数据结构与算法:软考核心知识点解析
发表时间: 2022-10-30 00:02

数据结构:元素之间的关系,分为逻辑结构和存储结构。
每个元素前、后最多都只能有一个节点,如:线性表、栈、队列、数组、串
如:二维数组、多维数组、树、图等
含有n个元素的线性表采用顺序存储,等概率删除其中任一个元素,平均需要移动n − 1 2 \frac{n-1}数据结构和算法2n−1个元素。

链表中的每个元素称为结点,每个结束是一个结构体变量,分为:
数组:表示n个数据类型相同的元素所组成的序列。
字符串:字符构成的一维数组。



每一层都不能增加结点
除了最后一层,都不能增加结点。 最后一层左侧连续有,右侧连续无。
除了最后一层,都不能增加结点。但不满足最后一层左侧连续有、右侧连续无的条件 。
如果i=1,则结点i无父结点,二叉树的根;如果i>1,则父结点是 i/2取整。
如果2i>n,则结点i为叶子结点,无左子结点;否则,其左子结点是结点2i。
如果2i+1>n,则结点i无右子结点,否则,其右子结点是结点2i+1。
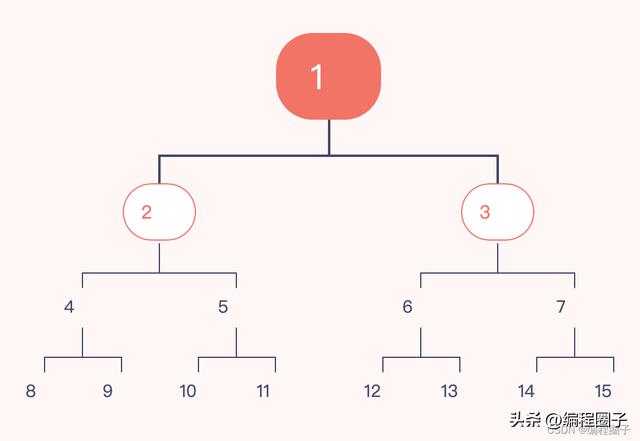
值最小的结点无左子树
值最大的结点无右子树。
二叉查找树的中序遍历序列为从小到大排列的序列
每一层从左到右进行遍历的序列为从小到大排列的序列。
一个顶点到另一个顶点是有方向的;
任意两个顶点之间都有一个路径相连。
n个顶点的无向图和有向图的完全图边的个数计算:
用一个n阶的方阵R来存放图中各结点的关联信息。

