Java编程:深入理解数据结构与算法
发表时间: 2023-11-12 13:24
数据项:一个数据元素可以由若干数据项组成】
数据对象:有相同性质的数据元素的集合,是数据的子集
数据结构:是相互之间存在的一种或多种特定关系的数据元素的集合
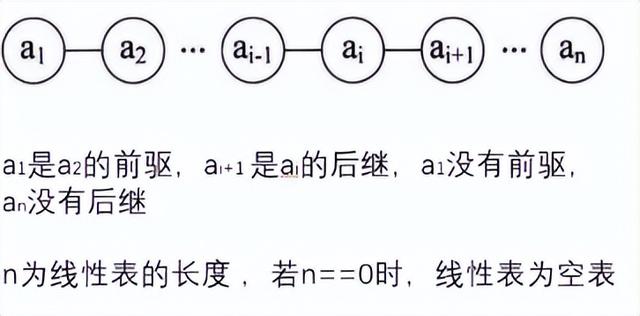
零个或多个元素的有序序列

class Student { Student[40]; int size; ... }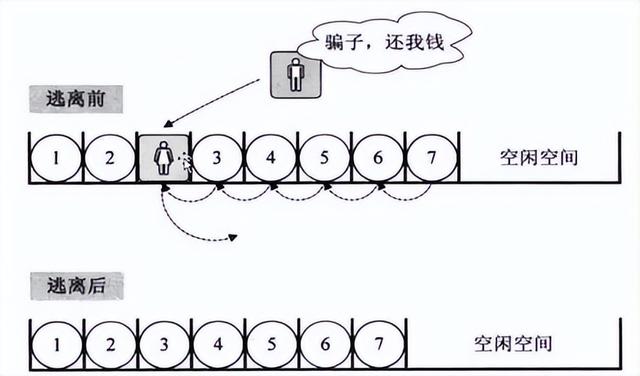
删除节点:将节点后每个元素往前挪一位
transient Object[] elementData;扩展:为什么用transient修饰elementData?
被transient修饰的变量不参与序列化和反序列化。当一个对象被序列化的时候,transient型变量的值不包括在序列化的表示中,然而非transient型的变量是被包括进去的。
elementData不参与默认的序列化和反序列化,不代表没有进行序列化和反序列化 ArrayList在序列化的时候会调用writeObject,直接将size和element写入ObjectOutputStream;反序列化时调用readObject,从ObjectInputStream获取size和element,再恢复到elementData。 不直接用elementData来序列化,而采用上诉的方式来实现序列化是因为elementData是一个缓存数组,它通常会预留一些容量,等容量不足时再扩充容量,那么有些空间可能就没有实际存储元素,采用上诉的方式来实现序列化时,就可以保证只序列化实际存储的那些元素,而不是整个数组,从而节省空间和时间。
ArrayList的底层操作机制源码分析(重点)
//创建了一个空的elementData数组 = {} public ArrayList() { this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; } //执行list.add //1. 先确定是否要扩容 //2. 然后再执行扩容的操作 public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true; } //该方法确定minCapacity 1.第一次扩容为10 private void ensureCapaccityInternal(int minCapacity) { if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity); } ensureExplicitCapacity(minCaacity); } //1. modCount++ 记录集合被修改的次数 //2. 如果elementData的大小不够,就调用grow()去扩容 //3. private void ensureExplicitCapacity(int minCapacity) { modCount++; // overflow-conscious code if (minCapacity - elementData.length > 0) grow(minCapacity); } //1. 真的扩容 //2. 使用扩容机制来确定扩容到多大 //3. 第一次newCapacity = 10 //4. 第二次及其以后,按照1.5倍扩容 //5. 扩容使用的是Arrays.copyOf() private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); }如果插入元素数大于index,将index后的元素移到新元素之后,再将新元素从index处开始复制
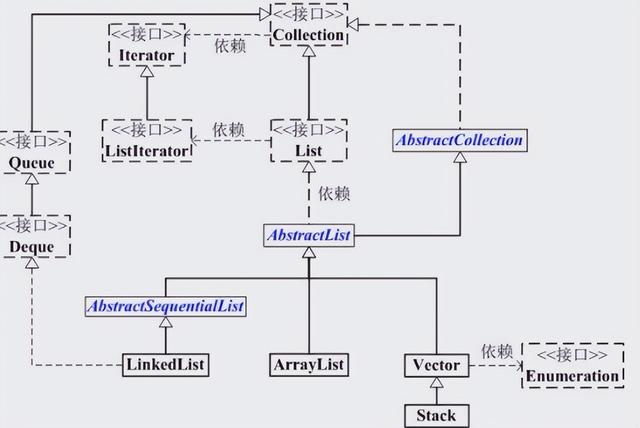
Arraylist的继承关系

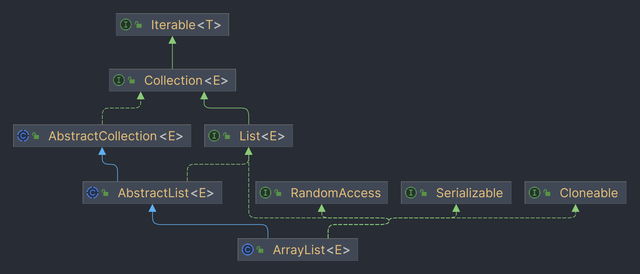
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.SerializableIsterator 接口 -> 用来快速轮询容器
