostgreSQL的其他部分使用进程,而不是线程,因此创建三个工作进程的查询可能比传统的执行速度快4倍。
Communication:Workers使用消息队列(基于共享内存)与leader通信。每个进程有两个队列:一个用于错误,另一个用于元组。
leader、gather、worker
· gather节点作为子查询树的根节点
并行查询工作原理与机制
· 使用要点
如果所有CPU内核都已饱和,则不要启用并行执行。并行执行会从其他查询中窃取CPU时间,从而增加其它查询的响应时间。
最重要的是,并行处理显著增加了具有高WORK-MEM值的内存使用量,因为每个hash连接或排序操作占用一个WORK-MEM内存量。
低延迟的OLTP查询在并行执行时不能再快了。特别是,当启用并行执行时,返回单行的查询可能会执行得不好。
Pierian spring对于开发人员来说是一个TPC-H基准。检查是否有类似的查询以获得最佳并行执行。
并行执行只支持不带锁谓词的SELECT查询。
正确的索引可能是并行顺序表扫描的更好选择。
不支持游标或挂起的查询。
窗口函数和有序集聚合函数是非并行的。
对IO绑定的工作负载没有好处。
没有并行排序算法。但是,使用排序的查询在某些方面仍然可以并行。
将CTE(替换为…)替换为支持并行执行的子选择。
外部数据包装器(FDW)当前不支持并行执行(但它们可以!)
不支持完全外部联接。
设置最大行数的客户端禁用并行执行。
如果查询使用未标记为并行安全的函数,则它将是单线程的。
可序列化事务隔离级别禁用并行执行。
· How many workers to use?
影响wokers数量的参数权重依次顺序:
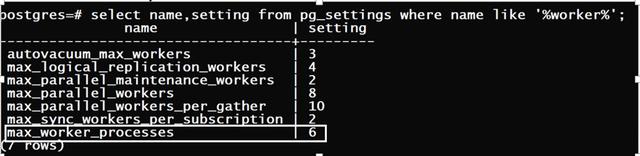
max_parallel_workers_per_gather :每次sql操作workers数量的最大值。
max_parallel_workers:其次,查询执行器从max_parallel_workers池中可以获取workers的最大数。
max_worker_processes:这个是workers的顶级限制后台进程的总数(此参数谨慎修改,根据系统实际的cpu个数(核数)来设置)。
max_parallel_workers_per_gather:理解为每个用户去银行取钱金额。
max_parallel_workers:理解为用户存在银行中的总存款金额。
max_worker_processes:理解为某个银行支点可用现金总数。
· How many workers to use?
· 参数针对的是一个session还是整个实例?
第一个会话:
第二个会话:
· 增加worders进程的条件
查询规划器可以考虑根据表或索引大小增加或减少工作线程的数量:
min_parallel_table_scan_size
min_parallel_index_scan_size
示例:
set min_parallel_table_scan_size='8MB'
8MB table => 1 worker
24MB table => 2 workers
72MB table => 3 workers
x => log(x / min_parallel_table_scan_size) / log(3) + 1 worker
每一次表比min_parallel_(index| table)扫描大小大3倍,postgres就添加一个worker。workers的数量不是基于成本的!
· 示例
假如一张表的大小是1600MB
1、设置
min_parallel_table_scan_size='500MB';
则:Workers Planned: 2
2、设置
min_parallel_table_scan_size=‘'200MB';
则:Workers Planned: 3
3、设置
min_parallel_table_scan_size=‘‘100MB';
则:Workers Planned: 4
· 改变
max_parallel_workers_per_gather进程分配规则
改变workers分配规则:
实际上,系统设置的参数在生产中并不总是合适的,可以使用下面命令覆盖特定表的workers数量。
ALTER table…SET(parallel_workers=N)
· 动态修改workers参数的值
我们可以在不重新启动服务器的情况下增加工作线程数
alter system set max_parallel_workers_per_gather=4;
select * from pg_reload_conf();
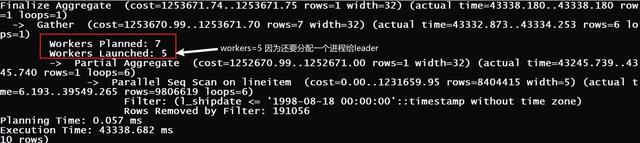
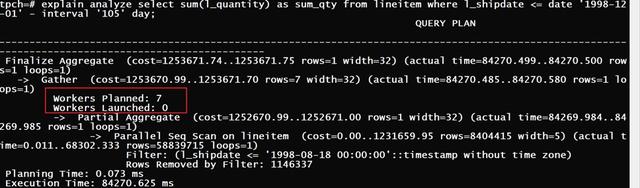
tpch=# explain analyze select sum(l_quantity) as sum_qty from lineitem where l_shipdate <= date '1998-12-01' - interval '105' day;
Finalize Aggregate (cost=1349772.08..1349772.09 rows=1 width=32) (actual time=160146.769..160146.769 rows=1 loops=1)
-> Gather (cost=1349771.65..1349772.06 rows=4 width=32) (actual time=160145.984..160147.581 rows=5 loops=1)
Workers Planned: 4
Workers Launched: 4
· Why parallel execution is not used?
