彭数学深度解析:AIGC热潮下,中国芯片与算力的未来展望及投资机遇
发表时间: 2023-08-04 11:34

图片来源@视觉中国
文|钛资本研究院
OpenAI发布ChatGPT模型引起了AIGC应用的爆红,AI领域的应用和创业再次迎来了资本的追捧,AIGC的创业项目纷纷获得巨额融资。AIGC可应用于各行各业,比如聊天、写作、视频、音频、制图、设计等,甚至可以生成游戏策略和代码。AIGC时代序幕已拉起,各大厂商纷纷布局。但是,AIGC的应用,离不开底层芯片与算力的支撑,在这一背景下,我们如何理解、发掘算力芯片产业,显得尤为重要。
中国的算力芯片领域有哪些机遇呢?近期,钛资本邀请到旭源资本创始人彭数学进行分享,主题是:AIGC爆红之下,我国芯片与算力的发展趋势与投资机会。他是资深工业互联网投资家,曾任职盈峰资本、啟赋资本,已主导投资50+项目,其中5家IPO上市,3家项目回报百倍,最快回报项目一年半DPI为10倍,曾获得2016中国活跃风险投资人、金鸥奖2021年度最佳投资人等多项荣誉。彭先生于2021年创立旭源资本(广东旭源私募股权投资基金管理有限公司,基金管理人编号P1072011),旭源资本系我国新锐精品投资机构,获得了金鸥奖2021年度新锐投资机构等荣誉。主要投资方向为:新能源、芯片半导体与高端装备制造领域,已经投资了麒麟软件(国产操作系统)、创芯人科技(FA零部件数字供应链)、象帝先(GPU芯片)、盛合晶微(2.5D/3D封装)、博康化学(光刻胶)等优质项目。本次分享主持人是钛资本叶灿斌,以下为分享实录:
AIGC的概念早在50年代就被提出。直到90年代到2011年,我们才将科研成果转变为实用性产品。当然,过去我们也面临算法瓶颈,但在2010年以及2014年开始出现了几个关键点。2014年生成式对抗网络的出现,以及2022年OpenAI发布ChatGPT模型,这一系列事件引爆了人工智能的发展,它的历程也因此而逐步完善。

从WEB1.0的PGC,到WEB2.0的UGC,再到WEB3.0的AIGC,这一连串的发展得益于深度学习模型的技术创新。在2014年,我们看到大量的AI辅助项目都没有取得成功,但现在AIGC已经可以完全替代人工,几乎百分之百地实现自主生产,这样的爆发才得以形成。
现在主流的大模型是3.5版本,在国内,百度和阿里的工作做得相当不错,而智谱则致力于打造通用模型,构建双语千亿的超大模型。这些初创公司的发展,在某种程度上已经与BAT独立开来。
值得注意的是,在万物皆可AI生产的时代,一些插画师、设计师在线平台很可能会被AI取代。阿里巴巴曾推出一个数据库,直接用AI替代人工进行图片生成,AIGC实际上只是更完善地实现了这种内容生成。AIGC还能进行策略生成,替代人工编写游戏代码,甚至直接为程序员编写代码。
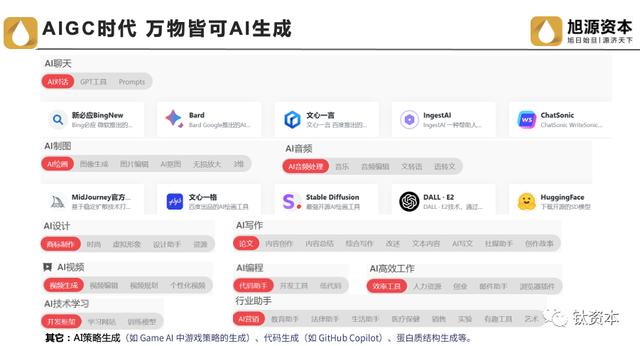
现在,AIGC规模非常庞大,到2023年已经达到了170亿,预计到2030年将达到1万亿。我们目前正处于培育蓬勃和整体加速的阶段。行业拥有巨大的成长性和爆发性,值得高度关注。
举几个案例。来画是我们曾经投资的一个项目,由创始人魏博主导。最初,来画专注于手绘短视频制作,以替代Flash技术和昂贵的拍摄制作。由于Flash技术在后期网页兼容性方面存在问题,而拍摄制作成本较高,所以这一创意应运而生。项目采用Windows的Surface电脑作为主要工具。经过几年的发展,现在转变成了AIGC,底层技术形成了动画和数字人智能生产平台。其中的数字人包括会议系统等,这些系统都非常完善,且国外用户已达到100多万。
另外,万兴科技是全球领先的新生代数字创意赋能者,2003年成立,推出的第一款数字创意产品(Photo to VCD)便风靡海外,目前用户覆盖全球200多个国家和地区。万兴科技的工具与AIGC的数字创意应用工具吻合,涵盖了创意应用、绘图、文档使用工具以及智能转换视频等方面。
