PG12.2数据库备份恢复机制详解:五大方法值得收藏
发表时间: 2020-12-22 00:04
备份重于一切,今天主要介绍PG的五种备份方式,仅供参考。
ps:前四种重点掌握
1、语法
可以在本地及远程进行备份,只需要表的读权限即可备份。pg_dump创建的备份是一致的,在pg_dump运行时数据库产生快照,不阻塞数据库的DML操作,但是会阻塞需要排他锁的操作,如alter table等。特别注意的是,pg_dump一次只能备份一个单独的数据库,且不能备份角色和表空间信息(因为这些信息是cluster-wide,而不是在某个数据库中(per-database))。
使用pg_dump的自定义转储格式。. 如果PostgreSQL所在的系统上安装了zlib压缩库,自定义转储格式将在写出数据到输出文件时对其压缩。这将产生和使用gzip时差不多大小的转储文件,但是这种方式的一个优势是其中的表可以被有选择地恢复。
下面的命令使用自定义转储格式来转储一个数据库:
pg_dump -Fc dbname > filename
自定义格式的转储不是psql的脚本,只能通过pg_restore恢复,例如:
pg_restore -d dbname filename
pg_dump [OPTION]... [DBNAME]pg_restore [OPTION]... [FILE]
2、常见用法
--导出指定库(不含create database语句)pg_dump -h xx.xx..142 -U hwb -p 55432 -d pas_db > /data/pgbackup/pas_db_bak202012.sql#导出指定库(包含create database语句)pg_dump -h xx.xx..142 -U hwb -p 55432 -C pas_db > /data/pgbackup/pas_db_bak202012.sql--导出指定库,结果以自定义压缩格式输出pg_dump -Fc -h xx.xx..142 -U hwb -p 55432 -d pas_db > /data/pgbackup/pas_db_bak202012.dump--备份表pg_dump -h xx.xx..142 -U hwb -p 55432 -d pas_db -t t1 -t t2 > /data/pgbackup/t.sql--备份某个模式所有表(schema名为hwb)pg_dump -h xx.xx.142 -U hwb -p 55432 -d pas_db -t 'hwb.*' > /data/pgbackup/schema_202012.sql--备份某个模式所有表,排除一张表pg_dump -h xx.xx.142 -U hwb -p 55432 -d pas_db -t 'hwb.*' -T hwb.t1 > /data/pgbackup/schema_t1_202012.sql--还原(导入postgres库,自动创建schema和表)pg_restore -h xx.xx.142 -U postgres -p 55432 -d postgres -v /data/pgbackup/pas_db_bak202012.dump--single-transaction表示整个恢复过程是一个事务,要么成功要么回滚--恢复后需运行ANALYZE收集统计信息psql -h xx.xx.142 -U postgres -p 55432 -d postgres --single-transaction < /data/pgbackup/pas_db_bak202012.sql

pg_dump只备份数据库集群中的某个数据库的数据,它不会导出角色和表空间相关的信息。pg_dumpall则可以导出整个数据库集群中所有的数据库中的数据,同时也会导出角色、用户和表空间的定义信息。
执行pg_dumpall需要超级用户权限。
1、语法
pg_dumpall [OPTION]...
2、常用用法
--导出所有database(当应用需要OID字段的话(比如在外键约束中用到),需添加-o选项)pg_dumpall -v > /data/pgbackup/db_all.dmp--只转储全局对象(角色和表空间),而不转储数据库pg_dumpall -g -v > /data/pgbackup/role_tbs.sql---r(roles-only)只转储角色,不转储数据库或表空间pg_dumpall -r -v > /data/pgbackup/role.sql-s(schema-only)只输出对象定义(模式),不输出数据pg_dumpall -s -v > /data/pgbackup/schema.sql--恢复(执行这个命令的时候连接到哪个数据库无关紧要,因为pg_dumpall 创建的脚本会包含创建和连接数据库的命令)--恢复时需删对应数据库,否则如果数据库存在对应的表会自动插入新的数据psql postgres -f db_all.dmp 
COPY在PostgreSQL表和文件之间交换数据。 COPY TO把一个表的所有内容都拷贝到一个文件,而COPY FROM从一个文件里拷贝数据到一个表里(把数据附加到表中已经存在的内容里)。 COPY TO还能拷贝SELECT查询的结果。
如果声明了一个字段列表,COPY将只在文件和表之间拷贝已声明字段的数据。 如果表中有任何不在字段列表里的字段,那么COPY FROM将为那些字段插入缺省值。
带文件名的COPY指示PostgreSQL服务器直接从文件中读写数据。 如果声明了文件名,那么服务器必须可以访问该文件,而且文件名必须从服务器的角度声明。 如果使用了PROGRAM选项,则服务器会从指定的这个程序进行输入或是写入该程序作为输出。 如果使用了STDIN 或STDOUT选项,那么数据将通过客户端和服务器之间的连接来传输。
注意:copy命令必须在plsql命令行执行,执行用户必须为superuser,普通用户进行执行,需要在copy前面加入 “\”,即 \copy。
COPY只能用于表,不能用于视图,不过可以用于COPY (SELECT * FROM viewname) TO ...
