小米大数据运维管理体系的构建与应用实践
发表时间: 2023-03-15 20:16
前段时间,很荣幸能参加云栖大会,并和大家分享了《小米大数据运维管理体系的建设和实践》,给议题分为两个部分,第一部分是聊聊大数据运维数字化转型相关的内容,看看运维层面如何做到化繁为简,打造极致效率的;第二部分,会给大家介绍一下小米大数据的技术架构,大家可以从中了解到小米怎样应对海量数据挑战的。
服务定位
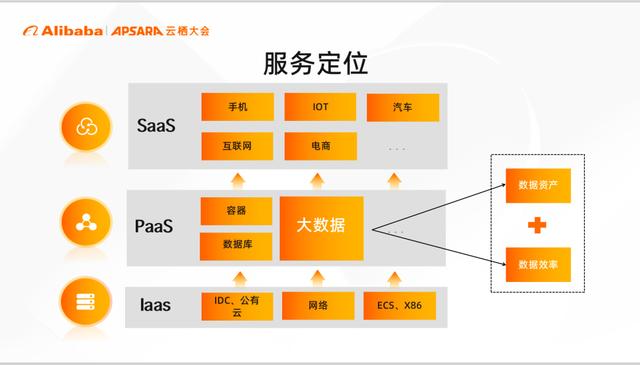
为了帮助大家理解,我们先来简单聊一聊小米服务的架构。整个业务架构按照云计算的分层模型来说分为三层,依次是 Iass 层、Pass 层、Sass 层。小米的 Iass 层是一个混合云的现状,涉及 IDC、公有云、网络等资源,小米的 Saas 层不仅包含战略业务手机 * IOT * 汽车,还包括互联网、电商等数百个业务线。大数据作为 Pass 层的一员,向下对接基础资源,向上承接业务的数据需求,提供离线报表、实时数仓等多种场景化能力,进一步帮助业务沉淀数据资产,提升整体数据效率。同时,大数据是的集团数字化底座,起到中流砥柱的作用。
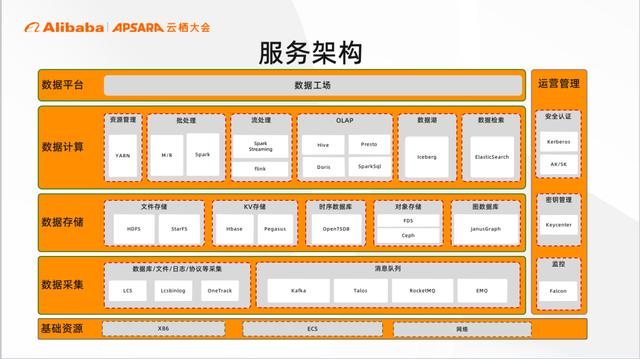
大数据服务架构
整个小米的大数据服务是立足于 x86 和 ecs 之上的自下而上分为4层,依次是数据采集层、数据存储层、数据计算层、数据平台层。
数据采集层:主要使用自研的 LCS 和以 Talos 为代表的消息队列组合去实现的,这一块也会在后面的分享中展开讲述
数据存储层:各类开源和自研存储引擎,包含我们的文件存储HDFS、KV 存储 HBase、对象存储 Ceph 等等;其中 Pegasus 是小米自研的,目前在 apache 已经开源。
数据计算层:小米使用 Yarn 作为统一的资源管理,基于 Yarn 之上提供了批处理、流处理多种计算引擎,比如我们常见的MapReduce、Spark、Flink 等;除此之外提供丰富的 Olap 引擎, 满足即席查询和检索需求。
数据平台层:我们内部称之为数据工场,主要提供一站式的数据开发和数据管理能力
小米大数据业务发展非常迅速,已经覆盖国内海外多个区域。现已达到千+集群,数万节点的规模,在存储总量上已经近 EB,计算任务30w/天。