还有叮咚课堂,其软件使用了AIGC的功能,用人工智能来替代老师,一对一的授课价格居然只要几十元,非常低。在ChatGPT还没有出现之前,我们已经通过推理推测到AIGC这个应用,可以实现千人千面的一对一个性化服务。
ChatGPT未来的产业化主要涵盖归纳、代码生成、图像处理、智能客服等领域。最初是基于Transformer模型的GPT,于2018年6月首次出现。接着,发展出GPT-2,这是一个多任务的通用模型。到了2020年,GPT-3是一个超大规模的语言模型,标志着一个里程碑。在2022年3月,人类反馈强化学习的引入进一步提升了AIGC的能力,因为通过人类反馈,它可以不断地进行训练和迭代,不断螺旋式地上升。到了2022年11月,强化学习进一步优化了AIGC的性能,持续出现了更多思维逻辑的推理。

未来,针对聊天机器人和智能客服的发展会更加完善。GPT-4将是一个多模态模型,国内公司如百度、阿里,甚至京东等也会参与其中的发展。然而,国内面临的困境在于硬件和训练成本较高,且数据资料库并不完美。因此,我们需要探讨如何提高训练数据库的质量,降低训练成本。特别是在自然语言理解方面会面临一定的困难。
AI的发展,一方面依赖于模型和算法,另一方面则依赖于芯片的算力。在电脑上,CPU擅长数值计算,能够推理出复杂的逻辑,缺点是计算速度较慢,不能并行处理任务。如果把CPU比作一个人的大脑 ,那么GPU和FPGA就相当于四肢,可以帮助它执行任务。
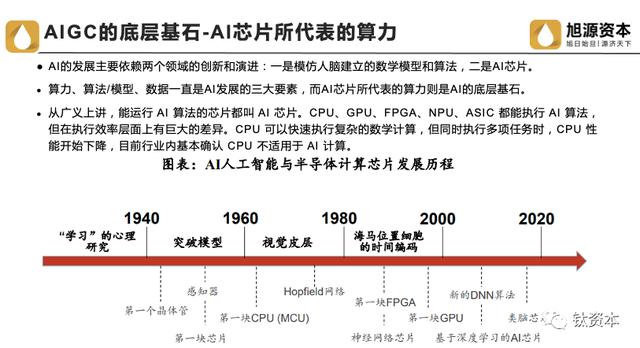
在训练单位方面,以ChatGPT为代表的人工智能大模型训练和推理需要强大的计算支持。ChatGPT单次训练所需算力约27.5PFlop/s-day,单颗NVIDIA V100芯片深度学习算力为125TFlops,则ChatGPT模型的训练至少需要1颗V100芯片计算220天(27.5*1000/125=220)才能完成。
在训练成本方面。GPT-3的数据训练需要45TB。训练该模型所需的算力是3640PF,总成本高达1200万美元。2021年,全球计算设备算力总规模达到615EFlop/s,而到2023年,全球大模型训练所需全部算力相当于超过200万张A100显卡。预计到2030年,全球算力规模将达到56ZFlps,年均增长率约为65%。我国计算设备算力总规模达到202EFlops,占全球约33%。
1、CPU:底层核心算力芯片
AI芯片分为几类。首先是CPU,其逻辑单元占60%,计算单元占40%。CPU在复杂的逻辑运算能力方面较强,主要用于逻辑控制,但计算单元较少,不擅长处理并行计算任务。
针对这一弱点,可以通过增加核数来提高能力。包括AMD,因为它们都是复杂指令的架构。从单核发展到多核,AMD推出了96核,Intel推出了56核。所以,对于CPU指令集来说,复杂指令主要是Intel和AMD,而简化指令则有许多其他公司推出,比如ARM架构、阿尔法等。
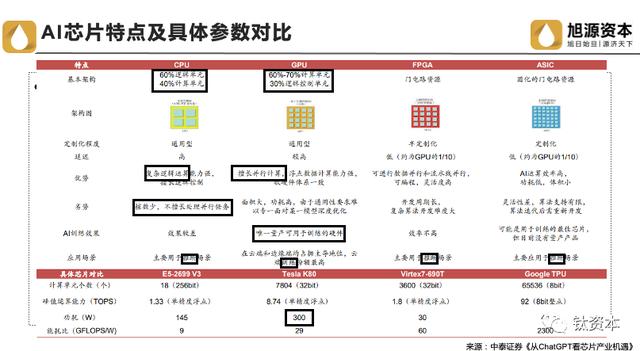
在国产芯片领域,国内有六大CPU厂商。第一个是拥有最核心的内部IP内核授权,即X86架构。包括上海兆芯和海光,后者已经上市。然而,海光的自主程度相对较低,安全基础不够牢靠,但其特点是发展速度最快,因为其现有架构和生态系统最成熟。这也是海光能够达到2000亿市值的原因。第二个是指令架构授权,比如ARM架构的华为鲲鹏和天津飞腾,处于自主研发和生态构建之间。第三个是最极端的,既有指令架构授权,又进行自主研制指令集,比如龙芯中科和申威科技。这两者的自主程度高,但生态构建极其困难。从长远来看,自主研发是最好的选择,但从短期来看,则可能选择全部授权。
2、CPU+XPU:异构形式成为大算力场景配置主流