1、语法
--导出COPY { table_name [ ( column_name [, ...] ) ] | ( query ) } TO { 'filename' | PROGRAM 'command' | STDOUT } [ [ WITH ] ( option [, ...] ) ]--导入(如果导出的时候,指定了header属性,那么在导入的时候,也需要指定)COPY table_name [ ( column_name [, ...] ) ] FROM { 'filename' | PROGRAM 'command' | STDIN } [ [ WITH ] ( option [, ...] ) ]copy to的导出速度非常之快,经测试10W的数据量只需要3秒左右的时间。
COPY FROM能够识别下列特殊反斜杠字符:

2、常见用法
--服务端导出,导出到数据库所在服务器copy t2 to '/data/pgbackup/t2.csv' with csv;--导出指定属性copy t2(name) to '/data/pgbackup/t2_name.csv' with csv;copy (select * from t2) to '/data/pgbackup/t2_sel.csv' with csv;--客户端导出,导出到psql命令所在服务器\copy t2 to '/tmp/t2.dmp' 或者psql -c "copy t2 to stdout" > /tmp/t2.dmp--如果导出的字段,有integer[]类型,直接导出,再导入的话,会有问题,解决办法是需要在导出的时候,进行处理\COPY ( select coalesce(integer_array, '{}')::integer[] as integer_array from table ) TO '/tmp/data.csv' with csv header;--使用escape或unicode模式输入特殊字符(例如TAB做分隔符)\copy aa from '/tmp/aa.csv' with (delimiter U&''\0009'09')\copy aa from '/tmp/aa.csv' with (delimiter E'\t')
1、基础备份
--postgresql.conf# - Archiving -wal_level = replicaarchive_mode = on # enables archiving; off, on, or alwaysarchive_command = 'test ! -f /data/pgarch/%f && cp %p /data/pgarch/%f;find /data/pgarch/ -type f -mtime +30 -exec rm -f {} \;'--创建REPLICATION角色CREATE ROLE replica login replication encrypted password 'replica@1234';--配置pg_hba.conf,允许远程流式备份echo "host replication replica 0.0.0.0/0 md5" >> pg_hba.conf--模拟数据create database pas_db with owner=hwb ENCODING='UTF8' TABLESPACE=pas_data connection limit=-1;\c pas_db