真实案例解析:Golang内存问题排查指南
发表时间: 2022-04-12 11:56
在日常搬砖的某一天发现了某微服务 bytedance.xiaoming 服务有一些实例内存过高,达到 80%。而这个服务很久没有上线过新版本,所以可以排除新代码上线引入的问题。

发现问题后,首先进行了迁移实例,除一台实例留作问题排查外,其余实例进行了迁移,迁移过后新实例内存较低。但发现随着时间推移,迁移过的实例内存也有缓慢增高的现象,有内存泄漏的表现。
通常内存泄露的主因就是 goroutine 过多,因此首先怀疑 goroutine 是否有问题,去看了 goroutine 发现很正常,总量较低且没有持续增长现象。(当时忘记截图了,后来补了一张图,但是 goroutine 数量一直是没有变化的)
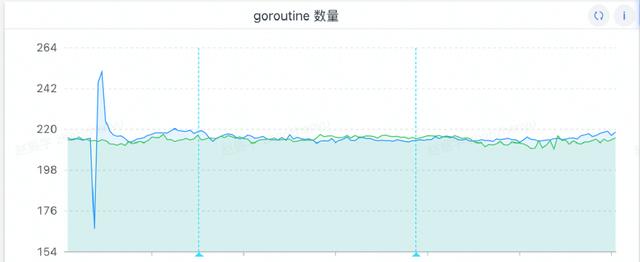
没有 goroutine 逃逸问题。
通过 pprof 进行实时内存采集,对比问题实例和正常实例的内存使用状况:
问题实例:

正常实例:

进一步看问题实例的 graph:

从中可以发现,metircs.flushClients()占用的内存是最多的,去定位源码:
func (c *tagCache) Set(key []byte, tt *cachedTags) { if atomic.AddUint64(&c.setn, 1)&0x3fff == 0 { // every 0x3fff times call, we clear the map for memory leak issue // there is no reason to have so many tags // FIXME: sync.Map don't have Len method and `setn` may not equal to the len in concurrency env samples := make([]interface{}, 0, 3) c.m.Range(func(key interface{}, value interface{}) bool { c.m.Delete(key) if len(samples) < cap(samples) { samples = append(samples, key) } return true }) // clear map logfunc("[ERROR] gopkg/metrics: too many tags. samples: %v", samples) } c.m.Store(string(key), tt)}发现里面为了规避内存泄露,已经通过计数的方式,定数清理掉 sync.Map 存储的 key 了。理论上不应该出现问题。
没有代码 bug 导致内存泄露的问题。
这时注意到了一个事情,在 pprof 里看到 metrics 总共只是占用了 72MB,而总的 heap 内存只有 170+MB 而我们的实例是 2GB 内存配置,占用 80%内存就意味着 1.6GB 左右的 RSS 占用,这两个严重不符(这个问题的临时解决方法在后文有介绍),这并不应该导致内存占用 80%报警。因此猜测是内存没有及时回收导致的。
经过排查,发现了这个神奇的东西:
一直以来 go 的 runtime 在释放内存返回到内核时,在 Linux 上使用的是 MADV_DONTNEED,虽然效率比较低,但是会让 RSS(resident set size 常驻内存集)数量下降得很快。不过在 go 1.12 里专门针对这个做了优化,runtime 在释放内存时,使用了更加高效的 MADV_FREE 而不是之前的 MADV_DONTNEED。详细的介绍可以参考这里:
https://go-review.googlesource.com/c/go/+/135395/
go1.12 的更新原文:
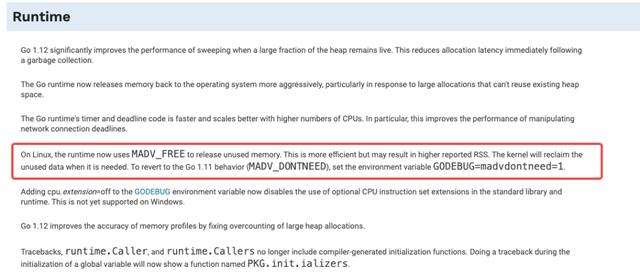
Go 1.12~1.15 runtime 优化了 GC 策略,在 Linux 内核版本支持时 (> 4.5),会默认采用更『激进』的策略使得内存重用更高效、延迟更低等诸多优化。带来的负面影响就是 RSS 并不会立刻下降,而是推迟到内存有一定压力时。
我们的 go 版本是 1.15, 内核版本是 4.14,刚好中招!
go 编译器版本+系统内核版本命中了 go 的 runtime gc 策略,会使得在堆内存回收后,RSS 不下降。
解决方法一共有两种:
这种方法可以强制 runtime 继续使用 MADV_DONTNEED.(参考:
https://github.com/golang/go/issues/28466)。但是启动了madvise dontneed 之后,会触发 TLB shootdown,以及更多的 page fault。延迟敏感的业务受到的影响可能会更大。因此这个环境变量需要谨慎使用!
2. 升级 go 编译器版本到 1.16 以上
看到 go 1.16 的更新说明。已经放弃了这个 GC 策略,改为了及时释放内存而不是等到内存有压力时的惰性释放。看来 go 官网也觉得及时释放内存的方式更加可取,在多数的情况下都是更为合适的。