未来AIGC将以CPU+XPU的异构形式成为主流。与CPU相比,XPU具有更强大的计算能力。目前最流行的异构计算系统是CPU+GPU,其中CPU负责对计算机的硬件资源进行控制和调配,并负责操作系统的运行,而GPU、FPGA等芯片则作为CPU的加速器存在。
3、GPU:AI高性能计算王者
我们现在重点关注的是GPU,作为AI高性能计算的王者,有两个主要功能:图形渲染和通用计算。而英伟达之所以如此受欢迎,因其具备通用计算功能,即GPGPU。这种模式将图形渲染功能削弱,增加通用计算功能。GPU微架构设计是提升GPU性能的关键,它是兼容特定指令集的物理电路构成,包括流处理器、纹理映射单元、光栅化处理单元、光线追踪核心、张量核心、缓存等组件。英伟达H100相比A100,性能提升了1.2倍来自于核心数目的提升,性能提升了5.2倍则来自于微架构的设计。
然而,在通用技术方面,国产厂商与国外仍存在巨大差距。目前我国使用的GPU芯片全部来自英伟达和AMD这两家公司,虽然图形渲染上的差距不断缩小,但在通用计算方面仍然存在较大差距。首先,在制程方面,英伟达采用4纳米制程,而国内厂商目前仍在7纳米制程上。其次,在算力方面,国内厂商大多不支持双精度(FP64)计算,而在单精度(FP32)和定点计算(INT8)方面与国外中端产品持平,天数智芯、壁仞科技的AI芯片产品在单精度性能上超过NVIDIA A100。最后,在生态方面,国内企业多采用OpenCL进行自主生态建设,相比Nvidia CUDA的成熟生态,差距较为明显。
4、FPGA:国产替代空间巨大
至于FPGA,国产替代的潜力还是很大。吞吐量是CPU的十倍,功耗却只有GPU的十分之一。全球FPGA市场呈现“两大两小”格局,Altera与Xilinx市占率共计超过80%,Lattice和Microsemi市占率共计超过10%。根据Frost&Sullivan的数据,国内FPGA厂商的国产化率不到5%,未来国产化的空间非常广阔。在工艺制程方面,当前国产厂商的先进制程集中在28nm,落后于国际16nm水平。而在等效LUT数量上,国产厂商旗舰产品只有约Xilinx高端产品的25%。
同时,我们正在考虑投资MPGA(Massively Parallel Genetic Algorithms)芯片企业,MPGA是替代和补充FPGA的。重点考虑的是结构优化,结构优化可以让MPGA超越FPGA在速度、容量、融合性、算力和功耗成本等方面都非常强。采用90纳米工艺相对于FPGA的14到16纳米工艺,从而减轻对光刻机的依赖。MPGA的基本诀窍是采用多层结构特殊工艺,简化了结构,使指令执行速度更快,功耗更小。它实现了逻辑和配线分离,避免了冯诺依曼构架中运算单元和存储单元分置的情况,实现了“存算一体”的功能。
5、ASIC:国产替代正当时
ASIC芯片因其定制化和分散化的特点而成为最成熟的解决方案。定制化的特点使得ASIC芯片能够根据客户需求进行定制设计,因此其市场壁垒相对较小。目前国内厂商在7nm工艺上已经与国外厂商持平,并且算力方面也逐渐赶上。国内厂商有望突破国外AI芯片的垄断地位。
对于AI芯片来说,最重要的护城河之一是生态体系,就像操作系统对于芯片的重要性一样。生态体系对用户体验至关重要,比如英伟达的CUDA架构大幅降低了GPGPU并行计算的编程难度,实现了GPU并行计算的通用化。作为完整的GPU解决方案,CUDA提供了硬件的直接访问接口,降低了开发门槛。
对于国内厂商,建设生态系统有两条路线。一是兼容英伟达的CUDA,可以减轻开发和迁移难度,快速实现客户端导入;二是自建生态系统,借鉴AMD和Google的做法,摆脱对英伟达的依赖,打造自己的生态圈核心壁垒。预计硬件性能高效且能构建符合下游需求的生态体系的国产厂商有望脱颖而出。
1、Chiplet是AI芯片大势所趋