private class Itr implements Iterator<E> { int cursor; // index of next element to return int lastRet = -1; // index of last element returned; -1 if no such int expectedModCount = modCount; // prevent creating a synthetic constructor Itr() {} public boolean hasNext() { return cursor != size; } @SuppressWarnings("unchecked") public E next() { checkForComodification(); int i = cursor; if (i >= size) throw new NoSuchElementException(); Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) throw new ConcurrentModificationException(); cursor = i + 1; return (E) elementData[lastRet = i]; } public void remove() { if (lastRet < 0) throw new IllegalStateException(); checkForComodification(); try { ArrayList.this.remove(lastRet); cursor = lastRet; lastRet = -1; expectedModCount = modCount; } catch (IndexOutOfBoundsException ex) { throw new ConcurrentModificationException(); } } @Override public void forEachRemaining(Consumer<? super E> action) { Objects.requireNonNull(action); final int size = ArrayList.this.size; int i = cursor; if (i < size) { final Object[] es = elementData; if (i >= es.length) throw new ConcurrentModificationException(); for (; i < size && modCount == expectedModCount; i++) action.accept(elementAt(es, i)); // update once at end to reduce heap write traffic cursor = i; lastRet = i - 1; checkForComodification(); } } final void checkForComodification() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); } }作业:
https://leetcode.com/problems/remove-duplicates-from-sorted-array/
https://leetcode.com/problems/search-insert-position/
https://leetcode.com/problems/search-insert-position/
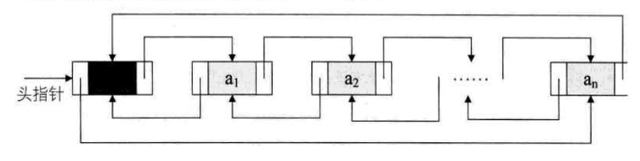
线性表的链式存储结构的特点是用一组任意的存储单元存储线性表的数据元素,这组存储单元还是可以连续的,也可以是不连续的
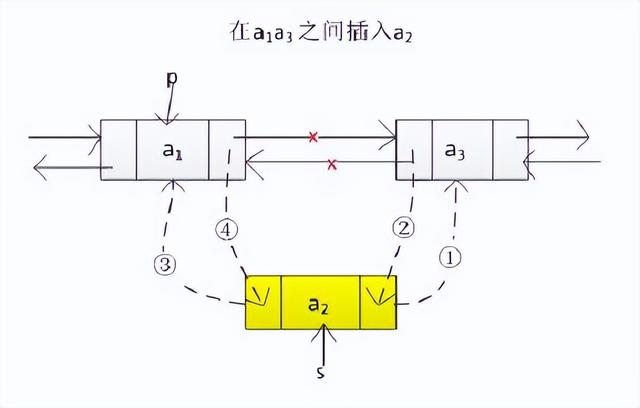
添加节点
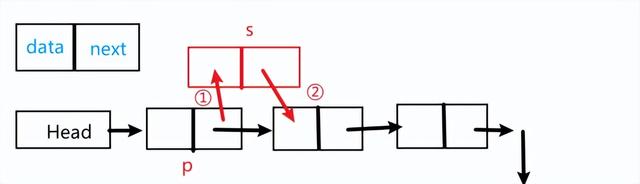
注意顺序:
① p.next = s
② s.next = p.next
为什么是这个顺序,反了会怎样?