postgresselect pg_switch_wal();create table t4(id int);select pg_switch_wal();insert into t4 values(1),(2),(3),(4);select pg_switch_wal();select current_timestamp;-- 2020-12-14 16:13:23.10133+08select pg_switch_wal();insert into t4 values(5),(6),(7),(8);--远程使用pg_basebackup备份systemctl stop postgresqlrm -rf /data/pgdata/*#-Fp表示以plain格式数据,-Xs表示以stream方式包含所需的WAL文件,-P表示显示进度,-R表示为replication写配置信息。#备份完成,使用-R选项,在data目录下自动生成standby.signal“信号”文件(可手工使用touch命令生成)以及更新了postgresql.auto.conf文件#postgresql.auto.conf中写入了主库的连接信息(可手工添加primary_conninfo信息)。pg_basebackup --progress -D /data/pgdata -h xx.142 -p 55432 -U replica --password -Fp -Xs -P -R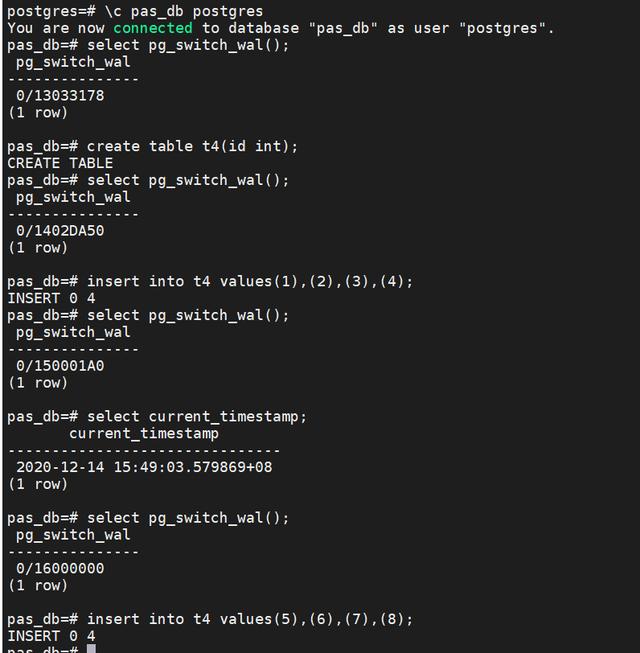
2、恢复
--在data目录下创建一个空文件:touch recovery.signal--修改 postgresq.conf 文件把archive相关参数全部注释掉并增加两行:restore_command = 'cp /data/pgarch/%f %p'recovery_target_time = '2020-12-14 16:13:23.10133+08'a.恢复到最新:restore_command = 'cp /data/pgarch/%f %p'recovery_target_timeline = 'latest'b.恢复到指定的时间点:restore_command = 'cp /data/pgarch/%f %p'recovery_target_time = '2020-12-14 16:13:23.10133+08'c.创建还原点:SELECT pg_create_restore_point('restore_point1');d.恢复到还原点:restore_command = 'cp /data/pgarch/%f %p'recovery_target_name ='restore_point1'--启动数据库进行恢复systemctl restart postgresqlPostgreSQL有一个导出和导入事务快照的功能,这个功能在9.2版本开始支持,允许事务共享它当时的snapshot给其他的事务使用。
SET TRANSACTION SNAPSHOT命令允许新的事务使用与一个现有事务相同的快照运行。已经存 在的事务必须已经把它的快照用pg_export_snapshot函数导出。该函数会返回一个快照标识符,SET TRANSACTION SNAPSHOT需要被给定一个快照标识符来指定要导入的快照。
需要注意的是:只有事务是SERIALIZABLE以及 repeatable read时,DEFERRABLE 事务属性才会有效。