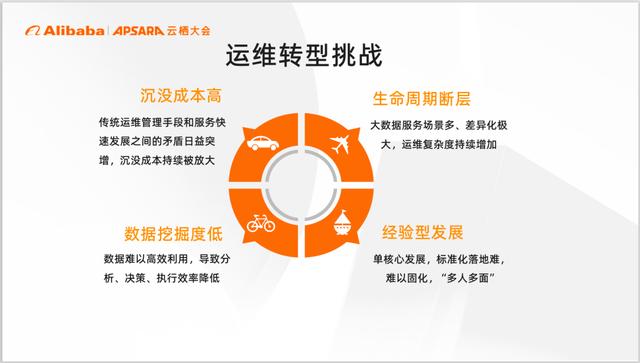
大数据运维转型挑战
如此数据规模,给服务运维带来了很多挑战,接下来,我们重点聊一聊。
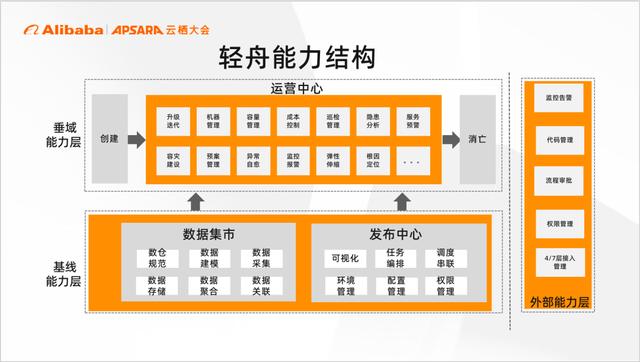
识别到问题后我们内部经过充分讨论,结合小米长期处于混合云的状态,发起了大数据运维中台-轻舟的整体规划。轻舟的主线是通过建设通用的基线能力、打造极致的垂域能力,来彻底贯通服务的生命周期。
轻舟的整体能力结构是两能力+三中心。
垂域能力层是贯穿服务的生命周期的,从服务的创建、运营到消亡,运营是我们日常工作花费时间精力最多的部分,包含服务升级迭代、机器管理、巡检管理等等

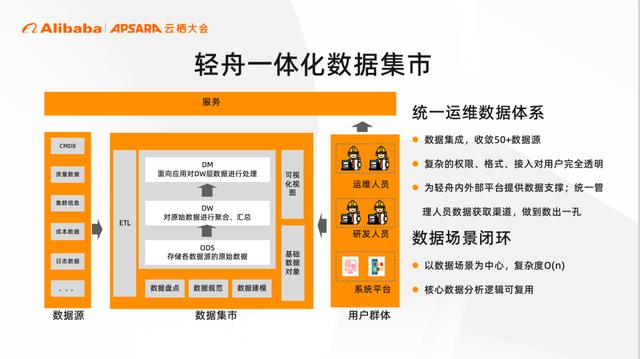
在数据上为了解决孤岛问题,我们的解决方案是数据集成、架构解耦。通过构建大数据的一体化运维数据集市,收敛运维周边的所有数据,在数据源头和数据使用方之间做了一层解耦。在数据集市层我们制定了数据规范,将运维数据进行建模和分层处理。最后针对现有的数据源进行ETL调度,最终实现数据统一存储和使用。
新的数据架构统一了运维数据体系,解决数据孤岛问题的同时,降低数据使用门槛,目前整套数据体系已经应用到所有的大数据服务当中,真正做到了数出一孔。再有整个数据场景是闭环的,复杂度由 O(n^2) 变成O(n),并且核心数据分析逻辑可复用。整个新的数据架构是以数据场景为中心,取代之前以人为中心。
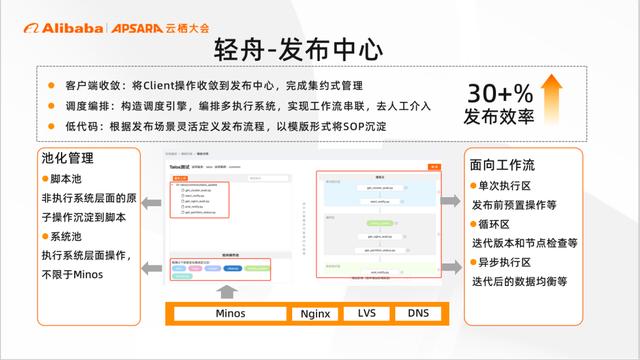
轻舟-发布中心
轻舟的发布中心,通过调度编排+低代码的模式,去灵活定义工作流。同时依托模版将 SOP 进行沉淀,将个人经验转化为组织能力。下图就是发布中心的工作流模版,我们将执行系统和自定义脚本抽象为操作池。在调度编排上定义了多种逻辑区域,如我们的单次执行区,循环区和异步执行区。
目前整套正在逐步推广到所有大数据服务中,并且在一些场景中实现了变更的无人值守,效率提升30%。后续整个发布中心也会在现有基础上继续优化和迭代,打造全局互联互通,最终实现全流程自动化
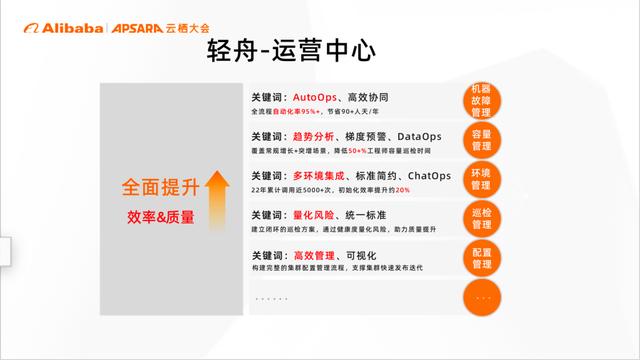