s.next = p.next
p.next = s
会导致s.next指向s
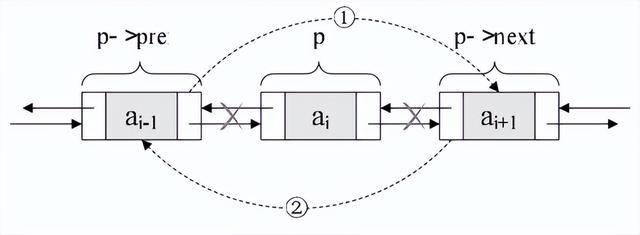
删除节点:
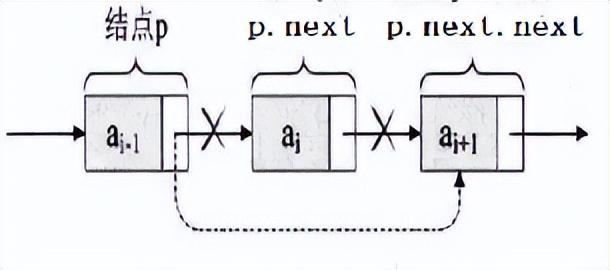
p.next = p.next.next
修改节点
p.data = new data();
查询节点
while(p.next != I){ p = p.next;}双链表的存储结构单元
private static class Node<E> { E item; Node<E> next; Node<E> prev;}
双链表的表现形式
增加节点
1: s.next = p.next;
2 p.next.prev = s;
3 s.prev = p;
4 p.next = s;
注意:2和4不能调换位置
删
p.next.prev = p.prev;
p.pre.next = p.next;
源码解析

优点 | 缺点 | 应用 | |
顺序表 | 存储空间连续 允许随机访问 尾插、尾删方便 | 插入效率低 删除效率低 长度固定 | 哪哪都在用 |
单链表 | 随意进行增删改 插入效率高 长度可以随意删改 | 内存不连续 不能随机查找 | |
双链表 | 随机进行增删改 插入效率高 删除效率高O 长度可以随意修改 查找效率比单链表快一倍 | 应用:linkedList |
作业:
算法题:
https://leetcode.cn/problems/merge-two-sorted-lists/
https://leetcode.c/problems/swap-nodes-in-pairs/
https://leetcode.com/problems/copy-list-with-random-pointer/
//节点的信息 class Node { T data; Node next; public Node(T data, Node node) { this.data = data; //记录当前节点的数据 this.next = node; //记录当前节点的下一个节点 }LinkedList类
public class LinkedList<T> { Node list; int size; }public LinkedList() { size = 0; //新创建节点数为0}CPU缓存:位于CPU与内存之间的临时存储器。解决CPU速度和内存速度之间速度差异问题
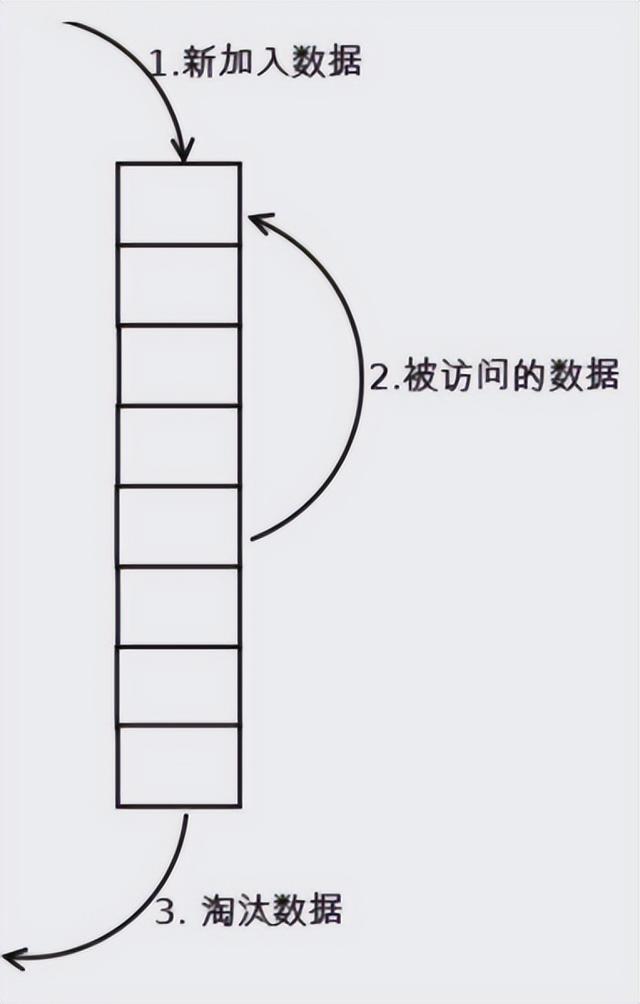
队列在线程池中是什么情况
队列的存储结构
队列的基本操作
队列的分类
ThreadPoolExecutor线程池实现类