除了一长串的并行执行限制之外,PostgreSQL还会检查成本:
“parallel_setup_cost”以避免短查询的并行执行。它模拟了内存设置、进程启动和初始通信所花费的时间。可以理解为执行时间小于指定的秒的查询不走并行。
“parallel_tuple_cost”:leader 和 workers 之间的沟通可能需要很长时间。时间与workers发送的元组数成正比。该参数模拟了通信成本。
· Why parallel execution is not used?
示例:
1张表200M数据,总共3百万行。
查询语句:explain analyze select sum(sal) from emp4;
1、parallel_setup_cost=10000时
当查询成本累计时间超过该值时使用并行查询
2、parallel_setup_cost=20000
当查询成本累计时间低于该值时使用串行查询
Serial sequential scan
· 串行顺序扫描
tpch=# explain analyze select l_quantity as sum_qty from lineitem where l_shipdate <= date '1998-12-01' - interval '105' day;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
Seq Scan on lineitem (cost=0.00..1874376.30 rows=58833712 width=5) (actual time=0.523..33309.303 rows=58839715 loops=1)
Filter: (l_shipdate <= '1998-08-18 00:00:00'::timestamp without time zone)
Rows Removed by Filter: 1146337
Planning Time: 6.637 ms
Execution Time: 41297.038 ms
(5 rows)
# 顺序扫描产生太多没有聚合的行。因此,查询由一个CPU核执行。
Parallel sequential scan
· 并行查询
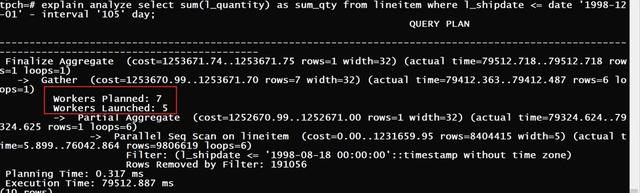
tpch=# explain analyze select sum(l_quantity) as sum_qty from lineitem where l_shipdate <= date '1998-12-01' - interval '105' day;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------------
Finalize Aggregate (cost=1349772.08..1349772.09 rows=1 width=32) (actual time=31962.761..31962.762 rows=1 loops=1)
-> Gather (cost=1349771.65..1349772.06 rows=4 width=32) (actual time=31961.980..31962.146 rows=5 loops=1)
Workers Planned: 4
Workers Launched: 4
-> Partial Aggregate (cost=1348771.65..1348771.66 rows=1 width=32) (actual time=31951.809..31951.809 rows=1 loops=5)
-> Parallel Seq Scan on lineitem (cost=0.00..1312000.57 rows=14708428 width=5) (actual time=1.491..29217.070 rows=11767943 loop
s=5)
Filter: (l_shipdate <= '1998-08-18 00:00:00'::timestamp without time zone)
Rows Removed by Filter: 229267
Planning Time: 0.666 ms
Execution Time: 31964.069 ms
*在添加SUM()之后,可以清楚地看到4个worker将帮助我们加快查询速度
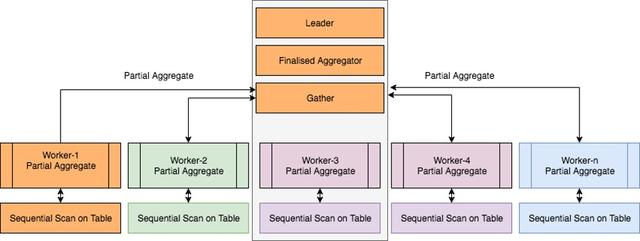
· Parallel Aggregation
“Parallel Seq Scan”节点生成用于部分聚合的行。“部分聚合”节点使用SUM()减少这些行。最后,由“Gather”节点从每个worker收集SUM计数器。
最终结果由“Finalize Aggregate”节点计算。
Finalize Aggregate (cost=1349772.08..1349772.09 rows=1 width=32) (actual time=31962.761..31962.762 rows=1 loops=1)
-> Gather (cost=1349771.65..1349772.06 rows=4 width=32) (actual time=31961.980..31962.146 rows=5 loops=1)
Workers Planned: 4
Workers Launched: 4
-> Partial Aggregate (cost=1348771.65..1348771.66 rows=1 width=32) (actual time=31951.809..31951.809 rows=1 loops=5)
-> Parallel Seq Scan on lineitem (cost=0.00..1312000.57 rows=14708428 width=5) (actual time=1.491..29217.070 rows=11767943 loop
s=5)
Nested loop joins
· Parallel Index Only Scan
