Redis数据类型深度解析:技术干货分享
发表时间: 2019-09-15 21:16
关于Redis的五大数据类型,它们分别为:String、List、Hash、Set、SortSet。本文将会从它的 底层数据结构 、 常用操作命令 、一些 特点 和 实际应用 这几个方面进行解析。对于数据结构的解析,本文只会从大的方面来解析,不会介绍详细的代码实现。
String
1.实现结构
String是Redis中最常用的一种数据类型,也是Redis中最简单的一种数据类型。首先,表面上它是字符串,但其实他可以灵活的表示 字符串、整数、浮点数 3种值。Redis会自动的识别这3种值。那么,String的底层数据机构又是怎样的呢?由于Redis是使用c语言实现的,而c语言中没有String这一数据类型,那么就需要自己实现一个类似于String的 结构体 。它的名字就叫做SDS(simple dynamic string),下面是它的代码结构。
1 typedef struct sdshdr {2 // buf中已经占用的字符长度3 unsigned int len;4 // buf中剩余可用的字符长度5 unsigned int free;6 // 数据空间7 char buf[];8 }如果有了解过Java集合框架类的朋友都知道,这种结构与集合中 动态数组结构 类似,那么就会涉及到一系列的扩容判断和操作,但这些具体的做法在这里不深入讲解。不过有一点比较重要的就是String的value值最大可以存放 512MB 的数据,所以有时候它不仅仅可以存放字符,还可以存放字节数据。
2.实际应用
在讲实际应用之前,要声明的是Redis是基于 单线程IO多路复用 的架构实现的NoSql,意味着它的操作都是 串行化 的,所以在命令操作上不会出现线程安全问题,基于这个特性可以有很多应用。
List
1.实现结构
首先,List的主要存取操作有 lpush、lpop、rpush、rpop, 有点像是双向队列。List的实现是灵活多样的,它分别有ziplist(压缩链表)、LinkedList(双向链表)两种实现方式。

1.ziplist
如下图所示,它是基于连续内存实现( 类似数组 )。当然, 它的每一个entry的大小可能不是一致的,这就需要特殊的控制手段去解决 ,所以才叫压缩表。那么数组有的特性它都会有,比如在lpush、lpop的时候就会有数据的搬移,时间复杂度是O(n)。所以,一般在 数据元素较少 时使用ziplist结构实现。

2.LinkedList
则与我们日常所学的双向链表相差无异,同样也保留则头尾指针、数据长度等数据,这里就不再详细说明,需要了解的去读一读Java的LInkedList源码也不错。
2.实际应用
Hash
1.实现结构
首先,Hash的特性我们可以想象为 Java集合中的HashMap ,一个hash中可以有多个field:value(键值对)。关于hash的实现同样有 两种情况 。一种是基于ZipList,一种是基于HashTable实现。
1.ZipList
这里的的ZipList与List当中的ZipList其实是相差无几的,唯一的特点就是Hash存储的时候,它的entry数量是成对增加的,同时也是 成对存在 的,所以它的长度一定是2的整数倍。filed值放在前面,value放在后面的形式存放。当然采用ZipList操作时,它的查找删改查的时间复杂度就会变为O(n),所以ZipList适合在数据较少的情况下使用。

2.HashTable
虽然说Hash与Java中的HashMap 功能类似 ,但在HashTable这个结构上还是有一定的不同点的。要想了解HashTable的实现,需要了解三个结构。它们分别是: dict 、 dictht 、 entry 。entry和前面list中提到的类似,下面列出前面两个结构的定义:
1 // 哈希表(字典)数据结构,Redis 的所有键值对都会存储在这里。其中包含两个哈希表。 2 typedef struct dict { 3 // 哈希表的类型,包括哈希函数,比较函数,键值的内存释放函数 4 dictType *type; 5 // 存储一些额外的数据 6 void *privdata; 7 // 两个哈希表 8 dictht ht[2]; 9 // 哈希表重置下标,指定的是哈希数组的数组下标10 int rehashidx; /* rehashing not in progress if rehashidx == -1 */11 // 绑定到哈希表的迭代器个数12 int iterators; /* number of iterators currently running */13 } dict;14 15 typedef struct dictht { 16 //槽位数组17 dictEntry **table; 18 //槽位数组长度19 unsigned long size; 20 //用于计算索引的掩码,可以理解为hash函数 21 unsigned long sizemask;22 //真正存储的键值对数量23 unsigned long used; 24 } dictht;关系可以总结为下面这幅图:

2.实际应用
Set
Set是一个不允许重复的,无顺序的数据集合。值得注意的是,这里说的无顺序其实还是有一点歧义的,那么到底是怎么回事呢?接下来的博文就会有提到这个差异。
1.实现结构
1.IntSet。
这里的IntSet是一种在满足特定情况下所使用的数据结构。这种情况就是当 全部value都为整型时,redis会使用IntSet这种结构。在这个情况下它是有序的。这是为什么呢?先从结构开始说起,为了平衡空间的性能的消耗,Redis在数据都为整型的时候使用了一种基于 动态数组 的结构体,同时在存放元素时保正元素的大小顺序,这样就可以使用 二分查找 以时间复杂度O(logn)来完成增删改查的操作。这样就节省了很多空间。至于增和删操作,同样会涉及到数组的数据搬移操作。下面为它的结构体代码:
1 typedef struct intset {2 // 编码方式3 uint32_t enconding;4 // 集合包含的元素数量5 uint32_t length;6 // 保存元素的数组 7 int8_t contents[];8 } intset;2.HashTable
当存在 非整型 数据的时候,Redis会 自动把IntSet转换为HashTable 的结构存放数据,但HashTable不能转换为IntSet。这里的HashTable与上面Hash结构提到的HashTable没有太大的差别。唯一的差别就在于Set存放在HashTable中只有Key值,没有value值,所以在HashTable的Entry中, Enrty的value永远为null。

2.实际应用
SortSet
SortSet是一个实现了 数据有序且唯一的键值对 集合。其中,Entry的键为string类型,值为整型或浮点型,表示权值score。其中 SortSet的顺序就是通过Score的值来确定 的。
1.实现结构
SortSet的实现结构同样有两种,一种是ZipList结构实现,适用于较少数据的情况。另一种是 SkipList+HashTable 的形式,使用与数据较多的情况,其中 SkipList 是在 保证有序 的情况下 优化范围查找 的时间复杂度,而 HashTable 则是 优化增删改查 的时间复杂度。
1.ZipList
SortSet的ZipList和Hash中的数据结构类似,同样也是存放键值对,但是它维护了基于Score的有序性( 默认从小到大 ),这里就不再赘述。
2.SkipList+HashTable
首先来说明主要的SkipList(跳表),跳表是一种基于 有序链表 ,通过建立 多层索引 ,以 空间换时间 的方式实现 平均查找效率为O(logn) 复杂度的一种数据结构。下面给出一个跳表的基本形式图:

可以看到在根据数据的权值Score进行查找的时候,从最顶层的索引开始查找。当找到数据在某个范围后,在往下一层的索引查找,然后就这样一路缩小查找的范围。看上去是不是有点 像二分查找 ?至于跳表的具体介绍和实现,可以参考这篇文章: 为什么Redis要用跳表实现有序集合?
上面可以看到,基于跳表的实现的有序集合可以完成增删改查实现O(logn)的时间复杂度,那么有没有更加快的方式来实现O(1)的时间复杂度呢?通常说起O(1)的时间复杂度都会想起HashTable这个数据结构。Redis就利用HashTable+SkipList的组合数据结构, HashTable来实现增删改查的时间复杂度为O(1)的同时SkipList保证数据的有序性 ,可以方便的获取一个范围的数据。
至于HashTable的实现与前面谈到的一致,下面用一张图来说明两个数据结构结合是什么样子的。
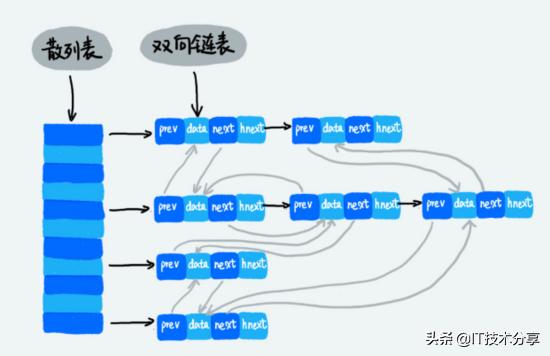
上图中,每一个节点可以看成 一个跳表的节点 同时也是 HashTable中的一个节点 。
这样,当我们需要增删改查的时候,利用HashTable的特性实现时间复杂度为1的操作,当我们需要基于权值Score进行范围查找的时候可以通过SkipList进行时间复杂度为O(logn)的查找。
2.实际应用
end:如果你觉得本文对你有帮助的话,记得关注点赞转发,你的支持就是我更新动力。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号