private final BlockingQueue<Runnable> workQuene; //阻塞队列private final ReentrantLock mainLock = new ReentrantLock(); //互斥锁private final HashSet<Worker> Workers = new HashSet<Worker>(); //线程集合 一个Worker对应一个xianchengprivate final Condition termination = mainLock.newCondition(); //终止条件private int largestPoolSize; //线程池中线程数量曾经达到过的最大值private long completedTaskCount; //已完成任务数量private volatile ThreadFactory threadFactory; //ThreadFactory对象,用于创建线程private volatile RejectedExecutionHandler handler; //拒绝策略的处理句柄private volatile long keepAliceTime; //线程池维护线程所允许的空闲时间private volatile boolean allowCoreThreadTimeOut;private volatile int corePoolSize; //线程池维护线程的最小数量,哪怕是空闲的private volatilee int maximumPoolSize; //线程池维护的最大线程数量线程池排队:
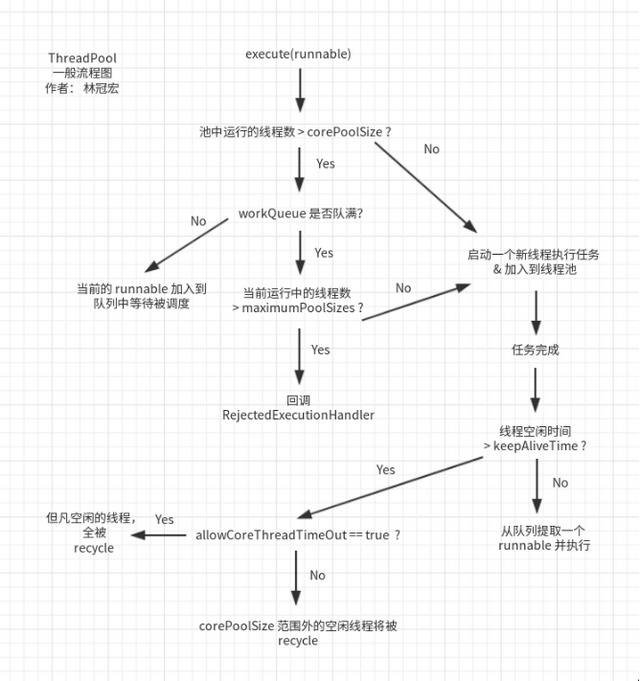
假设队列大小为10,corePoolSize为3,maximumPoolSize为6,那么当加入20个任务时,执行的顺序应该是怎样的?
队列(queue)又叫先进先出表,它是一种运算受限的线程表。
其权限是仅允许在表的一端进行插入和另一端取数据,插入是数据的一端是队尾,取数据的一端是队头
什么是栈?
栈(stack)又名后进先出表,它是一种运算受限的线性表
其限制是仅允许在表的一端进行插入和删除运算。这一端被称为栈顶,相对的,把另一端称为栈底
进栈:入栈或压栈,将新元素放到栈顶 元素的上面,使之成为新的栈顶元素
出栈:退站,将栈顶元素删除掉,使之与其相邻的元素成为新的栈顶元素
Java中的Stack是通过Vector来实现的,这种设计被认为是不良的设计,说说你的看法?
由于Stack继承了Vector,有了很多不符合栈的特性的方法 ,比如add方法
逆波兰表达式是一种利用栈来进行运算的数学表达式
中缀表达式转为后缀表达式:
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号