附:解决 pprof 看 heap 使用的内存小于 RSS 很多的问题,可以通过手动调用 debug.FreeOSMemory 来解决,但是执行这个操作是有代价的。

同时 go1.13 版本中 FreeOSMemory 也不起作用了(
https://github.com/golang/go/issues/35858),推荐谨慎使用。
我们选择了方案二。在升级 go1.16 之后,实例没有出现内存持续快速增长的现象。

再次用 pprof 去看实例情况,发现占用内存的函数也有变化。之前占用内存的 metrics.glob 已经降下去了。看来这个解决方法是有成效的。
在排查过程中发现的另一个可能引起内存泄露的问题(本服务未命中),在未开启 mesh 的情况下,kitc 的服务发现组件是有内存泄露的风险的。

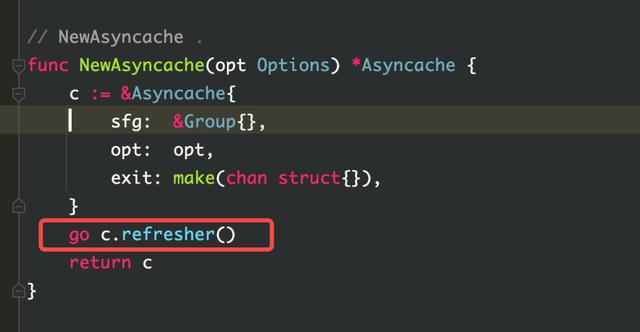
从图中可以看到 cache.(*Asynccache).refresher 占用内存较多,且随着业务处理量的增多,其内存占用会一直不断的增长。
很自然的可以想到是在新建 kiteclient 的时候,可能有重复构建 client 的情况出现。于是进行了代码排查,并没有发现重复构建的情况。但是去看 kitc 的源码,可以发现,在服务发现时,kitc 里建立了一个缓存池 asyncache 来进行 instance 的存放。这个缓存池每 3 秒会刷新一次,刷新时调用 fetch,fetch 会进行服务发现。在服务发现时会根据实例的 host、port、tags(会根据环境 env 进行改变)不断地新建 instance,然后将 instance 存入缓存池 asyncache,这些 instance 没有进行清理也就没有进行内存的释放。所以这是造成内存泄露的原因。