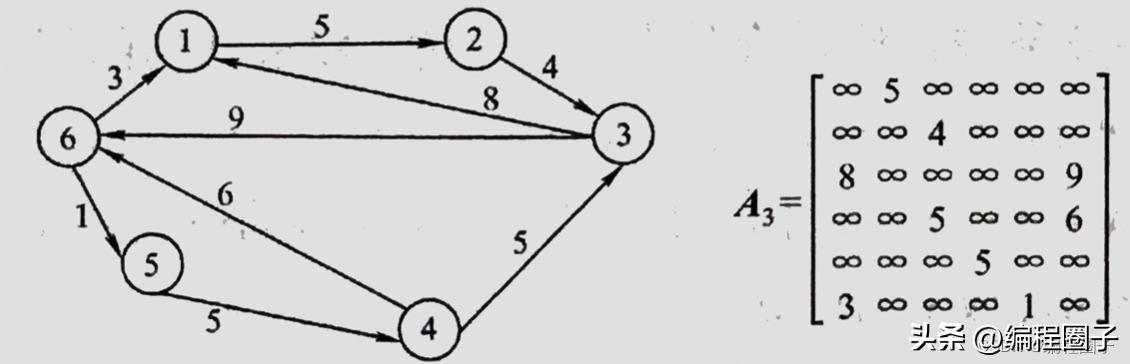
无穷大表示无连接。
指向该结点的边的数量
从该结点指出去的边的数量。

常见的算法时间复杂度:
O ( 1 ) < ( l o g 2 n ) < O ( n ) < O ( n l o g 2 n ) < O ( n 2 ) < O ( n 3 ) < O ( 2 n ) O(1) < (log_2n) <O(n) <O(nlog_2n) <O(n^2)<O(n^3)<O(2^n) O(1)<(log2n)<O(n)<O(nlog2n)<O(n2)<O(n3)<O(2n)
临时空间占用大小。
从头到尾依次查找。
平均查找长度: n + 1 2 \frac{n+1}数据结构和算法2n+1
int biSearch(int r[], int low, int high, int key){ int mid; while(low<=high ){ mid = (low+high)/2; if(key == r[mid]) return mid; else if(key<r[mid]) high = mid-1; else low = mid+1; } return -1;}int main(){ int data[] = {1,2,3,4,5}; int low=0; int high=sizeof(data) /sizeof(int); int key=3; int find = biSearch(data, low, high, key); printf("result: %d", find);}int biSearchRecursion(const int r[], int low, int high, int key){ int mid; if(low<=high){ mid = (low + high) /2; if(key ==r[mid]) return mid; else if(key<r[mid]) return biSearchRecursion(r, low, mid-1, key); else return biSearchRecursion(r, mid+1, high, key); } return -1;}int main(){ const int data[] = {1,2,3,4,5}; int low=0; int high=sizeof(data) /sizeof(int); int key=3; int find = biSearchRecursion(data, low, high, key); printf("result: %d", find); return 0;}仍使用散列函数,用链地址法。按关键码构造链,链的数量与关键码一致。
插入的元素与现有元素挨个比较,每次从元素前面一个元素比较,比前一元素小的话就继续往前比较。
直接插入排序在元素基本有序时比较有优势。

代码示例:
void insertSort(int data[], int n){ int i,j; int tmp; for(i=1;i<n;i++){ if(data[i]<data[i-1]){ tmp = data[i]; data[i] = data[i-1]; // 元素往后移 for(j=i-2;j>=0 && data[j]>tmp;j--){ data[j+1]=data[j]; } data[j+1]=tmp; } }}int main(){ int data[] = {3,4,5,3,5,1,22}; insertSort(data, 7); for(int i=0;i<7;i++){ printf("%d=%d\n", i, data[i]); } return 0;}不稳定排序
相邻元素比较和交换,一趟排序后最大移到最右、或最小移到最左。
示例代码:
#include <stdio.h>int less(int x,int y){ return ((x<y)?1:0);}int large(int x, int y){ return ((x>y)?1:0);}void bubbleSort(int arr[], int n, int(*compare)(int,int)){ int i,j; int swapped =1; for(i=0;swapped;i++){ swapped=0; for(j=0;j<n-1;j++){ if(compare(arr[j+1],arr[j])){ swap(arr[j+1], arr[j]); swapped = 1; } } }}void bubbleSortTest(){ int data1[] = {4,2,6,3,1}; bubbleSort(data1, 5, less); for(int i : data1){ printf("%d ", i); }}int main() { bubbleSortTest(); return 0;}代码:
int qusort(int s[],int start,int end) //自定义函数 qusort(){ int i,j; //定义变量为基本整型 i=start; //将每组首个元素赋给i j = end; //将每组末尾元素赋给j s[0]=s[start]; //设置基准值 while(i<j) { while(i<j&&s[0]<s[j]) j--; //位置左移 if(i<j) { s[i]=s[j]; //将s[j]放到s[i]的位置上 i++; //位置右移 } while(i<j&&s[i]<=s[0]) i++; //位置左移 if(i<j) { s[j]=s[i]; //将大于基准值的s[j]放到s[i]位置 j--; //位置左移 } } s[i]=s[0]; //将基准值放入指定位置 if (start<i) qusort(s,start,j-1); //对分割出的部分递归调用qusort()函数 if (i<end) qusort(s,j+1,end); return 0;}void selectSort(int data[], int n){ // k 指向最小值的下标 int i,j,k; int temp; for(i=0;i<n-1;i++){ for(k=i,j=i+1;j<n;j++){ if(data[j]<data[k])k=j; if(k!=i){ temp = data[i]; data[i]=data[k]; data[k]=temp; } } }}
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号