在运营中心中,我们结合数据和混合 ops 的理念,重点解决协同、服务差异和经验化等多个核心痛点。目前整体的效果还是不错的,比如在机器故障处理上已经实现了全流程自动,覆盖了95%的大数据服务,年均自动化处理机器故障近万次。在容量管理上,通过数据趋势的分析,覆盖全场景的容量的检测,降低大量的人工介入;在巡检管理上,通过将风险量化打分,进一步固化了巡检标准和处理流程。
此外还有环境管理、配置管理,目前整个运营中心还在持续建设和完善中。
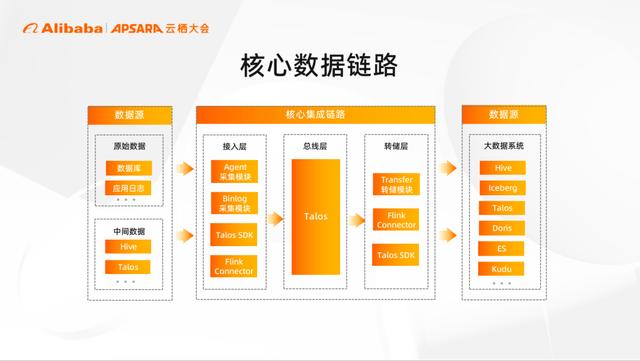
核心数据链路
接下来是第二部分,大数据的架构实践。
小米的核心数据链路,是以消息队列 Talos+ 接入转储这样的组合,作为数据总线去实现数据从端到端的打通。各类原始数据,通过 Agent 的采集方式,进入到消息队列中,同时也支持基于 binlog 的存量和增量采集。在转储层一般通过的统一 transfer 模块,将数据灌入其他大数据的存储引擎中,供进一步使用。
目前小米半数以上的数据都是通过这套方案接入的,整套流程做了产品化的设计,用户可以基于平台可自由定义数据链路。
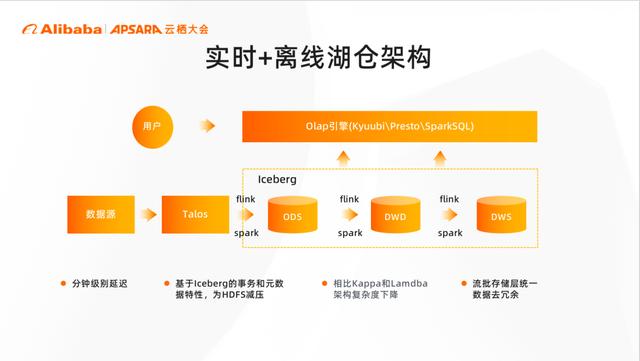
实时+离线湖仓架构
小米在数仓这个方向上也经历了基于 Hadoop 的离线数仓、Kappa 实时数仓、Lambda 架构数仓的过程。最新的数仓体系是基于数据湖iceberg+flink+spark 构建的离线+实时数仓。结合上面提到的,数据经过 MQ,最终进入到数据湖当中数仓的每一层之间通过 spark 或 flink 方式进行 etl 建设。
同时小米的 olap 引擎经过改造可直接查询湖中数据。整个方案在性能上效果表现很好,相比历史架构,其复杂度更低。由于了数仓存储层的统一和 ztsd 压缩算法的升级,在存储上也有很大的优化。
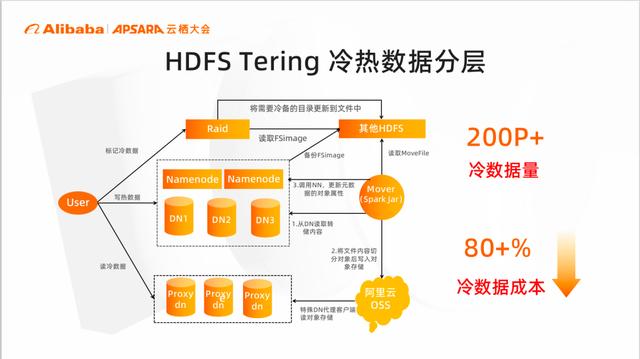
HDFS Tiering 冷热数据分层
上面提到的数据湖 iceberg 的底座也是基于 HDFS 的,这里我们聊聊HDFS 的数据架构实践。
一般业界实现中,为了实现数据分层的目的,会使用固态盘、机械盘和高密度存储的方式。在小米内部实现中,为了进一步压缩成本,自研了一套HDFS Tering 的架构,将冷数据直接上云管理。