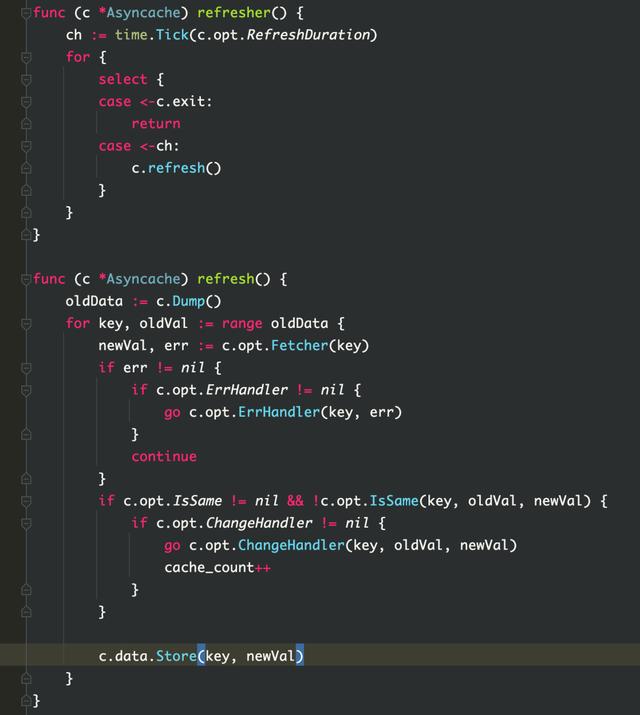

该项目比较早,所以使用的框架比较陈旧,通过升级最新的框架可以解决此问题。
首先定义一下什么是内存泄露:
内存泄漏(Memory Leak)是指程序中已动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果。
在 go 的场景中,常见的内存泄露问题有以下几种:
(1)goroutine 申请过多
问题概述:
goroutine 申请过多,增长速度快于释放速度,就会导致 goroutine 越来越多。
场景举例:
一次请求就新建一个 client,业务请求量大时 client 建立过多,来不及释放。
(2)goroutine 阻塞
① I/O 问题
问题概述:
I/O 连接未设置超时时间,导致 goroutine 一直在等待。
场景举例:
在请求第三方网络连接接口时,因网络问题一直没有接到返回结果,如果没有设置超时时间,则代码会一直阻塞。
② 互斥锁未释放
问题概述:
goroutine 无法获取到锁资源,导致 goroutine 阻塞。
场景举例:
假设有一个共享变量,goroutineA 对共享变量加锁但未释放,导致其他 goroutineB、goroutineC、...、goroutineN 都无法获取到锁资源,导致其他 goroutine 发生阻塞。
③ waitgroup 使用不当
问题概述:
waitgroup 的 Add、Done 和 wait 数量不匹配,会导致 wait 一直在等待。
场景举例:
WaitGroup 可以理解为一个 goroutine 管理者。他需要知道有多少个 goroutine 在给他干活,并且在干完的时候需要通知他干完了,否则他就会一直等,直到所有的小弟的活都干完为止。我们加上 WaitGroup 之后,程序会进行等待,直到它收到足够数量的 Done()信号为止。假设 waitgroup Add(2), Done(1),那么此时就剩余一个任务未完成,于是 waitgroup 会一直等待。详细介绍可以看 Goroutine 退出机制 中的 waitgroup 章节。
问题概述:
使用 select 但 case 未覆盖全面,导致没有 case 就绪,最终 goroutine 阻塞。
场景举例:
通常发生在 select 的 case 覆盖不全,同时又没有 default 的时候,会产生阻塞。示例代码如下:
func main() { ch1 := make(chan int) ch2 := make(chan int) ch3 := make(chan int) go Getdata("https://www.baidu.com",ch1) go Getdata("https://www.baidu.com",ch2) go Getdata("https://www.baidu.com",ch3) select{ case v:=<- ch1: fmt.Println(v) case v:=<- ch2: fmt.Println(v) }}问题概述:
场景举例:
上面三种原因的代码 bug 都会导致 channel 阻塞,这里提供几个生产环境发生的真实的 channel 阻塞的例子:
(1)time.after()使用不当
问题概述:
默认的 time.After()是会有内存泄漏问题的,因为每次 time.After(duratiuon x)会产生 NewTimer(),在 duration x 到期之前,新创建的 timer 不会被 GC,到期之后才会 GC。
那么随着时间推移,尤其是 duration x 很大的话,会产生内存泄漏的问题。
场景举例:
func main() { ch := make(chan string, 100) go func() { for { ch <- "continue" } }() for { select { case <-ch: case <-time.After(time.Minute * 3): } }}(2)time.ticker 未 stop
问题概述:
使用 time.Ticker 需要手动调用 stop 方法,否则将会造成永久性内存泄漏。
场景举例:
func main(){ ticker := time.NewTicker(5 * time.Second) go func(ticker *time.Ticker) { for range ticker.C { fmt.Println("Ticker1....") } fmt.Println("Ticker1 Stop") }(ticker) time.Sleep(20* time.Second) //ticker.Stop()}建议:总是建议在 for 之外初始化一个定时器,并且 for 结束时手工 stop 一下定时器。
问题概述:
场景举例:
var a []intfunc test(b []int) { a = b[:3] return}2. 在遇到的其他坑里提到的 kitc 的服务发现代码就是这个问题的示例。
今后遇到 golang 内存泄漏问题可以按照以下几步进行排查解决:
2. 判断 goroutine 问题;
3. 判断代码问题;
4. 解决对应问题并在测试环境中观察,通过后上线进行观察;
飞书是字节跳动旗下先进企业协作与管理平台,围绕目标、信息与人三个维度全方位助力组织升级。一站式整合即时沟通、日历、音视频会议、文档、云盘等办公协作套件,让组织和个人工作更高效更愉悦。飞书目前已服务包括互联网、信息技术、制造、建筑地产、教育、媒体在内等众多领域的先进企业。我们是飞书的Lark Core Services 团队,负责飞书核心的 IM 领域能力,包括消息、群组、用户资料、开放能力等等。期待您的加入~
社招链接:
https://job.toutiao.com/s/Ne1ovPK
校招链接(暑期实习)
https://jobs.toutiao.com/s/NJ3oxsp
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号