PostGreSQL采用“快照”方式来实现MVCC。具体地说,这意味着每一个事务中的查询仅能看到:
1)该事务启动之前已经提交的事务所作出的数据更改。
2)当前事务中该查询之前的查询所作出的更改。
下面基于事务隔离级别repeatable read进行测试
1、建表
create table test (id int); insert into test values (1),(2);--开启五个会话进行测试
2、session1:
begin TRANSACTION ISOLATION LEVEL repeatable read; SELECT pg_export_snapshot(); --00000004-0000047B-1insert into test values (3);SELECT pg_export_snapshot(); --00000004-0000047B-2select * from txid_current();select * from txid_current_snapshot(); 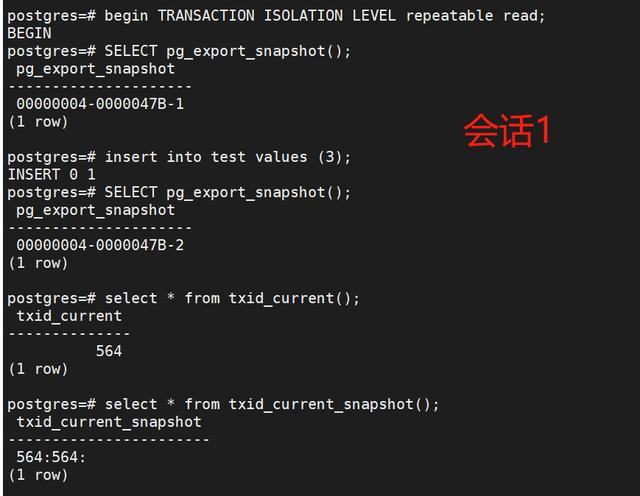
3、session2(插入一条新数据并提交):
insert into test values (4);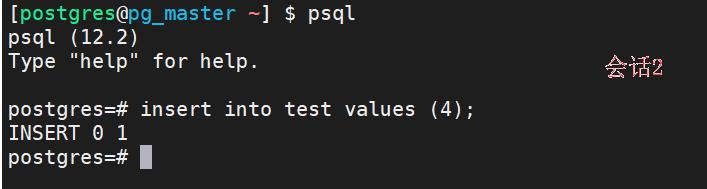
4、session3(能查看到会话2插入的数据):
select * from test;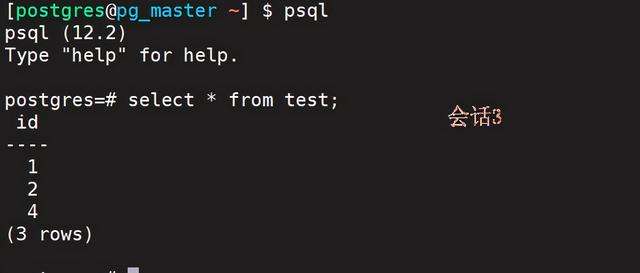
5、session4 (导入s1的第一个snapshot, 因此看不到s2提交的数据) :
begin TRANSACTION ISOLATION LEVEL repeatable read; SET TRANSACTION SNAPSHOT '00000004-0000047B-1';select * from test; select * from txid_current(); select * from txid_current_snapshot();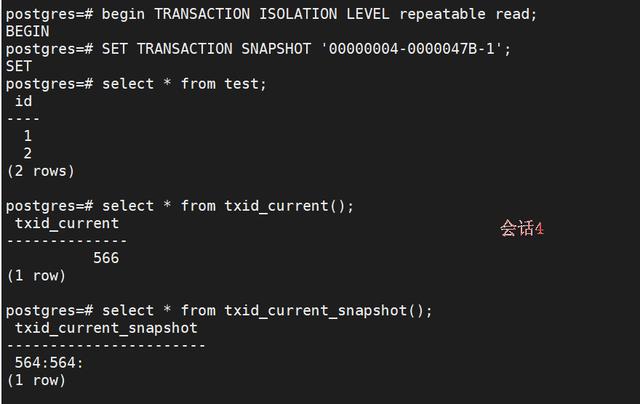
6、session5 (导入s1的第二个snapshot, 因此看不到s2提交的数据, 同时验证了看不到s1修改过的数据):
begin TRANSACTION ISOLATION LEVEL REPEATABLE READ; SET TRANSACTION SNAPSHOT '00000004-0000047B-2';select * from test; select * from txid_current(); select * from txid_current_snapshot(); 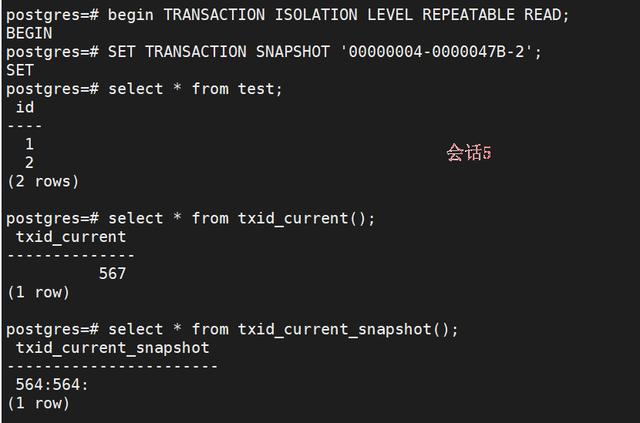
7、session1(提交):

8、session4 (s1提交后, 这个snapshot还存在, 只要还有导入了这个snapshot的事务存在着) :
select * from test; 
9、session5 (s1提交后, 这个snapshot还存在, 只要还有导入了这个snapshot的事务存在着)

篇幅有限,基于时间点恢复的内容后面单独介绍吧,感兴趣的朋友可以关注下!

声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号