下图就是整体的架构图,可以看到后台会有一个 mover 程序自动的将HDFS 冷数据的转储到阿里云 OSS 上。随后更新 Namenode 上的元数据,实现文件属性到block到对象的变化。同时对用户透明,在架构上增加了 proxydn 模块。
目前整套方案,已经累计冷备了200+PB 数据,数据成本降低80+%。
Lindorm引入
Lindorm引入(一)
为了支撑小米 IOT 的战略,解决业务海量数据索引+事务的需求。小米历史是基于封装 HBase Coprocessor 实现的自研存储,我们内部称之为SDS。
但随着数据规模不断上涨,暴露了很多架构问题,比如基于范围分片,failover 时间慢,依赖链路多等等。同时无法支撑业务的时序数据需求;此外 SDS 在开发维护成本上也非常高昂。
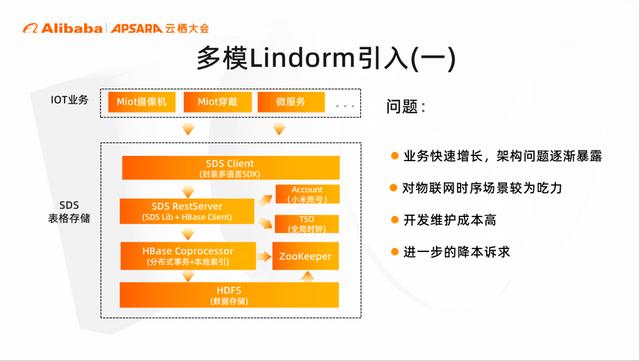
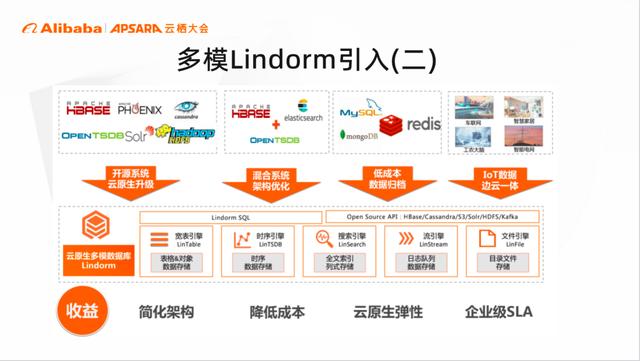
经过我们选型后,阿里云的 Lindorm 是非常符合我们需求的,在图中我们可以看到,Lindorm 兼容 HBase、Hadoop 等协议,提供了宽表引擎的同时,还提供了时序等多种引擎。
与此同时结合多级混合存储、Serverless 等多种特性,可以解决很多遗留问题。小米内部测试后性能还是蛮不错的,符合我们的整体需求。
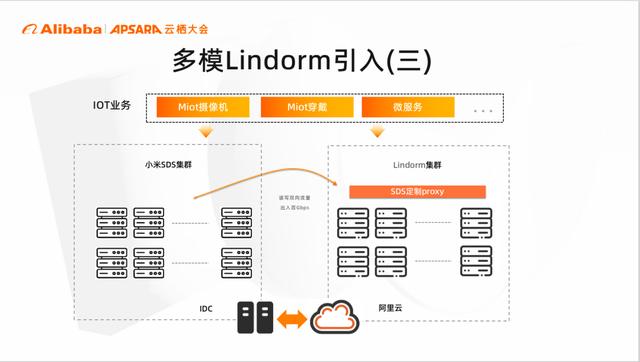
图中就是整体的迁移架构,我们为 IDC 到云间打通百G的网络链路
服务层面,SDS 和 Lindorm 之间会提前建立好数据同步链路,保证 SDS 和 Lindorm 都是最新数据
为了最小化业务改动成本,提供了sds proxy 的组件,将数据代理到 lindorm 上,最终实现业务迁移。
大数据事件云图

作者简介:
刘志杰,小米大数据运维负责人/SRE 专家,曾就职于百度、电信行业公司,有丰富的大数据、运维工程和数据库实践经验。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12











 鲁公网安备37020202000738号
鲁公网安备37020202000738号