tpch=# explain (costs off) select c_custkey, count(o_orderkey)
from customer left outer join orders on
c_custkey = o_custkey and o_comment not like '%special%deposits%'
group by c_custkey;
QUERY PLAN
--------------------------------------------------------------------------------------
Finalize GroupAggregate
Group Key: customer.c_custkey
-> Gather Merge
Workers Planned: 4
-> Partial GroupAggregate
Group Key: customer.c_custkey
-> Nested Loop Left Join
-> Parallel Index Only Scan using customer_pkey on customer
-> Index Scan using idx_orders_custkey on orders
Index Cond: (o_custkey = customer.c_custkey)
Filter: ((o_comment)::text !~~ '%special%deposits%'::text)
(11 rows)
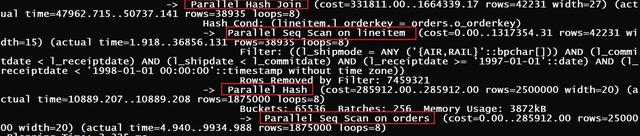
Hash Join
· Hash Join
PostgreSQL 11及以前版本,每个workers进程都构建自己的哈希表。结果,4+workers进程无法提高绩效。
直到PostgreSQL 12,新实现使用共享哈希表。每个工人都可以利用WORK-MEM来构建哈希表。
TPC-H的查询12很好地说明了并行散列连接。每个工作进程帮助构建一个共享哈希表。
-- Query 12 from TPC-H
· Tpch 12.sql执行计划
每个worker帮助构建一个共享的hash表
Merge Join
· Merge Join
由于merge-join的性质,不可能使其并行执行。不要担心,在查询执行的最后一个阶段,我们仍然可以看到带有合并联接的查询的并行执行。
-- Query 2 from TPC-H
-> Merge Join
Merge Cond: (part.p_partkey = partsupp.ps_partkey)
Join Filter: (partsupp.ps_supplycost = (SubPlan 1))
-> Gather Merge
Workers Planned: 4
-> Parallel Index Scan using part_pkey on part
Partition-wise join
· Partition-wise join
如果连接表的分区键之间存在相等连接条件,那么两个类似分区表之间的连接可以分解为它们的匹配分区之间的连接。分区键之间的等连接意味着一个分区表的给定分区中给定行的所有连接伙伴必须在另一个分区表的相应分区中。因此,分区表之间的连接可以分解为匹配分区之间的连接,这时候就会使用并行查询,然后比对,提高速度。这种将分区表之间的连接分解为分区之间的连接的技术称为partition-wise join。

PostgreSQL 12默认禁用分区连接功能。分区连接的规划成本很高。类似分区表的连接可以按匹配的分区进行。这允许postgres使用更小的哈希表。每个分区连接操作都可以并行执行。
tpch=# set enable_partitionwise_join=t;
tpch=# explain (costs off) select * from prt1 t1, prt2 t2
where t1.a = t2.b and t1.b = 0 and t2.b between 0 and 10000;
由于并行查询成本估计,可能该查询不会用到并行,可以改变成本估算设置:
tpch=# set parallel_setup_cost = 1; --默认值为1000
tpch=# set parallel_tuple_cost = 0.01; --默认值为0.1
tpch=# explain (costs off) select * from prt1 t1, prt2 t2
where t1.a = t2.b and t1.b = 0 and t2.b between 0 and 10000;
QUERY PLAN
-----------------------------------------------------------
Gather
Workers Planned: 2
-> Parallel Append
-> Parallel Hash Join
Hash Cond: (t2_1.b = t1_1.a)
-> Parallel Seq Scan on prt2_p2 t2_1 --prt2_p2 与prt1_p2 两个分区连接
Filter: ((b >= 0) AND (b <= 10000))
-> Parallel Hash
-> Parallel Seq Scan on prt1_p2 t1_1
Filter: (b = 0)
-> Parallel Hash Join
Hash Cond: (t2.b = t1.a)
-> Parallel Seq Scan on prt2_p1 t2 --prt2_p1 与prt1_p1 两个分区连接
Filter: ((b >= 0) AND (b <= 10000))
-> Parallel Hash
-> Parallel Seq Scan on prt1_p1 t1
Filter: (b = 0)
(17 rows)
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号