如何打破算力和制程工艺方面的瓶颈限制尤为重要,特别是在14纳米以下的制程无法生产且无法做出来的情况下。解决这个问题,我们需要依靠先进封装技术。系统异质整合是提升系统性能、降低成本的关键技术之一。AI芯片中,Chiplet技术正在兴起,类似于搭积木的方式,通过先进的集成技术将一些预先生产的实现特定功能的裸片(Chip)封装在一起,形成一个系统级芯片(SoC)。封测产业在国内芯片行业的产业链中处于最成熟的阶段,通富微电和长电科技已经是全球第三大封装企业,华天科技也处于市场战略很高的地位。
2、存算一体:打破“存储墙”限制
存算一体是一种新型的算力架构。在传统处理器设计中,主要关注提升计算速度,而存储方面更注重容量提升和成本优化,这导致了“存”和“算”之间性能失配的问题,即冯诺依曼架构中的“存储墙”和“功耗墙”。从处理单元外的存储器提取数据的时间往往是运算时间的成百上千倍,整个过程的能耗大约在60%到90%之间,能效非常低,成为了计算的瓶颈。在我国,存算一体的市场空间很大,预计到2025年将达到125亿元,到2030年有望达到1136亿元,增速也非常惊人。
最后,分享一个投资体会,当我们进行投资时,不仅仅应该专注于技术本身,更重要的是要跳出技术的视角,综合考虑多方面因素。单纯专注于技术而忽略其他方面可能导致投资效果不佳。
Q1: AIGC对于国内的中大型企业来讲,应用的障碍在于数据安全、流动共享等问题。目前我们有什么破局的手段和办法?
A:主要有两个层面,从国家立法层面,要持谨慎的态度。另外要做数据脱敏分析,不能直接进行盈利,如果直接把白名单泄露出去或者进行买卖盈利是不可行的。
Q2:按发展趋势,就其他云计算厂商跟英伟达包括在这个芯片厂家之间的竞争格局是什么样子的?
A:这个情况有些类似于手机操作系统的苹果iOS和安卓系统。谁开放,谁采用开源策略,并没有一个确定的结论。核心问题不在于技术本身,而在于生态系统的构建。除非大家联合起来,实现全部开源并统一标准。但根据当前趋势来看,各家都在建立自己独立的生态体系,自行研发芯片以降低成本。然而,要达到像英伟达那样通用的水平,仍然具有挑战性。
Q3:国内AIGC的各类芯片成功的关键要素是什么?你是怎样去选择标的?
A:判断标的标准首先要看大方向,我们必须考虑赛道的拥挤程度和竞争度。为什么GPU现在如此热门,而国内却没有GPU呢?这是因为大家都站在同一条起跑线上。如果现在进入这个领域,是否还来得及取得优势?拿CPU和GPU作比较,为什么GPU能做到而CPU做不到呢?对于投资来说,不能对技术有过多限制,否则容易产生一叶障目的局限性。逻辑很简单,这类公司的应用领域是国产替代。目前国产替代最广泛应用的是信创领域。另外,还需要看公司背景,CEO首席科学家的背书能力超过了团队中百分之六七十的力量。
Q4:GPGPU公司在国内五年之后的发展格局会是什么样?
A:目前我国国内的GPU和GPGPU初创公司,都是出于刚起步阶段,就像万米长跑,只不过是谁跑了500米,谁跑了1000米而已,先发优势不是那么重要,谁能跑到万米终点,目前来看,还没有定论。但有一点,不论是先做图形渲染功能的GPU公司,还是先做通用计算/并行计算的GPGPU公司,最后都会速途同归,肯定都有野心做两个功能兼备的GPU公司,只不过是结合各自企业的技术优势和情况,切入点不同而已,因此未来3-5年肯定会有一番混战。从综合因素考虑,如果这家企业出身根正苗红,拥有强大的创新能力,那么其先发优势将更为突出,因此大家起步的市场,都有赖于信创产业。
Q5:请问我国目前大模型创业还有机会吗?
A:目前来看,AI机器学习的大模型的主导地位还主要由大型企业占据。对于一些小公司来说,创业的难度可能较高。有些行业可能并不适合初创公司去涉足。在大模型创业领域,难度不仅仅在于算法,还在于后续的资源和资金投入,需要大量的数据库和硬件成本来进行堆积、计算和迭代,你看GPT-3的训练成本就高达1200万美元,所以资金才是最大的门槛。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号